Fetch join 전 후 코드 및 쿼리 비교
user 부분 리팩토링 중이다. 상황은 다음과 같다.
user entity는 userImage entity와 1:1 관계를 가진다. user는 6명이다. 코드는 아래와 같다. 작동 순서는 user list 가져온 후 User 참조형을 UserDto 로 바꾼다. userDto로 바꿀때 연관관계에 있는 UserImage를 가져온다.
<ReviewRepository>
List<User> findAllUserWithUserImage();
<UserMapper>
default UserDto toUserDto(User user) {
if (user == null) {
return null;
}
return new UserDto(
user.getId(),
user.getUsername(),
user.getUserImage().getProfile(),
user.getEmail(),
user.getDescription(),
user.getRoleType()
);
}
이때 아무런 조치를 취해주지 않으면 콘솔에 쿼리는 userList 호출 쿼리 + 각 유저의 userImage 정보를 가져오느라 6번 추가 쿼리 발생한다. 총 7번 쿼리가 발생한다. 가령 아래와 같다.
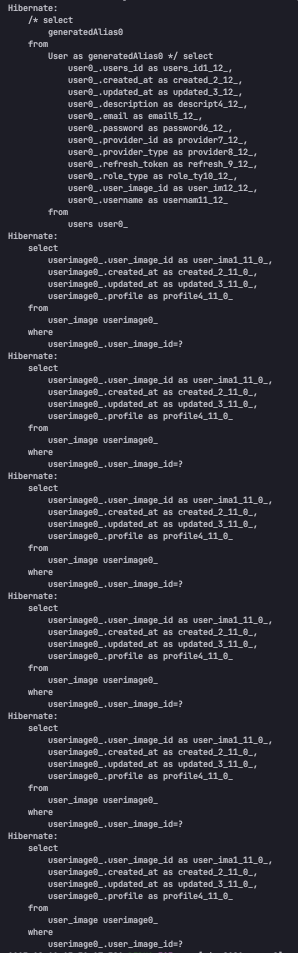
하지만 fetch join을 사용하면 쿼리는 아래와 같이 1번으로 줄어든다.
<UserRepository>
@Query("SELECT u FROM User u LEFT JOIN FETCH u.userImage")
List<User> findAllUserWithUserImage();
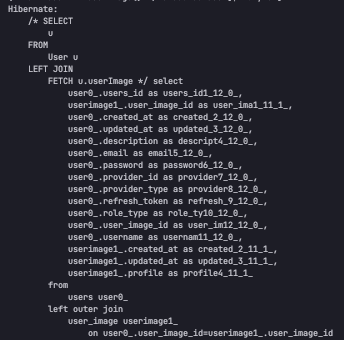
그럼 이렇게 쿼리가 줄어들면 뭐가 좋을까?
Fetch join과 검색 속도
fetch join 적용 전 후 코드에 대해 포스트 맨에서 검색 테스트 해봤다. 테스트는 각각 1000번씩 요청 보내고 속도를 측정했다.
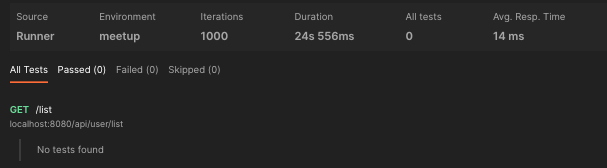
먼저 fetch join을 적용하지 않아서 N+1 발생하는 상황이다. 위에서 첨부한 사진처럼 1회 요청에 1+6회, 총 7회 쿼리가 날아간다. 그럼 1000번 요청은 1000 + 6000 = 7000 요청 발생했다. 속도는 아래 사진 처럼 약 24초다.
다음은 fetch join 적용한 코드다. 1000번 요청에 1000개의 쿼리 발생했다. 약 20초 정도 걸렸다.
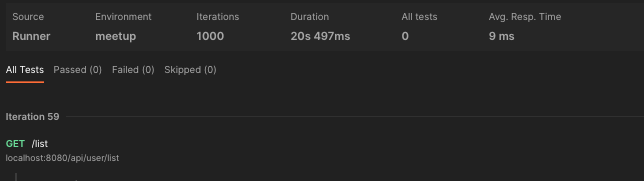
1000번의 쿼리 발생에서 약 4초 정도 차이 발생했다. 실제 서비스 24/7 다양한 유저의 요청 환경에서는 위와같은 차이는 적지 않은 성능 및 비용 발생으로 예상된다.
그럼 아예 안전하게 모든 N+1 발생 레포지토리에 fetch join 쓰면 좋을까?
fetch join 비용
정규화 된 환경에서 N+1 이 많이 발생하는 상황이라면 항상 fetch join을 사용할 것이다. 하지만 어느 순간 역정규화해서 한 테이블에서 검색하는게 fetch join 으로 인해 발생하는 join 비용보다 저렴할 상황이 발생할 수 있다. 이때는 과감히 정규화 + fetch join 을 버리고 역정규화를 선택하는게 좋다고 생각한다.
