Deep Learning - 캐릭터별 상담챗봇
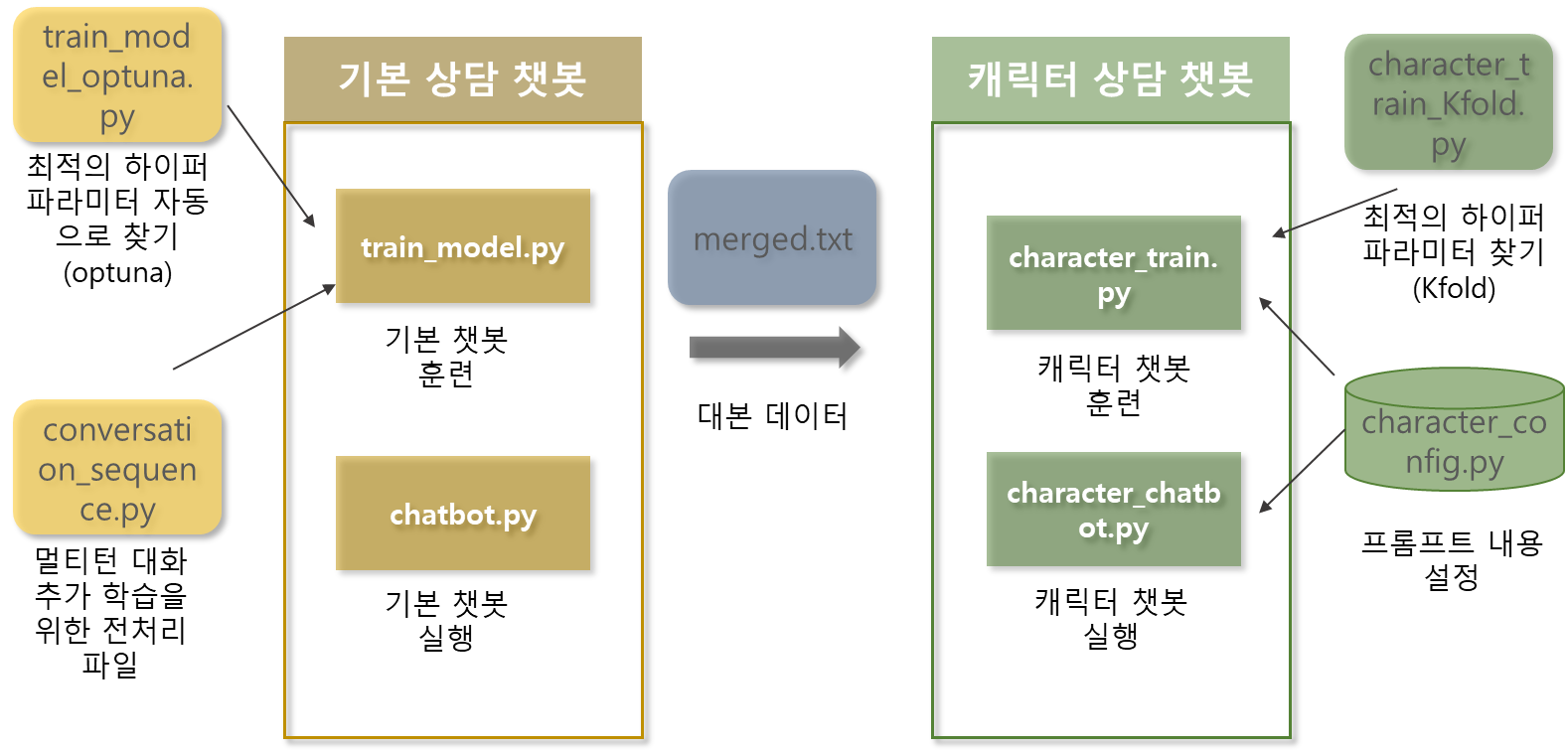
0. 캐릭터 선택 심리(연애) 상담 챗봇 프로세스
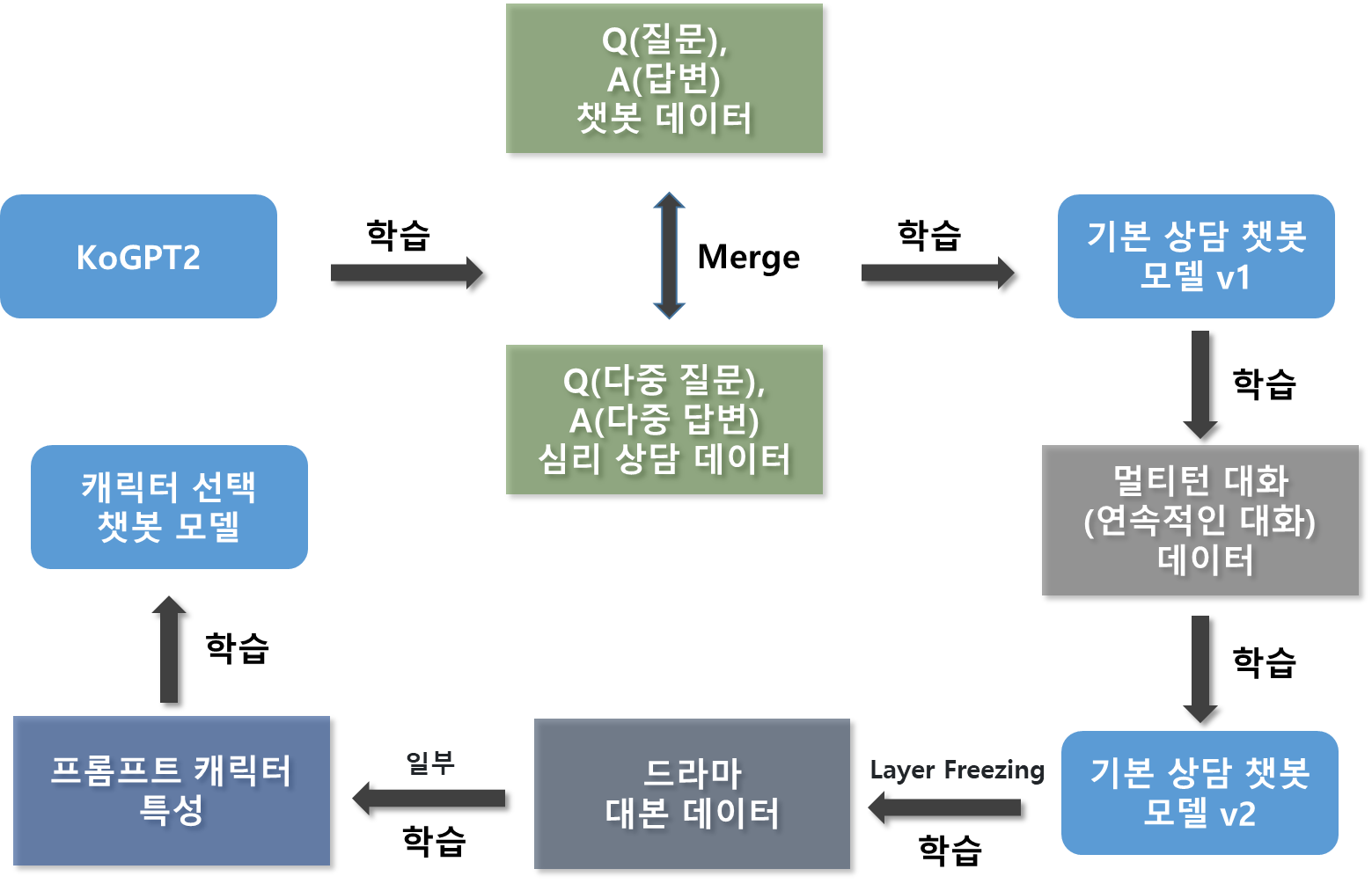
1. KOGPT2 기반 모델 준비
KOGPT2 모델 로드
skt/kogpt2-base-v2 모델은 SKT에서 제공하는 한국어 GPT-2 모델임. 이 모델은 이미 대규모 한국어 텍스트 코퍼스에서 사전 학습(pre-trained)된 상태임. 따라서 한국어 문장을 이해하고 생성하는 데 강점을 가지고 있음. 이 모델을 불러와 이후 단계에서 추가적인 학습을 진행하게 됨.
->참고 사이트:
1)skt/kogpt2-base-v2의 간단한 설명: https://ai-network.medium.com/ai-%EB%AA%A8%EB%8D%B8-%ED%83%90%ED%97%98%EA%B8%B0-7-%ED%95%9C%EA%B8%80-%EB%B2%84%EC%A0%84%EC%9D%98-gpt-2-f7317e6499f9
2)관련 github: https://github.com/SKT-AI/KoGPT2
3)구현 요약: https://wikidocs.net/157001
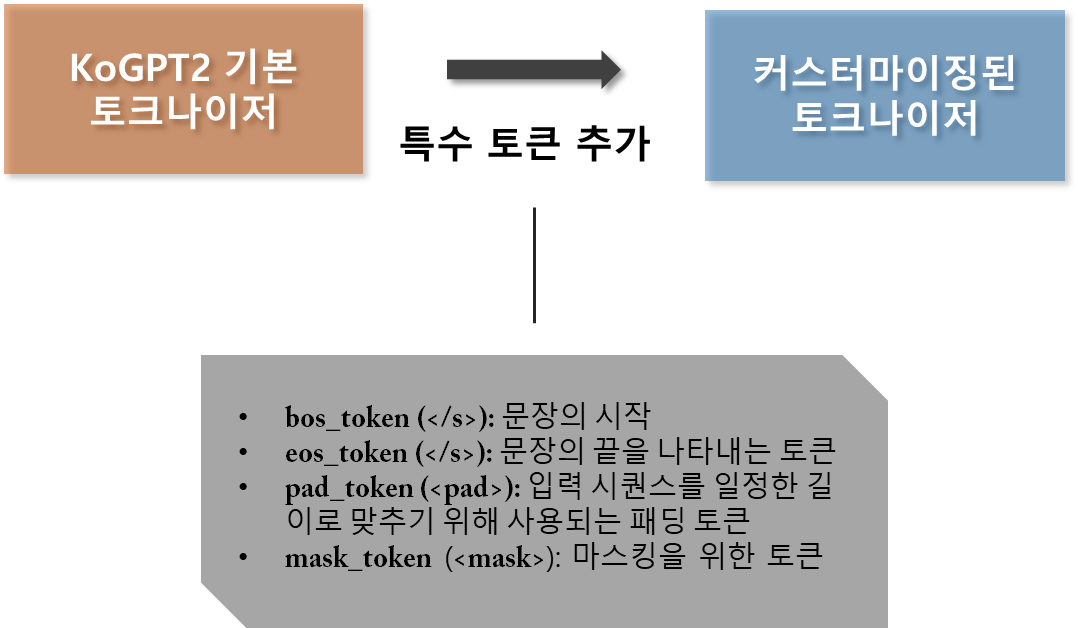
토크나이저 커스터마이징
PreTrainedTokenizerFast 클래스를 사용하여 kogpt2 모델에 맞는 토크나이저를 로드함. 이 토크나이저는 GPT-2 모델과 호환되도록 설계되었으며, 한국어 텍스트를 토큰 단위로 변환하는 데 최적화되어 있음. 또한, 특수 토큰들(bos_token, eos_token, pad_token, mask_token)을 설정하여, 모델이 문장의 시작과 끝, 패딩 등을 인식하고 처리할 수 있도록 함.
2. 데이터 준비
기본 데이터 로드 (ChatbotData.csv)
ChatbotData.csv 파일에는 기본적인 질문(Q)과 답변(A) 쌍이 포함되어 있음. 이 데이터는 챗봇이 기본적인 질문에 대해 응답을 생성할 수 있도록 학습하는 데 사용됨.
추가 데이터 로드 및 전처리 (감성대화말뭉치(최종데이터)_Training.xlsx)
감성대화말뭉치(최종데이터)_Training.xlsx 파일에는 감정 기반 대화 데이터가 포함되어 있음. 이 데이터를 Q&A 형식으로 변환하여, 챗봇이 감정적인 상황에서도 적절한 응답을 생성할 수 있도록 학습함.
데이터 병합
기본 데이터(ChatbotData.csv)와 감성 대화 데이터(감성대화말뭉치(최종데이터)_Training.xlsx)를 병합하여, 챗봇의 학습 데이터를 더욱 풍부하게 구성함.
대화 시퀀스 데이터 로드 (merged_conversation_sequences.csv)
merged_conversation_sequences.csv 파일에는 연속적인 대화 흐름이 포함되어 있음. 이 데이터는 Q&A 형식과는 달리, 대화의 맥락을 유지하면서 모델이 학습할 수 있도록 함.
대화 시퀀스 데이터 병합
Q&A 형식의 데이터와 대화 시퀀스 데이터를 병합하여, 모델이 단순한 질문 응답뿐만 아니라 대화의 흐름을 이해하고 유지할 수 있도록 학습함.
3. 데이터셋 정의 및 배치 처리
데이터셋 정의 (ChatDataset 클래스)
각 대화나 Q&A 데이터를 토크나이저를 사용해 토큰으로 변환하고, 지정된 길이를 넘는 경우 자르거나 패딩을 추가함. 모델이 학습할 수 있도록 텍스트 데이터를 [토큰 IDs, 마스크, 레이블] 형태로 반환함.
배치 처리 (collate_batch 함수)
각 배치에서 여러 데이터를 스택(stack)하여 텐서(tensor) 형태로 묶어줌. 이를 통해 GPU 메모리를 효율적으로 사용하며, 병렬 처리로 학습 속도를 높임.
4. 모델 학습
훈련 과정
손실 함수(CrossEntropyLoss)와 옵티마이저(AdamW)를 사용하여 모델의 파라미터를 업데이트함. 각 배치에서 손실을 계산하고, 역전파를 통해 모델의 가중치를 조정함. epochs마다 모델의 손실과 정확도를 출력하며 학습이 진행됨.
검증 과정
검증 데이터셋을 사용해 모델의 성능을 평가함. 검증 데이터는 모델이 보지 않은 데이터로 구성되어 있으며, 이를 통해 모델의 일반화 성능을 평가함. 검증 손실과 정확도를 계산하여 출력함.
5. 모델 저장
기존 모델 저장 (./model)
학습된 모델과 토크나이저를 ./model 디렉토리에 저장함. 이 모델은 기본 Q&A와 감성 대화를 학습한 상태임.
대화 시퀀스 학습 모델 저장 (./conversation_sequences_model)
대화 시퀀스 데이터를 추가 학습한 모델을 ./conversation_sequences_model 디렉토리에 별도로 저장함. 이 모델은 대화의 흐름을 유지하면서 더 자연스러운 대화를 생성할 수 있도록 학습된 상태임.
6. 캐릭터 특성 상담 챗봇 구현
캐릭터별 대본 데이터 준비 및 학습
대본 데이터(merged.txt)에서 캐릭터별 대사를 추출하여, 캐릭터의 말투, 성격, 자주 사용하는 추임새 등을 반영한 데이터셋을 생성함. 이 데이터셋을 사용하여 캐릭터 특성에 맞는 상담 챗봇 모델을 추가로 학습시킴.
자주 사용하는 추임새 추출
사용자가 직접 각 캐릭터별로 자주 사용하는 추임새를 수동으로 지정. 지정된 추임새는 각 캐릭터의 답변에 랜덤하게 삽입될 수 있도록 처리되며, 이를 통해 캐릭터 특유의 말투가 챗봇 대화에 반영. 이 방식은 자동 추출 방식에 비해 더 정확하게 캐릭터의 개성을 반영할 수 있으며, 대화의 자연스러움을 높이는 데 기여.
프롬프트 엔지니어링
각 캐릭터의 말투와 성격을 반영한 프롬프트를 설정하여, 모델이 캐릭터의 특성에 맞는 응답을 생성하도록 유도함. 프롬프트는 캐릭터별로 고유한 말투나 특성을 포함하도록 설계되어, 챗봇이 더 개성 있는 대화를 이어나갈 수 있도록 함.

감정 표현 및 행동 필터링
대본 데이터에서 괄호 안의 감정 표현이나 행동 묘사 부분을 필터링하여, 캐릭터의 대사에만 집중할 수 있도록 처리함. 이를 통해 모델이 불필요한 감정 표현이나 행동 묘사에 영향을 받지 않고, 대사만을 학습할 수 있도록 함.
캐릭터 특성 모델 저장 (./character_model/{character}_model)
캐릭터별로 학습된 모델을 ./character_model/{character}_model 디렉토리에 저장함. 이 모델들은 각 캐릭터의 특성을 반영하여 상담 챗봇 역할을 수행할 수 있음.
기본 상담 챗봇과의 차별화
기본 상담 챗봇(conversation_sequences_model)은 일반적인 대화 흐름과 응답을 생성하는 데 중점을 둠. 캐릭터 상담 챗봇은 각 캐릭터의 특성, 말투, 추임새 등을 반영하여 더 개성 있는 응답을 생성함. 프롬프트 엔지니어링과 필터링 기능을 통해 캐릭터 상담 챗봇은 각 캐릭터의 고유한 특성을 유지하면서도, 더욱 자연스러운 대화를 가능하게 함.
7. 챗봇 실행 방법
단계별 설명
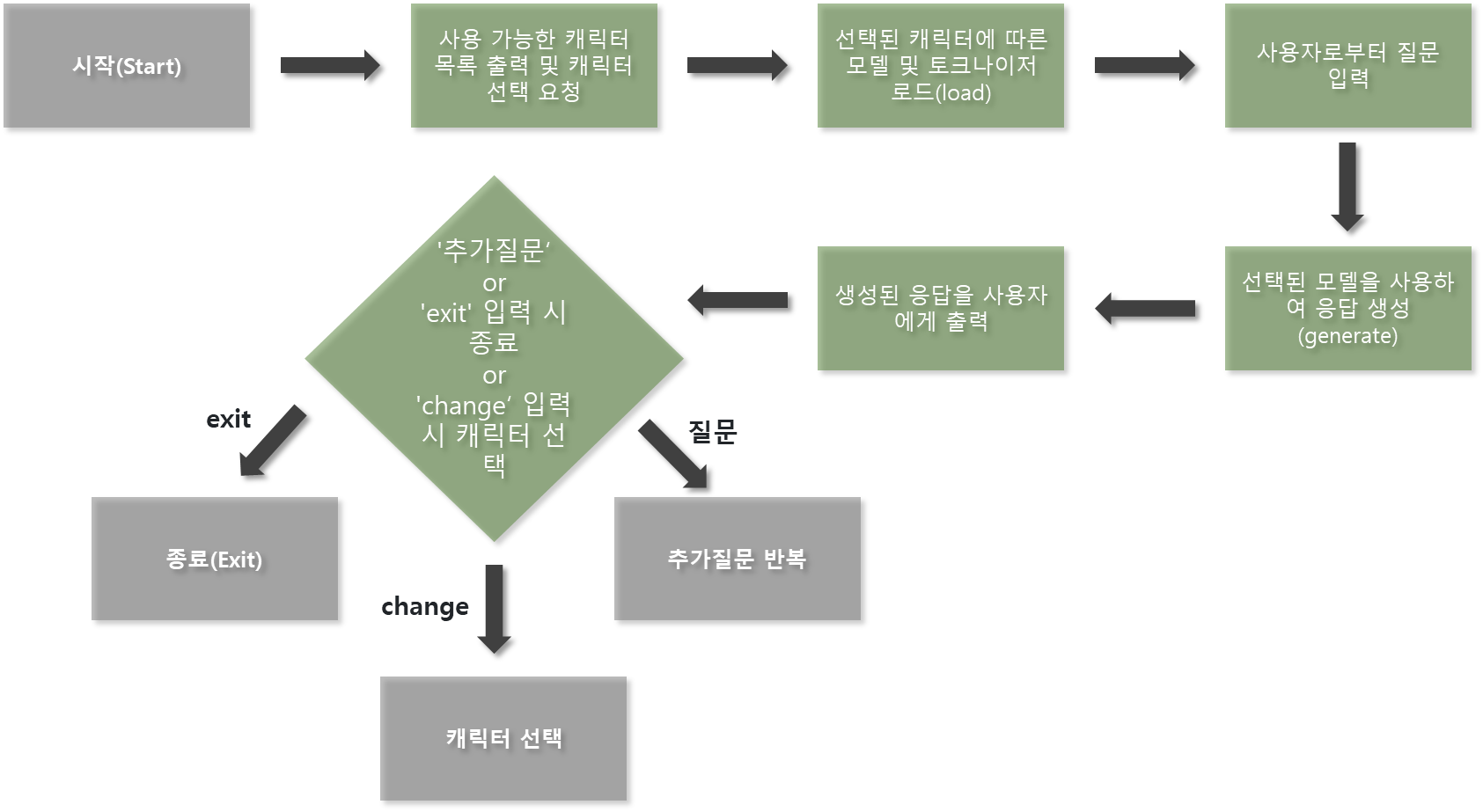
1) 시작 (Start)
프로그램이 실행되면 챗봇이 초기화.
사용자와의 상호 작용을 시작할 준비.
2) 사용 가능한 캐릭터 목록 출력 및 캐릭터 선택 요청
챗봇은 사용자에게 선택할 수 있는 캐릭터 목록을 제공.
예: 준하, 해미, 순재, 문희, 민용, 상담챗봇
사용자는 대화하고 싶은 캐릭터를 선택하여 입력.
3) 선택된 캐릭터에 따른 모델 및 토크나이저 로드
선택된 캐릭터에 맞는 언어 모델과 토크나이저를 로드.
모델 캐싱(Cache) 기능을 통해 동일한 모델을 재사용하여 로딩 속도를 향상.
이미 로드된 모델이 있으면 캐시에서 불러옴.
모델 경로를 확인하여 존재하지 않으면 오류를 처리.
로드된 모델은 해당 캐릭터의 말투, 성격, 추임새 등을 반영하도록 학습되어 있음.
4) 사용자로부터 질문 입력
사용자는 챗봇에게 질문을 입력.
입력된 질문은 선택된 캐릭터의 관점에서 답변.
5) 선택된 모델을 사용하여 응답 생성
로드된 모델과 토크나이저를 사용하여 입력된 질문에 대한 적절한 응답을 생성.
생성 과정에서는 다양한 하이퍼파라미터가 사용되어 응답의 다양성과 품질을 조절.
예: max_length, top_k, top_p, temperature 등
6) 생성된 응답을 사용자에게 출력
생성된 응답을 포맷팅하여 사용자에게 출력.
응답은 선택된 캐릭터의 말투와 특성을 반영.
7) 'exit' 입력 시 종료 여부 확인 및 처리
사용자가 'exit'를 입력하면 대화 세션을 종료.
그렇지 않으면 4번 단계로 돌아가 추가적인 질문을 받을 준비.
이 과정을 사용자가 종료를 원할 때까지 반복.
8. 최종 검토
학습 결과 확인
모든 학습이 끝난 후, 최종 손실 값을 출력하여 학습이 성공적으로 완료되었는지 확인함.
모델 테스트 및 활용
학습된 모델을 테스트하여 새로운 입력에 대해 응답을 생성할 수 있도록 함. 이를 통해 모델의 실서비스 적용 가능성을 확인하거나, 추가 학습이 필요할 경우 다음 단계로 진행할 수 있음.
9. 결과
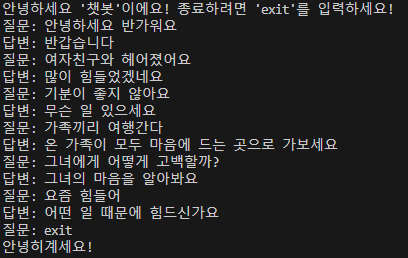
기본 챗봇 결과 확인
다소 어설픈 부분이 있지만, 그래도 어느정도 대답을 생성함
캐릭터 챗봇 결과 확인
1) 데이터: 거침없이 하이킥 대본 데이터 학습
2) 캐릭터: "준하", "해미", "순재", "문희", "민용"
-> 만족스럽지 못한 결과가 나왔지만, 캐릭터의 특성은 조금 보이는 것 같음.
10. 캐릭터 챗봇 성능 향상을 위한 테스트
캐릭터 별 자주 사용하는 추임새 생성
-> 캐릭터 별 추임새를 생성한 결과 더 자연스러운 문장이 됨.
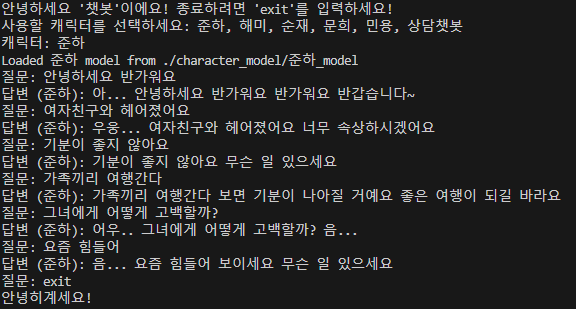


캐릭터 별 말투 강화
-> '순재' 캐릭터 특성인 거의 모든 말에 반말로 대답함을 강화함.
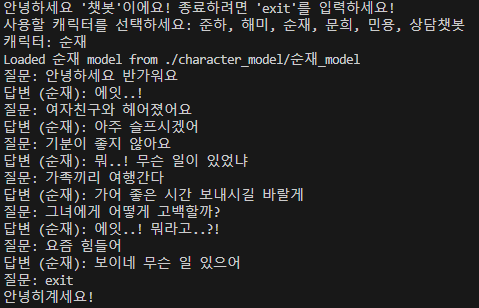
대본 데이터 특성 강화
목적:
대본 형식의 대화 데이터를 연속적인 대화 흐름으로 모델이 학습할 수 있게 변환하여, 모델이 대화의 맥락을 이해하고 적절한 응답을 생성할 수 있도록 함.
방법:
연속적인 대화 흐름 구성: 대본 형식의 대화 데이터를 이용하여, 각 대화를 앞뒤 문장의 맥락과 함께 모델이 학습할 수 있도록 입출력 쌍으로 묶음.
KoBERT를 이용한 유사도 판단: KoBERT 모델을 사용하여 이전 대화와 현재 대사의 유사도를 계산함.
각 문장 간 유사도를 측정하여, 유사도가 일정 기준(예: 70%) 이상이면 같은 대화의 연속으로 판단하여 묶음.
이 방법을 통해 화자가 달라지거나 새로운 문장이 추가되어도 대화의 주제가 이어지는지를 판단 가능.
예시:
예를 들어, 아래와 같은 대화가 있을 때:
A: 안녕하세요.
B: 안녕하세요, 오빠.
A: 오늘 날씨가 좋네요.
각 문장을 KoBERT를 이용해 유사도를 측정하여 연결 여부를 판단함.
첫 번째 문장 "A: 안녕하세요."와 두 번째 문장 "B: 안녕하세요, 오빠."는 유사도가 높아 동일 대화로 묶임.
세 번째 문장 "A: 오늘 날씨가 좋네요."도 앞선 문장들과 유사도가 높다면 연속적인 대화로 학습 데이터에 포함.
KoBERT를 통한 유사도 측정 과정
유사도 측정:
KoBERT 모델을 이용해 각 문장의 임베딩을 생성하고, 코사인 유사도 등을 계산하여 유사도를 측정.
유사도 값이 similarity_threshold를 초과하는 경우, 해당 문장들을 연속적인 대화로 인식함.
데이터 예시:
KoBERT 모델이 similarity_threshold=0.7로 설정되어 있다면, 앞뒤 문장의 유사도가 70% 이상일 때 같은 대화로 간주.
예시:
"A: 안녕하세요."와 "B: 안녕하세요, 오빠." → 유사도 0.85 → 연결
"B: 안녕하세요, 오빠."와 "A: 오늘 날씨가 좋네요." → 유사도 0.75 → 연결
결과:
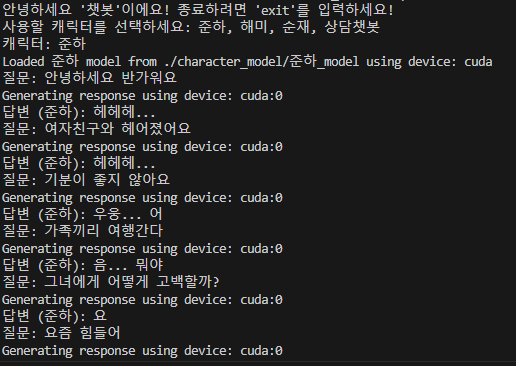
왜 대화 흐름을 묶는 전처리 방식이 챗봇 성능에 부정적인 영향을 미쳤을까?
1) 대화 맥락의 왜곡:
대화 흐름을 묶는 전처리 방식에서는 이전의 여러 대사를 함께 묶어 학습 데이터로 사용. 이 과정에서 특정 대사의 맥락이 왜곡될 수 있다고 생각함. 예를 들어, 대화 A가 B와 연결될 때, 사실 이 둘은 연관이 적지만 단순히 유사도 계산 결과로 인해 묶일 수 있음.
대화의 자연스러운 흐름이 깨지면서, 모델이 맥락을 잘못 이해하거나 불필요한 내용을 학습.
2) 과도한 맥락 연결로 인한 과적합:
이전 대사들을 지나치게 많이 고려하는 경우, 모델이 특정 패턴에 과적합될 가능성. 즉, 특정한 흐름에서만 잘 작동하고, 실제 사용자 질문에는 어울리지 않는 답변을 할 가능성이 높아짐.
이로 인해 모델이 실제 응답을 생성할 때, 지나치게 길고 맥락에 맞지 않는 대답을 할 수 있음.
3) 대화의 다양성 감소:
대화를 묶어서 학습하다 보면, 다양한 대화 형태를 학습할 기회가 줄어듬. 모델이 너무 제한된 맥락에서만 학습되기 때문에, 새로운 상황에서의 대응력이 떨어지게 됨.
특히, 짧고 명료한 대답보다는 길고 중복된 대답이 늘어나면서 챗봇의 퀄리티가 저하될 수 있음.
4) 불필요한 정보 학습:
여러 대사를 묶어서 학습하는 과정에서 유사도가 낮지만 임계값을 넘겨 연결된 대사들이 포함될 수 있음. 이런 대사는 실제로는 불필요하거나 오히려 혼란을 줄 수 있는 정보가 됨.
결과적으로 모델이 불필요한 내용을 학습하고, 응답의 질이 떨어지게 됨.
5) 상황 묘사와 행동 설명:
드라마, 시트콤 득성상 대사뿐만 아니라 행동 묘사나 상황 설명이 많이 포함. 예를 들어, "일어나며", "씩 웃는" 등의 행동 설명이 대사와 함께 제공. 이 정보는 대화의 맥락을 형성하지만, 챗봇 모델이 이를 대화의 일부로 오인해 적절하지 않은 응답을 생성할 수 있음.
6) 해결 방법:
전처리 방식 원복하기: 단일 대사 기반으로 되돌리기
이제 전처리 방식을 이전의 단일 대사 기반으로 되돌려서 대화 흐름을 묶지 않고, 각 대사를 독립적으로 처리
캐릭터 모델별 하이퍼파라미터 값 설정
K-Fold Cross Validation 검증으로 캐릭터 별 최적의 하이퍼파라미터 찾기

목적:
각 캐릭터의 대화 스타일과 데이터에 가장 적합한 하이퍼파라미터 값을 찾기 위해, K-Fold Cross Validation을 활용하여 모델을 검증.
방법:
각 캐릭터의 대사 데이터를 기반으로 K-Fold Cross Validation을 수행하여 최적의 하이퍼파라미터(학습률, 배치 크기, 에폭 수 등)를 탐색.
각 Fold에서 학습과 검증을 반복하여 평균 검증 손실을 계산.
검증 손실이 가장 낮은 하이퍼파라미터를 선택하여 최종 모델 학습에 사용.
결과 해석 및 요약
모든 캐릭터에 대해 K-Fold Cross Validation을 통해 최적의 하이퍼파라미터를 찾고, 그 결과를 사용하여 각 캐릭터별로 모델을 최종 학습(fine-tuning)하였음. 각 캐릭터에 대해 최적의 하이퍼파라미터와 그에 따른 성능(평균 손실 값)이 출력되었고, 최종적으로 모델이 저장.
캐릭터별 최적의 하이퍼파라미터와 학습 결과
준하 캐릭터
최적의 하이퍼파라미터:
Learning Rate (LR): 1e-05
Batch Size (BS): 8
Epochs: 5
평균 검증 손실 (Validation Loss): 1.4469
Fine-tuning Loss:
Epoch 1: 1.6364
Epoch 2: 1.4227
Epoch 3: 1.3948
Epoch 4: 1.3810
Epoch 5: 1.3714
결과: 준하 캐릭터 모델의 손실 값이 안정적으로 감소하며, 모델이 잘 학습되었음을 보여줌.
해미 캐릭터
최적의 하이퍼파라미터:
Learning Rate (LR): 1e-05
Batch Size (BS): 8
Epochs: 5
평균 검증 손실 (Validation Loss): 1.3479
Fine-tuning Loss:
Epoch 1: 1.5563
Epoch 2: 1.3225
Epoch 3: 1.2975
Epoch 4: 1.2853
Epoch 5: 1.2748
결과: 해미 캐릭터 모델도 학습이 잘 진행되었으며, 손실 값이 꾸준히 감소하는 경향을 보임.
순재 캐릭터
최적의 하이퍼파라미터:
Learning Rate (LR): 1e-05
Batch Size (BS): 8
Epochs: 5
평균 검증 손실 (Validation Loss): 1.4069
Fine-tuning Loss:
Epoch 1: 1.5739
Epoch 2: 1.3740
Epoch 3: 1.3546
Epoch 4: 1.3438
Epoch 5: 1.3367
결과: 순재 캐릭터 모델 역시 학습이 잘 진행되었으며, 손실 값이 안정적으로 줄어드는 모습을 보임.
종합 분석
모든 캐릭터에서 공통된 최적의 하이퍼파라미터 값은 LR=1e-05, BS=8, Epochs=5로 나타남. 이는 모든 캐릭터가 유사한 학습 패턴을 보이며, 이 조합이 상대적으로 좋은 성능을 제공함을 의미함.
모델 손실 값의 감소는 학습이 성공적으로 이루어지고 있음을 보여줌. 모든 캐릭터에서 학습 동안 손실 값이 꾸준히 감소하는 것을 확인할 수 있음.
참고 코드:
이 과정은 character_train_Kfold.py 파일에서 수행되며, 모델을 여러 번 학습시키며 최적의 조합을 탐색하는 방식으로 진행됨.
유사도 기반 응답 생성 및 캐릭터별 응답 생성 방안
이번 작업에서는 기존의 대본 데이터를 기반으로 캐릭터별 모델을 학습시켜, 챗봇이 질문에 대한 적절한 응답을 생성할 수 있도록 구현했음. 이 과정에서 유사도 기반 응답 생성과 캐릭터별 모델을 활용하는 방식을 적용했음.
유사도 기반 응답 생성
유사도 계산 모델
기존에는 'paraphrase-multilingual-MiniLM-L12-v2' 모델을 사용했으나, 한글 문장 간 유사도를 더 정확하게 측정하기 위해 한글에 최적화된 'BM-K/KoSimCSE-roberta-multitask' 모델로 변경했음.
유사도 계산 방식
사용자가 질문을 입력하면, 미리 계산된 대본 데이터의 질문-응답 쌍과 유사도를 비교하여 가장 유사한 질문-응답 쌍을 찾음. 이를 위해 FAISS(Facebook AI Similarity Search) 라이브러리를 활용해 유사도 검색 속도를 최적화했음.
유사도 임계값
설정된 임계값(기본값 0.6)을 넘는 경우, 해당 응답을 캐릭터 모델이 참고하도록 하고, 유사한 쌍을 찾지 못할 경우 캐릭터별 모델을 이용해 완전히 새로운 응답을 생성함.
캐릭터별 모델을 이용한 응답 생성
기본 챗봇 모델
기존에 학습된 conversation_sequences_model을 기반으로, 각 캐릭터의 대본 데이터를 추가 학습하여 캐릭터별로 파인튜닝했음.
학습 데이터 구성
각 캐릭터의 대사만 필터링하여 학습 데이터로 사용함. 필요에 따라 감정 표현을 필터링하거나 유지하는 방식을 적용해, 캐릭터의 고유한 특성과 말투를 반영함.
전체 학습 데이터 중 약 30%는 캐릭터의 특성을 명확히 나타내는 프롬프트를 추가하여 학습에 사용함. 이를 통해 프롬프트의 학습 비율을 조절하고, 캐릭터의 특성을 강화하면서도 데이터 다양성을 확보할 수 있음.
하이퍼파라미터 조정
각 캐릭터별로 최적의 하이퍼파라미터를 설정하여 모델을 학습했으며, 학습된 모델은 ./character_model/{character}_model 경로에 저장함.
응답 생성 방식
유사한 응답이 있을 때는 이를 참고하여 캐릭터의 말투와 스타일에 맞는 새로운 응답을 생성하고, 유사한 응답이 없는 경우에는 캐릭터별 모델을 사용해 질문에 대한 응답을 생성함. 이를 통해 캐릭터의 특성을 유지하면서도 새로운 상황에 적절히 대응할 수 있는 대화를 생성함.
챗봇 응답의 흐름
입력 처리
사용자가 질문을 입력하면, 유사도 계산 모델을 사용해 대본 데이터에서 가장 유사한 질문-응답 쌍을 찾음.
유사도 비교
유사도가 설정된 임계값보다 높을 경우, 해당 응답을 캐릭터 모델이 참고하여 새로운 응답을 생성하도록 하고, 그렇지 않을 경우 캐릭터별 학습된 모델을 사용하여 새로운 응답을 생성함.
응답 생성
유사한 응답이 없거나 참고할 필요가 없는 경우, 캐릭터별 모델을 사용해 자연스럽고 일관된 응답을 생성하고, 사용자가 선택한 캐릭터의 성격에 맞는 대화를 이어가도록 함.
Layer Freezing 기법을 적용한 응답 생성
Layer Freezing 기법 적용
기존 모델의 하위층을 고정하고 상위층만 학습하는 Layer Freezing 기법을 적용해, 캐릭터별 고유 특성을 학습하면서도 기본적인 언어 능력을 유지하도록 함. 이를 통해, 모델이 캐릭터 특성에 맞는 대답을 하되, 일반적인 대화 능력도 잃지 않도록 조정함.
하위층 고정 및 상위층 학습
모델의 하위층 8개를 고정(freeze)하고, 상위 4개 층만 학습하도록 하여 모델이 기존의 언어적 지식과 일반적 대화 능력을 유지하도록 조정함. 이렇게 함으로써 모델은 캐릭터의 말투와 스타일을 잘 반영하면서도, 일반적인 질문에 대해서는 적절하고 일관된 응답을 할 수 있음.
챗봇이 응답을 출력 하기 까지의 과정
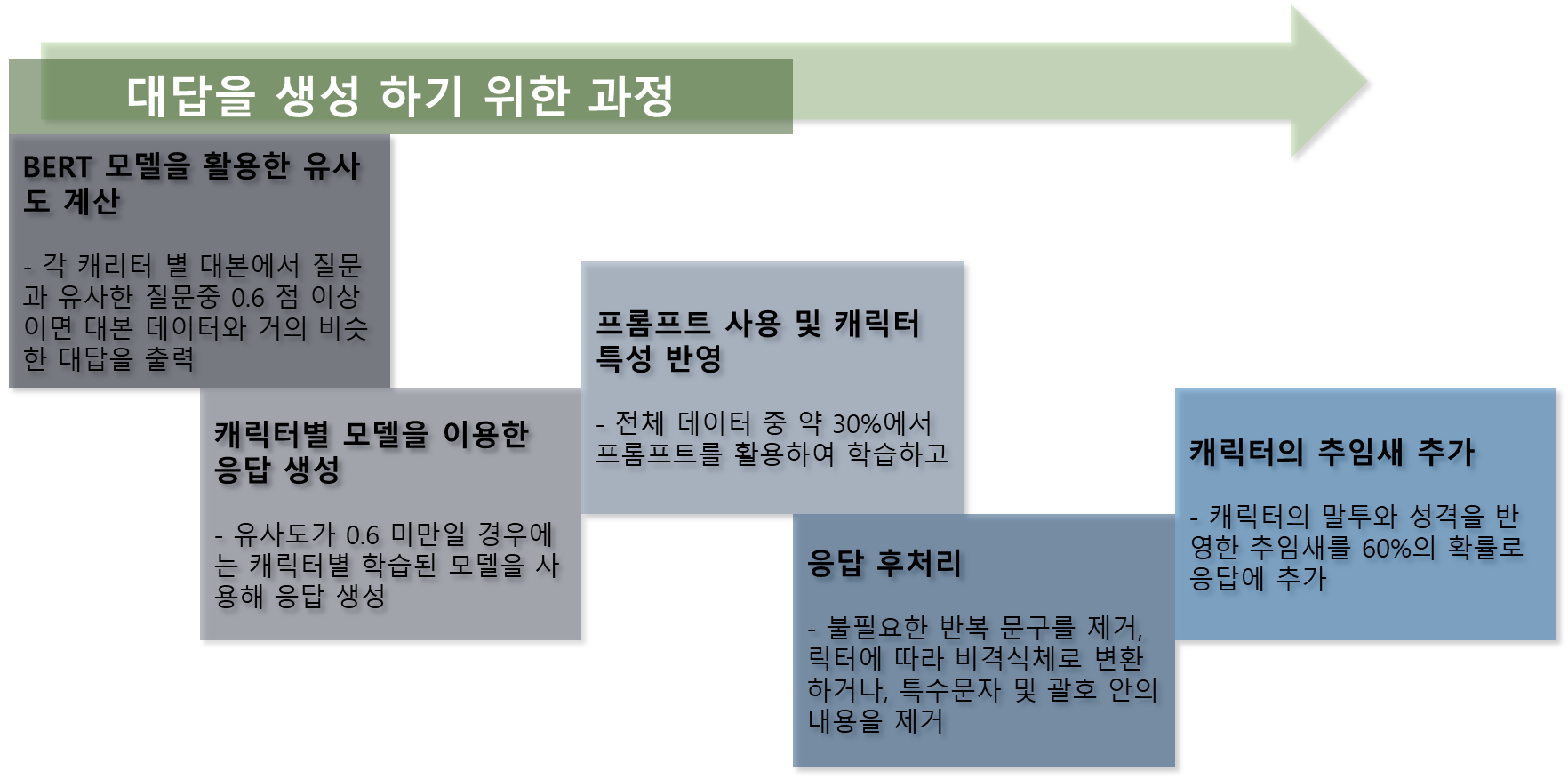
1. BERT 모델을 활용한 유사도 계산
사용자가 질문을 입력하면, 먼저 BM-K/KoSimCSE-roberta-multitask와 같은 BERT 기반의 모델을 사용해 해당 질문의 임베딩 벡터를 생성함.
이후, 캐릭터별로 미리 계산된 대본 데이터의 질문-응답 쌍과 유사도를 계산함. 여기에는 FAISS(Facebook AI Similarity Search) 라이브러리를 사용해 유사도 검색 속도를 최적화함.
계산된 유사도가 0.6 이상일 경우, 해당 질문에 가장 유사한 대본 데이터의 응답을 그대로 출력하거나, 이를 기반으로 응답을 생성함.
2. 캐릭터별 모델을 이용한 응답 생성
유사한 질문-응답 쌍을 찾지 못하거나, 유사도가 0.6 미만일 경우에는 캐릭터별로 학습된 GPT-2 모델을 사용해 새로운 응답을 생성함.
각 캐릭터의 특성(말투, 성격 등)이 반영된 모델을 사용해, 질문에 대한 맞춤형 응답을 생성함.
3. 프롬프트 사용 및 캐릭터 특성 반영
응답 생성 시, 캐릭터의 특성을 더욱 반영하기 위해 프롬프트를 사용함. 예를 들어, 캐릭터의 이름이나 성격에 맞는 특정한 문구를 응답 생성에 추가함.
전체 데이터 중 약 30%에서 프롬프트를 활용하여 학습하고, 응답 생성 시에도 이러한 프롬프트를 사용함.
4. 응답 후처리
생성된 응답에 대해 후처리 작업을 수행함. 예를 들어, 불필요한 반복 문구를 제거하거나, 문장을 정리해 더욱 자연스럽고 일관된 대화를 제공함.
캐릭터에 따라 비격식체로 변환하거나, 특수문자 및 괄호 안의 내용을 제거하는 등의 처리를 함.
5. 60% 확률로 캐릭터의 추임새 추가
최종 응답을 생성할 때, 캐릭터의 말투와 성격을 반영한 추임새를 60%의 확률로 응답에 추가해 더욱 생동감 있는 대화를 유도함.
현재까지 결과 화면

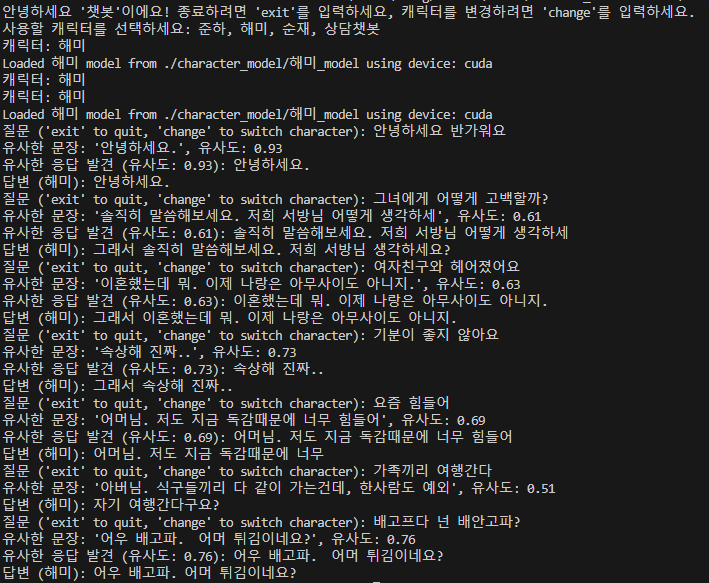

파일 설명
github
https://github.com/doing84/Deep-Learning_Chatbot/tree/main/GPT2
추가 성능 향상 계획
1) 다른 데이터(대본, 소설, 정리된 데이터 등)로 진행해 보기
다양한 출처의 데이터를 사용하여 챗봇의 응답 다양성을 높이고, 보다 폭넓은 상황에 대응할 수 있도록 함. 예를 들어, 영화 대본, 소설, 또는 사용자 리뷰 등의 데이터를 사용해 캐릭터의 반응을 다각화할 수 있음.
2) 현재 챗봇 대답 퀄리티를 향상 시킬 수 있는 전략 마련하기
Reinforcement Learning (강화 학습) 적용: 사용자 피드백을 활용해 모델의 응답을 점진적으로 개선하는 전략을 마련함.
언어 모델의 앙상블: 여러 언어 모델을 결합해 다양한 스타일의 응답을 생성하고, 그중 가장 적절한 응답을 선택하는 방식으로 퀄리티를 향상시킬 수 있음.
Zero-shot 또는 Few-shot Learning 기법 활용: 특정 상황에 대한 응답을 개선하기 위해 훈련 데이터를 추가하지 않고도, 새로운 유형의 질문에 대해 적절하게 대응할 수 있도록 함.
3) 대답에 여러 불필요한(특수문자, 괄호 등) 문자 제거해서 깔끔하게 만들기
텍스트 정제(Text Cleaning) 기능을 강화하여 대답에서 특수문자, 괄호, 이모티콘 등 불필요한 문자나 기호를 제거하고, 깔끔하고 명확한 응답을 제공하도록 함.
4) 기타 추가 전략
정확한 이름 인식 및 대명사 처리: 문맥에 따라 올바르게 대명사나 이름을 처리하여, 캐릭터의 발화가 자연스럽도록 함.
대화 기억 기능 강화: 챗봇이 이전 대화 내용을 일정 부분 기억하고, 문맥을 이해한 상태에서 응답을 생성하도록 함.
사용자 개인화: 사용자의 성향이나 선호에 맞춘 응답을 제공하기 위해 사용자의 대화 스타일을 학습하고 적용함.
응답 다양성 확보를 위한 데이터 증강: Synonym Replacement, Back Translation 등의 기법을 사용해 데이터를 증강하여 챗봇이 보다 다양한 표현과 스타일로 응답할 수 있도록 함.
