 + indeed 페이지 수 받아오기
+ indeed 페이지 수 받아오기
- 각 페이지 URL 생성
- 페이지로부터 일자리 추출
- csv 파일 생성 후, 추출한 job들의 정보 담기
- go channel 통해 동기적으로 데이터 주고 받기
👉 csv 파일 생성 후, 추출한 job들의 정보 담기
받아온 job들의 정보는 csv 파일로 저장해본다.
우선 csv 파일을 새로 생성하기 위해 os패키지의 Create() 메서드를 사용한다.
checkErr(err)만약 vscode에서는 한글이 잘 출력되지만 인코딩 문제로 excel에서 한글이 깨져 보이는 경우
checkErr(err) 밑에 줄에utf8bom := []byte{0xEF, 0xBB, 0xBF} file.Write(utf8bom)를 추가해준다.
CSV 파일을 쓰기 위해서 csv.NewWriter() 를 실행하여 CSV 포맷으로 쓸 수 있는 Writer를 생성하고, 이 Writer로부터 Write() 혹은 WriteAll() 메서드를 호출하여 데이터를 쓴다.
w := csv.NewWriter(file)
headers := []string{"Link", "Title", "Location", "Salary", "Summary"}
wErr := w.Write(headers)
checkErr(wErr)그리고 파일에 데이터를 입력하기 위해 Flush를 호출한다.
defer w.Flush() 여기까지 실행하게 되면 headers의 정보가 담긴 jobs.csv파일이 생성된다.
(만약 VScode에서 생성된 파일이 안보인다면 새로고침을 해본다.)
이제 headers에 맞게 job들의 정보를 입력해야 하는데 headers는 배열이므로 이에 맞는 형식으로 배열을 새로 생성하여 Write한다. 그러면 jobs.csv파일에 job의 정보들이 입력되게 된다.
for _, job := range jobs {
jobSlice := []string{"https://kr.indeed.com/viewjob?jk=" + job.id, job.title, job.location, job.salary, job.summary}
jwErr := w.Write(jobSlice)
checkErr(jwErr)
}👉 go channel 통해 동기적으로 데이터 주고 받기
위의 방법은 getPages()에서 getPage()를 하나씩 호출하는 방식이다.
속도를 높이기 위해 모든 페이지를 한번에 호출하도록 한다.
그리고 getPage()에서 호출하는 일자리에 대한 정보도 한번에 추출하도록 한다.
순서를 정리해보면 처음 main()함수에서 getPages()를 호출한다. getPages()에서 호출하는 getPage() 별로 goroutine을 생성한다. 그리고 getPages()는 각 페이지의 일자리 별로 goroutine을 생성한다.
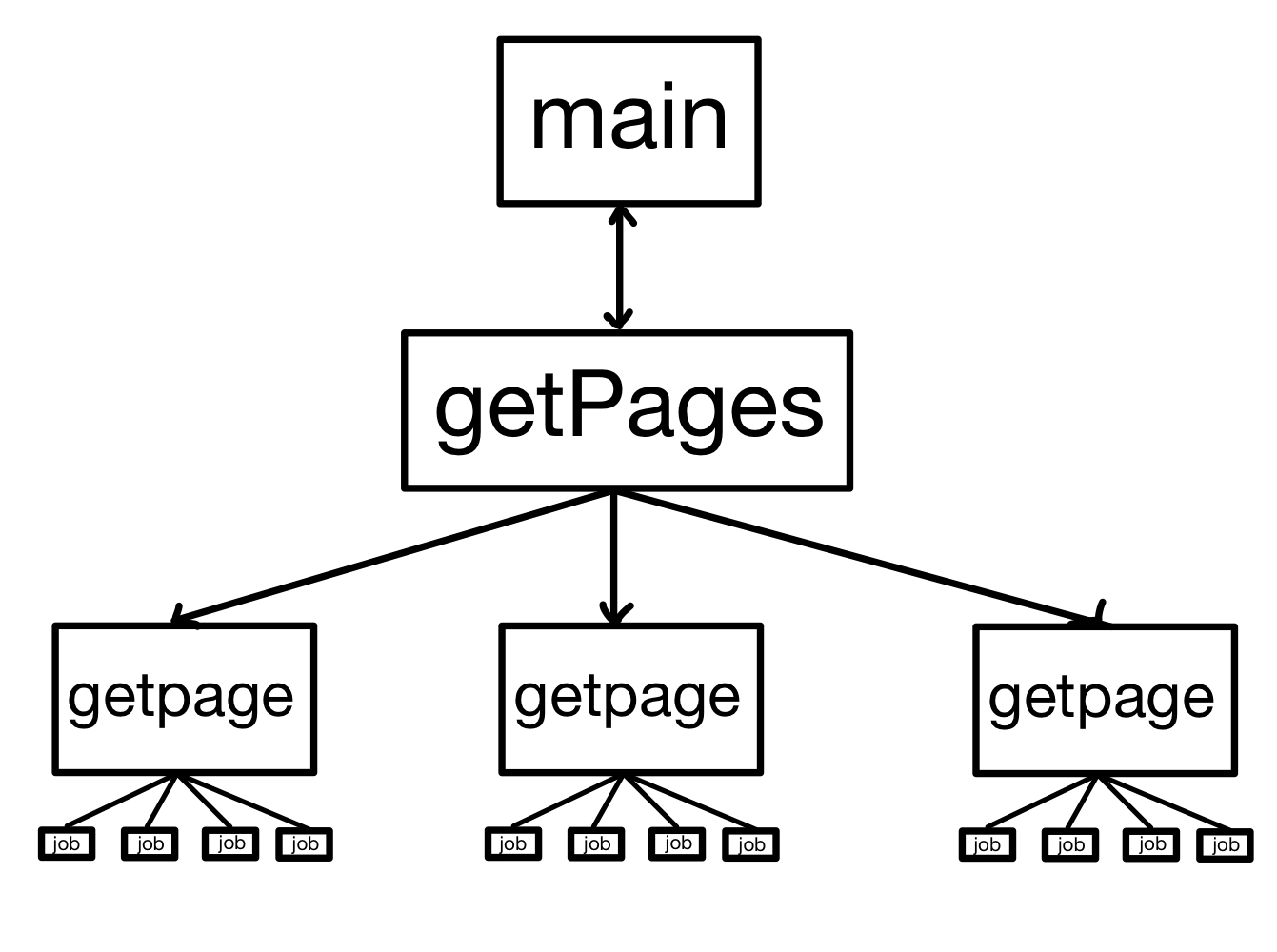
main <-> getpage와 getpage <-> extractJob 이렇게 두 개의 channel이 필요하다.
getpage와 extractJob에서 return을 통해 전달하는 내용을 channel을 통해 메시지로 전달하는 방식으로 변경하면 된다.
전체 코드는 아래와 같다.
package main
import (
"encoding/csv"
"fmt"
"log"
"net/http"
"os"
"strconv"
"strings"
"github.com/PuerkitoBio/goquery"
)
var baseURL string = "https://kr.indeed.com/jobs?q=golang"
type extractedJob struct {
id string
title string
location string
salary string
summary string
}
func main() {
var jobs []extractedJob
c := make(chan []extractedJob) //일자리 정보가 여러개 전달되므로 extractedJob이 아닌 []extractedJob
totalPages := getPages()
for i := 0; i < totalPages; i++ {
go getPage(i, c)
}
for i := 0; i < totalPages; i++ { //전체 페이지 수만큼 메세지가 오기 때문에
//jobs에 일자리를 저장하는 것을 같지만, return값을 받아서 저장하는 것이 아닌 메세지를 통해 받는다.
extractJobs := <-c
jobs = append(jobs, extractJobs...) // extractedJobs를 각각의 배열로 저장하는 것이 아닌 하나의 배열로 만들기 위해 contents를 가져온다. 이때 '...' 이용
}
writeJobs(jobs)
fmt.Println("Done, extracted", len(jobs))
}
func getPage(page int, mainC chan<- []extractedJob) { //하나의 페이지에 있는 일자리 추출
var jobs []extractedJob
C := make(chan extractedJob)
pageURL := baseURL + "&start=" + strconv.Itoa(page*10)
fmt.Println("Requesting", pageURL)
res, err := http.Get(pageURL)
checkErr(err)
checkCode(res)
defer res.Body.Close()
doc, err := goquery.NewDocumentFromReader(res.Body)
checkErr(err)
searchCards := doc.Find(".jobsearch-SerpJobCard")
searchCards.Each(func(i int, card *goquery.Selection) {
go extractJob(card, C)
})
for i := 0; i < searchCards.Length(); i++ { //전달받을 메세지의 수는 카드의 수와 같음.
job := <-C
jobs = append(jobs, job)
}
mainC <- jobs
}
func extractJob(card *goquery.Selection, c chan<- extractedJob) { //카드에서 일자리 정보 추출
id, _ := card.Attr("data-jk")
title := cleanString(card.Find(".title>a").Text())
location := cleanString(card.Find(".sjcl").Text())
salary := cleanString(card.Find(".salaryText").Text())
summary := cleanString(card.Find(".summary").Text())
c <- extractedJob{
id: id,
title: title,
location: location,
salary: salary,
summary: summary}
}
func cleanString(str string) string {
return strings.Join(strings.Fields(strings.TrimSpace(str)), " ")
}
func getPages() int { //총 페이지 수 가져오는 함수
pages := 0
res, err := http.Get(baseURL)
checkErr(err)
checkCode(res)
// 문장에서 에러가 발생하더라도 res.Body를 Close하여 메모리가 새어 나가는것을 막을 수 있다.
defer res.Body.Close()
// query docu 로드
doc, err := goquery.NewDocumentFromReader(res.Body) //res.Body는 기본적으로 byte
checkErr(err)
doc.Find(".pagination").Each(func(i int, s *goquery.Selection) {
pages = s.Find("a").Length() //pagination 클래스 내에 링크 갯수
})
return pages
}
func writeJobs(jobs []extractedJob) { //일자리를 csv파일로 저장하기 위한 함수
file, err := os.Create("jobs.csv") //jobs.csv 파일 생성
checkErr(err)
utf8bom := []byte{0xEF, 0xBB, 0xBF}
file.Write(utf8bom)
w := csv.NewWriter(file) //Writer 생성
defer w.Flush() //함수가 끝날 때 파일에 데이터 입력
headers := []string{"Link", "Title", "Location", "Salary", "Summary"}
wErr := w.Write(headers)
checkErr(wErr)
for _, job := range jobs {
jobSlice := []string{"https://kr.indeed.com/viewjob?jk=" + job.id, job.title, job.location, job.salary, job.summary}
jwErr := w.Write(jobSlice)
checkErr(jwErr)
}
}
// 에러를 계속 체크해줘야 하기 때문에 따로 함수를 만들어서 처리
func checkErr(err error) {
if err != nil { //에러가 있다면
log.Fatalln(err) //프로그램 끝내기
}
}
func checkCode(res *http.Response) { //http.Get()에서 http.Response의 포인터이기 때문에 앞에 * 를 붙여준다.
if res.StatusCode != 200 {
log.Fatalln("Request failed with Status: ", res.StatusCode)
}
}
실행 결과
위의 코드로 실행을 하면 아래와 같이 jobs.csv파일이 생성되고, 엑셀로 이 파일을 열어보면 원하는 정보들을 headers의 맞게 받아오는 것을 볼 수 있다.

끝!!👋👋
