ROLLUP, CUBE
- ROLLUP(A,B) : 자동으로 소계를 구해주는 함수
- 형식
SELECT [조회할 열 이름 1, 2, ... n개]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP[그룹화 열 지정(여러 개 가능)];- 예상 결과 : (A,B), (A), () (n+1개)
ex.
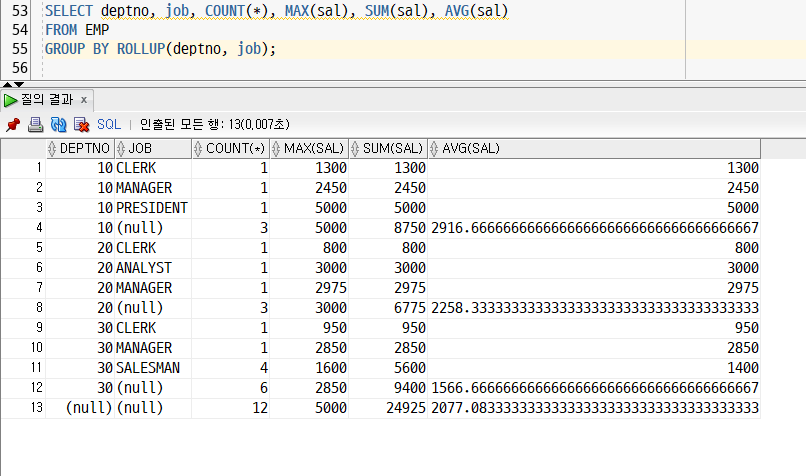
: deptno, job 기준으로 소계 구하고, deptno 기준으로 소계 구하고 마지막에 전체의 소계를 구해줌
- CUBE(A,B) : 자동으로 소계를 구해주는 함수 (모든 열에서 가능한 조합의 결과를 모두 출력)
- 형식
SELECT [조회할 열 이름 1, 2, ... n개]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY CUBE[그룹화 열 지정(여러 개 가능)];- 예상 결과 : (A,B), (A), (B), () (2n개)
ex.
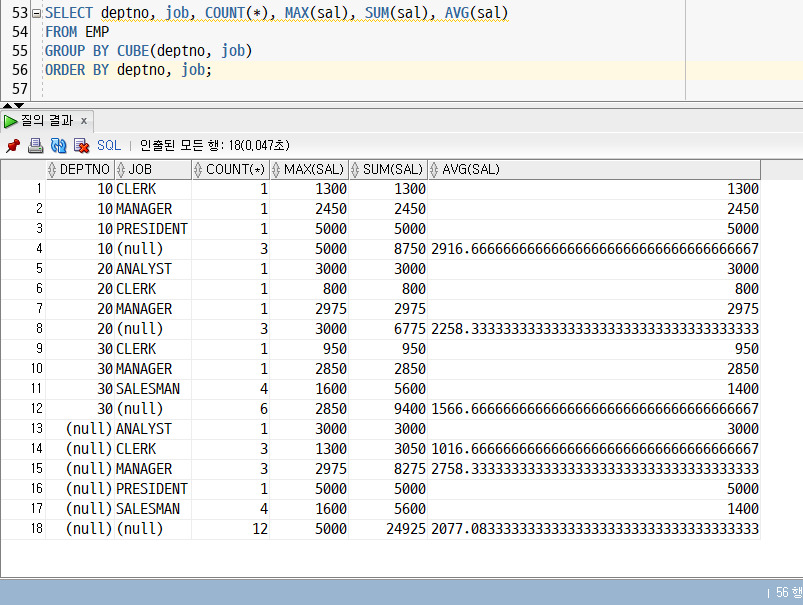
: deptno, job 기준(1), deptno 기준(2), job 기준(3), 전체 기준(4)
- GROUPING SETS(A,B) : 같은 수준의 그룹화 열이 여러 개일 때 각 열별 그룹화를 통해 결과 값을 출력하는 데 사용 (지정한 모든 열을 각각 대그룹으로 처리하여 출력)
- 형식
SELECT [조회할 열 이름 1, 2, ... n개]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY GROUPING SETS[그룹화 열 지정(여러 개 가능)];- 예상 결과 : (A), (B)
ex.
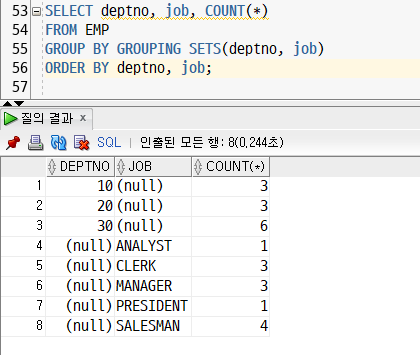
: deptno 기준 (1), job 기준 (2)
-
LISTAGG
: 그룹에 속해 있는 데이터를 가로로 나열할 때 사용
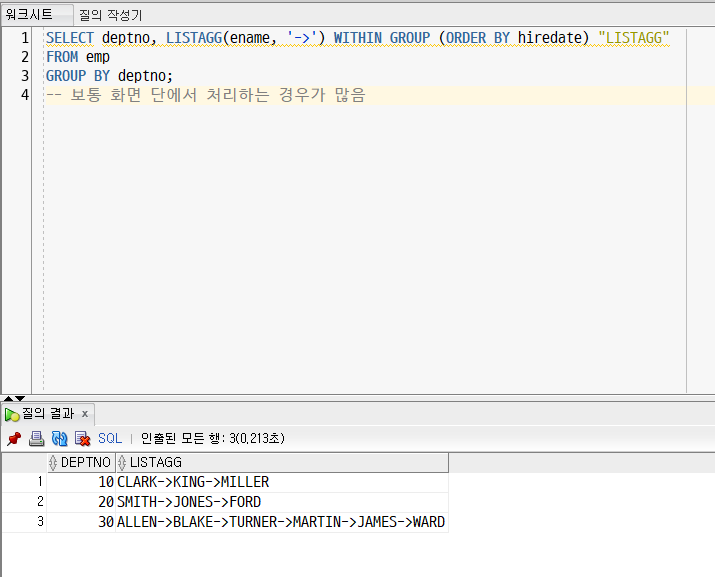
-
PIVOT 함수
5-1. PIVOT 함수 없이 DECODE로 캘린더 만들기
SELECT DECODE(day, 'MON', dayno) MON,
DECODE(day, 'TUE', dayno) TUE,
DECODE(day, 'WED', dayno) WED,
DECODE(day, 'THU', dayno) THU,
DECODE(day, 'FRI', dayno) FRI,
DECODE(day, 'SAT', dayno) SAT
FROM cal;결과
| SUN | MON | TUE | WED | THU | FRI | SAT | |
|---|---|---|---|---|---|---|---|
| 1 | 1 | null | null | null | null | null | null |
| 2 | null | 2 | null | null | null | null | null |
-
UNPIVOT 함수
-
LAG 함수
: 이전 행의 값을 찾을 때 사용
- 형식
LAG(expr [,offset] [,default]) OVER([partition by..] ORDER BY 정렬할 컬럼)
-- offset : 값을 가져올 행의 위치, 기본값은 1
-- default : 값이 없을 경우 기본값, 생략 가능- LEAD 함수
: 다음 행의 값을 찾을 때 사용
- 형식
LEAD(expr [,offset] [,default]) OVER([partition by..] ORDER BY 정렬할 컬럼)
-- offset : 값을 가져올 행의 위치, 기본값은 1
-- default : 값이 없을 경우 기본값, 생략 가능- RANK 함수
- 형식
1. 특정 값의 순위를 알고 싶을 때
RANK(조건값) WITHIN GROUP
(ORDER BY 조건값 컬럼명 [ASC | DESC])
2. 전체 순위
RANK() OVER (ORDER BY 조건컬럼명 [ASC | DESC])
3. 어떤 기준으로 그룹을 묶을건지
ORDER BY 전에 PARTITION BY를 통해서 값 정해줌- 주의
: RANK 뒤에 나오는 데이터와 ORDER BY 뒤에 나오는 데이터는 같은 컬럼이어야 함
-
DENSE_RANK 함수
: RANK와 동일한 역할 but 후순위 안밀림 -
ROW_NUMBER()
: 행 번호를 나타냄 -
SUM() OVER()
- 형식 : OVER 안에서 정렬된 순으로 누적 합계됨
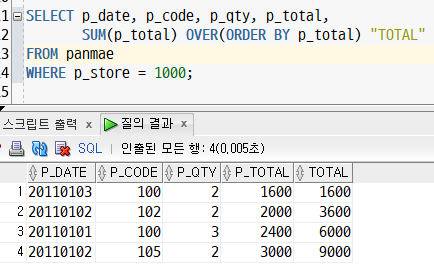
SUM(더하려는 값) OVER ([PARTITION..] ORDER BY 순서 기준이 되는 열ex. 1000번 대리점의 판매 내력 출력, 판매일자, 제품코드, 판매량, 누적 판매 금액을 출력
SELECT p_date, p_code, p_qty, p_total,
SUM(p_total) OVER(ORDER BY p_total) "TOTAL"
FROM panmae
WHERE p_store = 1000;결과
- RATIO_TO_REPORT()
- 형식
RATIO_TO_REPORT(값) OVER(): 비율을 나타내는 함수 (* 100으로 백분율 구하기 가능)
- OVER 함수 (출처 : https://normal11.tistory.com/18)
COUNT(*) OVER() : 전체행 카운트
COUNT(*) OVER(PARTITION BY 컬럼) : 그룹단위로 나누어 카운트
MAX(컬럼) OVER() : 전체행 중에 최고값
MAX(컬럼) OVER(PARTITION BY 컬럼) : 그룹내 최고값
MIN(컬럼) OVER() : 전체행 중에 최소값
MIN(컬럼) OVER(PARTITION BY 컬럼) : 그룹내 최소값
SUM(컬럼) OVER() : 전체행 합
SUM(컬럼) OVER(PARTITION BY 컬럼) : 그룹내 합
AVG(컬럼) OVER() : 전체행 평균
AVG(컬럼) OVER(PARTITION BY 컬럼) : 그룹내 평균
STDDEV(컬럼) OVER() : 전체행 표준편차
STDDEV(컬럼) OVER(PARTITION BY 컬럼) : 그룹내 표준편차
RATIO_TO_REPORT(컬럼) OVER() : 전체 행에서 비율
RATIO_TO_REPORT(컬럼) OVER(PARTITION BY 컬럼) : 현재행값 / SUM(그룹행값) 퍼센테이지로 나타낼 경우 * 100
