서브 쿼리
: SQL문을 실행하는 데 필요한 데이터를 추가로 조회하기 위해 SQL문 내부에서 사용하는 SELECT문
특징
- 연산자와 같은 비교 또는 조회 대상의오른쪽에 놓이며 괄호 ()로 묶어서 사용
- 몇몇 경우를 제외한 대부분의 서브쿼리에서는 ORDER BY 절을 사용할 수 없음!
- 서브쿼리의 SELECT 절에 명시한 열은 메인쿼리의 비교대상과 같은 자료형과 같은 개수로 지정해야함.
- 서브쿼리에 있는 SELECT문의 결과 행 수는 함께 사용하는 메인쿼리의 연산자 종류와 호환 가능해야 함
단일행 서브 쿼리
: 결과값이 하나인 쿼리
: 날짜형일때도 사용 가능
| 단일행 연산자 | 설명 |
|---|---|
| > | 초과 |
| >= | 이상 |
| = | 같음 |
| <= | 이하 |
| < | 미만 |
| <>, ^=, != | 같지 않음 |
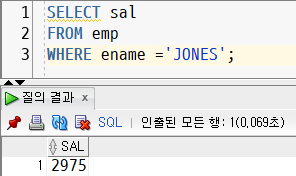
ex. emp 테이블에서 jones보다 급여가 높은 사원을 조회하고 싶은 경우
1. jone의 급여를 알아내는 서브쿼리
SELECT sal
FROM emp
WHERE ename = 'JONES';- 결과
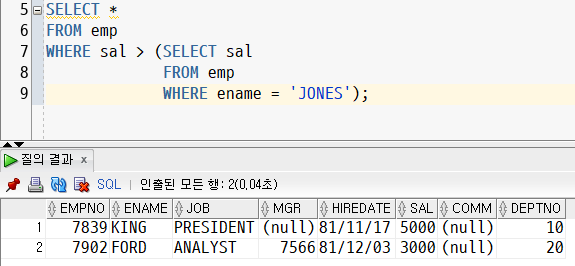
- 그 급여보다 높은 사원을 조회하는 메인쿼리
SELECT *
FROM emp
WHERE sal > (SELECT sal
FROM emp
WHERE ename = 'JONES');- 결과
다중행 서브 쿼리
| 다중행 연산자 | 설명 |
|---|---|
| IN | 메인쿼리의 데이터가 서브쿼리의 결과 중 하나라도 일치한 데이터가 있다면 true |
| ANY, SOME | 메인쿼리의 조건식을 만족하는 서브쿼리의 결과가 하나 이상이면 true (<ANY는 최소, >ANY는 최대) |
| ALL | 메인쿼리의 조건식을 서브쿼리의 결과 모두가 만족하면 true (<ALL는 최소, >ALL는 최대) |
| EXISTS | 서브쿼리의 결과가 존재하면(즉, 행이 1개 이상일 경우) true |
IN 연산자
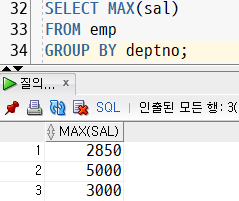
ex. 각 부서별 최고 급여와 동일한 급여를 받는 사원 정보 출력
SELECT *
FROM emp
WHERE sal IN (SELECT MAX(sal)
FROM emp
GROUP BY deptno);- 각 부서별 최고 급여를 뽑는 서브쿼리
- 급여가 서브쿼리의 결과값 중 하나와 일치하는 직원의 정보를 출력
- 그 최고 급여와 동일한 급여를 받는 사원 정보 뽑는 메인쿼리
- 결과

ANY, SOME 연산자
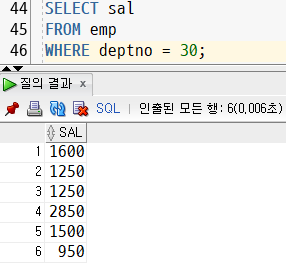
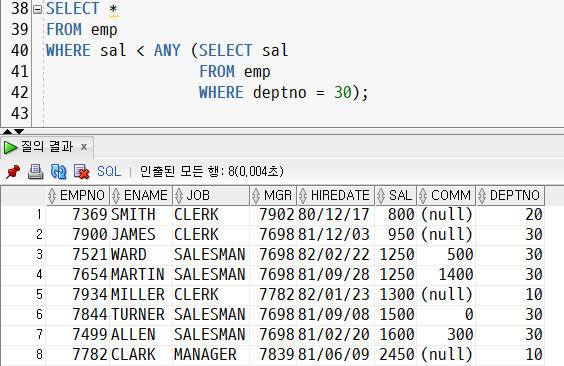
ex. 30번 부서 사원들의 최대 급여보다 적은 급여를 받는 사원 정보 출력
- 30번 부서 사원들의 급여를 출력하는 서브쿼리
SELECT sal
FROM emp
WHERE deptno = 30;- 결과
- 그 급여들보다 적은 급여를 받는 사원을 출력하는 메인쿼리
SELECT *
FROM emp
WHERE sal < ANY (SELECT sal
FROM emp
WHERE deptno = 30)-
다른 급여보다 값이 커도 이 중에 하나의 값보다 작으면 true값이 되기 때문에, 결과적으로 30번 부서 사원들의 급여 중 최대 급여인 2850보다 작은 값들이 출력된다
-
결과
-
결과적으로 서브쿼리에 MAX값을 적용해서, 비교 연산자만 사용한 쿼리와 같은 효과!
SELECT *
FROM emp
WHERE sal < (SELECT MAX(sal)
FROM emp
WHERE deptno = 30);ALL
: 서브쿼리의 모든 결과가 조건식에 맞아떨어져야만 메인쿼리의 조건식이 true가 되는 연산자
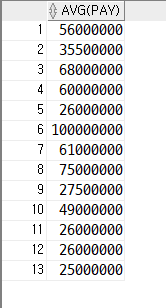
ex. 각 부서별 평균 연봉을 구하고, 그 중에서 평균 연봉이 가장 적은 부서의 평균 연봉보다 적게 받는 직원들의 부서명, 직원명, 연봉을 출력
- 각 부서별 평균 연봉을 구하는 서브 쿼리
-- 서브 쿼리
SELECT AVG(pay)
FROM emp2
GROUP BY deptno결과
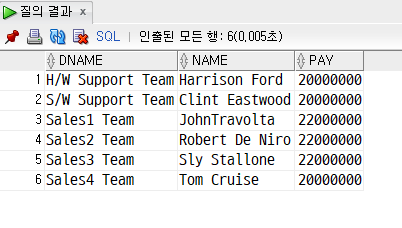
- 그 평균 연봉들보다 연봉을 적게 받는 직원들의 부서명, 직원명, 연봉을 출력하는 메인 쿼리
-- 메인 쿼리
SELECT d.dname, e.name, e.pay
FROM dept2 d, emp2 e
WHERE pay <ALL (SELECT AVG(pay)
FROM emp2
GROUP BY deptno)
AND d.dcode = e.deptno;-
위 값들을 돌면서 모든 값보다 작은 경우에 메인쿼리의 조건식이 true가 됨 (<ALL을 사용했기 때문에 결과가 모두 만족해야함)
-
그리고 그 중에서 deptno가 dept와 emp 모두에 존재하는 값을 뽑아서 보여줌
메인쿼리의 결과 값
EXISTS
: 서브쿼리에 결과 값이 하나 이상 존재하면 조건식이 모두 true, 존재하지 않으면 모두 false가 되는 연산자
: 특정 서브쿼리의 결과 값의 존재 유무를 통해 메인쿼리의 데이터 노출 여부를 결정해야 할 때 간혹 사용
ex.
SELECT *
FROM emp
WHERE EXISTS (SELECT dname
FROM dept
WHERE deptno = 10);- deptno가 10인 사원의 이름이 존재하기만 하면 출력
다중열 서브쿼리 (복수열 서브쿼리)
- 서브쿼리의 SELECT절에 비교할 데이터를 여러개 지정하는 방식
- 메인쿼리에서 비교할 열을 괄호로 묶어 명시, 서브쿼리에서는 괄호로 묶은 데이터와 같은 자료형 데이터를 SELECT절에 명시하여 사용
ex.
SELECT *
FROM emp
WHERE (deptno, sal) IN (SELECT deptno, MAX(sal)
FROM emp
GROUP BY deptno);Scalar Sub Query
: SELECT절에 하나의 열 영역으로서 결과 출력
: 반드시 하나의 결과만 반환하도록 작성
SELECT (Sub Query) : scalar sub query
FROM (Sub Query) : Inline View
WHERE (Sub Query) : SubQueryex.
SELECT empno, ename, job, sal,
(SELECT grade
FROM salgrade
WHERE e.sal BETWEEN local AND hisal) AS salgrade,
deptno,
(SELECT dname
FROM dept
WHERE e.deptno = dept.deptno) AS dname
FROM emp e;계층형 쿼리
-
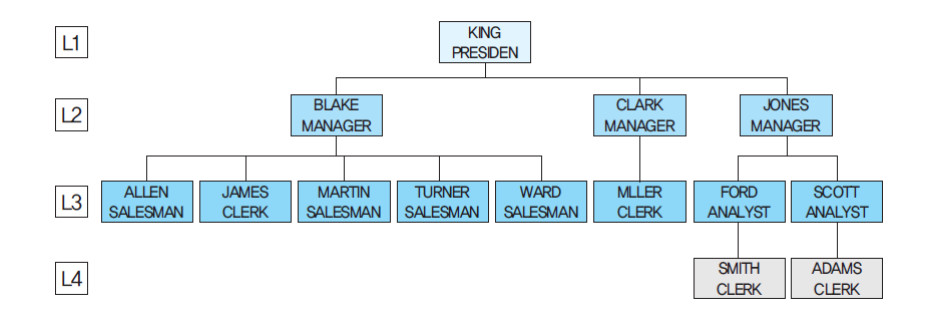
한 테이블에 담겨 있는 여러 레코드들이 서로 상하 관계(부모, 자식) 관계를 이루며 존재할 때, 이 관계에 따라 레코드를 hierarchical(상하위) 한 구조로 가져올 때 사용되는 SQL을 의미
-
형식
SELECT LEVEL(몇 단계인지 조회할 수 있음)
FROM 테이블
WHERE 조건
CONNECT BY 연결조건
START WITH 시작조건
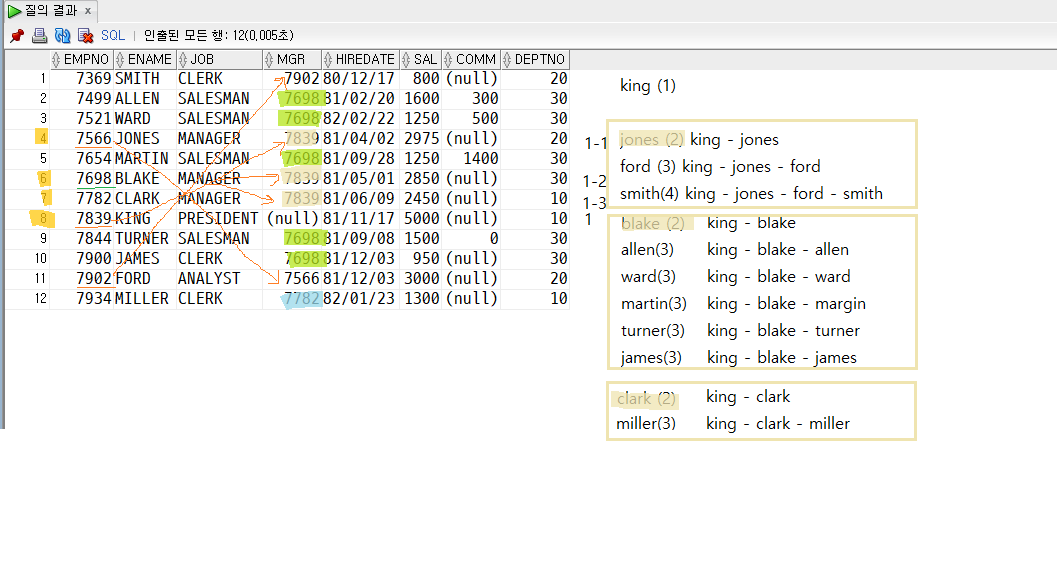
ORDER SIBLINGS BY 같은 level 행들의 정렬을 어떻게 할건지ex.
SELECT empno, ename, job, mgr,
PRIOR ENAME AS mgr_name,
LEVEL (몇 단계인지 조회할 수 있음),
LPAD('', (LEVEL-1)*2, '') || ename AS depth_name,
SYS_CONNECT_BY_PATH(ename, '-') AS ename_list
FROM emp
CONNECT BY PRIOR empno = mgr
START WITH mgr IS NULL
ORDER SIBLINGS BY empno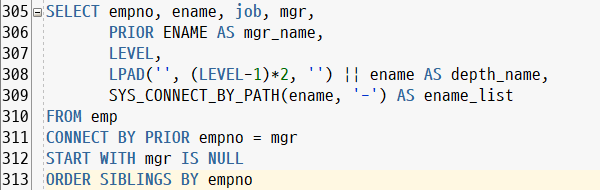
- 주의사항
- CONNECT BY 절에는 Sub Query 를 사용할 수 없음
- 대량의 데이터가 있을 경우에 시간이 오래 걸릴 수 있으므로 START WITH 절과 CONNECT BY 절, WHERE 절의 컬럼에는 반드시 인덱스가 적절하게 설정되어 있어야 함
CONNECT_BY_ISLEAF
- 계층형 쿼리에서 해당하는 로우가 자식노드가 있는지 없는지 여부를 체크, 자식노드가 있을 경우 0 , 자식노드가 없을 경우 1
CONNECT_BY_ROOT
- 계층형 쿼리에서 최상위 노드를 찾고자 할 경우
