
정렬 알고리즘
- simple, slow
1. Bubble sort
2. Insertion sort
3. Selection sort - fast
1. Quick sort
2. Merge sort
3. Heap sort - O(N)
1. Radix sort > 위의 6개의 알고리즘과는 근본적으로 다른 알고리즘
Selection sort 선택정렬
만약 [16, 24, 97, 36, 42]를 선택정렬을 사용해 정렬을 하게 되면
한 루프를 돌때마다 가장 큰값을 뒤로 옮긴다.
첫번째로는 가장 큰값인 97을 가장 맨 뒤에 있는 값인 42와 자리를 변경한다. 그럼 [16, 24, 42, 36, 97]이 되고, 97에대해서는 더이상 신경쓰지 않아도 된다.
두번째로는 97을 제외한 나머지 값들 중 가장 큰 값을 찾아(42) 그 값을 97의 앞에있는 수와 자리를 바꾼다.
그럼 [16, 24, 36, 42, 97] 가 된다. 그리고 42의 앞쪽만 신경쓰면 된다.
세번째로는 42와 97을제외한 나머지 값들중 가장 큰 값인 36을 42의 앞자리의 값과 바꿔주면 되는데 지금 배열에서는 36은 42의 바로 앞에 위치하므로 이동하지 않아도 된다.
네번째로는 36, 42, 97을 제외한 나머지 값을 비교해 큰 값은 36의 앞쪽으로 이동하면 되는데, 24는 36의 앞에있으니 이동하지 않아도 된다.
이렇게 작동하는게 선택정렬이다!
- n개의 값을 가진 배열을 선택정렬로 정렬하려면 n-1번 루프를 돌아야한다.
- 한번의 루프에서 n개의 수 중 가장 큰 수를 찾아야 할때의 비교횟수는 n-1번이다.
그럼 전체 비교횟수를 생각해보면 (n-1)+(n-2)+(n-3)+...+2+1 이다. - 따라서 시간복잡도를 계산해보면 (n-1)+(n-2)+(n-3)+...+2+1 = n(n-1)/2 이므로 시간복잡도는 O(N**2) 이다.
Bubble sort 버블정렬
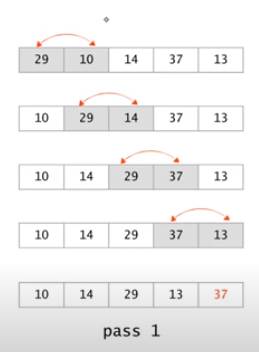
이게 한번의 루프이다.
맨 앞값부터 2개의 값의 대소를 비교해서 앞에있는 값이 더크면 자리를 바꾸게 되고, 결국 가장 큰 값이 맨뒤에 위치하게 된다. n개의 값이 있을때 비교횟수는 n-1번이다.
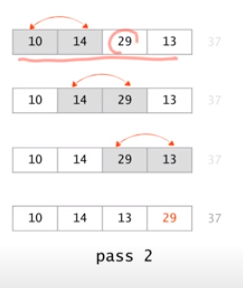
두번째 루프에서는 맨 뒤의 값이 가장 큰 값이므로 그 앞의 값들을 정렬한다.
n-1개의 값을 비교하므로 비교횟수는 n-2이다.
.
.
.
- n개의 값을 가진 배열을 버블정렬을 사용해서 정렬하면 n-1번 루프를 돈다.
- 모든 루프의 비교회수를 더하면 (n-1)+(n-2)+...+2+1이고 이는 선택정렬과 동일하다.
그래서 시간복잡도도 O(N**2)이다.
Insertion sort 삽입정렬
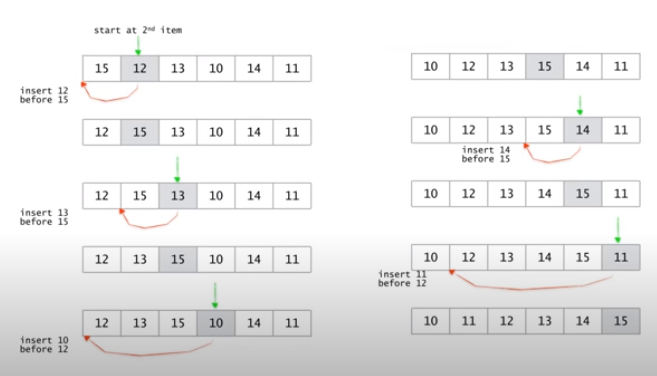
배열을 정렬된 부분과 정렬되지 않은 부분으로 나눈다.
가장 앞부분의 있는 값은 15를 정렬된 부분에 포함시키고, 그 뒷부분을 정렬되지 않은 부분으로 둔다.
정렬되지 않은 부분의 가장 앞에있는값을 정렬된 부분에 넣어주는데, 이때 정렬된 부분의 값들과 비교하며 어디에 값을 넣을지 찾는다.
그래서 배열상에서 n번째 값이 정렬된 부분에 들어갈 때 자신의 앞에 n-1개의 값이 있고, 이 값들과 최대 n-1번의 비교를 통해 자신이 들어 갈 위치를 찾는다.
-그래서 최악의 경우에 시간복잡도는 O(n**2) 이다.
- 버블정렬과 선택정렬과이 차이점은 삽입정렬에서의 시간복잡도는 최악의 경우라는 것이다.
즉, 최선의 경우(처음부터 모든 데이터가 정렬된 상태)에는 각 값들이 정렬된 배열로 들어갈 때 1번만 비교를하면 되므로 시간 복잡도는 O(N)이 된다.
Merge sort 합병정렬
devide&conquer 분할정복법
분할 : 해결하고자 하는 문제를 작은 크기의 동일한 문제들로 분할
정복 : 각각의 작은 문제를 순환적으로 해결
합병 : 작은 문제의 해를 합하여 원래 문제에 대한 해를 구함

- 정렬할 데이터를 반으로 나눔
- 각각을 순환적으로 정렬
- 정렬된 두 개의 배열을 합쳐 전체를 정렬
