
CPU-burst Time의 분포
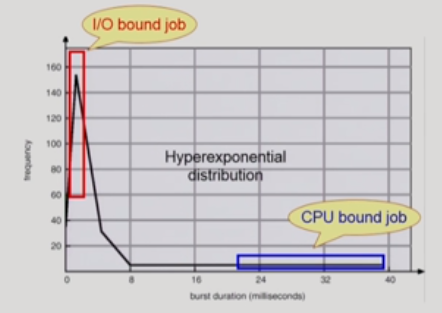
세로축은 빈도, 가로축은 burst duration을 의미함.
프로세스의 특성 분류
프로세스는 그 특성에 따라 다음 두가지로 나눔(위에서 봤던 내용임)
- I/O-bound process
- CPU를 잡고 계산하는 시간보다 I/O에 많은 시간이 필요한 job(many short CPU bursts)
- cpu를 짧게쓰고 중간에 I/O가 끼어드는 종류의 작업 - CPU-bound process
- 계산 위주의 job(few very long CPU bursts)
- cpu를 오래쓰는 종류의 작업
컴퓨터내에는 여러종류의 job(process)이 섞여있기 때문에 CPU 스케줄링이 필요하다.
- Interactive job에게 적절한 response제공 요망
- CPU와 I/O 장치 등 시스템 자원을 골고루 효율적으로 사용
CPU Scheduler & Dispatcher
- CPU Scheduler
- Ready 상태의 프로세스 중에서 이번에 CPU를 줄 프로세스를 고른다.
- Dispatcher
- CPU의 제어권을 CPU scheduler에 의해 선택된 프로세스에게 넘긴다.- 이 과정을 context switch 문맥교화 이라고한다.
- CPU 스케줄링이 필요한 경우는 프로세스에게 다음과 같은 상태변화가 있는 경우이다.
- Running > Blocked (예: I/O 요청하는 시스템 콜)
- Running > Ready (예: 할당시간만료로 timer interrupt)
- Blocked > Ready (예: I/O 완료후 인터럽트)
- Terminate
1, 4에서의 스케줄링은 nonpreemptive(비선점형. 강제로 빼앗지않고 자진 반납)
All other schedulling is preemptive(선점형. 강제로 빼앗음)
Scheduling Algorithms
성능척도(Scheduling Criteria)
스케줄링 알고리즘의 성능을 평가하는 방법
- 시스템 입장에서 성능척도(CPU하나로 최대한 많은일을 하는게 좋은거)
- CPU utilization(이용률)
전체시간중에서 CPU가 놀지않고 일한 시간
keep live CPU as busy as possible - Throughput(처리량)
주어진시간동안 얼마만큼의 양을 처리했느냐
- CPU utilization(이용률)
- 프로그램(고객)입장에서 성능척도(CPU를 빨리얻어서 빨리처리하면 좋은거)
- Turnaround time(소요시간, 반환시간)
CPU를 쓰러들어와서 다쓰고 나갈때까지 걸린시간
(프로세스가 시작되서 종료될때까지의 시간이 아님!!!!)
CPU를쓰러 들어와서 I/O하러 나갈때까지의 총시간! - Waiting time(대기시간)
CPU를 쓰고자할때 레디큐에서 대기하면서 기다리는시간 - Response time(응답시간)
레디큐에 들어와서 처음으로 CPU를 얻기까지 걸린시간 - 대기시간과 응답시간의 다른점
대기시간 - 선점형스케줄링인 경우에는 CPU를 얻었다가 뺐겼다가 다시 얻었다가 뺏겼다가를 반복할수도 있는데, 뺏기면 다시 레디큐에가서 기다릴수도 있게되고, 이때 줄서서 기다린 시간을 다 합친것
응답시간 - 최초의 CPU를 얻기까지 기다린시간
- Turnaround time(소요시간, 반환시간)
FCFS (First-Come First-Served)
- 먼저온 고객에게 먼저 서비스를 제공한다.
- 먼저온 순서대로 처리한다.
- 비선점형 스케줄링! 앞쪽에있는 프로세스가 시간을 오래쓰면 뒤쪽의 프로세스가 인터액티브한 작업이 힘들다
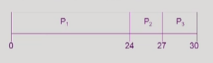
P1은 0초, P2는 24초, P3는 27초를 기다린다.(waiting time)

CPU를 짧게쓰는 프로세스가 먼저 도착하면 평균대기시간은 위의 경우보다 더 짧아진다.
FCFS는 프로세스의 순서에 따라 복불복임
Convoy effect : 앞쪽의 긴 프로세스때문에 뒤쪽의 짧은 프로세스들이 기다려야하는 현상
SJF(Shortest-Job-First)
-
각 프로세스와 다음번 CPU burst time을 가지고 스케줄링에 할당
-
CPU burst time이 가장 짧은 프로세스를 제일 먼저 스케줄
-
Two schemes:
Nonpreemptive
일단 CPU를 잡으면 이번 CPU burst가 완료될때까지 CPU를 선점당하지 않음
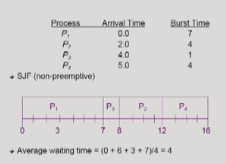
예시가 너무 잘되있어서 가져와봤는데,
P1이 도착한 시점에는 P1밖에없어서 시간이 제일 긴 P1을 실행하지만 P1이 끝난 시점에는 P2, P3, P4 모두 도착해있기때문에 이 중 가장 짧은것부터 실행시킨다.
Preemptive
-
현재 수행중인 프로세스의 남은 burst time보다 더 짧은 CPU burst time을 가지는 새로운 프로세스가 도착하면 CPU를 빼앗김
-
이 방법을 Shortest-Remaining-Time-First(SRTF)라고도 부른다

얘는 실행시키다가 끊고 실행시간이 짧은 것을 실행시킨다!
Nonpreemptive이랑 비교해보면 평균대기시간이 더 짧다!!!!
- SJF is optimal
- 주어진 프로세서들에 대해 minimum average wating time을 보장
그럼 CPU스케줄링에서 이 알고리즘을 쓰는게 제일 좋은가??????
이 스케줄링 알고리즘은 2가지 문제점이 있다
starvation(기아현상) - 극단적으로 CPU사용시간이 짧은 프로세스를 선호한다.
그래서 CPU사용시간이 긴 프로세스를 실행시키지 못하는경우가 발생할 수도있다.
CPU burst time을 미리 알 수 없다 - CPU사용시간을 미리 알수는없지만 추정은 가능하다. 과거의 CPU사용한 흔적을 통해 해당 프로세스의 CPU burst time을 예측한다.
Priority Scheduling
우선순위가 가장 높은 프로세스에게 CPU를 주는 개념
-
각 프로세스마다 우선순위(정수)가 주어지는데, 값이 작을수록 우선순위가 높음
- preemtive : 우선순위가 가장 높은 프로세스에 CPU를 줬는데, 우선순위가 더 높은 프로세스가 도착하면 걔한테 CPU를 준다.
- nonpreemtive : 일단 CPU를 한번 줬으면 더 높은 우선순위가 도착하더라도, 기존의 것을 계속 실행시킴
-
SJF는 일종의 priority scheduling이다
SJF에서의 우선순위는 예측한 CPU burst time이다. -
문제점
Starvation문제 -
해결책
Aging : 기다리는게 길어지면 우선순위를 높여준다.
Round Robin(RR)
현대적인 컴퓨터 시스템에서 사용하는 스케줄링은 RR에 기반하고 있다.
-
각 프로세스는 동일한 크기의 할당시간을 가짐
-
할당시간이 지나면 프로세스는 선점당하고, ready queue의 제일 뒤에 가서 다시 줄을 선다.
-
n개의 프로세스가 ready queue에 있고, 할당시간이 q time unit인 경우 각 프로세스는 최대 q time unit 단위로 CPU 시간의 1/n을 얻는다.
-> 어떤 프로세스도 (n-1)q time unit 이상 기다리지 않는다. -
각 프로세스의 응답시간이 빨라진다. 조금씩 CPU를 사용하기 때문에 모든 프로세스가 조금씩 CPU를 사용할 수 있다.
-
q를 크게잡으면 FCFS랑 같음
-
q를 잘게 하면 context swtich가 빈번히 발생한다 = 오버헤드
-
일반적으로 SJF보다 average turnaround time이 길지만, response time은 더 짧다.
Multilevel Queue

위에있을수록 우선순위가 높음!
프로세스가 줄을 서고, CPU가 하나밖에없다면 여러 줄 중 하나만 빼서 실행할 수 있다.
프로세스를 어느줄에 할당할 것인가를 결정해야함!
계급제도!!
- Ready Queue를 여러개로 분할
- foreground(interactive한 job을 넣는다)
- background(batch - no human interaction 사람과 소통하지않는 job) - 각 큐는 독립적인 스케줄링 알고리즘을 가짐
- foreground - RR
- background - FCFS
큐에 대한 스케줄링이 필요(여러개의 큐가있으면 어느줄에 cpu를 줄까!)
- Fixed prioity scheduling
- serve all from foreground then from background
- Possilbility of starvation - Time slice
- 각 큐에 CPU time을 적절한 비율로 할당
- 80% to foreground in RR, 20% to background in FCFS
Multilevel Feedback Queue
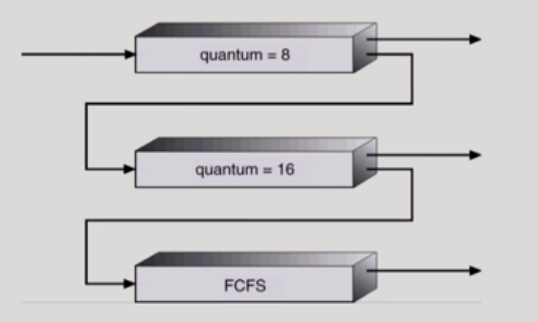
계급이 낮아도 계급을 올릴?수 있음
여러 계급을 왔다갔다할 수 있음
처음 들어온 프로세스는 가장 상위의 큐에 들어가고 할당시간을 짧게준다.
그리고 밑으로 갈수록 할당시간은 길어지고 맨 아래의 큐는 FCFS알고리즘이 적용됨
한 프로세스가 가장 상위에서 할당시간내에 일을 처리못하면 그 밑의 큐로 가게됨! 이런식으로 운영된다.
- 프로세스가 다른 큐로 이동가능
- 에이징을 이와 같은방식으로 구현할 수 있다.
- Multilevel-feedback-queue scheduler를 정의하는 파라미터들
- Queue의 수
- 각 큐의 scheduling algorithm
- Process를 상위큐로 보내는 기준
- Process를 하위큐로 내쫒는 기준
- 프로세스가 CPU 서비스를 받으려 할 때 들어갈 큐를 결정하는 기준
위에는 CPU가 하나밖에 없는 시스템이었다!
Multiple-processor scheduling
- CPU가 여러개인 경우 스케줄링은 더욱 복잡해짐
- Homegeneous processor인 경우
- queue에 한줄로 세워서 각 프로세서가 알아서 꺼내가게 할 수 있다.
- 반드시 특정 프로세서에서 수행되어야하는 프로세스가 있는 경우에는 문제가 더 복잡해짐
- Load sharing
-일부 프로세서에서 jib이 몰리지 않도록 부하를 적절히 공유하는 메커니즘이 필요함
- 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
- Symmetric Multiprocessing(SMP)
- 각 프로세서가 각자 알아서 스케줄링을 결정
- 모든 CPU가 대등함!
- Asymmetric multiprocessing
- 하나의 프로세서가 시스템데이터의 접근과 공유를 책임지고 나머지 프로세스는 거기에 따름
- 여러 CPU중 하나의 대장?CPU가 나머지 CPU를 관리
Realtime Scheduling
- Hard realtime scheduling
- 정해진 시간안에 반드시 끝내도록 스케줄링해야함
- Soft realtime scheduling
- 일반 프로세스에 비해 높은 priority를 갖도록 해야함
Thread Scheduling
- Local scheduling
User level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케줄할지 결정
-운영체제는 스레드를 모름 > 운영체제는 프로세스단위로 cpu를 줄지말지 결정하고 프로세스내부에서 스레드에 cpu를 줄지말지 결정
- Global scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬 가지로 커널의 단기 스케줄러가 어떤 thread를 스케줄할지 결정- 운영체제가 스레드의 존재를 알고있음
- 프로세스 스케줄링하듯이 스레드에게 cpu를 줄지 결정함!
알고리즘 평가방법
- Queueing models
- 확률 분포로 주어지는 arrival rate와 service rate등을 통해 각종 performance index값을 계산
- Implementation(구현) & Measurement(성능 측정)
- 실제 시스템에 알고리즘을 구현하여 실제작업에 대해서 성능을 측정 비교
- Simulation(모의 실험)
- 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과 비교
