연산자와 피연산자
- 연산자 : 연산을 수행하기위한 기호 (
+ - * / %...) - 피연산자 : 연산자의 작업대상 (
변수, 상수, 리터럴, 다른 식)
x + 3;
/*
x,3 : 피연산자
+ : 연산자
*/Java 의
연산자는언제나 연산 결과 값을 리턴한다.
식(Expression) 과 대입 연산자
식은 결과 값을 반환해야하며, 문은 결과 값을 반환하지 않는다.
- 식(Expression) 이란 프로그램 구조에 따라 제어문이 될 수도 있고(Kotlin..), 연산식의 조합이 될 수도 있다.
- 문장(Statement) 이란 프로그램에 작성하는 하나의 문장을 말한다.
- 문 이란 보통 프로그램 흐름 제어를 위한 문법을 이야기한다.
4 * x + 3 // 식, 연산식의 조합으로 이루어진 "연산의 표현 자체"
4 * x + 3; //문장, 프로그램에 작성하는 하나의 문장. 보통 "식"이라고 표현
if () {...} else {...} // 문, 프로그램 흐름제어를 위한 문법식은 언제나 결과 값을 반환한다.
식(Expression)은 언제나 결과 값을 반환하므로, 결과 값을 저장할 변수 없이는 쓸모 없는 문장이 되는 경우가 많다.식의 결과를 함수의 인자로 넘기고자 한다면, 식 자체를 인자로 주면 결과 값이 인자로 사용되므로 문제 없다.
int x = 5;
int y;
// 개발도구에서는 expression 이라고 판단하고, statement 가 아니라는 에러 발생
4 * x + 3; // 의미 없는 문장, 결과 값을 어느 곳에서도 사용하지 않고 있다.
y = 4 * x + 3; // statememt, 결과 값을 저장할 변수가 있다.
Math.max(4 + i + 3, 4 % i + 3);연산자의 종류
연산자를 기능으로 나누면 다음과 같다.

연산자의 기능 분류는
산술,비교,논리,대입으로 나눌 수 있다.
연산자를 피연산자의 수로 나누면 다음과 같다.
단항,이항,삼항표로 표현할 수 있으나, 보면 오히려 기능분류와 겹쳐서 햇갈린다.
int result;
result = -3 - 5; // 여기서의 연산자는 2개, 단항과 이항으로 나뉜다.
// 연산순서 : 단항 > 이항
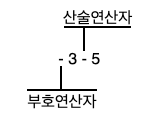
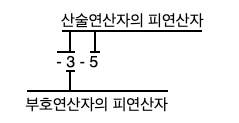
연산자의 우선순위를
기능,피연산자 수로 나누는 이유는 "연산자의 결합규칙" 때문이다.
연산자의 우선순위
식에 사용된 연산자가 2개 이상일 경우, 연산자의 우선순위에 따라 연산 순서가 결정된다.
보통 복잡하지않은 연산 규칙을 가진다.
단항 > 이항 > 삼항
산술 > 비교 > 논리 > 대입

연산자의 우선순위에 상관 없이 먼저 계산을 진행하려면
()괄호를 기입하면 되기 때문에,더 명시적인 코드를 만들 수 있다.
즉, 순서의 암기 여부가 크게 중요하지는 않다.
연산자의 연산 방향
하나의 식에 연산 순위가 같은 연산자가 2개 이상 있을 경우 연산의 규칙은 연산자의 결합 규칙 에 따라 결정된다.
"단항연산자"와 "대입 연산자"를 제외한 모든 연산자의 결합규칙은
왼쪽에서 오른쪽이다.
1. 단항, 대입 : <-
2. 이외의 연산자 : ->
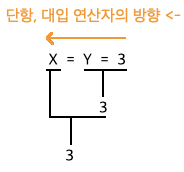
여기서 이해하기가 좀 어려웠던게, x = y =3 의 3이라는 결과가 좌항의 값을 우항의 값에 대입하라는 대입연산자의 의미랑 일치하는 건지 의아했다.
int x, y;
// 함수의 인자가 주어져야하므로 println() 함수에 3이 찍힌다면, 대입연산자는 "대입한 값을 리턴"한다는 것임
System.out.println(y = x = 3);// 3즉, 대입 연산자는 우항의 값을 좌항에 저장하고, 저장한 값을
연산결과로 반환하는 연산자임.
Java 의 모든 연산자는 연산결과를 반환한다.
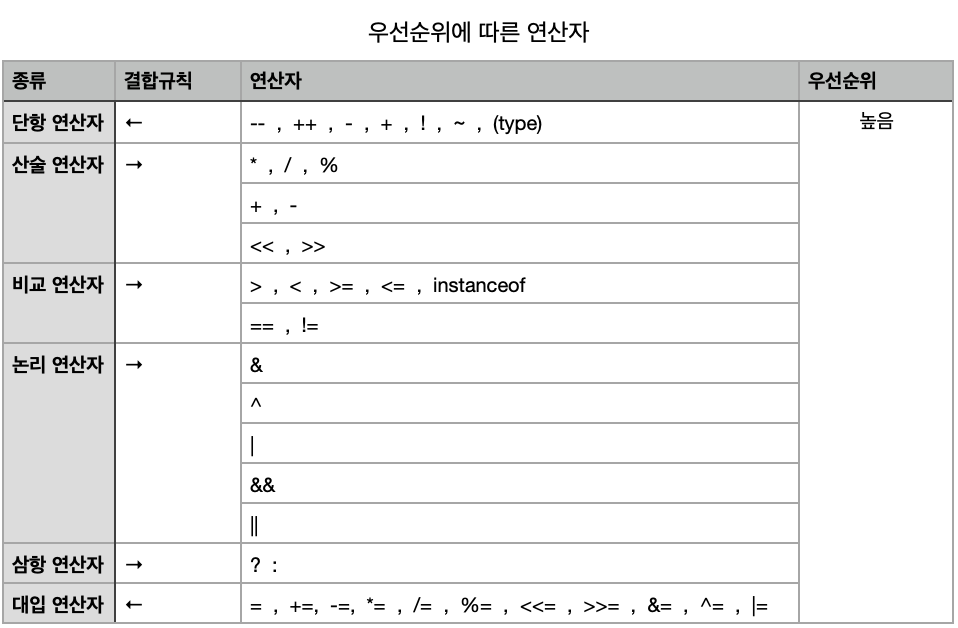
연산자 총 정리
단항 < 이항 < 삼항
산술 < 비교 < 논리 < 대입대입, 단항 연산자를 제외한 모든 연산자의 결합규칙 :
->
대입, 단항 연산자의 결합규칙 :<-
산술변환
산술 변환은 저번 정리에서 정리 했으나, 놓칠 수 있는 점을 기록한다.
int / int => int
즉, 몫 & 나머지 연산에서 피연산자가 모두 int 타입이라면 결과 값의 타입도int타입이다.
- 소수점 이하는 버린다.
해당 문제를 해결하기위해서는 피연산자 중 하나의 타입을 실수 타입으로 변환하면 된다. 자동으로 산술 연산이 일어나서 피연산자 모두 실수타입으로 변환되므로 결과 값도 실수 타입이 반환된다.
int x = 5, y = 2;
System.out.println(x / y); // 2 , 2.5 에서 소수점 이하는 버려졌다.
System.out.println(x % y); // 1
System.out.println(x / (double) y); // 2.5
System.out.println(x % (double) y); // 1.0증감 연산
증감 연산자는 정수, 실수타입의 값을 1 만큼 증가시키거나 감소 시킨다. 하지만, 상수 는 한번 초기화하면 값을 재할당 할 수 없으므로 증감연산자를 상수에 적용할 수는 없다.
public static void main(String[] args) {
final int INT_VALUE = 10; // 상수는 값에 의미있는 이름을 적용하기 위해 사용한다.
final double DOUBLE_VALUE = 1.0;
int intValue = 10; // 로컬 변수는 반드시 초기화한다.
double doubleValue = 1.0;
// printf() 함수의 첫 번째 인자는 지시자를 포함한 문자열, 두 번째 인자는 지시자로 변환 될 값이다.
System.out.printf("intValue : %d , doubleValue : %15.14f", ++intValue, --doubleValue);
//intValue : 11 , doubleValue : 0.00000000000000
// 상수는 한번 값을 할당하면 값을 바꿀 수 없으므로, 증감연산도 불가능하다.
++INT_VALUE; // Cannot assign a value to final variable 'INT_VALUE'
--DOUBLE_VALUE; // Cannot assign a value to final variable 'DOUBLE_VALUE'
}증가 연산자(++) : 피연산자의 값을 1 증가
감소 연산자(--) : 피연산자의 값을 1 감소
증감연산자의 산술변환 여부
- 증감 연산자는 연산 중 "산술변환이 발생하지 않는다". 연산 후에도 타입이 유지된다.
byte b = 1;
byte bResult = ++b; // 증감 연산에는 산술변환이 발생하지 않아, 타입이 유지된다.증감 연산자는 피연산자의 값을 변경시킨다.
증감 연산자와대입 연산자만 피연산자의 값을 변경시킨다.
byte b = 1;
System.out.println(b = 127); // 대입연산자가 피연산자 b 의 값을 변경시켰다.
++b;// 증감연산자는 산술변환이 일어나지 않으므로, 오버플로우가 발생한다.
System.out.println(b); // 증걈연산자가 피연산자 b 의 값을 변경시켰다.
/*
127
-128
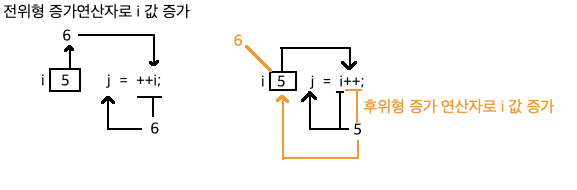
*/prefix 와 postfix
증감 연산자는 "단항 연산자" 이며, 보통 단항 연산자는 피연산자 앞에 기술하지만 증감 연산자는 피연산자의 앞과 뒤 모두 기술 할 수 있다.
여기서 중요한 점은, "참조" 전과 후로 나뉜다는 것이다.

public class OperatorEx1 {
public static void main(String[] args) {
int i = 5;
i++;
System.out.println(i); // 6
i = 5;
++i;
System.out.println(i); // 6
int result = 0;
i = 5;
result = i++;
System.out.printf("result : %d , i : %d%n",result,i);
i = 5;
result = ++i;
System.out.printf("result : %d , i : %d%n",result,i);
i = 5;
result = defineValue(i++);
System.out.println("Method Parameter Value : " + i);
i = 5;
result = defineValue(++i);
System.out.println("Method Parameter Value : " + i);
}
//call by value
private static int defineValue(int value) {
System.out.println("defaultValue, Method reference parameter : "+value);
return value;
}
}
/**
6
6
result : 5 , i : 6
result : 6 , i : 6
defaultValue, Method reference parameter : 5
Method Parameter Value : 6
defaultValue, Method reference parameter : 6
Method Parameter Value : 6
*/
call by value방식에서는 변수의 값 만을 참조한다.이를 바탕으로 보면
전위형 증감 연산자가변수의 값을 불러오기 전에 증감을 시킨다는 것을 알 수 있다.
부호 연산자
부호연산자는 "단항 연산자"이며, - 와 +로 나뉜다. 실질적으로 쓰는 부호 연산자는 - 뿐이다.
-: 숫자형 타입의 부호를 반전 시킨다.(양수 - 음수)
숫자로 표현할 수 없는 boolean , 양수만 표현하는 char 를 제외한 모든 숫자형 타입에 적용가능
- 정수, 실수형 타입에 모두 적용가능
public static void main(String[] args) {
int i = -10;
i = +i; // 그대로 부호를 놔둠
System.out.println(i);
i = -i; // 부호 연산자 - 는 부호 반전 연산자
System.out.println(i);
/**
* -10
* 10
*/
}산술 연산자
연산의 우선순위는 사칙연산과 동일하며, 연산의 결합 규칙은 -> 이다.
public static void main(String[] args) {
int a = 10;
int b = 4;
System.out.printf("%d + %d = %d%n", a, b , a+b);
System.out.printf("%d - %d = %d%n", a, b , a-b);
System.out.printf("%d * %d = %d%n", a, b , a*b);
System.out.printf("%d / %d = %d%n", a, b , a/b);
System.out.printf("%d %% %d = %d%n", a, b , a%b);
System.out.printf("%d / %2.1f = %2.1f%n", a, (float) b , a / (float) b);
System.out.printf("%d %% %2.1f = %2.1f%n", a, (float) b , a % (float) b);
/**
10 + 4 = 14
10 - 4 = 6
10 * 4 = 40
10 / 4 = 2
10 % 4 = 2
10 / 4.0 = 2.5
10 % 4.0 = 2.0
*/
}
산술 변환으로인하여int로 변환된 피연산자 간의몫이나나머지연산은결과 값이 int 타입이므로 소수점을 버린다.
int / int -> int
int % int -> int
int 타입의 피연산자중 하나의 피연산자의 타입을실수형으로 캐스팅하면,산술 변환이 일어나 두 피연산자가 더 큰 타입인실수형으로 프로모션된다. [ 캐스팅 연산자는 "단항 연산자"이므로 우선순위가 높다]
int / (float) int -> int / float -> float / float -> float
int % (float) int -> int % float -> float % float -> float
나누기 연산자
나누기 연산은 /[몫] , %[나머지] 로 나뉜다. 0 으로 나누면 산술연산 예외가 발생하며 0.0 으로 나누면 Infinity 가 도출된다. % 연산은 배수 & 짝수 & 홀수 검사에 자주 사용한다.
value % 2 == 0: 짝수 검사
value % 2 != 0: 홀수 검사
value % n == 0: n의 배수 검사나머지 연산은 음수로도 나눌 수 있지만, 나누는 수의 부호는 무시한다.
System.out.println(10 % -8); System.out.println(10 % 8); //똑같이 2
산술 연산 예외 (java.lang.ArithmeticException)
자바의 예외 중 하나로, 산술연산의 잘못된 연산 시 발생한다.
피연산자가 정수형일 경우0 으로 나누게 되면ArithmeticException이 발생한다.
int x = 0;
//Exception in thread "main" java.lang.ArithmeticException: / by zero
System.out.println( 10 / x );
System.out.println( 10 % x );Infinity
피연산자가 정수형일 경우 0.0 으로 나누게 되면 예외가 발생하지 않고 Infinity가 도출된다.
이외에도 NaN(Not a Number) 가 있는데, 기준 상 크게 중요하지 않으므로 넘어간다.
double y = 0.0;
System.out.println( 10 / y);
System.out.println( 10 % y );
/**
* Infinity
* NaN
*/연산결과에 따른 타입 선택
형변환 항목에서 다룬 내용과 다소 겹친다.
산술 변환으로 인하여 int 보다 작은 타입의 피연산자 간의 연산의 경우, int 타입으로 자동 형변환된다.
int * int -> int이므로, int 보다 작은 타입에 대입하기 위해서는명시적 형변환[캐스팅]이 필요하다.
byte a = 10;
byte b = 30;
byte c = a * b; // 에러
// 원한다면 명시적 형변환을 해야한다.
byte c = (byte) (a * b);
System.out.println(c); // 44, 값 손실명시적 형변환을 진행해도 "결과값인 300 은 byte 의 표현범위를 벗어나므로"
값 손실이 발생한다.
오버플로우에 대한 연산 순서 고려
해당 연산은 이미 오버플로우가 발생한 상태에서 long 타입 변수에 결과 값을 대입하고 있다.
피연산자는 int 타입이므로, 연산의 결과도 int 타입이기 때문에 int 가 표현할 수 있는 값을 넘어섰기 때문에 결과값은 오버플로우가 발생한 쓰레기 값이 된다.
int value1 = 1_000_000;
int value2 = 2_000_000;
long result = value1 * value2;
System.out.println(result); //-1454759936산술연산의 진행과정을 고려한다면, 피연산자 중 하나의 타입을 long 타입으로 캐스팅해주면 된다.
int value1 = 1_000_000;
int value2 = 2_000_000;
long result = (long) value1 * value2;
System.out.println(result); //2000000000000
long result1 = 1_000_000 * 2_000_000;
long result2 = 1_000_000 * 2_000_000L;
System.out.printf("result1 : %d%n",result1);
System.out.printf("result2 : %d%n",result2);
/**
* result1 : -1454759936
* result2 : 2000000000000
*/
int * int :
int[쓰레기 값]
long * long :long[결과 값 보존]
똑같은 의미의 식이라도, 연산 순서에 따라 다른 값이 도출될 수 있다.
// 연산자의 결합규칙에 따라서, 몫연산을 먼저 실행한 식은 int가 표현할 수 있는 범위의 값이다.
int result3 = value1 * value1 / value1;
int result4 = value1 / value1 * value1;
System.out.println(result3);
System.out.println(result4);
/**
* -727
* 1000000
*/문자형 타입의 산술연산
문자형은 리터럴이 변수에 저장될 때 유니코드 인코딩이 되므로, 정수형 리터럴과 저장형식이 같다.
그러므로, 문자타입에 산술연산이 가능하다. 보통 문자형 간의 빼기를 많이한다.
'2' - '0' -> 50 - 48 ->
숫자 2
- 문자형의 숫자 -> 정수형 : '0' 을 빼면 됨
- 정수형의 숫자 -> 문자형 : '0' 을 더하면 됨
유니코드의 a ~ z, A ~ Z, 0 ~ 9 는 순차적으로 배치되어있기 때문에 해당연산이 가능하다.
리터럴과 상수의 연산
리터럴 , 상수는 프로그램 내에 "고정된 값"을 가지고 있다.
리터럴과 상수의 값은 런타임에 변동되는 값이 아니므로 연산 시 "컴파일러가 미리 계산"하여 결과로 바로 변환한다. 그러므로, 상수와 리터럴 간의 계산은 런타임 시에 수행되지 않는다.
char ch = 'a';
final char CH = 'a';
//char ch1 = ch + 1; // 산술 변환 발생으로 명시적 캐스팅이 필요
char ch1 = 'a' + 1; // 리터럴 & 상수는 프로그램 내에 고정된 값이므로, 컴파일러가 결과 값을 계산해서 식을 대체한다.
// char ch1 = 'b';
ch1 = CH + 1; // 리터럴 & 상수는 프로그램 내에 고정된 값이므로, 컴파일러가 결과 값을 계산해서 식을 대체시킨다.
// ch1 = 'b';중요한 점 :
상수와 리터럴 간의 연산은컴파일 시점에 연산이 완료되므로, 실행 시 성능에 영향을 끼치지 않는다.int dayToSec = 60 * 60 * 24; // 이렇게 선언해도 컴파일 시점에 연산이 끝나서 런타임에 성능 변화가 없음.
60 * 60 * 24 라는 식이 나중에 "값을 바꿀 때"와 "읽을 때" 둘 다 좋다. 런타임에 성능 변화도 없다.
상수에 리터럴을 저장할 때에 리터럴을 연산 식으로 풀어서 쓰는 것이 좋을 때가 있다.
