
목표
- Docker 활용 하둡 클러스터 구성하기
- 클러스터 구성 - Master1, Worker1, Worker2
(여기서 Worker는 작성자에 따라 Slave로 쓰기도 한다.)
개요
원래는 다른 서버에 데이터노드와 네임노드를 만들어야한다고 한다. 나는 한 서버에 돌려야하기 때문에,hadoop이 돌아갈 OS(Ubuntu)를 Docker로 돌리고 그 위에서 환경설정을 해주었다.
클러스터 구축
서버 환경
| Environment | Version |
|---|---|
| OS | Ubuntu 22.04.2 LTS |
| Hadoop | Hadoop-3.2.3 |
| Docker | Docker version 23.0.1 |
BASE 설치 및 환경 설정
Ubuntu 컨테이너 실행
docker run -i -t --name hadoop-base ubuntuUnable to find image 'ubuntu:latest' locally가 떠도 된다. 알아서 docker hub에서 해당 이미지를 pull해서 가져온다.
실행된 bash에서는 Ctrl + P + Q로 컨테이너 종료없이 빠져나올 수 있다. 기억하자.
command 설치
apt-get update
apt-get upgrade -y
apt-get install -y curl openssh-server rsync wget vim iputils-ping htop openjdk-8-jdk sshHadoop 다운로드 및 압축해제
# 현재 위치에 hadoop 압축파일을 받는다.
wget http://mirror.navercorp.com/apache/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
# 압축해제
tar zxvf hadoop-3.2.3.tar.gz
# 남아있는 입축 파일 삭제
rm hadoop-3.2.3.tar.gz
# 압축 해제한 hadoop 폴더 이동
mv ./hadoop-3.2.3 /usr/local/hadoop/미러사이트에서 원하는 하둡 버전을 받는다. 미러사이트는 다음과 같은 곳이 있다. 공식문서에서 가이드하는 사이트는 apache의 미러사이트다.
http://mirror.navercorp.com/apache/hadoop/common/
http://apache.mirror.cdnetworks.com/hadoop/common/
환경변수 셋팅
vi ~/.bashrc 위의 ~은 현재 사용자의 홈 디렉토리를 나타낸다. root는 /root 디렉토리가, 다른 사용자는 보통 /home/{username}의 경로를 가진다.
현재 별도의 유저 생성 및 이동을 거치치 않았기 때문에 /root/.bashrc의 파일이 열렸을 것이다.
열린 파일의 하단에 다음을 덧붙인다.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib" :wq으로 파일을 저장하고 다음 명령어를 실행하여 작성한 환경변수를 적용시킨다.
source ~/.bashrc👏 notice 1
환경에 따라 이후 기술되는WARN util.NativeCodeLoader에 대해 HADOOP_OPTS 환경변수를 수정할 수 있다. 일단 알아두자.
👏 notice 2
이후 복사/붙여넣기 할 일이 많은데, vim 편집기를 열고나면 docker-vim 편집기 클립보드가 따로 인식되는지ctrl+v도shift+insert도 안먹는 경우가 있다.
본인은docker cp {filepath} {container}:{filepath}명령어와 vim의nyy(n은 숫자)단축키를 활용하여 해결하였다. 참고 바람~
core-site.xml 세팅
vi $HADOOP_HOME/etc/hadoop/core-site.xml
# 다음 작성 후 :wq로 나오기
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master1:9000</value>
</property>
</configuration>yarn-site.xml 세팅
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 다음 작성 후 :wq로 나오기
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>mapred-site.xml 세팅
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml
# 다음 작성 후 :wq로 나오기
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>masters 세팅
masters 파일이 없을 수도 있다. 그냥 작성한다.
vi $HADOOP_HOME/etc/hadoop/masters
# 다음 작성 후 :wq로 나오기
master1workers 세팅
master와 worker로 사용한 컨테이너를 적는다.
나는 vi $HADOOP_HOME/etc/hadoop/workers를 입력하면 localhost가 한 줄 적혀있었는데, 지우고 다음을 적었다.
vi $HADOOP_HOME/etc/hadoop/workers
# 다음 작성 후 :wq로 나오기
master1
worker1
worker2master, worker 컨테이너 생성
공통 환경 설정이 끝났다. exit로 호스트로 돌아간다.
이미지 커밋
대상 컨테이너를 바탕으로 이미지를 만든다.
# 이미지를 만들 hadoop-base의 컨테이너 아이디를 확인한다.
docker ps -a
# 해당 컨테이너 ID를 넣고 이미지를 만든다. 대략 5~10초 소요된다.
docker commit -m "hadoop install in ubuntu" <container id> ubuntu:hadoop컨테이너 생성
root 권한 필요. 이후 각 컨테이너마다 해야할 일 이 있기때문에, 실행 후 매번 Ctrl+P+Q로 빠져나온다.
포트번호 설정은 왜 이렇게 한 건지 필요성이 있는지 잘 모르겠다..
docker run -i -t -h master1 --name master1 -p 29870:9870 -p 28088:8088 -p 29888:19888 ubuntu:hadoop
docker run -i -t -h worker1 --name worker1 --link master1:master1 ubuntu:hadoop
docker run -i -t -h worker2 --name worker2 --link master1:master1 ubuntu:hadoop컨테이너 ip 확인 및 host 설정
출력되는 텍스트에서 IPAddress를 확인한다.
docker inspect master1 (172.17.0.4)
docker inspect worker1 (172.17.0.5)
docker inspect worker2 (172.17.0.6)각각 컨테이너 bash로 접속해서 다음을 추가한다.
나의 경우 일부 작성된 부분이 있어서 없는 부분만 작성해주었다.
docker attach {container name}
vi /etc/hosts
<IP주소> master1
<IP주소> worker1
<IP주소> worker2master, worker ssh 키 생성
worker끼리 서로 ssh로 통신이 가능하도록 하기 위해, public key를 생성하여 잘 보관해주기로 한다.
다음 작업은 세 컨테이너 모두에서 이뤄져야한다.
Key 생성
# 키 생성. 키 파일 위치와 passphrase를 묻는다. 전부 엔터로 넘어감.
ssh-keygen -t rsa
Key 복사
각 키를 출력해보면 끝에 root@master1와 같이 어떤 사용자로 어떤 컨테이너에 접속 가능한지 나타나있다.
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
cat ~/.ssh/authorized_keysKey 등록
각 컨테이너에서 복사한 public key를 authorized_keys 파일에 저장한다.
vi ~/.ssh/authorized_keys접속 확인
# 각 컨테이너에서 다음 모두 확인
ssh master1
ssh worker1
ssh worker2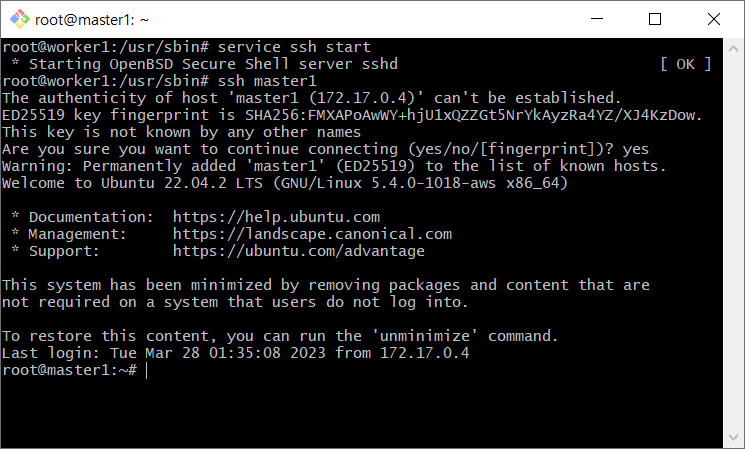
worker1에서 master1로 접속이 된 모습이다!
첫 접속 시에는 Are you sure you want to continue connecting (yes/no/[fingerprint])?라고 물어보는데, yes라고 하면 무사히 접속된다. (아직 fingerprint는 개념을 잘 모르겠다)
ssh: Could not resolve hostname worker1: Name or service not known
vi ~/etc/hosts에서 각 IP와 서버이름을 제대로 적었는지 확인.
ssh: connect to host {container_name} port 22: Connection refused
접속하려는 컨테이너에서 ssh 서비스가 돌아가고 있는지 확인.service ssh status # sshd is not running 이라면 다음으로 ssh 실행 service ssh start
Master 셋팅
디렉토리 생성
cd /usr/local/hadoop
mkdir -p hadoop_tmp/hdfs/namenode
mkdir -p hadoop_tmp/hdfs/datanode
chmod 777 hadoop_tmp/hadoop-env.sh 설정
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-amd64'
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=roothdfs-site.xml 설정
참고한 블로그에서는 namenode와 datanode의 임시 디렉토리 경로가 잘못 지정되어있었다.
나는 위에서 만든 디렉토리 경로로 작성하였다.
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>Worker 세팅
디렉토리 생성
cd /usr/local/hadoop
mkdir -p hadoop_tmp/hdfs/datanode
chmod 777 hadoop_tmp/hadoop-env.sh 설정
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME='/usr/lib/jvm/java-8-openjdk-amd64'hdfs-site.xml 설정
이것도 같다. 참고 블로그는 잘못되어 있다. 위에서 생성한 디렉토리인 /usr/local/hadoop/hadoop_tmp/hdfs/datanode으로 지정해주었다.
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop_tmp/hdfs/datanode</value>
</property>
</configuration>작동 확인
hadoop 시작
master1에서 다음을 실행한다.
# 나의 경우 다음을 실행하면 SHUTDOWN_MSG: Shutting down NameNode at master1/172.17.0.4가 출력된다. 다음 진행에 무리는 없다.
hdfs namenode -format
start-all.shjps 명령어
각 노드에서 jps을 입력하여 결과를 확인한다. 각각 다음과 같이 출력되면 성공이다.
master1
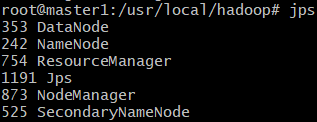
workers

👏 notice 3
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
64비트 운영체제에서 32비트 하둡을 돌려서 생기는 문제.
이 상태에서 hdfs dfs 명령을 입력해도 듣지 않는다. master1에서 다음을 설정한다.vi ~/.bashrc # export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"에서 다음으로 수정한다. export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" source ~/.bashrc # 환경변수 적용을 위한 하둡껐다키기 stop-all.sh start-all.sh다음과 같이 테스트 해보면 경고메시지 없이 문제 없이 잘 출력되는 것을 볼 수 있다.

👏 notice 4
Datanode가 나타나지 않을 때
각 컨테이너에 들어가서 로그를 확인한다.# ex) cat /usr/local/hadoop/logs/hadoop-root-datanode-master1.log cat /usr/local/hadoop/logs/hadoop-root-datanode-{container_name}.log좀 더 복잡한 원인이 있을 수 있겠으나, 나는 임시 데이터 디렉토리 문제였다.
하둡을 여러번 재실행하는 과정에서 임시 데이터가 생성되었고, 해당 데이터 때문에 실행시 문제가 생겼던 것. 초기 설치가 아닌 하둡 사용 중 namenode를 포맷해야한다면 hdfs의 data 폴더를 지우고 다시 생성한 후, namenode를 포맷해야한다고 한다.stop-all.sh rm -rf /usr/local/hadoop/hadoop_tmp/hdfs/datanode cd /usr/local/hadoop/hadoop_tmp/hdfs mkdir datanode hadoop namenode -format start-all.sh
wordCount 실행
hdfs라는 파일시스템을 사용하기 위해선, hdfs 내의 최상위 폴더를 만들어줘야한다. (참고블로그엔 없는 내용이다.)
hdfs dfs -ls를 입력하면 ls: `.': No such file or directory의 에러메시지가 출력될 것이다.
최상위 폴더 없이 사용하려면 hdfs dfs -ls /{디렉토리명}이나 hdfs dfs -mkdir /{디렉토리명} 처럼 대상 /+디렉토리명으로 명시하면 되지만, 이는 이전에 설정해준 파일 시스템 구조를 사용하지 않는 듯하다. 좋은 사용방법이 아니라고 생각한다.
따라서 다음을 통해 하둡 최상위 디렉토리를 생성해준다. 현재 진행에서는 root 계정에서 환경 구축을 했기 때문에 root 이지만, 만약 hadoop 계정으로 구축했다면 hadoop이라는 이름으로 디렉토리를 만들어줘야한다.
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root하둡에서 기본으로 제공하는 예제파일을 실행해본다. 실행 내용이 출력될 것이다.
hdfs dfs -mkdir /input
hdfs dfs -copyFromLocal /usr/local/hadoop/README.txt /input
hdfs dfs -ls /input
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /input/README.txt ~/wordcount-output
마지막으로 결과로 생성된 파일을 확인해본다.
hdfs dfs -ls ~/wordcount-output
hdfs dfs -cat /root/wordcount-output/part-r-00000 | more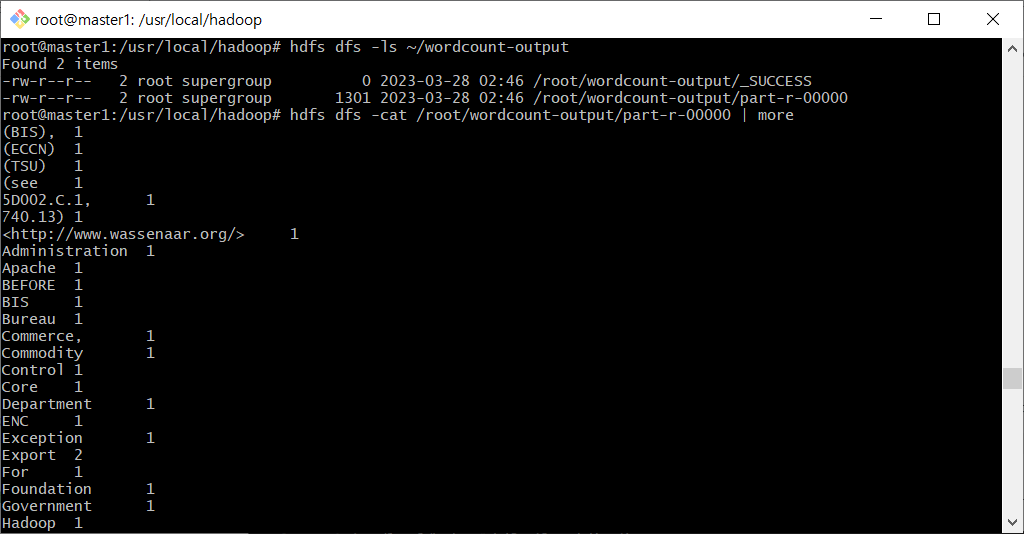
참고
