번역
서론
상대적으로 새로운 것을 설명하기 위해 오래된 단어를 차용하자면, Apache kafka는 messaging middleware입니다. 장애 처리가 가능하며(fault-tolerant) 고가용성(high-capacity) 방식으로 한 서버에서 다른 서버로 데이터를 전송하고, 구성에 따라 전송된 데이터의 수신을 확인하도록 설계되었습니다. 이는 성능 테스트에서 초당 2백만 쓰기(write)가 가능한 것을 보여주었습니다. 소프트웨어로서 더해, Kafka는 또한 TCP와 같은 프로토콜입니다. 다른 말로, 이것은 OSI 모델의 transport 계층에서 작동합니다. 당신은 이것을 매우 큰 용량의 syslog라고 생각할 수 있습니다.
Kafka는 LinkedIn에 의해 작성되었으며, 이제 오픈 소스 Apache 상품입니다. 그것은 Scala로 작성되었습니다. LinkedIn과 다른 회사들은 Kafka를 사용하여 데이터 피드를 읽고 topic으로 구성(organize)합니다.
당신은 대체제로 ActiveMQ와 같은 publish-subscribe 컨셉의 아무 메시징 도구를 생각할 수 있습니다. 이것은 거의 제한 없이 확장되고 내결함성이 높기 때문에 오늘날 널리 사용됩니다. 아래와 같이 매우 인기 있는 다른 오픈소스 도구와 함께 자주 사용됩니다.
예시로, 리눅스 시스템 관리자는 모든 종류의 로그 수집(aggregator) 플랫폼의 대체제로 Spark를 쓸 수 있습니다. 이는 이것의 결과를 그저 syslog처럼, 이것만의 TCP protocol을 사용하여 socket으로 전송합니다. 따라서 이것은 쉽게 syslog의 대체제로 동작 가능합니다. 당신이 아마도 로그 수집을 위해 syslog를 사용하고 있을 것이므로, 제품을 배울 수 있도록 Kafka를 설치할 좋은 구실이 있습니다. 그때 이것이 당신의 다른 플랫폼 도구에 어떻게 맞을 수 있는지 깨달을 수 있습니다.
Kafka data를 분석과 보고를 위한 Hadoop이나 data 웨어하우스로 출력할 수도 있습니다. 핀터레스트와 같은 많은 회사는 stream 프로세싱에 Kafka를 사용합니다. (여기서 stream은) 예를 들어 웹서버 clickstreams는 데이터가 계속 들어오고 멈추지 않는다는 것을 의미합니다. (열고 닫는 파일과 달리).
Kafka Concepts
먼저, 다음은 Hortonworks의 아래 그래픽으로 설명된 Kafka의 기본 개념입니다.
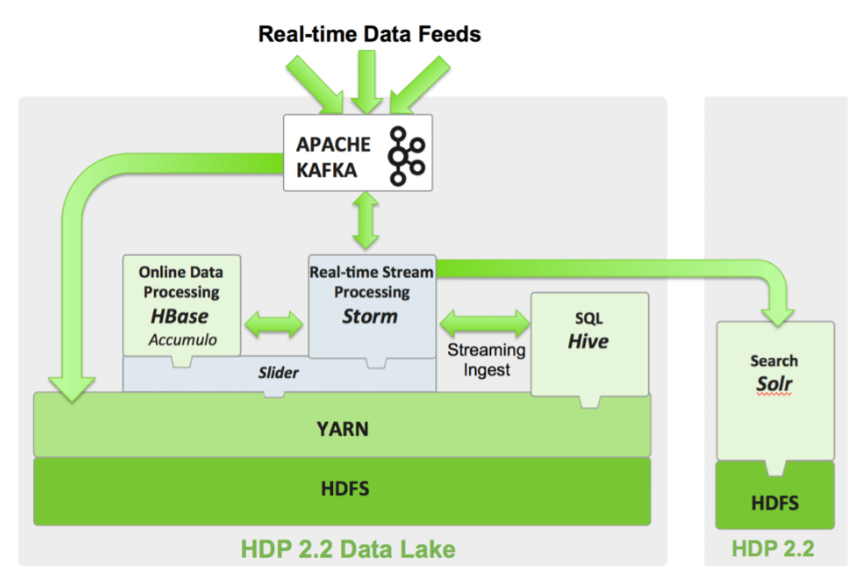
- Producers
- data feed를 소비하고 cosumers에게 배포하기 위해 Kafka를 보냅니다. - Consumers
- topic을 구독(subsribe)하는 applications.- 예시로, 자체 어플리케이션이나 아무 products가 이 글의 마지막에 나열되어있습니다.
- Brokers
- producer로부터 data를 가져오고, cosumer에게 이를 전송하는 일꾼.- 이들은 복제 또한 다룹니다.
- Partitions
- topic의 물리적 구분, 아래 사진에 보이는 것처럼.
- 파티션이 서로 다른 스토리지 서버에 분산되어 있으므로 중복성을 위해 사용됩니다.
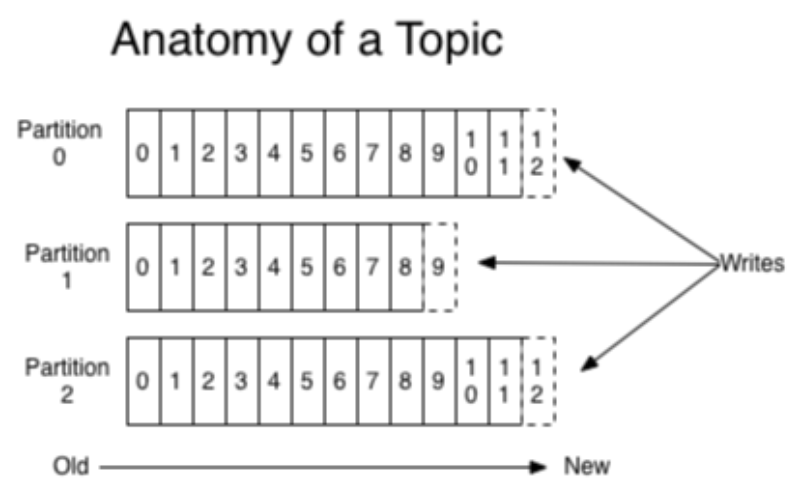
- Topics
- 메시지들의 분류(category). 이들은 "apachelogs"나 "clickstream"와 같은 것이 될 수 있습니다. - Zookeeper
- Kafka 이전에 시작해야합니다. Apache Zookeeper는 분산환경에서 서비스를 시작하기 위해 사용됩니다. Kafka의 일부는 아니지만, Kafka에 필요합니다.
Create a Topic
이 quick start 설명서는 Kafka를 어떻서 다운받고, Zookeeper를 실행하고 server를 어떻게 실행하는지 보여줍니다.
다음과 같이 topic을 생성하세요.
bin/kafka-topics.sh --create --zookeeper (server:port) --replication-factor 1 --partitions 1 --topick (topic name)Publish and Consum a Message
그리고 아래에 보이는 것처럼 메시지를 발행하고 소비해보세요.
이 간단한 예제는 설명을 위해 stdin 과 stout을 사용합니다. 또한 Tail2Kafka를 사용하여 tail을 사용하여 데이터를 작성할 수도 있습니다. 예시로, 당신은 Apache webserver logs를 Kafka에 작성할 수 있습니다.
Publish
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testConsume
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning(작성중)
원문 링크
https://anturis.com/blog/apache-kafka-an-essential-overview/
