
빅데이터 기술 소개
데이터 엔지니어는 데이터 웨어하우스를 만들고, 내부나 외부 데이터를 적재한다.
데이터 엔지니어가 ETL, 데이터 파이프라인을 구현한다.
ETL이란 ETL(Extract, Transform, Load) - 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업을 말한다.
데이터 팀의 구성원
- 데이터 엔지니어(Data Engineer)
- 데이터 분석가(Data Analyst)
- 데이터 과학자(Data Scientist)
머신러닝 모델링 사이클
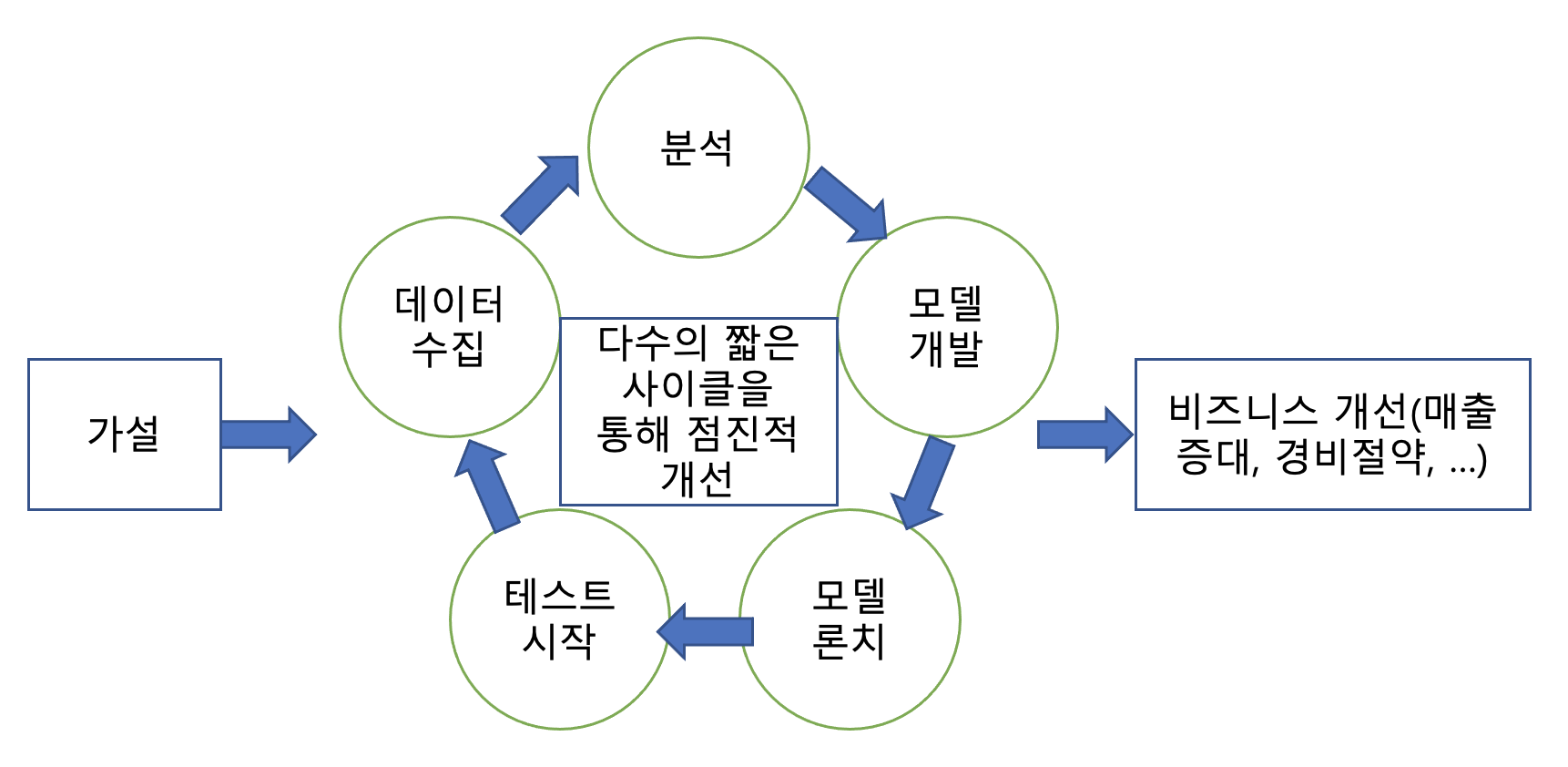
Airflow, Looker, Tableau를 많이 사용!
A/B 테스트
100%의 사용자에게 런칭하는 것이 아니라 작은 비율로 런치하고 결과를 관찰 후 결정
무작위 대조 시험(Randomized Controlled Trial)을 온라인으로 옮긴 것
보통 사용자들을 2개의 그룹으로 나누고 시간을 두고 관련 지표를 비교
모든 문제에 딥러닝을 쓰지는 말자! - 가능하면 간단한 솔루션으로 시작하는 것이 좋다
빅데이터
빅데이터 -> 서버 한대로, 기존의 소프트웨어로는 처리할 수 없는 규모의 데이터
4V(Volume, Velocity, Variety, Varecity)
하둡
1대 혹은 그 이상의 서버로 구성, 최초의 대용량 분산처리 기술
MapReduce 방식의 프로그래밍이 너무 복잡해서 생산성이 떨어졌다.
MapReduce는 기본적으로 배치 작업에 최적화, SQL 같은 언어들의 원리가 필요해 Hive를 만들었다.
하둡은 기반 분산처리 시스템이 되고 그 위에 애플리케이션 레이어가 올라가는 구조로 발전했다.
하둡은 데이터 웨어하우스이다. 하둡 2.0을 YARN이라고 부르기도 함
Spark
Spark는 MapReduce의 단점을 상당히 개선했다.
Spark Core: Pandas와 굉장히 흡사
Spark SQL: Spark Core 위에서 데이터처리를 SQL언어로 하는 구조
작은 데이터를 다루는데 굳이 Spark을 쓸 필요없다.
Spark MLlib 모델 튜닝 - 최적의 하이퍼 파라미터를 선택하는 것
교차 검증(Cross Validation)과 홀드 아웃(Train-Validation Split) 테스트 방법을 지원
Predictive Model Markup Language - 잘 안돼서 실습 X
판다스로 대부분 충분, 모델링은 Scikit-Learn, Pytorch, Tensorflow(Keras)등으로도 충분
스파크는 정말 데이터가 많을 때
RDD(Resilient Distributed Dataset)
클러스터 내의 서버에 분산된 로우레벨 데이터, spark cluster는 기본적으로 하나 이상의 서버로 구성
처리해야 할 데이터를 spark cluster위에 로딩할 때 쓸 수 있는 구조가 3가지가 있는데,
이는 rdd, dataframe, dataset으로 분산 저장되는 데이터이다.
Spark MLlib
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
RDD 기반의 spark.mllib과 데이터프레임 기반의 spark.ml이 두 버전이 존재
MLflow
모델 개발과 테스트와 관리와 서빙까지 제공해주는 프레임워크
ML Pipeline
파이프라인으로 하나로 과정을 묶는 방법
Load data -> Extract features -> Train model -> Evaluate
API로 사용하게 해줌
저장했다가 나중에 다시 로딩하는 것이 가능
ML Tuning
최적의 하이퍼 파라미터를 선택하는 것
ML Pipeline과 같이 사용함
모델 테스트
교차 검증(Cross Validation)
K-Fold 테스트라고 부르기도 함
오버피팅 문제가 감소되는 효과가 있고 K개로 데이터를 나눈 뒤, 나뉜 각각의 데이터가 검증의 대상이 됨으로써 최종적으로 K개의 결과에 대한 평균이 Output이 된다.
Train-validation split
보통 훈련과 테스트 비율을 80:20 or 75:25로 한다. 그치만 오버피팅의 위험성이 있음
모델의 성능을 측정할 때에 AUC(Area Under the Curve)가 성능지표이다.
MinMaxScaler
다수의 피쳐 컬럼들이 하나의 컬럼으로 벡터 형태로 변환이 되어서 피쳐 값들이 0과 1사이로 정규화시킴
