
@EqualsAndHashCode 필요한 이유
Lombok에서 자주 사용되는 애노테이션 중 @EqualsAndHashCode가 있다. 이 애노테이션은 equals(), hashCode() 메서드를 자동 오버라이딩해준다. 도메인 객체에 습관적으로 사용했지만, 제대로 알지는 못하는 것 같아 기초부터 공부하고 정리해보았다.
equals(),hashCode()메서드란 어떤 역할을 하는지?- 각 메서드를 오버라이딩 하는 이유
- 함께 오버라이딩 하는 이유
Java에서의 비교
@EqualsAndHashCode 애노테이션을 사용하지 않은 객체를 테스트 해보면 의도대로 객체 비교가 동작하지 않을 수 있다. 자바에서는 두 객체가 같은지 비교하기 위한 기준이 '동일성'과 '동등성' 두 가지가 있기 때문이다.
원시 타입과 참조 타입
자바의 데이터 타입은 크게 원시 타입(primitive type)과 참조 타입(reference type)으로 나눌 수 있다. 원시 타입은 변수가 위치한 메모리 공간에 값 자체가 저장되지만, 참조 타입은 객체가 저장된 곳의 주소값을 가지고 있다. (실제의 메모리 주소 그대로는 아니다.)
- 원시 타입 :
int,byte,short,long,float,double,boolean,char(8 종류) - 참조 타입 : 원시 타입을 제외한 모든 데이터 타입.
자바의 동일성 비교 연산자(==)로 두 대상을 비교해보자 :
assertThat(1 == 1).isTrue();원시 타입은 값 자체를 비교하여 두 대상이 일치한지 판단한다.
Integer a = new Integer(1);
Integer b = new Integer(1);
assertThat(a == b).isFalse();반면 참조 타입의 경우 두 대상의 주소값을 비교한다. 따라서 각각의 생성자로 만들어진 두 객체는 가지고 있는 값이 동일해도 주소값이 다르기 때문에 다른 객체로 간주된다.
동일 비교와 동등 비교
동일성(identity)이란 두 값이 물리적으로 일치하는 것이다. 위 예시들에서 살펴본 == 연산자는 동일성을 비교한다. 원시 타입의 경우 값이 같으면 '동일'하고, 참조 타입의 경우 주소값이 같으면 '동일'하다고 간주한다.
반면 동등성(equality)은 덜 엄격한 비교로, 두 대상이 물리적으로 동일하지 않아도 표현하는 값이 같다면 같게 간주한다. '동일'하지는 않지만 '동등'하다는 것이다. 원시타입의 경우 동일성과 동등성의 구분은 의미가 없으나, 참조타입은 물리적으로 '동일'하지 않아도 표현하는 값이 같다면 '동등'하다(동등X → 동일은 불가능).
equals()
자바에는 대상 비교를 위해 사용되는 Object.equals() 메서드가 있다. 이 메서드는 오버라이딩하지 않으면 기본적으로는 동일성 비교를 수행한다. 하지만 동일성 비교는 간단하게 == 연산자로 가능하기 때문에 일반적으로 이 메서드를 오버라이드하여 동등성 비교에 사용한다. 아래에서 자세히 살펴보자.
오버라이딩 전
public class Person {
private String name;
private int age;
}위와 같은 Person 클래스를 예시로 들어보자.
Person joe = new Person("Joe", 20);
Person joeAgain = new Person("Joe", 20);
assertThat(Objects.equals(joe, joeAgain)).isFalse();equals()를 오버라이딩하지 않고 joe와 joeAgain이 같은지 비교해 보면 결과는 false가 된다.
public class Object {
public boolean equals(Object obj) {
return (this == obj);
}
}내부적으로 == 동일성 비교를 하고 있기 때문이다. joe와 joeAgain은 서로 다른 곳에 저장된 객체이기 때문에 당연히 동일하지 않다.
오버라이딩
public class Person {
// other fields and methods omitted
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
}Person 클래스에서 equals()를 위와 같이 오버라이딩 해보자(IDE에서 자동 생성 가능하다).
오버라이딩 한 코드를 하나씩 살펴보자 :
- 우선
==비교를 통해 비교 대상으로 받은o와 주소값이 같으면 당연히 같은 객체임으로true를 반환한다(동일함 → 동등함). - 그 다음 비교 대상인
o이null이거나 다른 클래스인 경우 동등하지 않은 객체로 간주해false를 반환한다. - 그 다음
o의 프로퍼티에 직접 접근하기 위해(person.name처럼)Object타입인o를Person타입으로 캐스팅한다. - 두 비교 대상 객체의 필드를 각각 비교한다.
age는 원시 타입이므로==연산자를 통해 비교하고,name은String타입이기 때문에 동등성 비교를 위해equals()를 사용한다.
참고) String 타입은 참조 타입이기 때문에 String 객체에서 자체적으로 equals()를 오버라이딩 하고 있어, 두 객체를 비교할 때 문자열 값을 비교하여 동등성을 검사한다.
hashcode()
해시코드란
해시코드는 간단하게 말해 해싱 알고리즘에 의해 만들어진 정수값이다.
어떤 값을 해싱 알고리즘을 통해 계산한다면, 몇 번을 반복해서 계산해도 항상 동일한 값(해시코드)이 나와야 한다. 자바의 Objects.hashCode() 메서드는 해시코드를 만들어주는 해시 함수(알고리즘)와 같다.
해시코드의 필요성

해시코드는 왜 필요할까? 해시 기반의 자료구조를 사용하기 위해서다.
해시 테이블을 예로 들어보겠다. 위 이미지와 같이 로우 키를 해시 함수에 넣으면 해시 코드가 도출된다. 이 해시 코드는 인덱스로 사용되어 해시 테이블에 저장된다. 해시테이블은 함수를 통해 인덱스를 계산하여 데이터에 즉시 접근할 수 있기 때문에 속도가 빠르다. (거의 상수 시간의 시간복잡도를 가진다.)
한 가지 주의할 점은, 해시 코드는 고유값은 아니라는 것이다. 같은 키(객체)라면 반드시 항상 같은 해시 코드를 가져야 하지만, 다른 키라고 해서 꼭 값이 다르지는 않기 때문이다.
예를 들면 Joseph과 John을 키로 사용했을 때, 해시 함수를 통해 도출된 해시코드가 둘 다 0으로 동일할 수 있다. 이것을 해시 충돌이라고 한다.
충돌이 일어나면 인덱스가 동일하기 때문에 값을 정확하게 가져올 수 없다. 0 인덱스에 목표 값이 있다고 해서 찾아갔는데 객체가 두 개라면 어느 것을 가져와야 할 지 프로그램은 알 도리가 없다. 따라서 해시 테이블에 Linked list를 함께 사용하는 이중 자료구조를 사용하거나, 충돌이 생긴 경우 다른 비어있는 인덱스에 데이터를 저장하는 등 해시충돌을 해결하는 매커니즘을 사용한다. ( Details : 🔗 Understanding Hash Tables )
hashCode() 오버라이딩의 필요성
hashCode()를 오버라이딩해서 사용해야 하는 이유는 객체가 표현하는 값에 관계없이 객체마다 다른 해시코드를 만들어주기 때문이다.
예를 들어 해시 기반 자료구조인 HashSet은 중복된 값은 저장하지 않는데, 중복의 기준은 '표현하는 값이 같은지'이다. 즉 동등성과 관련이 있기 때문에 메모리 주소를 기반으로 해시코드를 생성하는 것은 적절하지 않다.
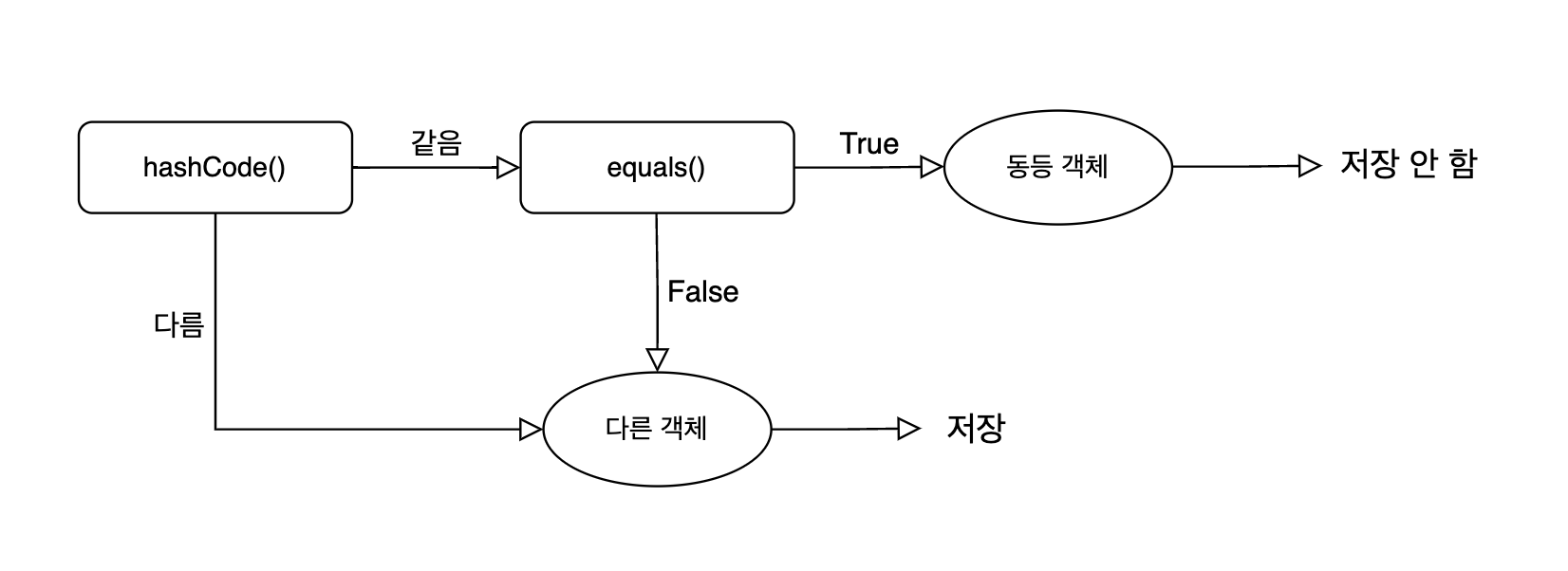
HashSet은 새로운 객체를 저장할 때 같은(동등한) 객체가 이미 저장되어 있는지 판단하기 위해 먼저 hashCode()를 통해 도출된 해시 코드를 비교한다. 해시코드가 다르면 다른 값이므로 저장한다. 해시코드가 같으면 equals()를 통해 동등성을 다시 비교한다(값이 다른 객체여도 해시코드가 같을 수 있다 - 해시 충돌). 다른 값이면(false) 저장하고 같은 값이면(true) 저장하지 않는다.
참고) 여러 글에 따르면 hashCode()는 기본적으로 메모리 주소를 기반으로 해시코드를 만들어준다고 한다. hashCode()의 원래 로직을 보기 위해 자바 코드를 뒤져보았는데 확인할 수가 없었다. 검색 결과 한 블로그(🔗 [Velog] hashCode는 정말 메모리주소와 관련이 있을까?)에 의하면 hashCode()의 해싱 알고리즘은 객체의 메모리 주소와 관련이 없으며 구현부는 JDK에 따라 달라진다고 한다. 하지만 hashCode()의 해싱 알고리즘이 메모리 주소와 관련이 있든 없든, 디폴트 로직이 동등성 비교에 알맞지 않으므로 오버라이딩하는 것이 맞다.
hashCode() 오버라이딩
public class User {
private long id;
private String name;
private String email;
}@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((email == null) ? 0 : email.hashCode());
result = prime * result + (int) (id ^ (id >>> 32));
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}해싱 알고리즘은 표준이 없어서 임의대로 정의하면 되는데, 요즘의 IDE는 효율적인 자체 알고리즘을 사용해 자동 오버라이딩 해 준다.
예시 클래스인 User에서 IntelliJ IDE를 통해 hashCode()를 오버라이딩한 코드이다. 객체의 물리적 메모리 주소가 아닌 필드인 id, name, email의 값을 해시 코드 생성에 사용한 것을 확인할 수 있다.
@Override
public int hashCode() {
return Objects.hash(name, age);
}참고) 🔗 Baeldung 에서 가져온 위 오버라이딩 예시와 달리 직접 IntelliJ IDE를 통해 오버라이딩 해보니 위와 같이 hash() 메서드를 사용해서 오버라이딩되었다. hash()는 파라미터로 여러 객체를 받아 해시코드를 생성해주는 메서드로, 내부에서 hashCode()를 사용한다.
함께 오버라이딩 하는 이유
1) hashCode()만 오버라이딩 하는 경우
HashSet은 동등한 객체를 중복 저장하지 않고, HashMap은 동등한 객체의 중복 저장은 허용하나 중복 키(해시코드 인덱스)를 허용하지 않는다. HashSet과 HashMap은 중복 객체 또는 중복 키 여부를 검사할 때 위와 같이 hashCode()와 equasl()를 통해 동등성을 검사한다.
해시 충돌 가능성이 있기 때문에 hashCode() 리턴값이 같다고 해서 동등한 객체라고 확신할 수는 없다. 따라서 equals()를 통해 한 번 더 검사를 할 필요성이 있다. (처음부터 equals() 비교를 하지 않는 이유는 해시 충돌 가능성이 있긴 하지만 낮기 때문에 hashCode()로 먼저 판별하는 것이 빠르기 때문인 것 같다. )
따라서 해시 기반 자료구조를 사용하기 위해서는 반드시 equals()와 hashCode()를 함께 오버라이딩 해주어야 한다.
2) equals()만 오버라이딩 하는 경우
해시 기반 자료구조를 사용하지 않는다면 hashCode()를 꼭 오버라이딩 할 필요는 없을지도 모른다. 하지만 객체가 나중에 해시 기반 자료구조를 통해 관리될 지 안 될지는 예측하기 매우 어렵다.
hashCode() 오버라이딩이 비용이 많이 드는 것도 아니므로 함께 오버라이딩하는 것이 좋다. Lombok에 @EqualsAndHashCode 애노테이션이 존재하는 이유일 것이다.
🔗 References
- [Baeldung] Difference Between == and equals() in Java, written by Mateusz Szablak
- [Baeldung] Comparing Objects in Java, written by François Dupire
- [Baeldung] Guide to hashCode() in Java, written by Baeldung
- [Baeldung] Comparing Objects in Java, written by François Dupire
- [Baeldung CS] Understanding Hash Tables, written by Vinicius Fulber-Garcia
