
시작하며
한 달동안 Terraform으로 신규 AWS 운영 환경을 구성해보는 작업을 맡았었는데, 이를 정리해보려고 한다.
이번 글에서는 VPC와 서브넷까지 만들어보려 한다.
Terraform 설치와 AWS 사용자 인증(.aws/credentials)은 되어있다고 가정하고 시작하자.
최종 소스코드는 아래 깃허브에 업로드 되어있다.(aws 디렉토리)
설계도
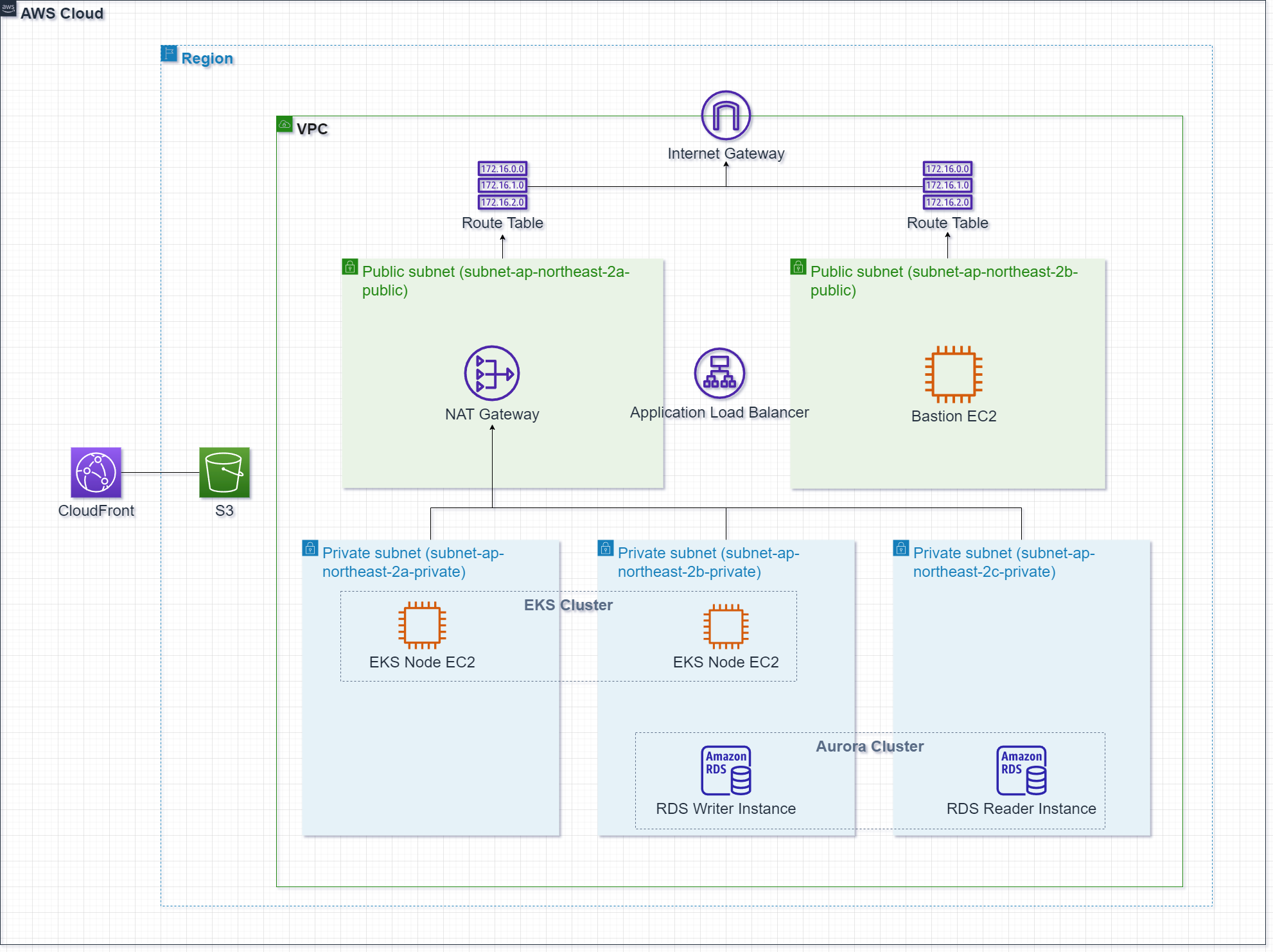
Terraform을 통해 최종적으로 만들어보려하는 아키텍처이며, 사용하는 리소스는 아래와 같다.
- VPC
- EC2
- EKS
- RDS
- S3
- CloudFront
CloudFront + S3로 VueJS로 개발한 샘플 SPA(Single Page Application)를 배포하여 웹 호스팅하도록 구성하고 Spring Boot로 개발한 샘플 WAS를 컨테이너로 패키징해 EKS로 배포할 것이며, WAS에 연결될 RDS까지 사용해 볼 것이다.
네이밍 룰
시작하기 전에, 생성할 AWS 리소스에 대해 네이밍 룰을 명확하게 정하고 시작하고 싶었다.
누구나 공감할 것이라 생각되는데, 리소스명 규칙이 없으면 이름 정하는데에만 시간을 꽤나 쏟게 되고, 추후에 이름을 수정하고 싶어도 마음대로 수정하지 못하는 리소스도 있기 때문이다.
여러 블로그와 베스트 프랙티스 등을 찾아보며 내가 정한 리소스 네이밍 룰은 아래와 같다.
[리소스명]-[리전/AZ]-[환경]-[public/private]-[용도]
여기서 public/private 부분은 서브넷이나 네트워크 관련된 리소스에만 추가하기로 했고, [환경], [용도]는 dev,stg,prd나 app,database,web 등을 의미하는데 이번 포스팅에서는 제외하기로 했다.
그리고 Terraform에서 사용되는 블록 개체명은 -이 아닌 _를 사용하기로 했다.
그 이유는 이 문서에서 권장하는 항목이기 때문...
Terraform Module
Terraform 시작 전에 어떤 식으로 리소스를 관리하면 좋을 지 찾아봤는데, 모듈화하여 관리하는 것이 베스트 프랙티스로 여겨지는 듯하다.
모듈화하여 관리하는 것에는 아래와 같은 장점이 있다.
- 재사용성 증가(=중복 코드 제거)
- 리소스별 관리 구별
- 복잡한 설정 추상화 가능
이번 작업에서는 이 모듈 구조를 적용해보기로 했고, 사실 모듈 구조를 이해하는데는 시간이 조금 걸렸다.
모듈화를 하는 것이 베스트 프랙티스이긴 하지만 정답은 아니기에, 결국 자기 입맛에 맞게끔 관리하는 편이 좋다는 생각이 든다.
루트 모듈에 여러 리소스를 파일명으로 구분해서 꼬이지 않고 잘 정리할 수만 있다면 모듈 구조보다 오히려 좋은 점도 많을 것이라고 생각한다.
최종적으로 생성될 Terraform 구조는 아래와 같다.
[dgyoon@terraform aws]# tree
.
├── main.tf
├── modules
│ ├── cloudfront
│ │ ├── main.tf
│ │ ├── output.tf
│ │ └── variable.tf
│ ├── ec2
│ │ ├── main.tf
│ │ ├── output.tf
│ │ └── variable.tf
│ ├── ecr
│ │ └── main.tf
│ ├── eks
│ │ ├── main.tf
│ │ └── variable.tf
│ ├── rds
│ │ ├── main.tf
│ │ └── variable.tf
│ ├── s3
│ │ ├── main.tf
│ │ ├── output.tf
│ │ └── variable.tf
│ ├── subnet
│ │ ├── main.tf
│ │ ├── output.tf
│ │ └── variable.tf
│ └── vpc
│ ├── main.tf
│ ├── output.tf
│ └── variable.tf
├── output.tf
└── variable.tf모듈 구조에서는 각 모듈이 폴더별로 구분이 되고, 주로 main.tf, variable.tf, output.tf 파일을 사용한다.
main.tf에 리소스 코드가 담기게 되고, variable.tf와 output.tf는 외부에서 리소스 코드에 데이터를 넣어 줄때(variable.tf), 혹은 리소스 코드에서 외부로 데이터를 내보낼 때(output.tf)를 사용하게 된다.
ROOT 모듈
처음 시작할 때 필요한 최상단 경로(루트 모듈)의 main.tf는 아래와 같다.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.80.0"
}
}
}
provider "aws" {
region = "ap-northeast-2"
}위 코드는 Terraform AWS 문서에 그대로 기술되어 있는 코드이다.
위 링크를 타고 들어가 우측 USE PROVIDER를 클릭해 코드를 복사해오면 된다.
terraform 블록에 사용할 provider까지 명시했다면 terraform init을 통해 사용할 인프라 공급자(여기서 AWS)의 API를 호출할 수 있는 플러그인을 가져오자.
.terraform/providers 하위에 해당 provider의 플러그인 파일을 확인할 수 있을 것이다.
나의 경우 terraform-provider-aws_v5.80.0_x5.exe 파일이다
VPC 모듈
이제 모듈 구조를 적용해볼테니 프로젝트 최상위 경로에 modules 폴더를 만들고 그 아래에 vpc 폴더를 생성한다.
그리고 아래와 같이 main.tf를 작성한다.
modules/vpc/main.tf
resource "aws_vpc" "vpc" {
cidr_block = var.vpc_cidr_block
tags = {
Name = "vpc-${var.region}"
}
}resource 블록은 실제로 AWS 계정안에 생성할 리소스를 명시하는 블록이다.
resource 블록을 작성할 때에는 상단에 언급했던 문서를 꼭 참고해 필요한 인자가 무엇인지 파악하고 작성해야 한다.
우리는 VPC를 먼저 만들어야하기에 resource "aws_vpc" 블록을 작성한다.
resource "aws_vpc" "vpc"는 AWS 프로바이더를 통해 생성할 VPC를 정의하는 의미이며, 뒤의 "vpc"가 해당 리소스의 개체명이 된다.
객체 지향 언어를 사용해봤다면 금방 이해가 갈 것이다.
그리고 안에 cidr_block = var.vpc_cidr_block으로 VPC에서 사용할 IPv4 범위를 정의한다.
var은 variable 블록에서 선언한 변수를 가져오는 것이며, variable.tf 파일에 정의되어 있다.
tags = { Name = "vpc-${var.region}" }는 VPC의 이름을 정하기 위해 태그를 달아준 것이며 자유롭게 변경해도 된다.
modules/vpc/variable.tf
variable "vpc_cidr_block" {
type = string
}
variable "region" {
type = string
}variable 블록에서는 외부에서 resource 블록안으로 주입시켜줄 변수를 선언한다.
VPC의 CIDR과 리전을 꼭 외부에서 주입시켜야 하는가에 대한 질문이 생길 수 있는데 꼭 그러지 않아도 된다.
다만 환경별로 달라질 수 있는 변수를 주로 terraform.tfvars 파일에 담아 관리하기 때문에 그렇다.
variable.tf
variable "vpc_cidr_block" {
type = string
}
variable "region" {
type = string
}변수명만 같을 뿐 여기는 루트 모듈의 variable.tf이다.
terraform.tfvars
vpc_cidr_block = "10.100.0.0/16"
region = "ap-northeast-2"VPC CIDR을 10.100.0.0/16으로 정했고 리전은 서울 리전이다.
terraform.tfvars 파일에 명시되어 있지 않고, default 값이 정해져있지 않다면 terraform apply 단계에서 주입시킬 수도 있다.
참고로 terraform.tfvars은 로컬 환경에 필요한 변수를 정의하기 때문에 GIT에는 업로드하지 않는 것이 좋다.
권장하는 Terraform gitignore 파일 목록은 아래 링크에 있다.
그리고 이제 다시 루트 모듈로 돌아가 main.tf에서 VPC 모듈을 호출한다.
main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.80.0"
}
}
}
provider "aws" {
region = var.region
}
module "vpc" {
source = "./vpc"
vpc_cidr_block = var.vpc_cidr_block
region = var.region
}루트 모듈에서 하위 모듈을 호출한 이후에는 terraform init을 꼭 해주어야 한다.
이렇게 되면 terraform.tfvars 파일에 명시된 vpc_cidr_block, region 값이 루트 모듈의 variable.tf에 명시된 변수에 담겨 module "vpc" 블록안에 var.vpc_cidr_block, var.region에 담겨 최종적으로 리소스 모듈에 주입되는 것이다.
이렇게 작성하고 루트 모듈 커맨드 창에서 terraform plan을 입력하면 Terraform 코드를 통해 수행될 계획이 출력된다.
그리고 terraform apply 후 실행 계획이 그대로 출력된다면 yes를 입력해 VPC를 생성하고 AWS 콘솔에 접속하여 생성된 VPC를 확인해보자.
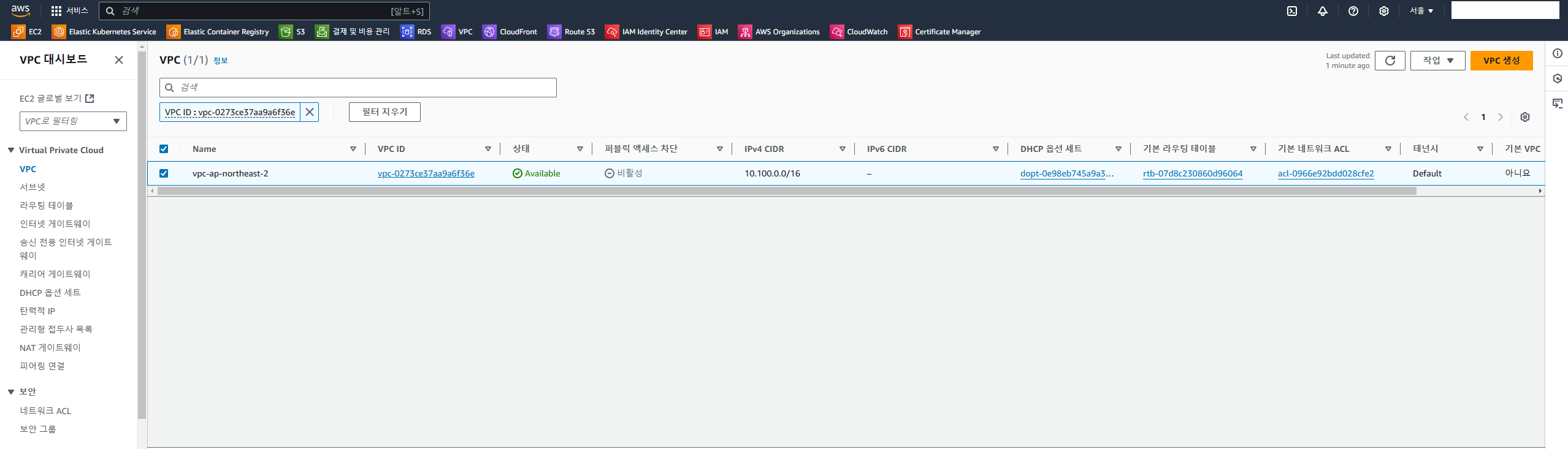
원하는 CIDR과 리전 값으로 생성이 잘 되었다.
이제 서브넷을 생성해보자.
Subnet 모듈
서브넷을 통해 모듈화를 통해 왜 재사용성이 증가하고 중복 코드가 줄어드는지 알아보자.
우선 서브넷에는 퍼블릭 서브넷과 프라이빗 서브넷이 존재한다.
퍼블릭 서브넷은 인터넷 접근이 자유롭고 외부 트래픽도 자유롭게 받을 수 있는 서브넷이며, 프라이빗 서브넷은 인터넷 접근이 제한적이며 내부 네트워크에서만 혹은 지정한 호스트만 접근 가능한 서브넷이다.
우리는 하나의 서브넷 모듈을 만들고 두 종류의 서브넷을 만들 것이다.
modules 폴더 하위에 subnet 폴더를 만들어 main.tf를 작성한다.
modules/subnet/main.tf
resource "aws_subnet" "subnet" {
for_each = var.subnet_cidr_blocks
vpc_id = var.vpc_id
cidr_block = each.value
availability_zone = each.key
map_public_ip_on_launch = var.automatic_public_ip
tags = {
Name = "subnet-${each.key}-${var.access_modifier}"
}
}처음보면 당황스러울 수 있으나 어렵지 않다.
우선 나는 외부에서 각 서브넷의 CIDR을 지정해 주입할 것이고, 생성할 서브넷 수만큼 정의할 것인데, 그 목록을 변수 subnet_cidr_blocks에 "key" = "value" 형태의 map(string) 형태로 정의할 것이다.
여기서 for_each = var.subnet_cidr_blocks 구문을 보면 var.subnet_cidr_blocks 담긴 항목만큼 반복해 리소스를 생성한다.
즉, subnet_cidr_blocks에 CIDR을 4개 정의했다면, 서브넷이 4개가 생기는 것이다.
아래 each.value, each.key는 for_each의 각 순회되는 키와 밸류에 해당하는 값을 가져오는 것이고 여기선 each.key가 AZ, each.value가 CIDR이 되겠다.
vpc_id, cidr_block, availability_zone은 서브넷의 소속 VPC, CIDR, AZ를 지정하는 것이며, map_public_ip_on_launch은 해당 서브넷에 생성되는 인스턴스에 자동으로 공인 IP를 부여할지에 대한 여부이다.
여기서 vpc_id의 경우 위 VPC 모듈에서 생성한 VPC의 id를 가져와야 한다.
즉, VPC 모듈에서 서브넷 모듈로 id를 전달해주어야 한다는 의미이다.
모듈과 모듈간의 데이터 전달은 output.tf, variable.tf를 통해 가능하다.
modules/vpc/output.tf
output "vpc_id" {
value = aws_vpc.vpc.id
}VPC 모듈의 output.tf 파일에서는 외부로 전달시킬 값을 선언하고, 반대로 값을 받아야 하는 서브넷 모듈에서는 variable.tf 파일에 변수를 선언한다.
modules/subnet/variable.tf
variable "vpc_id" {
type = string
}데이터 전달은 두 모듈의 상위 모듈(여기서는 루트 모듈)에서 아래와 같이 수행할 수 있다.
main.tf
module "vpc" {
source = "./vpc"
...
}
module "public_subnet" {
source = "./subnet"
...
vpc_id = module.vpc.vpc_id
...
}보통 퍼블릭 서브넷은 배치된 인스턴스마다 공인(퍼블릭) IP를 갖고 인터넷 게이트웨이로 직접 통신하고, 프라이빗 서브넷은 공인 IP 없이 NAT 게이트웨이(또는 인스턴스)를 통해 인터넷 게이트웨이를 통과해 외부와 통신한다.
resource "aws_internet_gateway" "internet_gateway" {
count = var.access_modifier == "public" ? 1 : 0
vpc_id = var.vpc_id
tags = {
Name = "igw-${var.region}"
}
}
resource "aws_nat_gateway" "nat_gateway" {
count = var.access_modifier == "private" ? 1 : 0
allocation_id = aws_eip.nat_ip[0].id
subnet_id = var.nat_subnet_id
tags = {
Name = "nat-${keys(var.subnet_cidr_blocks)[0]}-public"
}
}
resource "aws_eip" "nat_ip" {
count = var.access_modifier == "private" ? 1 : 0
domain = "vpc"
tags = {
Name = "eip-${keys(var.subnet_cidr_blocks)[0]}-nat"
}
}나는 access_modifier라는 변수를 두어 내가 생성하려는 서브넷이 퍼블릭인지 프라이빗인지를 구분하였다.
변수 access_modifier가 public이면 퍼블릭 서브넷을 만드는 것이기 때문에, 인터넷 게이트웨이를 생성해야할 것이고, private이면 NAT 게이트웨이를 생성해야할 것이다.
그리고 NAT 게이트웨이는 고정 아이피가 필요하기 때문에, EIP(Elastic IP)를 통해 고정 아이피를 부여받기 위해 aws_eip 리소스를 생성하고 allocation_id에 id를 담아주고, NAT 게이트웨이가 배치될 서브넷까지 지정해준다.
참고로 공식 문서에서 NAT 게이트웨이를 AZ별로 하나씩 두는 것을 권장하는데, 찾아보니 속도가 빨라서라기보다는(물론 차이는 존재할 것 같으나 희미할 듯) 고가용성을 위해서라고 한다.
하지만 여기서는 하나만 생성한다.
그리고 keys() 함수로 map을 key의 리스트 형태로 만들어 가장 처음의 값을 가져온다.
여기서는 ap-northeast-2a 가 될 것이다.
그리고 라우트 테이블을 생성해 퍼블릭 서브넷은 외부 트래픽을 인터넷 게이트웨이로, 프라이빗 서브넷은 NAT 게이트웨이로 향하게 한다.
resource "aws_route_table" "route_table" {
vpc_id = var.vpc_id
route {
cidr_block = "0.0.0.0/0"
gateway_id = var.access_modifier == "public" ? aws_internet_gateway.internet_gateway[0].id : null
nat_gateway_id = var.access_modifier == "private" ? aws_nat_gateway.nat_gateway[0].id : null
}
route {
cidr_block = var.vpc_cidr_block
gateway_id = "local"
}
tags = {
Name = "rtb-${var.region}-${var.access_modifier}"
}
}
resource "aws_route_table_association" "route_table_association" {
for_each = var.subnet_cidr_blocks
subnet_id = aws_subnet.subnet[each.key].id
route_table_id = aws_route_table.route_table.id
}첫 번째 route 블록에서는 모든 트래픽을 인터넷 게이트웨이(퍼블릭), NAT 게이트웨이(프라이빗)으로 보내게끔 설정하고 두 번째 route 블록에서는 도착지 IP가 VPC 내부인 경우 local = (서브넷 내부)로 이동하게끔 설정한다.
그리고 resource "aws_route_table_association"로 라우트 테이블과 서브넷을 연결시킨다.
modules/subnet/variable.tf
variable "vpc_id" {
type = string
}
variable "subnet_cidr_blocks" {
type = map(string)
}
variable "automatic_public_ip" {
type = bool
}
variable "vpc_cidr_block" {
type = string
}
variable "access_modifier" {
type = string
}
variable "nat_subnet_id" {
type = string
default = null
}
variable "region" {
type = string
}루트 모듈에서 주입받을 변수들이고, NAT 게이트웨이 관련된 변수는 퍼블릭 서브넷일 경우 따로 주입하지 않기 위해 default = null 구문을 추가해주었다.
이제 루트 모듈에서 서브넷 모듈을 호출해보자.
main.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.80.0"
}
}
}
provider "aws" {
region = var.region
}
locals {
public_subnet_cidr_blocks = {
"ap-northeast-2a" = cidrsubnet(var.vpc_cidr_block, 8, 0),
"ap-northeast-2b" = cidrsubnet(var.vpc_cidr_block, 8, 1)
}
private_subnet_cidr_blocks = {
"ap-northeast-2a" = cidrsubnet(var.vpc_cidr_block, 8, 10),
"ap-northeast-2b" = cidrsubnet(var.vpc_cidr_block, 8, 11),
"ap-northeast-2c" = cidrsubnet(var.vpc_cidr_block, 8, 12)
}
}
module "vpc" {
source = "./vpc"
vpc_cidr_block = var.vpc_cidr_block
region = var.region
}
module "public_subnet" {
source = "./subnet"
subnet_cidr_blocks = local.public_subnet_cidr_blocks
vpc_id = module.vpc.vpc_id
automatic_public_ip = true
vpc_cidr_block = var.vpc_cidr_block
access_modifier = "public"
region = var.region
}
module "private_subnet" {
source = "./subnet"
subnet_cidr_blocks = local.private_subnet_cidr_blocks
vpc_id = module.vpc.vpc_id
automatic_public_ip = false
vpc_cidr_block = var.vpc_cidr_block
access_modifier = "private"
nat_subnet_id = module.public_subnet.subnet_id[keys(local.public_subnet_cidr_blocks)[0]]
region = var.region
}locals 블록이 추가되었는데, 로컬 변수를 선언하는 블록이다.
나는 각 서브넷의 cidrsubnet() 함수로 CIDR 범위(value)와, AZ(key)를 선언해주었다.
그리고 module "public_subnet"와 module "private_subnet"을 선언해준다.
서브넷 리소스에서 필요했던 값을 주입해주고, 프라이빗 서브넷은 NAT 관련된 값까지 주입해주었다.
여기서 nat_subnet_id 변수에는 NAT 게이트웨이가 배치될 퍼블릭 서브넷의 id 값이 필요하다.
때문에 먼저 생성되는 퍼블릭 서브넷 모듈에서 후에 생성될 프라이빗 서브넷 모듈로 데이터를 보내줘야 하는데 이 때 output 블록을 사용하면 된다.
modules/subnet/output.tf
output "subnet_id" {
value = [for subnet in aws_subnet.subnet : subnet.id]
}퍼블릭 서브넷 모듈에서 생성되는 서브넷의 id 값을 전부 output으로 내보내고, nat_subnet_id = module.public_subnet.subnet_id[keys(local.public_subnet_cidr_blocks)[0]] 구문으로 첫 번째 인덱스의 서브넷의 id를 주입해주게 된다.
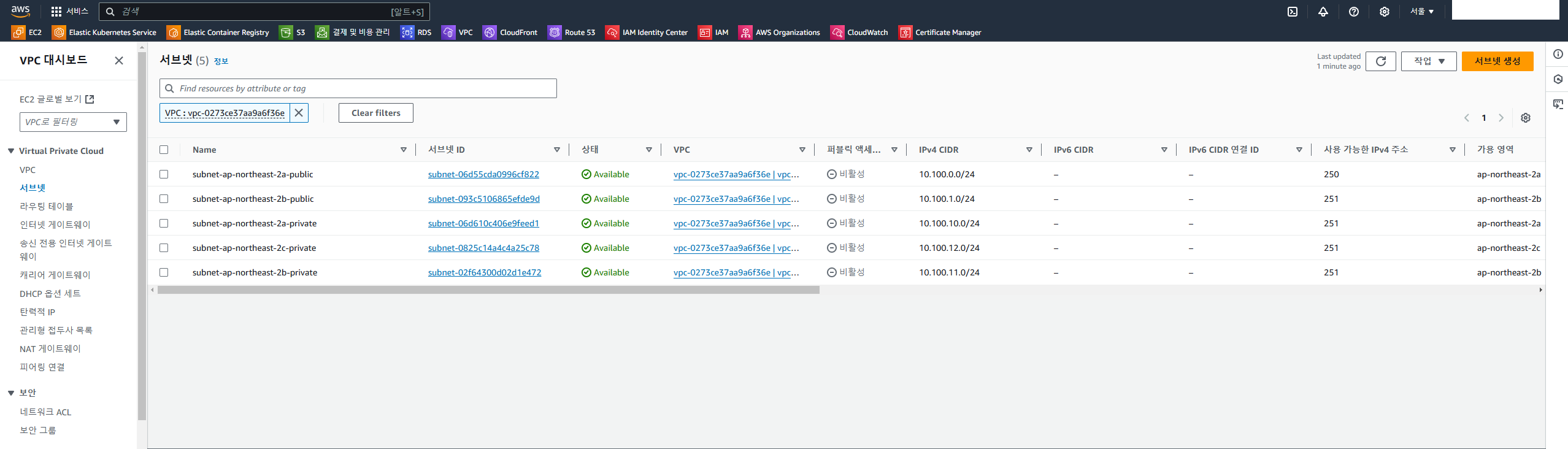
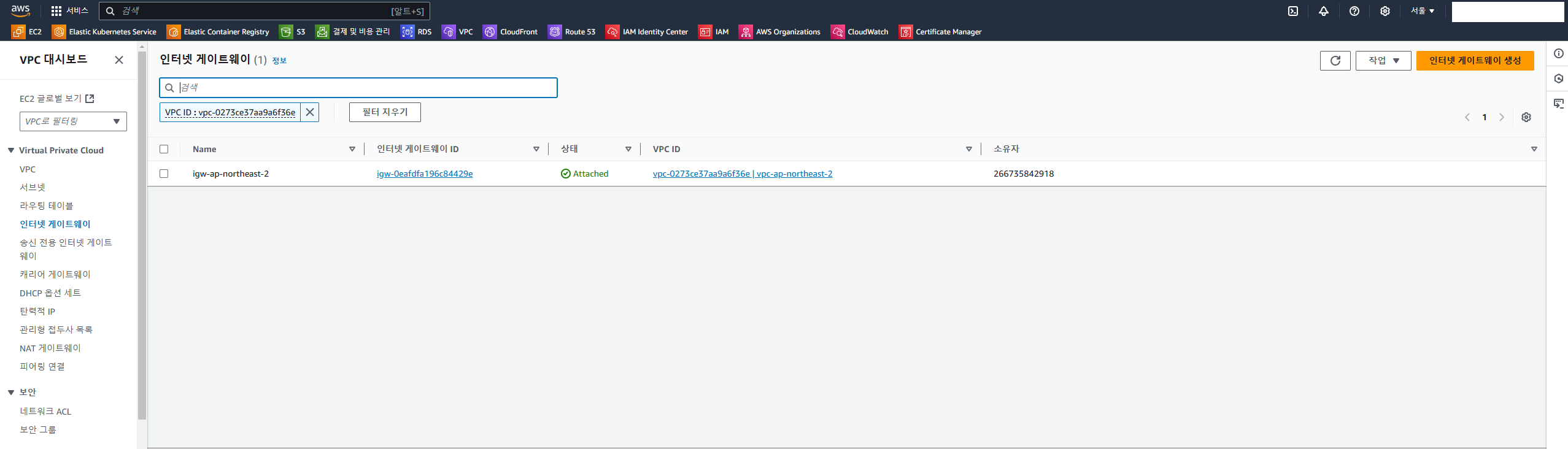
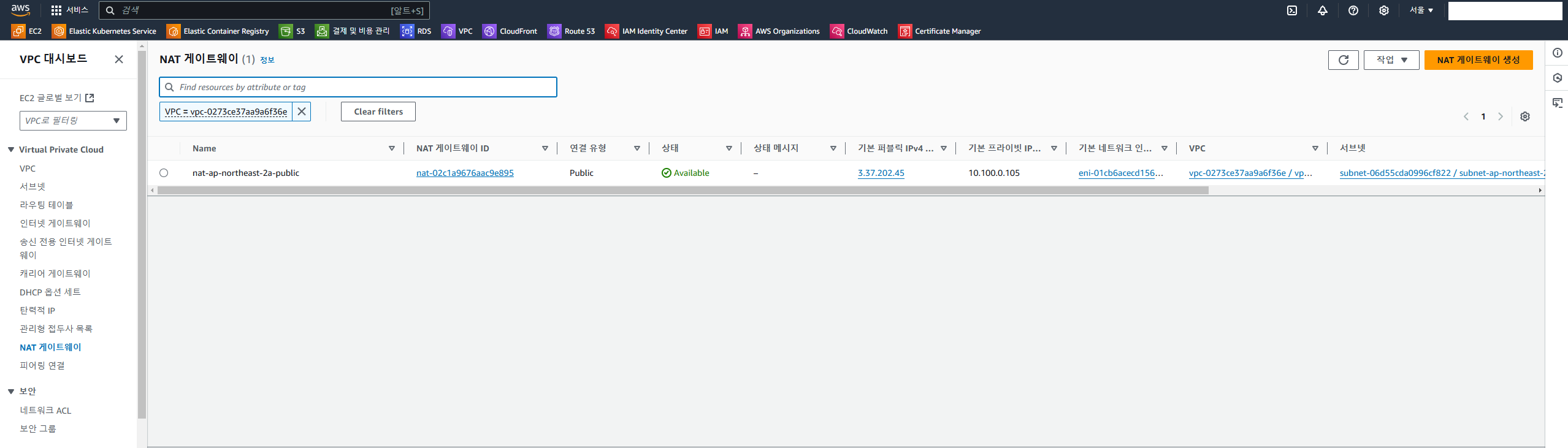
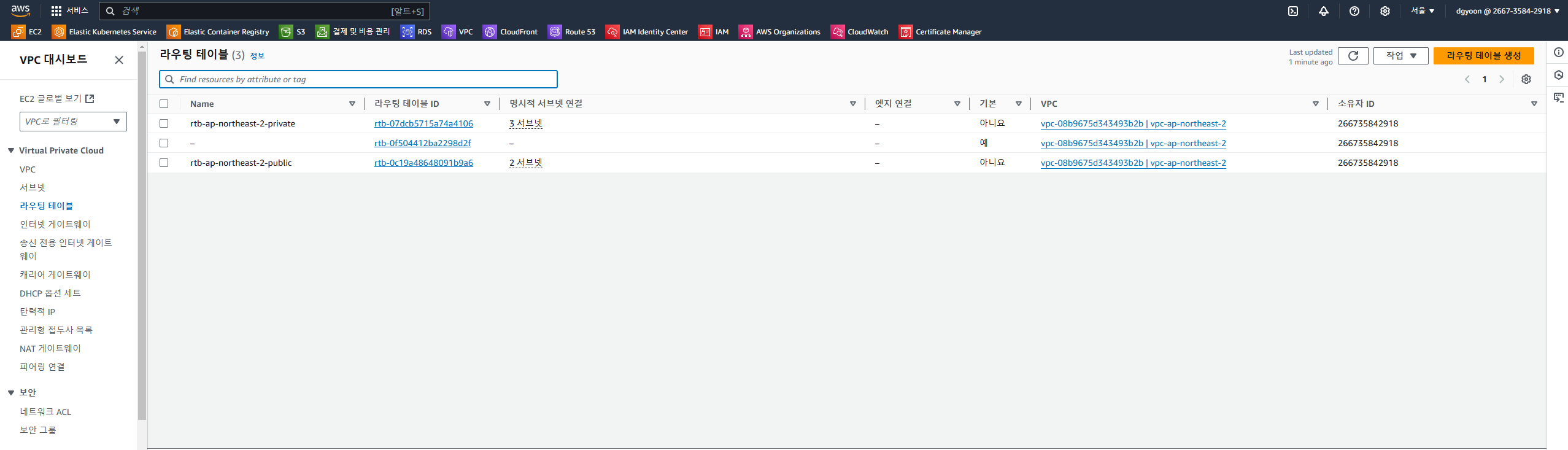
이후 terraform plan → terraform apply → yes 까지 진행해주면 아래 사진과 같이 퍼블릭 서브넷 2, 프라이빗 서브넷 3, 인터넷 게이트웨이, NAT 게이트웨이, 라우트 테이블까지 생성된다.
서브넷
인터넷 게이트웨이
NAT 게이트웨이
라우트 테이블
그리고 VPC 리소스 맵을 통해 서브넷과 게이트웨이간 경로를 확인한 결과는 아래와 같다.
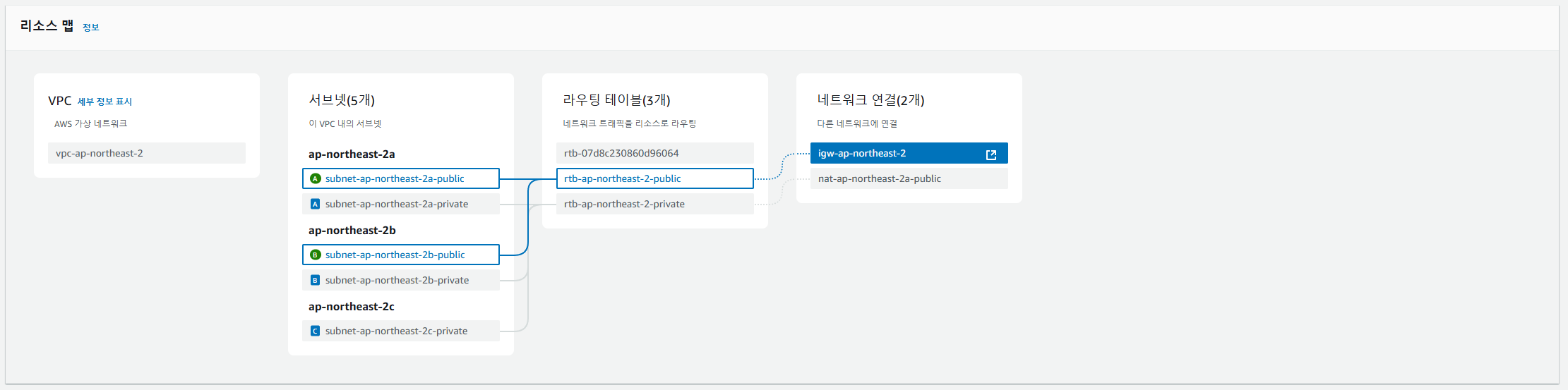
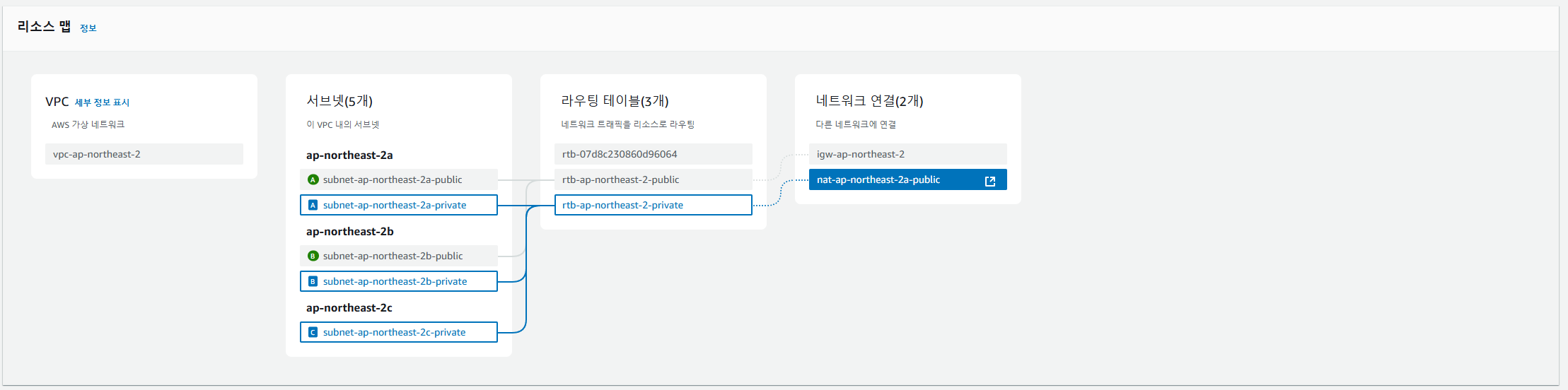
퍼블릭 서브넷은 인터넷 게이트웨이로, 프라이빗 서브넷은 NAT 게이트웨이로 잘 연결되었다.
지금까지 완성된 설계도는 이렇다.
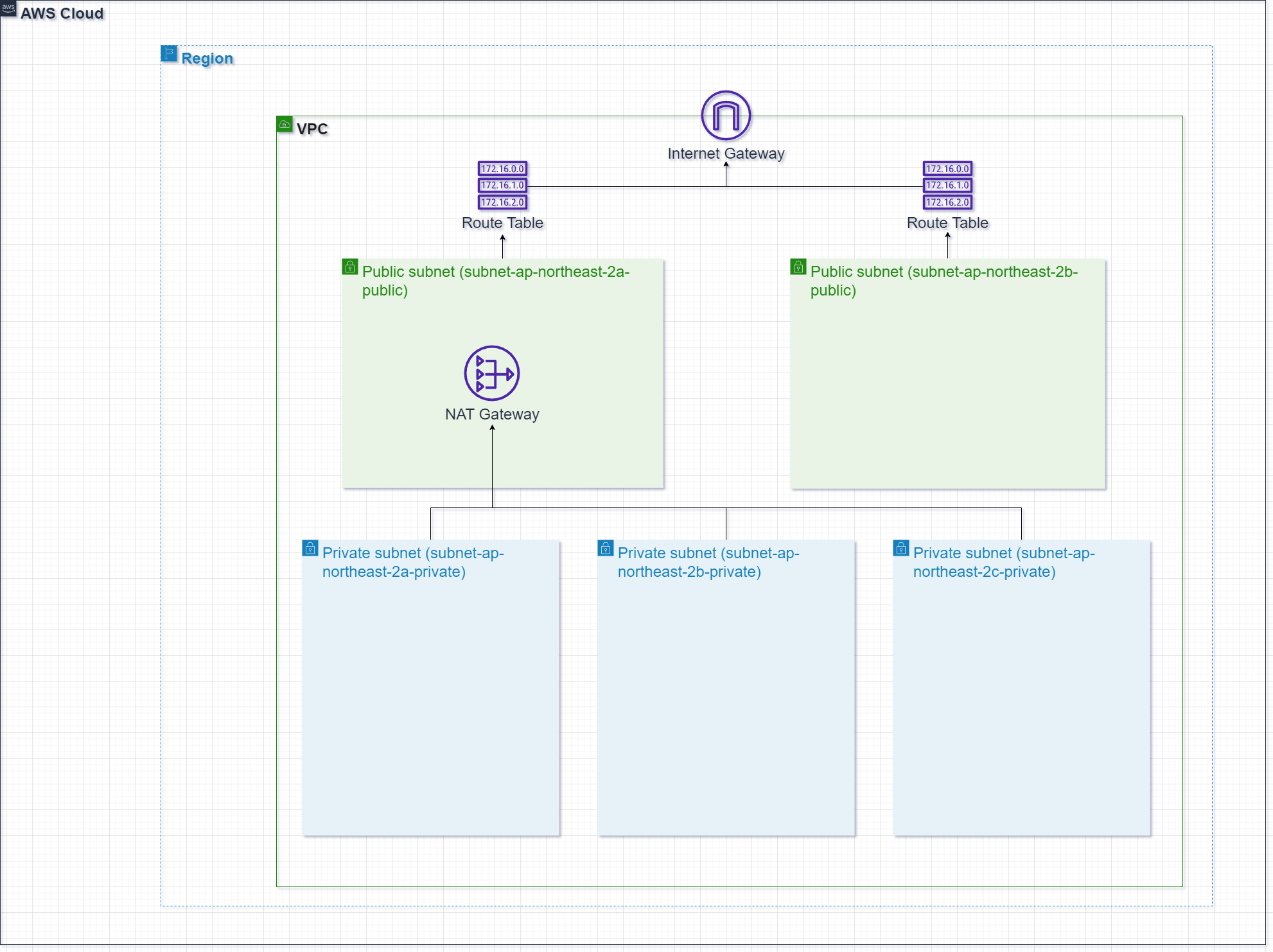
마치며
이처럼 서브넷 리소스를 모듈화해 하나의 서브넷 모듈로 두 종류의 서브넷을 생성해볼 수 있었다.
더 세분화시킬 점은 있지만, 이번 글에서는 결국 반복되는 resource 블록을 줄이고 필요한 설정들(NAT, IGW, Route TABLE)을 하나의 모듈로 만들어 추상화할 수 있었다는 점에 주목하면 좋을 듯 싶다.
물론 나는 resource 블록으로 직접 퍼블릭, 프라이빗 서브넷 추가하는게 더 좋은데요?라는 생각이 들면 그렇게 해도 된다.
남들이 자주 사용하는 구조라고 해도 결국 나에게 맞는 구조를 찾고 적용해야 하기에 항상 정답은 없고 장단점이 존재하는 선택의 차이라고 보면 좋다.
(단지, 남들이 자주 사용하는 구조가 나에게도 맞는 구조가 될 가능성이 높다는 점...)
다음 글에서는 배스천 호스트로 사용할 EC2 인스턴스까지 생성하고 EKS 클러스터를 만들어 파드까지 배포해볼 것이다.
