
[SWEA/1257] K번째 문자열
Suffix 배열 & LCP
- Suffix 배열은 문자열의 부분 문자열을 다루는 데 매우 유용하게 사용되는 자료구조이다.
- LCP는 생성된 접미어 배열 문자열들의 공통 접두어 개수를 저장한다.
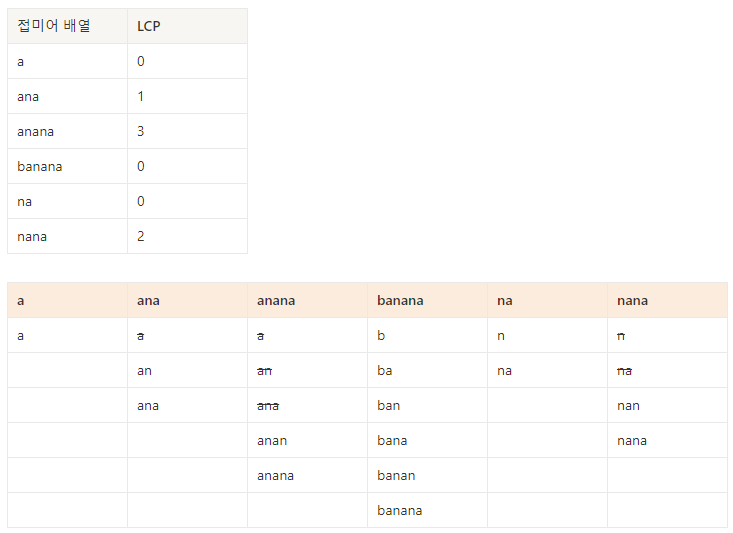
예시 ( 문자열 : banana )
1. 접미어 배열 생성 & 정렬
- 문자열의 오른쪽에서 왼쪽으로 하나씩 문자를 더해주며 접미어 배열에 저장한다.

static void getSuffixArr() {
String s = "";
for (int i = str.length() - 1; i > -1; i--) {
s = str.charAt(i) + s;
suffixArr.add(s);
}
Collections.sort(suffixArr);
}2. 각 접미어 문자열들의 부분 문자열을 생성 & LCP배열 생성
- 아래 표는 접미어 배열의 각 문자열의 부분 문자열이다.
코드를 살펴보면 앞, 뒤 문자열을 비교한다.
앞에서부터 한 글자씩 비교하여 같으면 카운트한다.
오른쪽으로 idx를 이동하며 비교하다가 idx가 두 문자열 중 한 문자열의 길이만큼 이동하였거나, 서로 다른 문자가 나타나면 stop한다.
그리고 카운트한 횟수를 LCP에 저장한다. - 즉, LCP에 저장한 카운트 횟수는 앞 문자열의 부분 집합에 현재 문자열의 부분 집합과 똑같은 부분 문자열이 포함된 개수이다.
static void setLCP() {
for (int i = 1; i < str.length(); i++) {
int idx = 0;
int cnt = 0;
String str1 = suffixArr.get(i - 1);
String str2 = suffixArr.get(i);
while (true) {
// ana와 anana를 비교해서 LCP를 만든다고 가정하자.
// 앞 (idx 0)부터 비교를 시작한다. 만약 같으면 anana의 LCP에 +1을 해주고 다음 idx로 진행한다.
// 진행하다 어느 문자열 중 하나의 길이 끝 idx에 도달하게 된다면 중단한다. 또는 두 문자열이 다른 값을 가지면 중단한다.
if (idx >= str1.length() || idx >= str2.length() || str1.charAt(idx) != str2.charAt(idx)) {
LCP[i] = cnt;
break;
} else {
cnt++;
idx++;
}
}
}
}3. 2번 설명의 결과를 통해 원본 문자열의 문자열 부분 집합 구하기
- 접미어 배열(suffixArr)의 문자열 개수만큼 반복문을 수행한다.
-
각 접미어의 문자열 앞부터 문자를 하나씩 꺼낸다.
-
문자를 하나씩 더하는데 이때 중요한 것은 LCP를 확인하는 것이다.
LCP의 값보다 해당 문자의 idx가 작다면, 부분 문자열로 추가하지 않는다.
만약 LCP의 값보다 크다면, 원본 문자열의 부분 문자열로 추가해준다.예를 들어 “ana”의 LCP 값은 1이다.
이 뜻은 ana의 부분 문자열에는 앞 문자열의 부분 문자열과 중복되는 것이 하나(”a”) 존재한다는 뜻으로 중복으로 추가하면 안된다.
따라서 “ana”의 부분 문자열은 “na”, “ana”만 해당할 수 있다.
-
static void getSubString() {
for (int i = 0; i < suffixArr.size(); i++) {
String s = "";
for (int j = 0; j < suffixArr.get(i).length(); j++) {
s += suffixArr.get(i).charAt(j);
if (j >= LCP[i])
subString.add(s);
}
}
}완성 코드
import java.io.*;
import java.util.*;
public class Solution {
static BufferedReader br;
static int K;
static String str;
static List<String> suffixArr;
static int[] LCP;
static List<String> subString;
public static void main(String[] args) throws Exception {
br = new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine());
for (int t = 1; t < T + 1; t++) {
init();
getSuffixArr();
setLCP();
getSubString();
System.out.println("#" + t + " " + subString.get(K - 1));
}
}
static void getSubString() {
for (int i = 0; i < suffixArr.size(); i++) {
String s = "";
for (int j = 0; j < suffixArr.get(i).length(); j++) {
s += suffixArr.get(i).charAt(j);
if (j >= LCP[i])
subString.add(s);
}
}
}
static void setLCP() {
for (int i = 1; i < str.length(); i++) {
int idx = 0;
int cnt = 0;
String str1 = suffixArr.get(i - 1);
String str2 = suffixArr.get(i);
while (true) {
// ana와 anana를 비교해서 LCP를 만든다고 가정하자.
// 앞 (idx 0)부터 비교를 시작한다. 만약 같으면 anana의 LCP에 +1을 해주고 다음 idx로 진행한다.
// 진행하다 어느 문자열 중 하나의 길이 끝 idx에 도달하게 된다면 중단한다. 또는 두 문자열이 다른 값을 가지면 중단한다.
if (idx >= str1.length() || idx >= str2.length() || str1.charAt(idx) != str2.charAt(idx)) {
LCP[i] = cnt;
break;
} else {
cnt++;
idx++;
}
}
}
}
static void getSuffixArr() {
String s = "";
for (int i = str.length() - 1; i > -1; i--) {
s = str.charAt(i) + s;
suffixArr.add(s);
}
Collections.sort(suffixArr);
}
static void init() throws Exception {
K = Integer.parseInt(br.readLine());
str = br.readLine();
suffixArr = new ArrayList<>();
LCP = new int[str.length()];
subString = new ArrayList<>();
}
}