CPU 스케줄링

다중 프로그래밍의 목적은 CPU 이용률을 최대화하기 위해 항상 실행 중인 프로세스를 가지게 하는 데 있다. 다중 프로그래밍에 대한 기본 아이디어는 비교적 간단하다. 단일 프로세스, 스레드 환경에서는 어떤 I/O 요청이 완료되기를 기다리는 동안 CPU는 놀게 된다. 다중 프로그래밍은 이렇게 놀면서 낭비되는 CPU를 생산적으로 활용하려는 시도이다. 다수의 프로세스를 메모리 내에 유지한다. 어떤 프로세스가 대기해야 할 경우, 운영체제는 CPU를 그 프로세스로부터 회수해 다른 프로세스에 할당한다. 하나의 프로세스가 대기해야 할 때마다, 다른 프로세스가 CPU 사용을 양도받을 수 있다. 다중 코어 시스템에서 CPU를 바쁘게 유지하는 이 개념은 시스템의 모든 처리 코어로 확장된다.
이러한 종류의 스케줄링은 운영체제의 기본적인 기능이다. 거의 모든 컴퓨터 자원들은 사용되기 전에 스케줄 된다. CPU는 중유한 컴퓨터 자원 중 하나이기 때문에 CPU의 스케줄링은 운영체제 설계의 핵심이 된다.
CPU Burst, I/O Burst
프로세스에서 연산이 필요한 구간이 있을 것이고, 입출력이 필요한 구간이 있을 것이다. 이 연산이 필요한 구간을 CPU Burst라고 하고 입출력이 필요한 구간을 I/O Burst라고 한다.
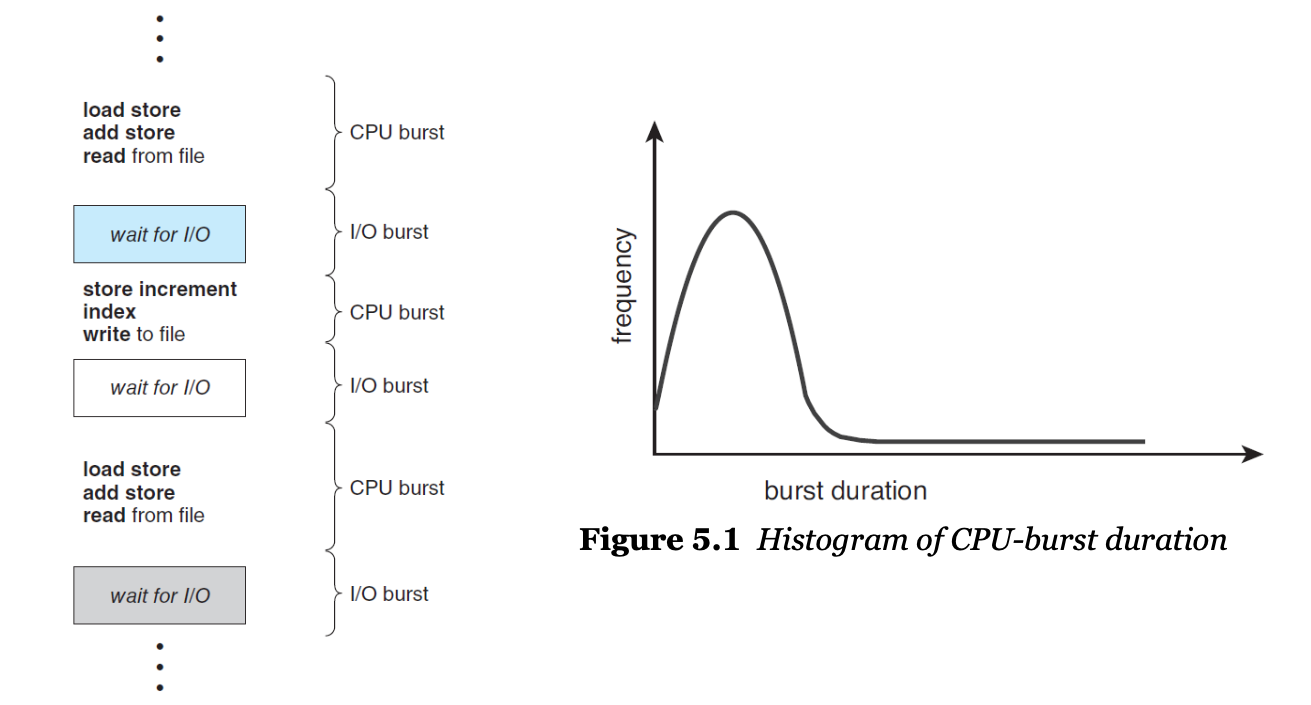
프로세스마다 그리고 컴퓨터마다 차이는 있지만, CPU 버스트들의 지속 시간을 광범위 하게 측정해보면 아래의 그림과 유사한 빈도수 곡선을 갖는 경향이 있다. 이 곡선은 일반적으로 지수형 또는 초지수형(htperexponential)으로 특성화된다. 짧은 CPU 버스트가 많이 있으며, 긴 CPU 버스트는 적다. I/O 중심의 프로그램은 전형적으로 짧은 CPU 버스트를 많이 가질것이다. CPU 지향 프로그램은 다수의 긴 CPU 버스트를 가질 수 있다. 이러한 분포는 CPU 스케줄링 알고리즘을 구현할 때 매우 중요할 수 있다.
CPU 스케줄러
CPU가 유휴(Idle) 상태가 될 때마가, 운영체제는 준비 큐에 있는 프로세스 중에서 하나를 선택해 실행해야 한다. 선택 절차는 CPU 스케줄러에 의해 수행된다. 스케줄러는 실행 준비가 되어 있는 메모리 내의 프로세스 중에서 선택하여, 이들 중 하나에게 CPU를 할당한다.
준비 큐(Ready Queue)는 반드시 선입선출 큐가 아니여도 되는 것에 유의해야한다. 준비 큐는 선입선출 큐(FIFO Queue), 우선순위 큐(Priority Queue), 트리(Tree) 또는 연결 리스트(Linked List)로 구현할 수 있다.
개념적으로 볼 때 준비 큐에 있는 모든 프로세스는 CPU에서 실행될 기회를 기다리며 대기하고 있다. 큐에 있는 레코드들은 일반적으로 프로세스들의 프로세스 제어 블록(PCB)들이다.
선점(Preemptive) vs 비선점(Non-preemptive)
비선점형(Non-preemptive)는 프로세스가 실행 상태에서 대기 상태로 전활 될 때 혹은 프로세스가 종료 될 때 스케줄링이 발생하는 것을 말하고,
그렇지 않으면 선점형(Preemptive)이라고 한다. 선점형은 즉 쉽게 말하면 쫓아낼 수 있다는 뜻이다.
디스패처(Dispatcher)
CPU 스케줄링 기능에 포함된 또 하나의 요소는 디스패처(Dispatcher)이다. 디스패처는 CPU 코어의 제어를 CPU 스케줄러가 선택한 프로세스에 주는 모듈이며 아래와 같은 작업을 한다.
- 한 프로세스에서 다른 프로세스로 문맥을 교환(context switch)하는 일
- 사용자 모드(user mode)로 전환하는 일
- 프로그램을 다시 시작하기 위해 사용자 프로그램의 적절한 위치로 이동하는 일
디스패처는 모든 프로세스의 문맥 교환 시 호출되므로, 가능한 한 최고로 빨리 수행되어야한다. 디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간을 디스패치 지연(dispatch latency)라고 한다.
아래의 그림에서 디스패처의 역할을 확인할 수 있다.
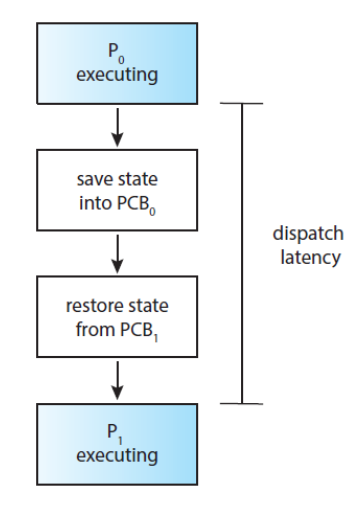
쉽게 말하면 스케줄러가 교체할 프로세스를 선택하면 디스패처가 실제로 교체를 해주는 역할을 한다.
스케줄링 기준(Scheduling Criteria)
서로 다른 CPU 스케줄링 알고리즘들은 다른 특성이 있으며 한 부류의 프로세스들을 다른 부류보다 더 선호할 수 있다. 특정 상황에서 알고리즘을 선택하려면, 다양한 알고리즘들의 서로 다른 특성을 반드시 고려해야 한다.
CPU 스케줄링 알고리즘을 비교하기 위한 여러 기준이 제시되었는데, 비교하는 데 사용되는 특성에 따라 최선의 알고리즘을 결정하는 데 큰 차이가 발생한다. 사용하는 기준은 다음을 포함한다.
- CPU utilization(이용률): 가능한 한 CPU를 최대한 바쁘게 유지해야한다.
- Throughtput(처리량): 단위 시간당 완료된 프로세스의 개수
- Turnaround time(총처리 시간): 프로세스를 실행하는 데 소요된시간, 프로세스의 제출 시간과 완료 시간의 간격으로 총처리 시간은 준비큐에서 대기한 시간, CPU에서 실행하는 시간, 그리고 I/O 시간을 합한 시간이다.
- Waiting Time(대기 시간): 프로세스가 준비큐(ready queue)에서 대기하는 시간
- Response time(응답 시간): 첫번째 응답이 나올 때까지의 시간.
스케줄링 알고리즘(Scheduling Algorithms)
CPU 스케줄링은 준비 큐에 있는 어느 프로세스에 CPU 코어를 할당할 것인지를 결정하는 문제를 다룬다. 대부분의 최신 CPU 아키텍처에는 여러 개의 처리 코어가 있지만, 일단 여기서는 한 개의 코어를 가진 즉 CPU가 한 개인 시스템에 대한 스케줄링 알고리즘을 다뤄보자.
FCFS(First Come First Served)
- 가장 단순한 스케줄링 알고리즘
- CPU를 먼저 요청하는 프로세스가 CPU를 먼저 할당받는다.
- FIFO 큐로 쉽게 관리할 수 있다.
CPU Burst time이 아래와 같은 프로세스들을 가정해 보자

프로세스가 아래와 같은 순서로 온다면,

평균 대기 시간은 (0+24+27)/3 = 17밀리초이고, 평균 총처리 시간은 (24+27+30)/3 = 27밀리초이다.
이에 반해 아래와 같은 순서로 프로세스가 온다면,

평균 대기 시간은 (0+3+6)/3 = 9밀리초이고, 평균 총처리 시간은 (3+6+30)/3 = 13밀리초이다.
이를 통해 FCFS는 일반적으로 최소의 평균 대기 시간과 총처리 시간을 갖지 못해 효율적이지 못하고 CPU Burst 시간이 크게 변할 경우에 평균대기 시간도 상당히 변할 수 있다.
이 방식이 특히 문제가 되는 상황은 하나의 CPU-bound 프로세스(CPU 소모가 큰 프로세스)와 많은 IO-bound 프로세스(I/O가 많은 프로세스)상황인데, 만약 CPU-bound 프로세스가 IO-bound 프로세스보다 앞에 배치된다면 모든 IO-bound 프로세스가 CPU-bound 프로세스의 종료를 기다려야하는 convoy effect가 발생하게 된다.
SJF(Shortest Job First)
- CPU 버스트가 가장 작은 프로세스를 우선적으로 할당한다.
- 두 프로세스가 동일한 길이의 CPU 버스트를 가지면, 순위를 정하기 위해 선입 선처리 스케줄링을 적용한다. 따라서 Shortest-next-CPU-Burst 알고리즘이라는 용어가 더 적합할 수 있다.
SJF는 waiting time 측면에서는 최적인 방식이다. 하지만 이 방식에서의 문제는 다음 CPU Burst time을 알 수 있는 방법이 없다는 점이다. 이에 따라 근사적으로 다음 CPU Burst time을 예측한다. 이 예측은 과거의 CPU 사용량에 기반하여 이루어진다.
SJF는 선점형이나 비선점형일 수 있는데, 앞의 프로세스가 실행되는 동안 새로운 프로세스가 준비 큐에 도착하면 선택이 발생한다. 새로운 프로세스가 현재 실행되고 있는 프로세스의 남은 시간보다도 더 짧은 CPU Burst틀 가질 수도 있다. 선점형 SJF 알고리즘은 현재 실행하는 프로세스를 선점할 것이고, 반면에 비선점형 SJF 알고리즘은 현재 실행하고 있는 프로세스가 자신의 CPU 버스트를 끝내도록 허용한다.
선점형 SJF 알고리즘은 Shortest-reamaining-time-first 스케줄링이라고도 물린다.
RR(Round-Robin)
라운드 로빈(RR) 스케줄링 알고리즘은 선입 선처리(FCFS) 스케줄링과 유사하지만 시스템이 프로세스들 사이를 옮겨 다닐 수 있도록 선점이 추가된다. 시간 할당량(time quantum), 또는 타임슬라이스(time-slice)라고 하는 작은 단위의 시간을 정의한다.
준비 큐는 원형 큐로 동작하며 프로세스를 실행하며 두가지 경우 중 하나가 발생한다.
1. 프로세스의 CPU 버스트가 시간 할당량보다 적은 경우
2. 프로세르의 CPU 버스트가 한번의 시간 할당량 보다 긴 경우
1 의 경우에는 자신이 자발적으로 CPU를 방출할 것이고 2의 경우에는 타이머가 끝나고 운영체제에 인터럽트를 발생한다. 이 때 context switch가 일어나고 실행하던 프로세스는 준비 큐의 꼬리에 넣어지고 CPU 스케줄러는 준비큐의 다음 프로세스를 선택한다.
RR 스케줄링은 평균 대기 시간이 오히려 늘어질 수 있다.
RR 스케줄링의 성능은 time quantum에 의해 좌우되는데, 이 time quantum은 문맥 교환 시간보다는 길어야지 프로세스를 처리할 시간이 생기고, 너무 길어지면 FCFS 스케줄링 방식으로 퇴보하게 된다.
Priority-base
우선순위 기반(Priority-base) 스케줄링은 가장 높은 우선순위를 가진 프로세스에서 할당된다. 우선순위가 같은 프로세스들은 선입 선터리(FCFS) 순서로 스케줄된다.
우선순위는 내부적 또는 외부적으로 정의될 수 있다. 내부적으로 정의돈 우선순위는 프로세스의 우선순위를 계산하기 위해 어떤 측정 가능한 양들을 사용한다. 예를 들면 시간 제한, 메모리 요구, 열린 파일의 수, 평균 I/O 버스트의 평균 CPU 버스트에 대한 비율 등이 우선순위 계산에 사용된다. 외부적 우선순위는 프로세스의 중요성, 컴퓨터 사용을 위해 지불되는 비용의 유형과 양, 그 작업을 후원하는 부서 그리고 정치적인 요인등과 같은 운영체제 외부적 기준에 의해 결정된다.
우선 순위 스케줄링 알고리즘의 주요 문제는 indefinite blocking(무한 봉쇄)또는 starvation(기아) 상태이다. 우선순위 스케줄링 알고리즘을 사용할 영구 낮은 우선순위 프로세스들이 CPU를 무한히 대기하는 경우가 발생한다. 이런 현상의 한가지 해결 방안은 aging(노화) 인데 이는 시스템에서 대기하는 프로세스들의 우선순위를 점진적으로 증가시키는 것이다.
Multi-Level Queue
다단계 큐 스케줄링은 우선순위마다 별도의 큐를 갖는 알고리즘이다.
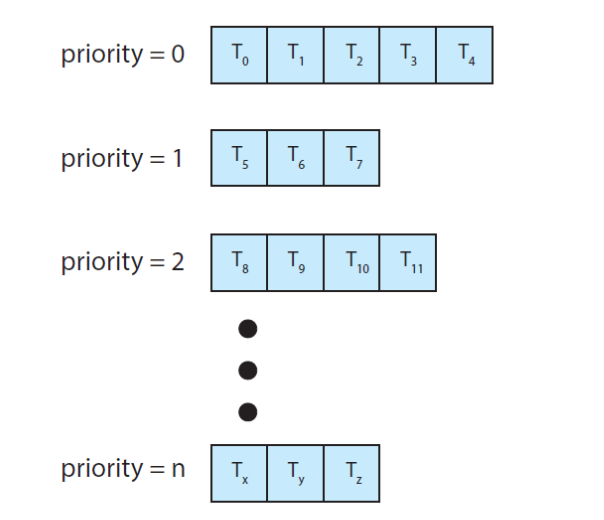
프로세스 유형에 따라 프로세스를 여러 개의 개별 큐로 분할하기 위해 다단계 큐 스케줄링 알고리즘을 사용할 수도 있다.
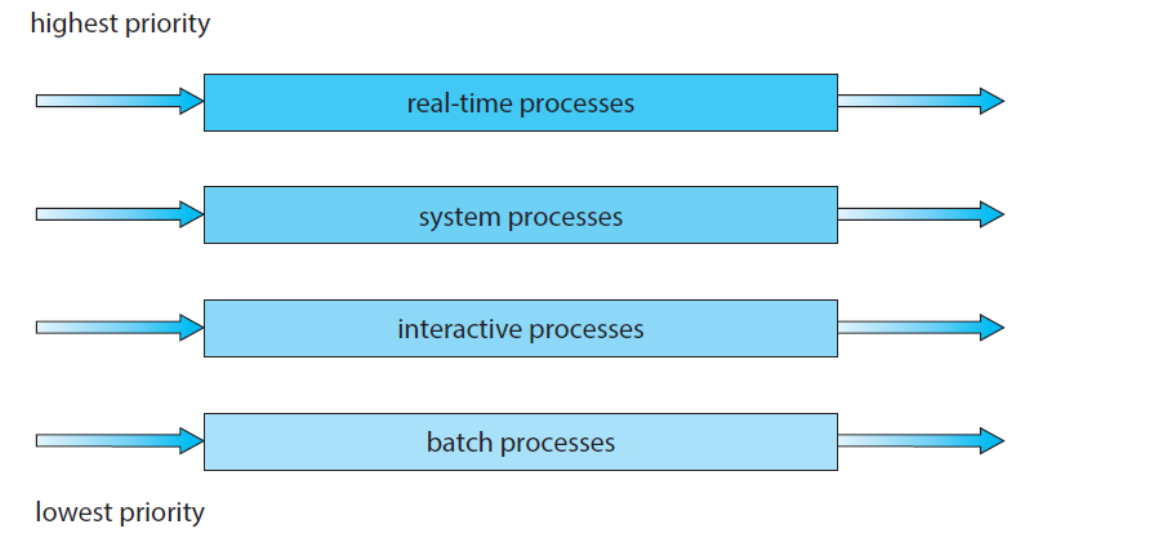
예를 들어 흔히 포그라운드(대화형)프로세스와 백그라운드(배치) 프로세스를 구분한다. 이 두 가지 유형의 프로세스는 응답 시간 요구 사항이 다르므로 스케줄링 요구 사항이 다를 수 잇다.
추가로, 큐와 큐 사이에 스케줄링도 반드시 있어야 하며, 일반적으로 고정 우선순위의 선점형 스케줄링으로 구현된다. 예를 들어, 실시간 큐는 대화형 큐보다 절대적으로 높은 우선순위를 가질 수 있다.
MultiLevel Feedback Queue
다단계 큐는 일반적으로 프로세스들이 시스템 진입 시에 영구적으로 하나의 큐에 할당된다. 예를 들어, 포그라운드와 백그라운드 프로세스를 위해 별도의 큐가 있으면, 프로세스들은 한 큐에서 다른 큐로 이동하지 않는다. 왜냐하면 프로세스들이 포그라운드와 백구라운드의 특성을 바꾸지 않기 때문이다. 이러한 방식은 스케줄링 오버헤드가 장점이 있으나 용통성이 적다.
대조적으로 다단계 피드백 큐(MultiLevel Feedvack Queue) 스케줄링 알고리즘에서는 프로세스가 큐들 사이를 이동하는 것을 허용한다.
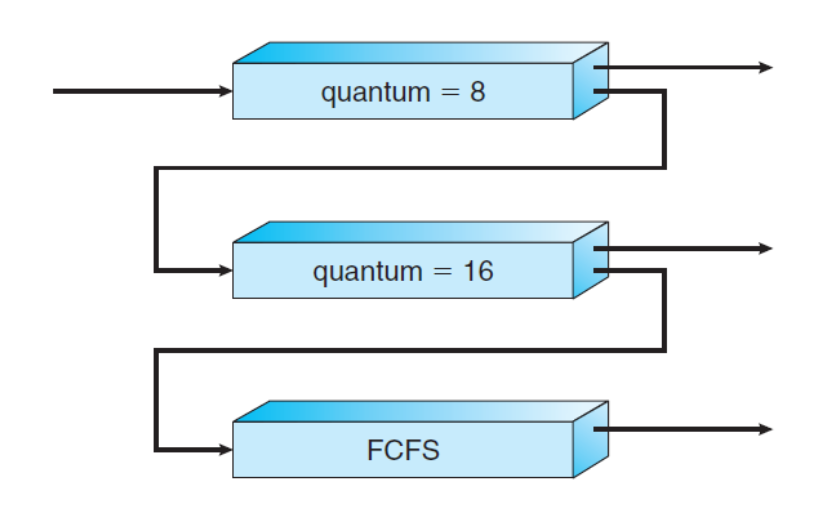
이 알고리즘은 프로세스들을 CPU 버스트 성격에 따라서 구분한다. 어떤 프로세스가 CPU 시간을 너무 많이 사용하면, 늦은 우선순위의 큐로 이동된다. 이 방법에서는 I/O 중심의 프로세스와 대화형 프로세스들을 높은 우선순위의 큐에 넣는다. 마찬가지로 낮은 우선순위의 큐에서 너무 오래 대기하는 프로세스는 높은 우선순위의 큐로 이동할 수 있다. 이러한 aging을 통해 기아 상태를 예방한다.
이 스케줄링 알고리즘이 일반적으로 O/S에서사용되는 알고리즘이다. 이 알고리즘은 설계 중인 특정 시스템에 부합하도록 구성 가능하다. 그러나 가장 좋은 스케줄러로 동작하기 위해서는 모든 매개변수들의 값을 선정하는 특정 방법이 필요하기 때문에 가장 복잡한 알고리즘이기도 하다.
스레드 스케줄링
현대적인 컴퓨터에서는 스케줄 되는 대상은 프로세스가 아니라 커널 수준 스레드이다. 운영체제는 user threads와 kernel threads중에서 kernel thread를 관리하고 user threads는 스레드 라이브러리에 의해 관리된다.
해당 게시물은 흔히 공룡책이라고 불리는 Avraham Silberschatz, ⌜Operating System Concepts 10th edition⌟, 박민규 옮김 과 인프런 주니온님의 운영체제 공룡책 강의 및 구글링을 통해 접한 글들을 보며 공부한 내용을 작성한 것입니다.
수강 강의
운영체제 공룡책 강의, 인프런, 주니온
출처 및 참고자료
Avraham Silberschatz, ⌜Operating System Concepts 10th edition⌟, 박민규 옮김
