과거 정보를 현재에 반영해서 사용할 수는 없을까?
순차 데이터
순차 데이터(sequential data)는 ‘어떤 순서를 가진 데이터’로 순서가 변경될 경우 데이터의 특성을 잃어버리는 데이터를 말한다. 예를 들어 “I like coffee.”라는 문장은 이해할 수 있지만 ‘Like coffee I”라는 문장은 이해할 수 없다. 문장 뿐만 아니라 주가, DNA 염기서열, 날씨와 같은 시계열 데이터(time series data)는 모두 순차 데이터에 해당한다.
FFNN과 달리 순차 데이터를 분석하기 위한 모델은 과거 정보를 기억하는 기능이 필요하다. 과거 정보를 기억하기 위해 사용하는 대표적인 방법은 이전에 사용한 데이터를 재사용하는 방법이 있다. 데이터를 재사용하기 위해서는 신경망 층에 순환될 필요가 있다. 이런 알고리즘을 우리는 순환 신경망이라고 부른다.
Linear Regression, KNN, Random Forest 같은 전통적인 머신러닝 모델이나 CNN, ANN과 같은 딥러닝 모델은 데이터가 입력부터 출력까지 일방향으로만 전달되어 피드포워드 신경망(Feedforward neural network, FFNN)이라고 한다.
.
.
.
순환 신경망(RNN)
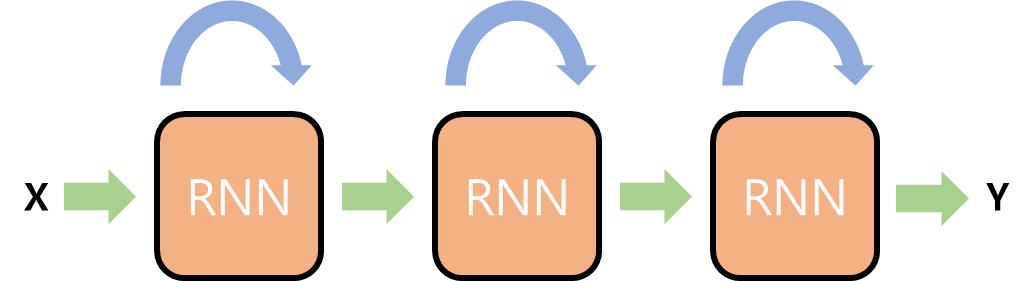
순환 신경망(Recurrent neural network, RNN)에서 데이터가 순환되는 한 단계를 time step이라고 부르고, 순환층을 cell이라고 부른다. 또 cell 출력 결과는 hidden state라고 부른다. 기본적인 순환 신경망 구조는 다음과 같다.

새로운 X 값이 입력되면 cell을 통과해 hidden state가 된다. h는 재사용 되어 다음 시점 X와 결합되어 새로운 h를 만든다. 새로운 hidden state는 다음 X값을 위해 재사용 된다. 이처럼 hidden state가 계속해서 순환해서 순환 신경망이라고 부르는 것이다.
from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.SimpleRNN())RNN모델은 keras의 SimpleRNN클래스를 사용하면 되서 상당히 간단하다.
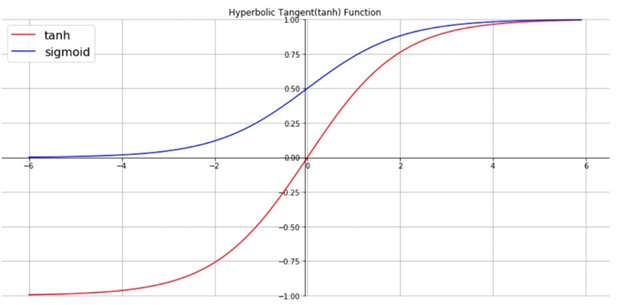
순환 신경망의 활성화 함수는 일반적으로 하이퍼볼릭 탄젠트(tanh) 함수를 많이 사용한다.
시그모이드 함수와 달리 Y값의 범위가 -1 ~ 1이다. 시그모이드 함수보다 학습 효율성이 뛰어나고 기울기 소실 문제가 적은 편이다.
.
.
.
다중 계층 신경망
다중 계층 신경망(Multi-Layer RNN)은 여러 RNN 층을 추가시킨 모델이다.
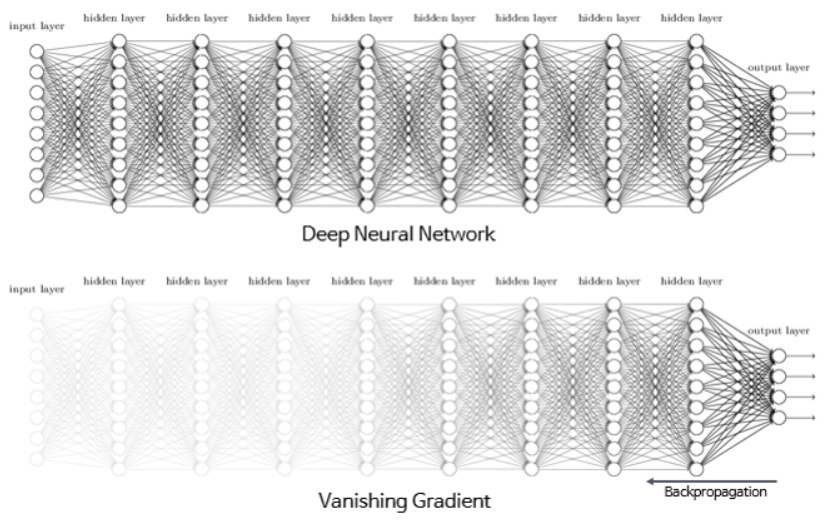
다층 신경망이 simplt rnn보다 뛰어난 학습 효율을 보일지 몰라도 드라마틱한 변화를 기대하기는 어렵다. 층이 많아 질수록 기울기 소실 문제가 나타나기 때문이다.
기울기 소실 문제
기울기 소실 문제는 입력층에 가까운 층의 기울기가 0에 가깝게 수렴하는 현상을 말한다. 기울기가 0이 되면 특성 값도 0이 되고 유의미한 모델을 만들 수 없게 된다. 이런 현상은 왜 일어날까?
우리는 뛰어난 신경망 모델을 만들기 위해 여러 개의 층을 추가한다. 이 때 층이 많아 질수록 그에 따른 가중치도 자연스럽게 늘어난다. 일반적으로 인공신경망에서 가중치를 업데이트 할 때 오류 역전파 알고리즘(Back propagation algorithm)을 사용한다. 오류 역전파 알고리즘은 데이터가 입력층에서 출력층으로 가는 것과 반대로 출력층에서 입력층 방향으로 가중치를 업데이트 한다. 많은 층을 지날 경우 소수점의 가중치를 계속 곱하다 보면 값은 0에 수렵하게 될 것이다.
LSTM
LSTM은 RNN이 오래된 것을 기억하지 못하는, 기울기 소실 문제를 해결하기 위해 탄생했다. LSTM 알고리즘은 기억할 것과 잊을 것을 선택해 중요한 정보만 기억하는 것이 핵심이다. LSTM도 RNN과 동일하게 입력과 가중치를 곱하고 절편을 더해 활성화 함수를 통과시키는 층을 여러 개 가지고 있다.
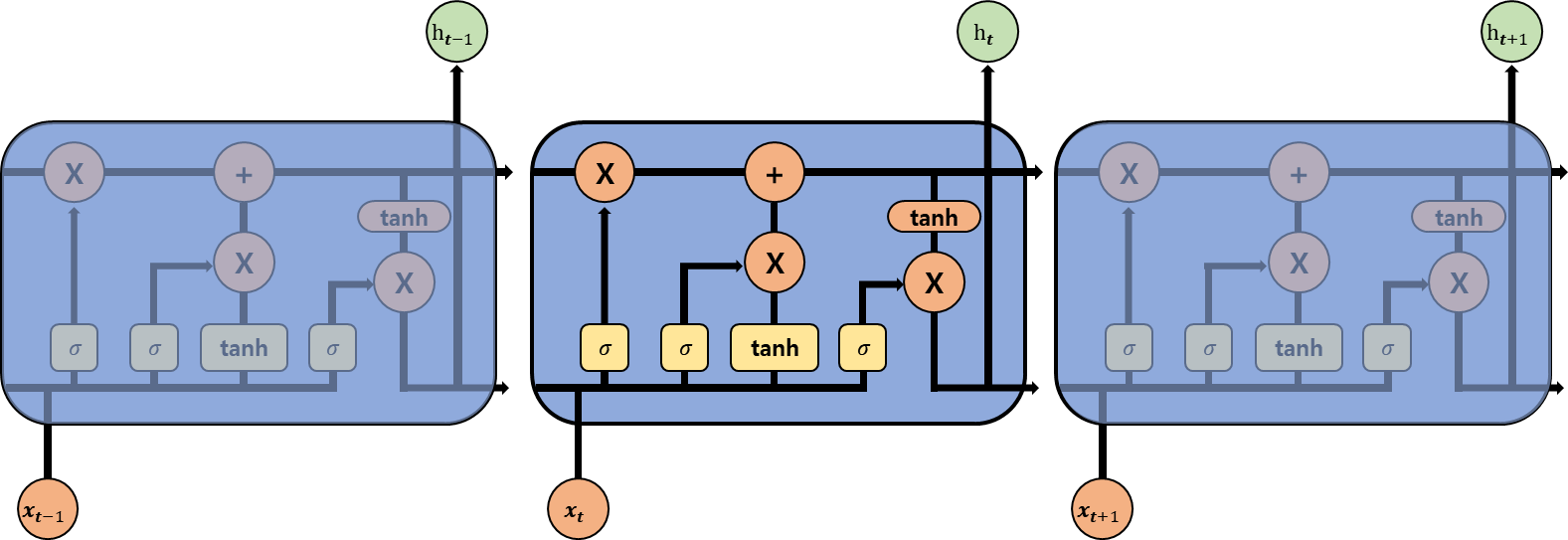
RNN과의 차이점은 순환되는 층이 2개라는 것이다. Hidden state와 Cell state에서 과거 정보가 순환한다. Cell state는 Hidden state와 달리 다음 층으로 전달되지 않는다. 또한 LSTM은 Gate를 통해서 정보를 통제한다. 이름대로 지나갈 수 있는 문을 만들어서 원하는 정보만 통과시키는 방법이다.
Input Gate
현재 정보를 얼마나 기억할 지 결정하는 Gate이다. 이전 층의 hidden state에는 tanh를 곱하고 새로운 정보에는 sigmoid 활성함수를 곱한다. 새로운 특성에 sigmoid를 곱하기 때문에 0~1 사이의 결과값으로 새로운 정보를 얼마나 사용할 지 결정한다.

Forget Gate
정보를 얼마나 잊어버릴지 결정하는 Gate이다. 입력과 hidden state를 서로 다른 가중치를 곱한 다음 sigmoid 활성 함수를 통과시킨다. 0~1 사이의 결과값을 얻기 때문에 얼마나 정보를 잊을 지 결정할 수 있다. 이전 타임스텝의 Cell state와 곱하여 새로운 Cell state를 만든다.

Output gate
다음 층으로 전달할 hidden state를 만드는 Gate이다. 먼저, 이전 hidden state값과 입력 값에 각각 다른 가중치를 곱하고 sigmoid 활성 함수를 통과시킨다. 그 출력 값과 현재 Cell state 값을 tanh 활성 함수에 통과시킨 값을 서로 곱해서 hidden state를 만든다.

from tensorflow import keras
model = keras.Sequential()
model.add(keras.layers.LSTM(n))코드도 RNN과 비슷하다. RNN 부분을 LSTM으로 바꿔주기만 하면 된다. n에는 Cell에서 사용하고 싶은 뉴런 개수를 입력하면 된다.
GRU
LSTM을 개선한 모델이다. LSTM보다 파라미터가 더욱 적어 연산 비용도 적고, 모델도 간단해 학습 속도가 더 빠르지만 비슷한 성능을 내는 모델이다. Forget Gate와 Input Gate를 합쳐 Update Gate를 만들고, Reset Gate를 추가했다.
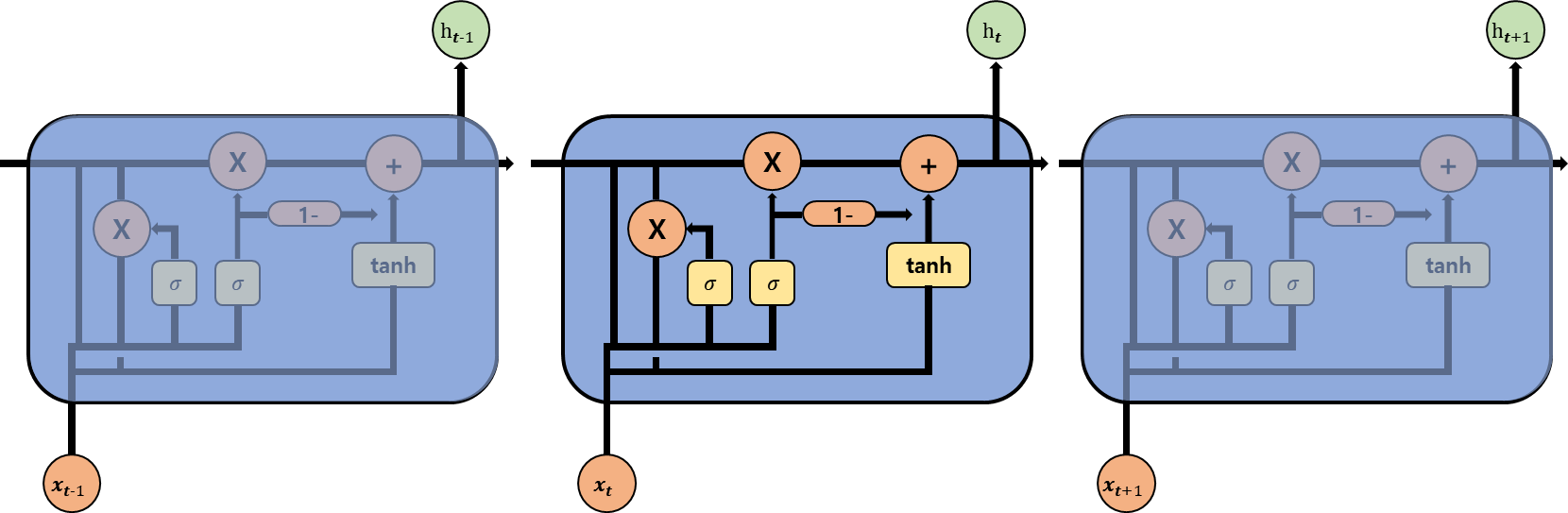
Update Gate
Forget Gate와 Input Gate를 합친 Gate이다. 이전의 정보를 얼마나 통과시킬지 결정하는 Gate이다. 입력 값과 hidden state 값을 각각 가중치에 곱하고 sigmoid 함수에 통과시켜 Forget Gate로 사용한다. 이 값을 1에서 빼 Input Gate로 사용한다.

Reset Gate
이전 hidden state의 정보를 얼마나 잊을 지를 결정하는 Gate이다. Sigmoid 활성함수를 통과시켜 0~1 사이의 범위로 잊을 정보의 양을 결정한다.

from tensorflow import keras
model = keras.Sequentail()
model.add(keras.layers.GRU())코드도 RNN과 비슷하다. 단순히 RNN을 GRU로 바꿔주기만 하면 된다.
.
.
.
