
Item 1: 가변성을 제한하라
class BankAccount {
var balance = 0.0
private set
fun deposit(depositAmount: Double) {
balance += depositAmount
}
@Throws(InsufficientFunds::class)
fun withdraw(withdrawAmount: Double) {
if (balance < withdrawAmount) {
throw InsufficientFunds()
}
balance -= withdrawAmount
}
}
class InsufficientFunds : Exception()
fun main() {
val account = BankAccount()
println(account.balance)
account.deposit(100.0)
println(account.balance)
account.withdraw(50.0)
println(account.balance)
}다음 코드를 보면 BankAccount라는 클래스는 balance라는 가변 변수를 통해 상태 관리를 하고 있다.
하지만 이처럼 상태를 가지도록 코드를 작성하는 것은 단점이 존재한다.
- 많은 변경점이 있기 때문에, 프로그램을 이해하고 디버깅하기 어렵다. 변이들 간의 관계를 이해해야 하며, 그 수가 많을 때 어떻게 변화하는지 추적하기가 어렵다.
- 가변성은 코드에 대한 추론을 어렵게 만든다. 가변 변수의 경우 언제든지 변경될 수 있으므로 그 값이 무엇인지 추론하기 어렵다.
- 멀티스레드 환경의 프로그램에서 잠재적인 충돌을 예방하기 위해 적절한 동기화가 필요하다.
- 모든 가능한 상태를 테스트해야 하기 때문에 테스트하기가 어렵다.
- 상태가 변할 때 얽혀 있는 다른 클래스에세 변경 사항을 알려야 한다. 예를 들어, 정렬된 리스트에 가변 요소를 추가하고 이를 변경 시 리스트를 다시 정렬해야 한다.
fun main() {
var num = 0
for (i in 1..1000) {
thread {
Thread.sleep(10)
num += 1
}
}
Thread.sleep(5000)
print(num)
}suspend fun main() {
var num = 0
coroutineScope {
for (i in 1..1000) {
launch {
delay(10)
num += 1
}
}
}
print(num)
}다음 코드는 각각 멀티 스레드, 멀티 코루틴을 활용하여 가변 변수의 값을 변경하고 있다. 기대되는 값은 1000이지만 동기화 처리가 되어 있지 않아 몇몇 + 연산이 손실된다. 따라서 원하는 값을 반환받지 못한다.
fun main() {
val lock = Any()
var num = 0
for (i in 1..1000) {
thread {
Thread.sleep(10)
synchronized(lock) {
num += 1
}
}
}
Thread.sleep(1000)
print(num)
}다음 코드처럼 synchronzied 키워드를 통해 동기화를 처리해 1000이라는 원하는 값을 반환받을 수 있다.
Kotlin에서 가변성 제한하기
1. 읽기 전용 속성(val)
val a = 10
a = 20 // 변경 불가val list = mutableListOf(1, 2, 3)
list.add(4)
print(list)읽기 전용 속성은 반드시 불변이거나 final값이 아니라, 가변 객체 또한 가질 수 있다.
var name: String = "Marcin
var surname: String = "Moskala"
val fullName
get() = "$name $surname"
fun main() {
println(fullName)
name = "Maja"
println(fullName)
}또한, 위 코드와 같이 사용자 정의 getter를 만들 수 있다.
읽기 전용 속성(val)의 값은 변경될 수 있지만, 변경 지점(mutations)를 제공하진 않는다. 이것이 var 대신 val을 선호하는 이유다.
하지만, val은 불변을 의미하진 않는다. getter 또는 delegate를 통해 정의될 수 있다. 이는 유연성을 제공하며, 필요하지 않을 때는 final을 사용한다.
val name: String? = "Marton"
val surname: String = "Braun"
val fullName: String?
get() = name?.let { "$it $surname"}
val fullName2: String? = name?.let { "$it $surname" }
fun main() {
if (fullName != null) {
println(fullName.length) // 스마트 캐스팅 불가
}
if (fullName2 != null) {
println(fullName2.length)
}
}다음 코드에서 fullName은 getter로 지정, fullName2는 직접 값을 지정했다.
fullName은 필드 값이 존재하지 않고 getter 메소드만 존재한다. getter 메소드가 호출될 때마다 name과 surname을 확인하기 때문에 값이 달라질 수 있다. 따라서 스마트 캐스팅이 불가능하다.
반면에, fullName2는 필드 값이 존재하고 getter에 현재의 값이 저장되므로 스마트 캐스팅이 가능하다.
2. 가변 컬렉션과 읽기 전용 컬렉션 구분하기
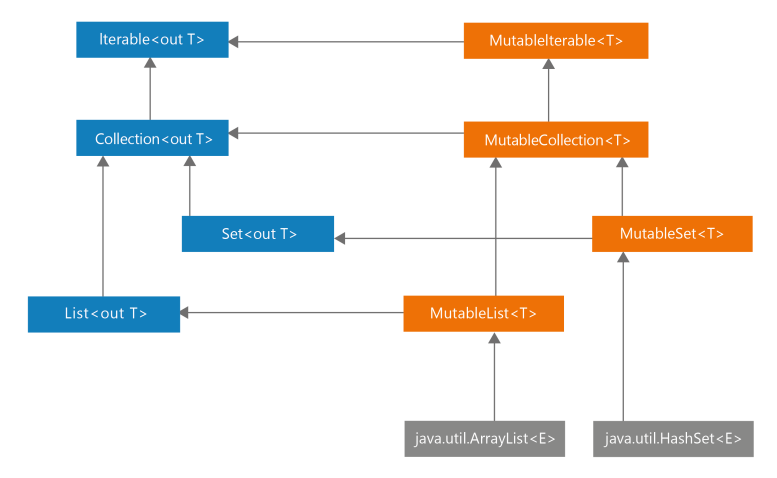
왼쪽의 Iterable, Collection, Set, List는 읽기 전용 인터페이스, 오른쪽의 MutableIterable, MutableCollection, MutableSet, MutableList는 왼쪽 인터페이스를 상속받은 가변 인터페이스이다.
읽기 전용 컬렉션은 반드시 불변한 것은 아니지만, 제공하는 인터페이스를 통해서는 변경 불가능하다.
inline fun <T, R> Iterable<T>.map(
transformation: (T) -> R
): List<R> {
val list = ArrayList<R>()
for (elem in this) {
list.add(transformation(elem))
}
return list
}예를 들어, Iterable.map 함수는 ArrayList(가변 리스트)를 List(읽기 전용 인터페이스)로 변환한다.
val list = listOf(1, 2, 3)
if (list is MutableList) {
list.add(4) // 에러 발생
}val list = listOf(1, 2, 3)
val mutableList = list.toMutableList()
mutableList.add(4)만약, 컬렉션 안의 값을 수정하고 싶다면 List.toMutableList 메소드처럼 가변 컬렉션으로 변경하는 메소드를 사용해야 한다.
절대로 읽기 전용 인터페이스를 읽고 쓸 수 있는 인터페이스로 다운캐스팅을 하면 안된다. 이는 추상화를 무시하고 예기치 못한 결과를 초래하기 때문이다.
3. 데이터 클래스의 copy
불변 객체를 사용했을 때 얻을 수 있는 이점은 다음과 같다.
- 상태가 변경되지 않기 때문에 추론하기가 더 쉽다.
- 공유하는 객체들간의 충돌을 없기 때문에 병렬화된 프로그램을 만들기 쉽다.
- 변경되지 않기 때문에 불변 객체에 대한 참조를 캐시할 수 있다.
- 생성 후에 수정할 수 없기 때문에 의도하지 않은 수정으로부터 보호하기 위해 방어적 복사(defensive copy)를 수행할 필요가 없다.
- 불변 객체는 다른 객체를 구성하기에 이상적이다. 가변과 불변 모두에 대해 결정할 수 있으며, 불변 객체에 대한 조작이 더 쉽다.
- 불변 객체를 집합(set)에 추가하거나 맵(map)의 키로 사용할 수 있다. 반대로 수정할 수 있을 경우, 해당요소를 더 이상 찾을 수 없게 되기 때문이다.
하지만 불변 객체를 사용하더라도 때로는 데이터가 변경해야 될 때가 있다. 이를 위해 변경된 새로운 객체를 반환할 수 있어야 한다.
data class User(val name: String, val surname: String)
fun main() {
var user = User("Maja", "Markiewicz")
user = user.copy(surname = "Moskala")
print(user)
}다음 코드처럼, data class의 copy 기능을 사용하면 손쉽게 변경된 객체를 반환받을 수 있다.
다른 종류의 변경 가능 지점
val list1: MutableList<Int> = mutableListOf()
var list2 : List<Int> = listOf()
list1 += 1
list2 += 1각각 1을 추가한다는 점에서 결과는 같지만, 내부적인 동작 방식은 차이가 있다.
@kotlin.internal.InlineOnly
public inline operator fun <T> MutableCollection<in T>.plusAssign(element: T) {
this.add(element)
}public operator fun <T> Collection<T>.plus(element: T): List<T> {
val result = ArrayList<T>(size + 1)
result.addAll(this)
result.add(element)
return result
}list1 += 1은 list1.plusAssign(1)로 컬렉션에 직접 값을 추가한다.
하지만, list2 += 1은 list2.plus(1)로 ArrayList를 생성 후 기존 갑과 새로운 값을 추가하여 반환한다.
list1 += 1은 변경이 리스트 구현체 add 내에서 발생하고, list2 += 1은 plus 메소드를 사용할 때 발생한다. 변경 가능 단일 속성에만 존재하기 때문에 전반적인 보안성이 더 우수하다. (해당 속성에 대한 동기화만 필요하기 때ㅜㅁㄴ이다.)
fun main() {
var names by Delegates.observable(listOf<String>()) {
_, old, new ->
println("Names changed from $old to $new")
}
names += "Fabio" // Names changed from [] to [Fabio]
names += "Bill" // Names changed from [Fabio] to [Fabio, Bill]
}다음 코드처럼 가변 리스트 대신 가변 속성을 사용하면 커스텀 setter나 delegate를 사용하여 속성이 어떻게 변경되는지 추적할 수 있다.
var list3 = mutableListOf<Int>()하지만 다음과 같이, 가변 속성과 가변 컬레션을 동시에 사용하면 안된다. 속성 변경과 내부 상태 변경 모두를 동기화해야 할 뿐만 아니라, plus를 사용할지 plusAssign 메소드를 상용할지 모호해진다.
따라서, 상태를 변경하는 불필요한 방법은 생성하지 않아야 한다. 상태를 변경하는 각각의 방법은 비용이 발생하기 때문이다.
변경 가능 지점 노출하지 않기
data class User(val name: String)
class UserRepository {
private val storedUsers: MutableMap<Int, User> = mutableMapOf()
fun loadAll(): MutableMap<Int, User> {
return storedUsers
}
}다음 코드는 읽기 전용 속성 storedUsers를 loadAll 메소드를 통해 노출시킨다.
val userRepository = UserRepository()
val storedUsers = userRepository.loadAll()
storedUsers[4] = User("Kirill")따라서 읽기 전용 속성임에도 불구하고 변경이 가능하다는 문제점이 있다.
class UserHolder {
private val user: MutableUser()
fun get(): MutableUser {
return user.copy()
}
}이를 해결하기 위한 방법으로, 방어적 복사(defensive copy)를 이용하거나
data class User(val name: String)
class UserRepository {
private val storedUsers: MutableMap<Int, User> = mutableMapOf()
fun loadAll(): Map<Int, User> {
return storedUsers
}
}읽기 전용 타입으로 업캐스팅하여 반환하는 방법이 있다.
정리
- var 대신 val을 선호해라.
- 가변 속성 대신 불변 속성을 선호해라.
- 가변 객체와 가변 클래스 대신 불변 객체와 불변 클래스를 선호해라.
- 변경이 필요한 경우, 불변 데이터 클래스로 만들고 copy 메소드를 사용하는 것을 고려해라.
- 상태를 유지할 때 가변 컬렉션 대신 읽기 전용 컬렉션을 선호해라.
- 변경 지점을 현명하게 설계하고 불필요한 변경 지점을 생성하지 말라.
- 가변 객체를 노출하지 말라.
Item 2: 변수의 범위를 최소화해라
상태를 정의할 때, 변수와 속성의 범위를 좁히는 것을 선호한다.
- 속성 대신 지역 변수를 사용한다.
- 변수를 가장 좁은 범위에서 사용한다. 예를 들어, 변수가 한 루프에서만 사용된다면 해당 루프 내에서만 정의한다.
// Bad
var user: User
for (i in users.indices) {
user = users[i]
print("User at $i is $user")
}
// Better
for (i in users.indices) {
val user = users[i]
print("User at $i is $user")
}
// Same variables scope, nicer syntax
for ((i, user) in users.withIndex()) {
print("User at $i is $user")
}첫 번째 예제에서 user 변수를 for 루프 범위 뿐만 아니라 외부에서도 접근 가능하고, 나머지 예제에서는 user 변수의 범위를 for 루프의 범위로 제한한다.
이런 방식을 선호하는 이유는 변수의 범위를 좁혀 프로그램을 추적하고 관리하기 쉽게 하기 위해서다. 또한, 범위가 넓은 변수가 다른 개발자에 의해 남용되는 것을 막기 위해서다.
// Bad
val user: User
if (hasValue) {
user = getValue()
} else {
user = User()
}
// Better
val user: User = if(hasValue) {
getValue()
} else {
User()
}가변 변수이든 불변 변수이든 정의할 떄 초기화해서 개발자가 정의된 곳을 찾아보도록 하지 말자.
// Bad
fun updateWeather(degrees: Int) {
val description: String
val color: Color
if (degrees < 5) {
description = "cold"
color = Color.BLUE
} else if (degrees < 23) {
description = "mild"
color = Color.YELLOW
} else {
description = "hot"
color = Color.RED
}
}
// Better
fun updateWeather(degrees: Int) {
val (description, color) = when {
degrees < 5 -> "cold" to Color.BLUE
degrees < 23 -> "mild" to Color.YELLOW
else -> "hot" to Color.RED
}
}캡쳐링
에라토스테네스의 체를 구현하는 과정은 다음과 같다.
- 2부터 시작하는 숫자 리스트를 만든다.
- 첫 번째 숫자를 가져온다. 이 숫자는 소수다.
- 나머지 숫자들 중에서 첫 번째 숫자를 제거하고, 이 소수로 나누어 떨어지는 모든 숫자를 필터링한다.
val primes: Sequence<Int> = sequence {
var numbers = generateSequence(2) { it + 1 }
while (true) {
val prime = numbers.first()
yield(prime)
numbers = numbers.drop(1).filter { it % prime != 0 }
}
}
print(primes.take(10).toList())다음 코드를 실행하면 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29]가 출력된다. 이 때, prime 변수를 매번 선언하는 것이 효율적이지 못하다고 생각해 while 문 밖으로 옮기는 발상을 할 수도 있다.
val primes: Sequence<Int> = sequence {
val numbers = generateSequence(2) { it + 1 }
var prime: Int
while (true) {
prime = numbers.first()
yield(prime)
numbers = numbers.drop(1).filter { it % prime != 0 }
}
}
print(primes.take(10).toList())하지만, 다음 코드를 실행하면 [2, 3, 5, 6, 7, 8, 9, 10, 11, 12]가 출력된다.
이러한 결과가 발생하는 이유는 변수 prime이 캡쳐되었기 때문이다. Sequences를 사용하므로 필터링은 게으르게(lazily) 이루어진다. 따라서, 해당 코드에서는 항상 마지막 prime의 값으로 필터링된다. 이로 인해 필터링이 제대로 동작하지 않는다.
정리
가능한 한 좁은 범위에 변수를 정의하는 것이 좋다. 또한 지역 변수는 var보다 val을 선호해야 한다. 변수가 람다에 캡쳐된다는 사실도 항상 인지해야 한다.
Item 3: 최대한 플랫폼 타입을 사용하지 말라
플랫폼 타입이란 다른 언어로부터 가져온 타입이며, null 여부를 알 수 없는 타입이다.
// Java
public class UserRepo {
public User getUser() {
// ...
}
}
// Kotlin
val repo = UserRepo()
val user1: User = repo.user!
val user2: User = repo.user
val user3: User? = repo.user?Kotlin 변수나 속성에 플랫폼 값이 할당될 때, 유추될 수는 있지만 명시적으로 설정할 수 없다. 대신 위와 같이 예상되는 타입을 선택할 수 있다.
하지만, 현재 null이 아니라고 가정한 것이 미래에는 null을 반환할 수도 있기 때문에 주의를 기울여야 한다. 이를 방지하기 위해 @Nullable, @NotNull같은 어노테이션을 표시하는 것이 좋다.
// Java
public class JavaClass {
public String getValue() {
return null;
}
}
// Kotlin
fun statedType() {
val value: String = JavaClass().value
// ...
println(value.length)
}
fun platformType() {
val value = JavaClass().value
// ...
println(value.length)
}다음 코드에서 getValue가 null을 반환하지 않을 것이라고 예상했기 때문에 두 경우 모두 NPE(Null Pointer Exception)이 발생한다. 하지만 에러가 발생하는 곳은 다르다.
statedType 메소드에서는 String 타입이 아닌 null 값이 들어와 값을 가져오는 위치에서 NPE가 발생한다. platformType 메소드에서는 플랫폼 타입으로 지정하였기 때문에 nullable 일 수도 아닐 수도 있다. 따라서, println(value.length)를 호출하는 과정에서 NPE가 발생한다. 값을 찾는 곳에서 에러가 발생하기 때문에 오류를 찾기가 어려울 수 있다.
interface UserRepo {
fun getUserName() = JavaClass().value
}
class RepoImpl : UserRepo {
override fun getuserName(): String? {
return null
}
}
fun main() {
val repo: UserRepo = RepoImpl()
val text: String = repo.getUserName() // NPE 발생플랫폼 타입을 더 넓은 범위로 전파한다면 누구나 타입이 nullable인지 아닌지를 결정할 수 있기 때문에 문제가 심각해질 수 있다.
정리
플랫폼 타입이란 다른 언어에서 가져온 null 여부를 알 수 없는 타입이다. 이러한 플랫폼 타입은 위험하기 떄문에 가능한 한 빨리 제거하고 전파되지 않도록 해야 한다. 또한 노출된 Java 생성자, 메소드 및 필드에 null 여부를 지정하는 주석 (@NotNull, @Nullable)을 사용하여 타입을 명시하는 것이 좋다.
Item 4: 추론된 타입을 노출시키지 마라
타입 추론은 기본적으로 상위 클래스나 인터페이스의 타입으로 추론되지 않는다. 다음 코드를 살펴보자.
open class Animal
class Zebra: Animal()
fun main() {
var animal = Zebra()
animal = Animal() // 타입 불일치
}animal은 Zebra의 상위 클래스인 Animal로 타입 추론이 되지 않고, Zebra로 추론되기 때문에 에러가 발생한다.
open class Animal
class Zebra: Animal()
fun main() {
var animal: Animal = Zebra()
animal = Animal()
}이 문제는 타입을 명시적으로 선언하면 해결할 수 있다.
외부 라이브러리나 모듈을 사용할 때도 추론된 타입을 사용하는 것은 지양해야 한다.
interface CarFactory {
fun produce(): Car = DEFAULT_CAR
}
DEFAULT_CAR: Car = Fiat126P()CarFactory 인터페이스가 존재하고 produce 메소드에서는 Car를 반환하도록 명시적으로 지정되어있다.
interface CarFactory {
fun produce() = DEFAULT_CAR
}여기서 DEFAULT_CAR가 Car를 명시적으로 반환하기 때문에 produce 메소드에서 추론된 타입을 사용한 코드이다. 여기까지는 크게 문제가 되지 않는다.
val DEFAULT_CAR = Fiat126P()하지만, 누군가가 이 코드를 유지보수할 때, DEFAULT_CAR가 추론된 타입을 사용하도록 하면 문제가 된다. 기존에 Car를 반환하는 의도와는 다르게 Fiat126P만을 반환하게 된다.
따라서, 리턴 타입을 명시적으로 지정해주는 것이 중요하다.
정리
타입에 대해 확신이 없다면, 반드시 명시해야 한다. 또한, 보안을 위해 외부 API에서는 항상 타입을 명시해야 하며 임의로 변경되어서는 안 된다.
Item 5: 기대하는 인수 및 상태에 대해 명시하라
기대하는 바가 있다면 다음 수단을 통해 명시하자
require- 인수에 대해 기대하는 바를 명시, 참이 아니면IllegalArgumentException발생check- 상태에 대해 기대하는 바를 명시, 참이 아니면IllegalStateException발생assert- 참으로 생각하는 바에 대한 체크return이나throw를 활용한 Elvis 연산자
fun pop(num: Int = 1): List<T> {
require(num <= size) {
"Cannot remove more elements than current size"
}
check(isOpen) { "Cannot pop from closed stack" }
val collection = innerCollection ?: return emptyList()
val ret = collection.take(num)
innerCollection = collection.drop(num)
assert(ret.size == num)
return ret
}이와 같이 기대 사항을 명시하면 다음과 같은 이점이 있다.
- 기대 사항을 만족시키지 않으면 예외를 throw하므로 예상치 못한 동작이 발생하는 대신 예외가 발생한다.
- 코드가 어느 정도 자체 검사를 수행하기 때문에, 단위 테스트의 필요성이 적어진다.
- 스마트 캐스팅과 함께 작동하므로, 캐스팅이 더 적게 필요하다.
스마트 캐스팅: 변수나 식을 자동으로 적절한 유형으로 캐스팅
인수 (Arguments)
fun factorial(n: Int): Long {
require(n >= 0)
return if (n <= 1) 1 else factorial(n - 1) * n
}
fun sendEmail(user: User, title: String, message: String) {
requireNotNull(user.email)
require(isValidEmail(user.email)
}인수에 대한 요구사항 명시는 require를 사용한다. 요구사항을 충족하지 못할 시 IllegalArgumentException을 throw한다.
requireNotNull 같이 변형된 형태도 존재한다.
fun factorial(n: Int): Long {
require(n >= 0) { "Cannot calculate factorial of $n because it is smaller than 0" }
return if (n <= 1) 1 else factorial(n - 1) * n다음 코드와 같이 lambda 식을 통해 에러 메시지도 전달할 수 있다.
상태 (State)
fun speak(text: String) {
check(isInitialized)
// ...
}
fun getUserInfo(): UserInfo {
checkNotNull(token)
// ...
}상태에 대한 요구사항 명시는 check를 사용한다. 요구사항을 충족하지 못할 시 IllegalStateException을 throw한다.
checkNotNull 같이 변형된 형태도 존재한다.
fun getUserInfo(): UserInfo {
checkNotNull(token) { "Cannot find user info" }
}마찬가지로 lambda 식을 통해 에러 메시지를 전달할 수 있다.
Assertions
올바르게 구현했다면, 참이어야만 하는 것들이 있다. 예를 들어, 10개의 요소를 반환하는 함수를 구현했다면 10개의 요소를 반환해야 한다. 이를 확인하기 위해 assert를 사용한다.
class StackTest {
@Test
fun `Stack pops correct number of elements`() {
val stack = Stack(20) { it }
val ret = stack.pop(10)
assertEquals(10, ret.size)
}
}오류가 나더라도 어떤 에러도 throw하지 않기 때문에 오류가 발생하더라도 유저에게 알리고 싶지 않을 때 사용한다.
또한, 단위 테스트가 아닌 pop 함수 내에서도 assert를 사용할 수 있다.
fun pop(num: Int = 1): List<T> {
// ...
assert(ret.size == num)
return ret
}단위 테스트 대신 함수 내에 assert를 포함하는 것은 다음 장점을 가진다.
- 코드 자체에서 자가 확인(self-checking)을 수행하고, 보다 효과적인 테스트를 이끌어낼 수 있다.
- 모든 실제 사용 사례에 대해 체크할 수 있다.
- 실행 시점에서 원하는 것을 확인하기 위해
assert를 사용할 수 있다. - 코드 실행을 조기에 실패해, 실제 문제에 더 가까워질 수 있다. 이를 통해 예기치 않은 동작이 시작된 위치와 시간이 더 쉽게 파악할 수 있다.
Nullabiltiy and smart casting
require 나 check 블록으로 조건 확인 시 이후부터는 해당 조건이 만족됐다고 가정하고 실행된다.
class Person(val email: String?)
fun validateEmail(email: String) { /*...*/ }
fun sendEmail(person: Person, title: String, text: String) {
val email = requireNotNull(person.email)
validateEmail(email) // String으로 스마트 캐스팅
}따라서, 조건 확인 후에는 스마트 캐스팅이 실행된다. 다음 코드를 보면 requireNotNull로 person.email이 null인지 아닌지 확인 후 validateEmail에 스마트 캐스팅된 email 변수를 String 처럼 사용할 수 있다.
fun sendEmail(person: Person, title: String, text: String) {
val email: String = person.email ?: return
// ...
}Nullability를 체크하기 위해 throw나 return를 활용한 Elvis 연산자를 사용할 수 있다.
fun sendEmail(person: Person, title: String, text: String) {
val email: String = person.email ?: run {
log("Email not sent because of lack of email address")
return
}
// ...
}Nullability 체크 후, 특정 동작을 수행하고 return 이나 throw 를 하고 싶은 경우 run을 사용할 수 있다.
정리
- 요구사항을 좀 더 잘 보이게 하자
- 앱의 안정성을 올리자
- 코드의 정확성을 올리자
- Smart casting을 이용하자
Item 6: 사용자 정의 오류보다 표준 오류를 사용하라
가능하면 사용자 정의 오류보다 표준 오류를 사용해야 한다. 표준 오류는 이미 많은 개발자들이 알고 있으므로 코드를 더 쉽게 이해하는 데 도움이 된다.
다음은 몇 가지 표준 오류들이다.
- IllegalArgumentException
- IllegalStateException
- IndexOutOfBoundsException
- ConcurrentModificationException
- UnsupportedOperationException
- NoSuchElementException
Item 7: 결과 부족이 발생할 경우 null 과 Failure 를 사용하라
때때로, 원하는 결과를 받지 못하는 상황이 있을 수 있다.
- 서버에서 데이터를 받아올 때 인터넷 연결에 문제가 있는 경우
- 조건에 맞는 첫번째 요소를 찾을 때 조건에 맞는 요소가 없는 경우
- 텍스트를 파싱해서 객체를 생성할 때 텍스트의 형식이 맞지 않는 경우
이러한 상황은 두 가지 방법을 통해 해결할 수 있다.
- null 또는 실패를 나타내는 sealed class를 반환한다.
- 예외를 throw한다.
하지만 예외는 정보를 전달하는 방버으로 사용하면 안되고, 잘못된 특별한 상황을 처리해야 한다. 그 이유는 다음과 같다.
- 대부분의 개발자에게 예외 전파 방식은 가독성이 떨어지고 코드에서 쉽게 놓칠 수 있다.
- Kotlin에서는 모든 에외가 unchecked이다. 사용자가 처리를 강제하거나 심지어 처리를 권장받지 않는다.
- 예외는 예외적인 상황을 위해 설계되었기 때문에 빠르게 동작되지 않는다.
- try-catch 블록 내에 코드를 배치하면 컴파일러가 수행할 수 있는 특정 최적화를 제한한다.
inline fun <reified T> String.readObjectOrNull(): T? {
// ...
if (isCorrectSign) {
return null
}
// ...
return result
}
inline fun <reified T> String.readObject(): Result<T> {
// ...
if (isCorrectSign) {
reutrn Failure(JsonParsingException())
}
// ....
return Success(result)
}
sealed class Result<out T>
class Success<out T>(val result: T): Result<T>()
class Failure(val throwable: Throwable): Result<Nothing>()
class JsonParsingException: Exception()이러한 에러 처리 방식은 try-catch 블록보다 효율적이며, 사용하기 쉽고 더 명확하다.
val age = userText.readObjectOrNull<Person>?.age ?: -1null을 반환한다면, Elvis 연산자를 통해 표현할 수 있고
sealed class Result<out T>
class Success<out T>(val result: T): Result<T>()
class Failure(val throwable: Throwable): Result<Nothing>()
val age = when(val person = userText.readObjectOrNull<Person>()) {
is Success -> person.age
is Failure -> -1
}result 클래스를 사용할 경우 when 표현식을 이용해 다음 코드와 같이 사용할 수 있다.
nullable한 결과와 sealed result class를 비교할 때, 실패할 경우 추가 정보를 전달하고 싶다면, 후자를 선호해야 한다. 그렇지 않은 경우 null을 사용한다.
실제로 이러한 에러 처리 방식은 List의 getOrNull 함수에서 찾아볼 수 있다.
get: 주어진 위치에 요소가 있지 않다면 IndexOutOfBoundsException을 throw한다.getOrNull: 주어진 위치에 요소가 있지 않다면 null을 반환한다. ?: 을 사용해 안전하게 처리할 수 있다.
Item 8: null을 적절히 처리하라
함수에서 null을 반환한다면 함수에 따라 null의 의미가 다를 수 있다.
String.toIntOrNull(): String이 Int로 파싱이 불가능할 때 null 반환Iterable<T>.firstOrNull(() -> Boolean): 해당하는 요소가 없을 때 null 반환
따라서, null은 해석의 의지가 다분하기 때문에, 가능한 한 의미가 명확해야 한다.
nullable 타입은 3가지 방법으로 다룰 수 있다.
- ?., 스마트 캐스팅, Elvis 연산자 등 safe call 상용하기
- 에러를 throw하기
- nullable 하지 않게 함수 개선하기
null을 안전하게 처리하기
printer?.print() // Safe call
if (printer != null) printer.print() // Smart castingSafe call이나 스마트 캐스팅을 통해 null을 안전하게 처리할 수 있다.
에러 throw하기
null이 아니어야만 하는 상황에서, null일 경우 에러를 throw함으로써 개발자가 에러를 쉽게 찾아낼 수 있다.
fun process(user: User) {
requireNotNull(user.name)
val context = checkNotNull(context)
val networkService =
getNetworkService(context) ?: throw NoInternetConnection()
networkService.getData { data, userData ->
show(data!!, userData!!)
}
}throw를 사용하거나 !!, requireNotNull, checkNotNull 또는 다른 오류를 throw하는 함수를 사용하여 이를 수행할 수 있다.
not-null assertion !!을 사용할 때의 문제점
not-null assertion 연산자 !!는 주로 타입이 nullable하지만 null이 예상되지 않는 상황에서 사용되며 null일 시 NPE(NullPointerException)을 발생시킨다.
사용하기 쉽다는 장점이 있지만 에러를 throw하는 방식에 비해 정보를 적게 제공한다는 단점이 있다. 또한 !!을 선언한 변수도 추후에는 null이 될 수 있는 가능성이 존재한다. 이 때, nullabilty를 숨기게 된다는 단점도 있다.
따라서, 최대한 !!의 사용은 피해야 한다.
무의미한 nullability를 피하자
Nullabilty를 위해서는 비용이 발생한다. 따라서, 의미없는 nullabilty를 피해야 한다.
- sealed result class를 null 대신 반환한다.
- 클래스 생성 이후에 값을 설정하는 경우,
lateinit이나notNull delegate를 사용한다. - 빈 컬렉션 대신 null을 반환하지 않는다. 컬렉션 안에 요소가 없다면 빈 컬렉션을 반환해야 한다.
- Nullable enum과 None enum은 다르다. null은 따로 처리해야 하는 특별한 케이스이다.
lateinit과 notNull delegate
class UserControllerTest {
private lateinit var dao: UserDao
private lateinit var controller: UserController
@BeforeEach
fun init() {
dao = mockk()
controller = UserController(dao)
}
@Test
fun test() {
controller.doSomething()
}클래스 생성 중 초기화할 수 없지만 첫 사용 전에 반드시 초기화되는 변수의 경우 lateinit를 사용할 수 있다.
class DoctorActivity : Activity() {
private var doctorId: Int by Delegates.notNull()
private var fromNotification: Boolean by Delegates.notNull()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
doctorId = intent.extras.getInt(DOCTOR_ID_ARG)
fromNotification = intent.extras.getBoolean(FROM_NOTIFICATION_ARG)
}
}lateinit을 사용할 수 없는 경우는 JVM에서 원시 타입(Int, Long, Double, Boolean 등으으로 초기화하는 경우이다. 이러한 경우 Delegates.notNull을 사용해야 한다.
class DoctorActivity: Activity() {
private var doctorId: Int by arg(DOCTOR_ID_ARG)
private var fromNotification: Boolean by arg(FROM_NOTIFICATION_ARG)
}다음 코드처럼 property delegate pattern을 사용할 수도 있다.
Item 9: use를 사용해 리소스를 닫아라
Kotlin에서 일부 리소스는 자동으로 닫히지 않으며, 더 이상 필요하지 않을 때, close 메소드를 호출해야 한다.
- InputStream과 OutputStream
- java.sql.Connection
- java.io.Reader(FileReader, BufferedReader, CSSParser)
- java.new.Socket과 java.util.Scanner
이러한 리소스는 AutoCloseable을 상속받는 CLoseable 인터페이스를 구현하고 있다. 전통적으로, 해당 리소스를 닫기 위해 try-finally 블록으로 감싸고 close를 호출했다.
fun countCharactersInFile(path: String): Int {
val reader = BufferedReader(FileReader(path))
try {
return reader.lineSequence().sumBy { it.length }
}
} finally {
reader.close()
}
}하지만 이러한 구조는 문제점이있다. close 메소드는 예외를 throw할 수 있는데, 해당 예외는 catch되지 않을 것이다. 또한, try 블로과 finally 블록 모두 에러가 발생하면 한 가지만 올바르게 전파가 된다.
fun countCharactersInFile(path: String): Int {
BufferedReader(FileReader(path)).use { reader ->
reutrn reader.lineSequence().sumBy { it.length }
}
}이를 use 메소드를 사용함으로써 처리할 수 있다.
fun countCharactersInFile(path: String): Int {
File(path).useLines { lines ->
reutrn lines.sumBy { it.length }
}
}추가로 파일을 한 줄 씩 처리하는 useLines 메소드도 존재한다. 메모리에 파일 전체가 아닌, 파일의 내용을 한 줄씩만 유지하므로 대용량 파일도 적절하게 처리할 수 있다. 하지만, 파일의 특정 줄을 두 번 이상 반복처리하려면 파일을 여러 번 열어야 된다는 단점이 있다.
Item 10: 단위 테스트를 작성하라
시스템의 구체적인 요소가 올바르게 작동하는지 확인하고 개발 중에 빠른 피드백을 받기 위해 단위 테스트를 작성할 필요가 있다.
@Test
fun `fib works correctly for the first 5 positions`() {
assertEquals(1, fib(0))
assertEquals(1, fib(1))
assertEquals(2, fib(2))
assertEquals(3, fib(3))
assertEquals(5, fib(4))
}다음 코드는 피보나치 수를 계산하는 fib 메소드가 올바른 값을 반환하는지 확인하는 코드이다.
이러한 단위 테스트에서 확인하는 내용은 다음과 같다.
- 일반적인 사용 사례 (happy path) - 일반적으로 요소들이 작동하는 방식을 말한다. 위의 예시처럼 몇몇 작은 숫자에 대해 작동하는지 테스트 한다.
- 일반적인 오류 사례 또는 잠재적인 문제 - 예상대로 작동하지 않을 수 있는 경우 또는 이전에 문제가 있었던 경우를 확인한다.
- 경계 값(edge case)과 부적합한 인수(argument) - Int의 경우 Int.MAX_VALUE 같이 경계값을 확인할 수 있다. fib 함수를 검사한다고 가정하면 음수에 대한 피보나치 수는 없으므로 음수를 넣었을 때, 어떻게 작동하는지 테스트해 볼 수 있다.
단위 테스트를 통해 다음과 같은 이점을 얻을 수 있다.
- 테스트가 잘 수행되면 요소를 더 신뢰할 수 있으며, 더 자신감있게 작업할 수 있다.
- 테스트가 잘 수행되면 리팩토링을 하는 것에 대한 부담을 줄일 수 있다.
- 수동으로 확인하는 것보다 훨씬 빠르게 정확성을 체크할 수 있다.
물론, 단위 테스트의 단점도 존재한다.
- 단위 테스트를 작성하는 데 시간이 소요된다. 하지만, 추후 디버깅 및 버그를 찾는 시간을 덜 소비하게 만든다.
- 테스트 가능하도록 코드를 잘 조정해야 한다. 하지만, 결과적으로 잘 짜여진 아키텍처를 사용하도록 강제한다.
- 좋은 단위 테스트 코드를 짜는 것이 어렵다.
테스트 코드를 작성해야 하는 중요 파트들은 다음과 같다.
- 복잡한 기능
- 시간이 지남에 따라 변경되거나 리팩토링될 가능성이 높은 부분
- 비즈니스 로직
- 공개 API의 일부
- 자주 문제가 발생하는 부분
- 수정한 프로덕션 버그
정리
프로그램이 올바르게 작동하는지 확인하기 위해 단위 테스트를 수행하는 것이 중요하다.
