최근 openAI에서 발표한 DALL.E2의 놀라운 성능에 감명 받아, 논문을 읽어보다 diffusion model에 대해 먼저 공부하기 위해, Denoising diffusion probabilistic model(DDPM)에 대해 공부해 보았다.
생성 모형은 기본적으로 어떤 도메인(이미지, 자연어, 음성 등)의 복잡한 확률 분포를 모형화하는 것을 목적으로 한다. 이 포스팅에서는 이미지에 대한 생성 모형에 대해 다루고자 한다.
우선, 이미지 생성을 위한 몇 가지 접근 방향에 대해 간단히 소개하고 그 중 최근 각광받고 있는 diffusion model에 대해 소개하고자 한다.
생성 모형의 종류
1. Generative Advarsarial Network(GAN)
2014년 이안 굿펠로가 제안한 프레임워크로, 생성자와 판별자의 minmax(advarsarial) training을 통해, realistic한 이미지를 생성하는 생성자를 학습한다.

- 장점
- High fidelity : 실제 사진와 유사한 일관성 있는 이미지를 생성할 수 있다.
- 모델 구조의 선택이 자유롭다. - 단점
- Less diversity : model의 coverage가 좁아서, 사실적인 이미지를 생성하긴 하지만 다양한 이미지를 생성하지는 못한다.
- 훈련 과정의 불안정성
2. Likelihood Based Model
Flow Model
flow model은 딥러닝 모델에 대한 역변환을 통해, 단순한 분포(ex.Normal distribution)에서 시작하여 복잡한 분포를 모델링하는 방법이다. 확률론에서 자주 언급되는 change of variable theorom에 기반한 방법이며, log likelihood objective로 학습이 이루어진다.
Autoregressive Model(DALL.E)
DALL.E(2021)처럼, 이미지 패치를 vector quantization을 통해 토큰화(visual token)시킨 후, visual token간의 관계를 transformer decoder로 모델링한다. 이것은 NLP분야에서 언어 생성에 사용되는 GPT의 응용된 버전이고, 이미지 생성 도메인 뿐 아니라, 언어 생성. 음성 생성에도 사용된다. transformer decoder구조를 사용하기 때문에, 모델 스케일링에 대한 장점이 있다.
3. Diffusion Model

diffusion model은 원본 이미지에 gaussian noise를 순차적으로 추가하며 완전한 random noise로 만들어주는 과정(diffusion process)으로부터, 이것의 역변환(inverse process)을 학습하고, 이 학습된 역변환을 사용하여 random noise로부터 이미지를 생성하는 메커니즘을 따른다.
- 장점
- GAN과는 달리 stationary training objective를 사용
- Model scalability(CNN architecture)
- Distribution coverage가 높음 -> 다양한 이미지 생성 가능
- 단점
- 순차적인 inverse process를 통해 이미지가 생성되므로, 생성 속도가 비교적 느림
- GAN에 비해 fidelity가 낮음
DDPM
ddpm의 목적은, 이미지에 노이즈를 순차적으로(step)추가하는 diffusion process의 역변환을 학습하는 것이다. 이 과정에서 지극히 많은 수학이 사용된다.
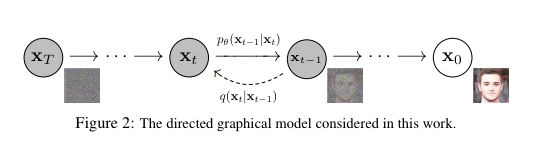
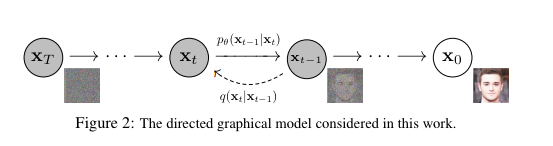
Diffusion process
위 figure에서 은 diffusion process이다. 즉, 원본 이미지 에 대해 순차적으로 gaussian Markov chain을 적용하는 것이고, 그 횟수가 충분히 많아지면, 는 완전한 random gaussian을 따르게 된다.
여기서 은 아래와 같이 표현된다.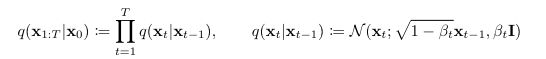
Inverse process
Inverse process는 완전한 gaussian을 따르는 로부터 시작하여, 이것을 다시 으로 되돌리는 과정이다.
이 과정(inverse process)을 학습하는 것이 ddpm의 목적이고, 따라서 inverse process는 gaussian Markov chain의 모수()로 parameterize 된다.
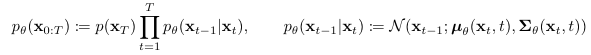
Training Objective(variational bound)
여기서 우리가 생각할 수 있는 직관은 와 사이의 거리(ex.KL-Divergence)를 좁히는 것이다.
해당 논문에서는, negative log likelihood of 의 variational bound(upper bound)를 최소화하는 방식으로 최적화를 진행하는데, 수식전개는 아래와 같다.
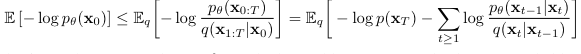
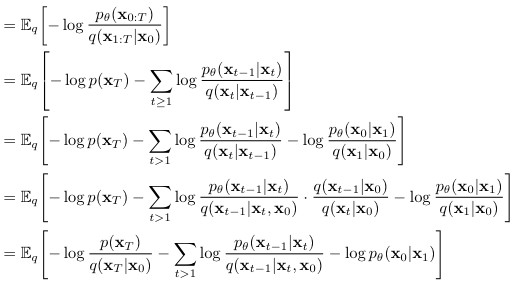
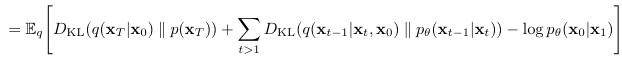
위 수식 전개에서 세 번째 식에서 네 번째 식으로 넘어가는 부분이 핵심이라고 생각한다.
결과적으로, 마지막 수식의 앞의 두 항은 gaussian distribution간의 KL-divergence이므로, 마지막 수식 전체가 tractable해진다.
참고로, 은 아래와 같다.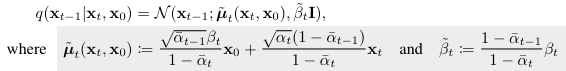
여기서 ELBo로 구해진 위 training objective를 다시 살펴 볼 필요가 있다.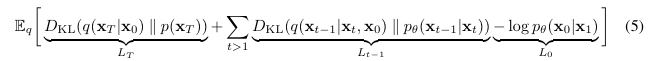
1. Forward Process
이 부분은 학습 가능한 파라미터가 없다. 따라서, 학습 과정에서 이 부분은 상수이므로, 무시할 수 있다.
2. Reverse Process
이 부분을 최적화함으로써, 최적의 (t = 1~T-1)를 얻을 수 있다.
이 때, 로부터 을 sampling하는 것은, 아래를 계산하는 것과 같다. 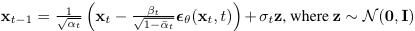 여기서 는 를 바탕으로 ~를 예측하도록 parameterize된 함수이다.
여기서 는 를 바탕으로 ~를 예측하도록 parameterize된 함수이다.
Training과 Sampling(Generation) 알고리즘은 아래와 같다.
학습이 끝난 이후에는, 오른쪽과 같은 방식의 순차적인 sampling을 통해 완전한 gaussian을 따르는 에서 시작하여, realistic한 이미지인 을 생성할 수 있다.
Results

