Graph neural network를 활용한 task는 크게 node classification, link prediction, graph classification으로 나뉩니다.
각각의 task가 무엇인지 이해를 돕기 위해 예를 들자면,
Node classification은 소셜 네트워크에서 특정 개체가 봇인지 인간인지 분류하는 task에서 활용될 수 있고,
graph classification은 특정 분자(graph structured molecule)의 화학적 속성에 대한 예측에 사용될 수 있습니다.
또한, Link prediction은 온라인 플랫폼에서의 추천 시스템에 사용될 수 있습니다.(특정 제품과 특정 사용자 간에 관계가 존재하는가 or 존재하지 않는가?)
본 포스팅에서는, 각각의 task에 어떤 손실함수(loss function)들이 사용되는지 정리해 보겠습니다.
1. Node Classification
Node classification을 위한 손실함수는 매우 간단합니다. GNN을 통해 산출된 노드 의 임베딩을 라고 할 때, 임베딩에 대해 classification weight 를 적용한 뒤, cross entropy loss를 산출하면 됩니다.
수식으로는 아래와 같이 표현할 수 있습니다. 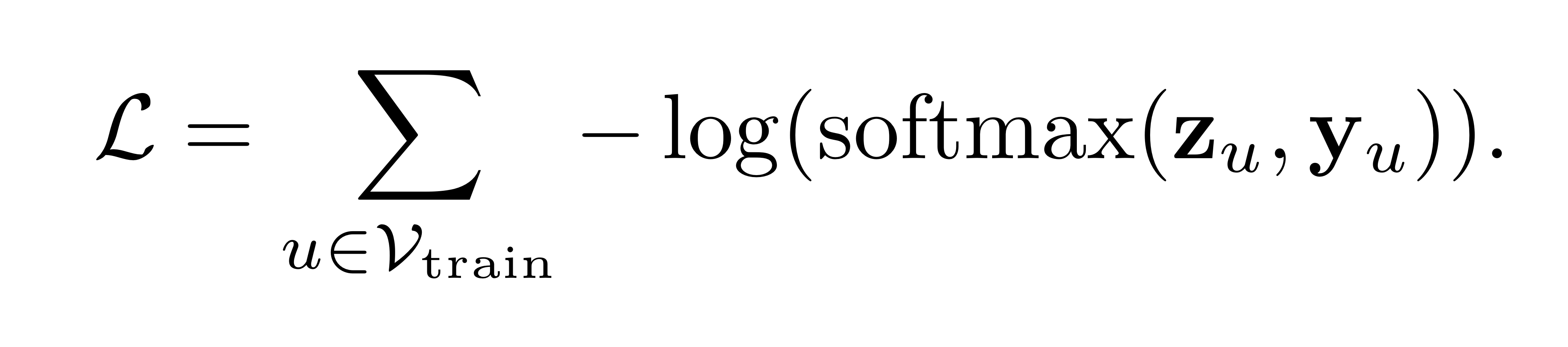
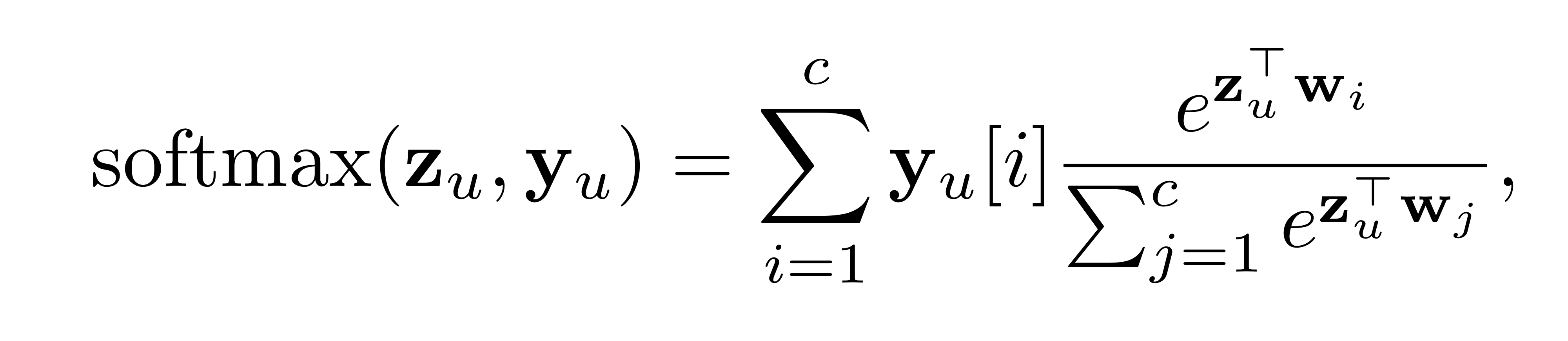 where is trainable parameter(for classification)
where is trainable parameter(for classification)
node classificaion task는 semi-supervised learning으로 불리기도 하고 supervised learning으로 불리기도 합니다. 이 명칭을 명확히 하기 위해서는, transductive test node와 inductive test node에 대한 이해가 필요합니다.
-
Train node
은 node classification을 위한 label이 할당되어 있는 노드로, cross entropy loss 산출에 직접적으로 활용되는 노드입니다. -
Transductive test node
는 node classification을 위한 label이 할당되어 있지 않기 때문에 cross entropy loss산출에는 영향을 주지 못하지만, training 시점에 그래프 내에 존재하는 노드들이기 때문에 에 속하는 노드들의 임베딩 산출을 위한 message passing operation에 영향을 줍니다. -
Inductive test node
는 training 시점에 그래프 내에 아예 존재하지 않은 노드입니다. 예를 들면, 2019년~2020년 까지의 Citation dataset으로 학습을 한 후, 2021년의 Citation dataset으로 test를 할 경우, 후자에 속한 노드 중 2019~2020년 동안에는 존재하지 않던 노드들이 가 되는 것입니다.
test node가 transductive한 경우에만 node classification을 semi-supervised learning이라고 할 수 있고, test node가 inductive한 경우, node classification은 supervised learning 입니다.
2. Graph Classification
Graph classification을 위한 손실함수도 node classification의 경우와 크게 다르지 않습니다(Cross Entropy loss 사용). 한 가지 다른 점이 있다면, 노드 임베딩 가 아닌 그래프 임베딩 가 사용된다는 것입니다.
물론, 그래프 임베딩 를 산출하기 위한 그래프 풀링(graph pooling)방법은 매우 다양하고, 이 분야에 대한 연구가 활발히 진행되고 있습니다.
Graph classification뿐 아니라, 그래프 단위의 regression task(ex. molecular solubility prediction)도 가능합니다. Graph Regression을 위한 수식은 아래와 같이 정의될 수 있습니다.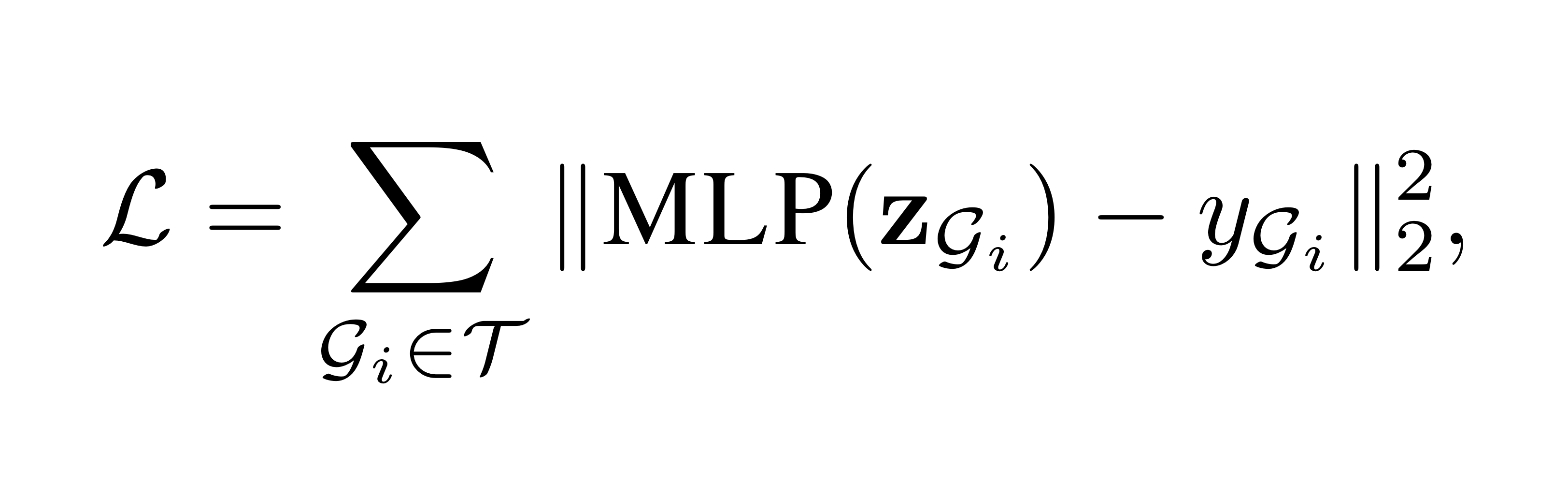
3. Relation(Link) Prediction
Link prediction의 대표적인 응용으로는 추천 시스템(recommender system), knowledge graph completion 등이 있습니다.
두 노드 간에 연결(link)이 있는지 없는지 혹은, 두 노드 간에 존재하는 연결(relation)의 종류가 무엇인지를 판단하는 task 입니다.
이런 경우엔, pairwise node embedding loss function을 사용하여 GNN을 학습할 수 있습니다.
GNN을 통해 산출된 노드 와 노드 의 노드 임베딩을 각각 라고 했을 때, 아래와 같은 pairwise loss를 통해 link prediction task를 학습할 수 있습니다. 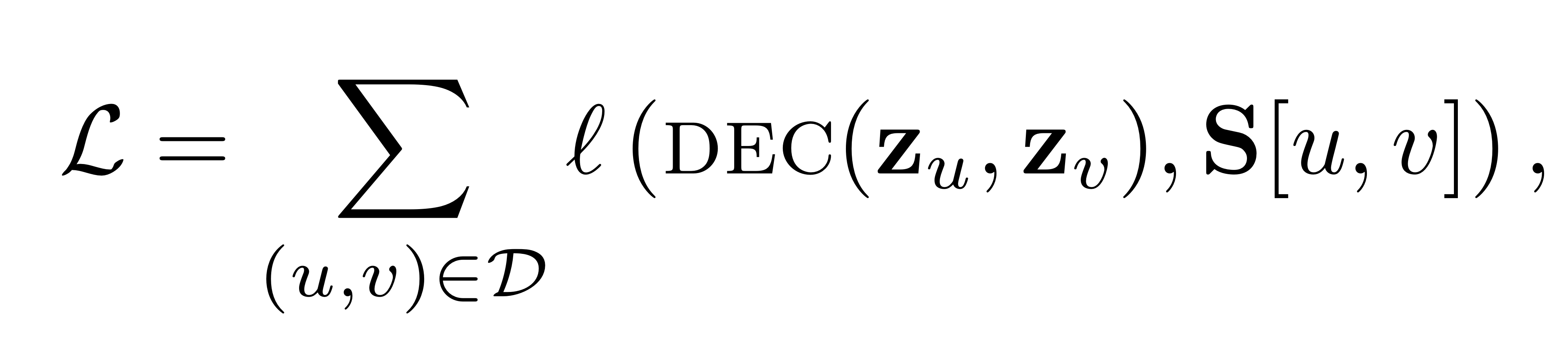 : similarity measure between
: similarity measure between
: ground truth pairwise neighborhood ovelap statistics (인접행렬 도 가능)
4. Pre-training GNN
node classification, link prediction, graph classification과 같은 task를 학습하기 앞서, node2vec과 같은 방식의 node reconstruction loss(unsupervised learning)를 통해 GNN을 사전학습 하는 방법을 생각해볼 수 있습니다.
하지만 단순한 reconstruction loss를 기반으로 GNN을 사전학습 하는 것은, 특정 task에서의 성능 향상에 크게 도움이 되지 않는다고 합니다(Velickovic et al. 2019). reconstruction loss를 통한 사전학습 없이도, GNN의 message passing operation을 통해 이웃 노드끼리는 비슷한 노드 임베딩을 갖게 되기 때문입니다.
하지만, Deep Graph Infomax(DGI) 사전학습 전략을 통해 성능 향상이 가능합니다.
