Generation-based MRC는 주어진 지문과 질의(question)를 보고 답변을 생성하는 Generative task이다. 이전의 Extraction-based MRC는 각 토큰이 answer span의 시작과 끝이 될 수 있는지를 분류하는 문제였다면 Generation-based MRC는 Language Modeling 처럼 text를 생성하는 것이 목적인 셈이다. 그렇기 때문에 BERT처럼 Encoder 단일로만 이루어진 모델은 사용할 수 없고 Autoregressive한 모델을 사용해야만 한다. 따라서 맨 처음 Transformer처럼 Seq2Seq(Encoder-Decoder) 기반의 모델을 사용하는 것이 일반적이다.
Tokenization은 Extraction-based MRC와 크게 다르진 않다. Vocabulary 사전을 통해 주어진 시퀀스의 각 토큰을 사전 인덱스로 변환한 input_ids는 동일하게 사용한다. 대신 BERT에서 봤던 것처럼 [CLS]나 [SEP]의 Special token으로 Question과 context를 구분해주기 보단 자연어를 이용한 정해진 text format으로 이를 구분짓는 경우가 더 많다.
Extraction-based MRC : [CLS] question_text [SEP] context_text
Generation-based MRC : question : question_text context : context_text
Attention 연산시 Padding을 무시하기 위해 사용했던 attention mask도 사용한다. 그러나 BERT에서 두 시퀀스를 구분하기 위해 추가적으로 사용했던 token_type_ids는 사용하지 않는다. 입력시퀀스를 하나의 큰 시퀀스로 취급하기 때문이다.
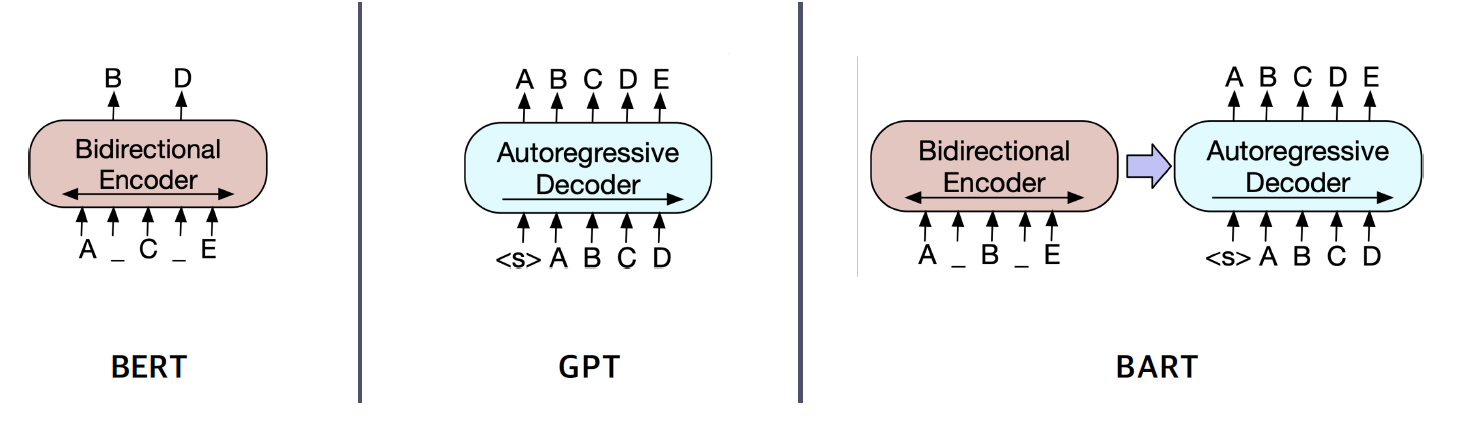
BART는 이러한 Needs에 맞춰 Seq2Seq 형태로 만들어진 모델이다. 쉽게 생각하면 BERT를 encoder로, GPT1을 Decoder로 연결하여 자연어 생성 task를 해결하겠다는 것이 목적인 셈이다. 이때 Encoder의 Bi-directional한 성질과 Decoder의 autoregressive한 성질을 그대로 유지하는 것이 특징이다.
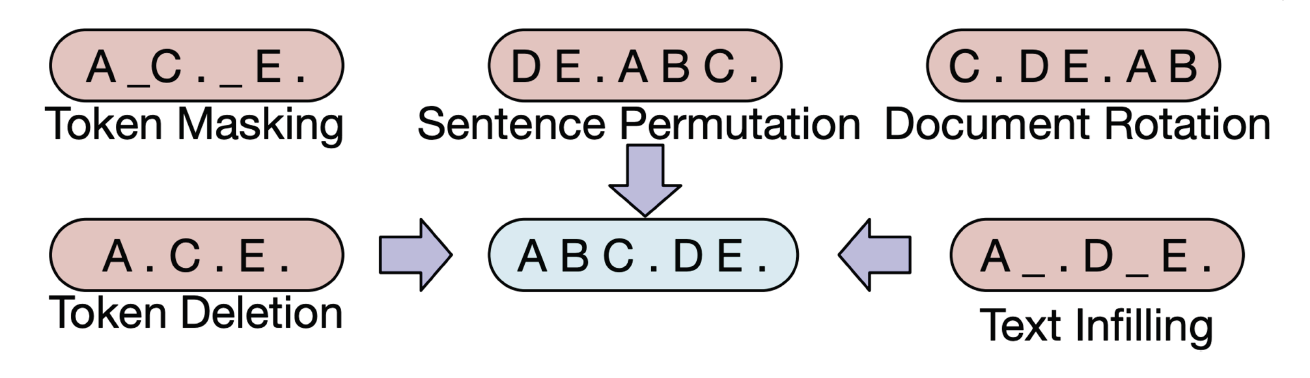
이 BART의 Pretraining은 Encoding 과정에서 텍스트에 Mask 뿐만 아니라 Sentence Permutation 등 다양한 방식으로 텍스트에 노이즈를 주고 이를 Decoder에서 Reconstruct하는 방식으로 진행된다. 그래서 이를 Denoising Autoencoder라고 불리기도 한다.
