
예전에 잠깐 세션 들었는데 node 공부를 하면서 다시 복습한다. 물리치자 디비
관계형 데이터베이스
관계형 데이터 모델에 기초를 둔 데이터베이스 시스템을 말한다. ex) MySQL, Postgres, Oracle DB
관계형 데이터란?
데이터를 서로 상호관련성을 가진 형태로 표현한 데이터
아이패드 사야지..
-
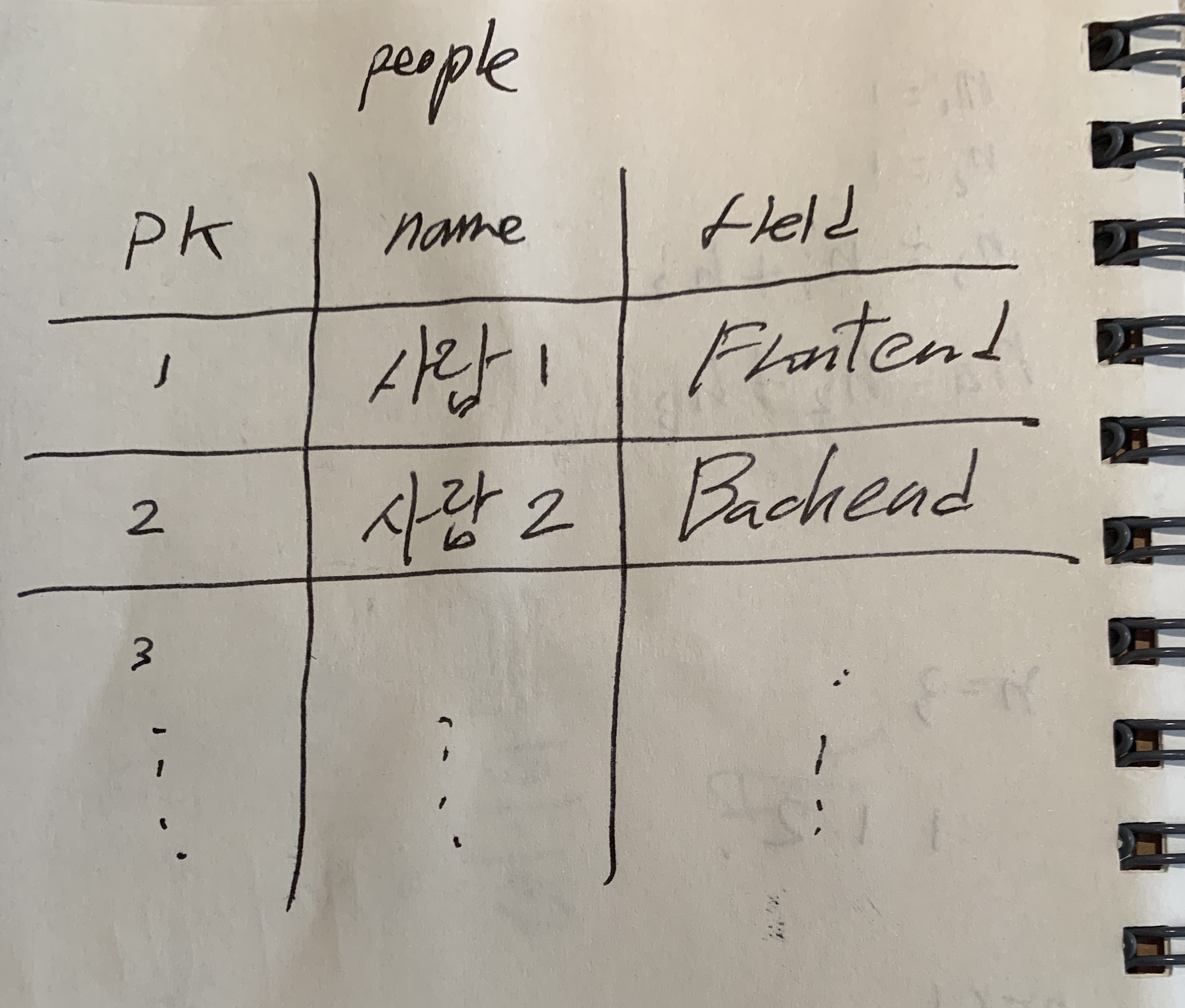
테이블은 칼럼과 로우로 구성
- 칼럼은 테이블의 각 항목들
- 로우는 각 항목들의 실제 값들
- 각 로우는 고유 키가 있다. 고유키를 통해 해당 로우를 찾거나 참조한다.
-
각 테이블들은 서로 상호관련성을 가지고 서로 연결할 수 있다.
-
테이블끼리의 연결 종류 3가지
-
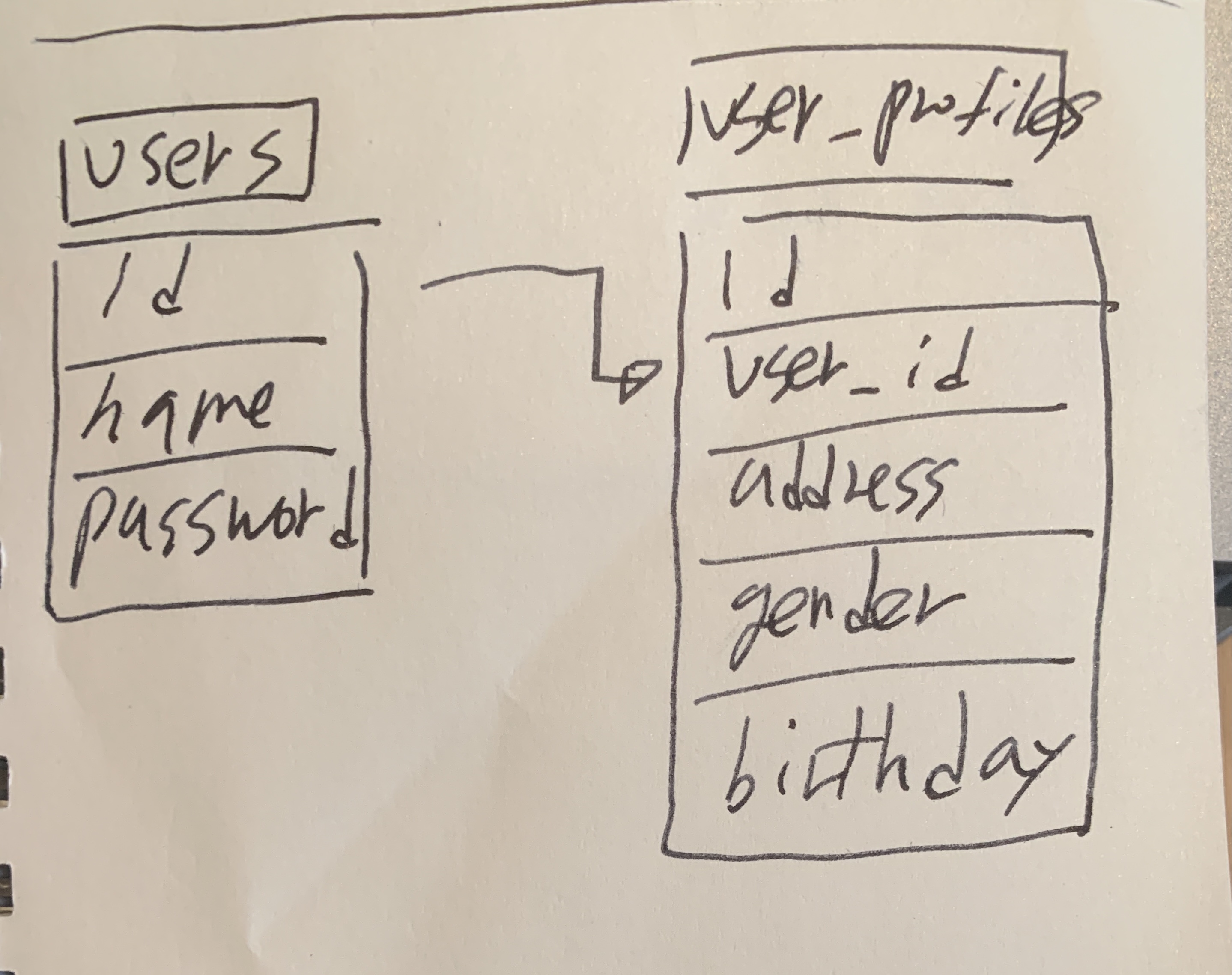
one to one
- 테이블 A의 로우와 테이블 B의 로우가 정확히 일대일 매칭이 되는 관계
-
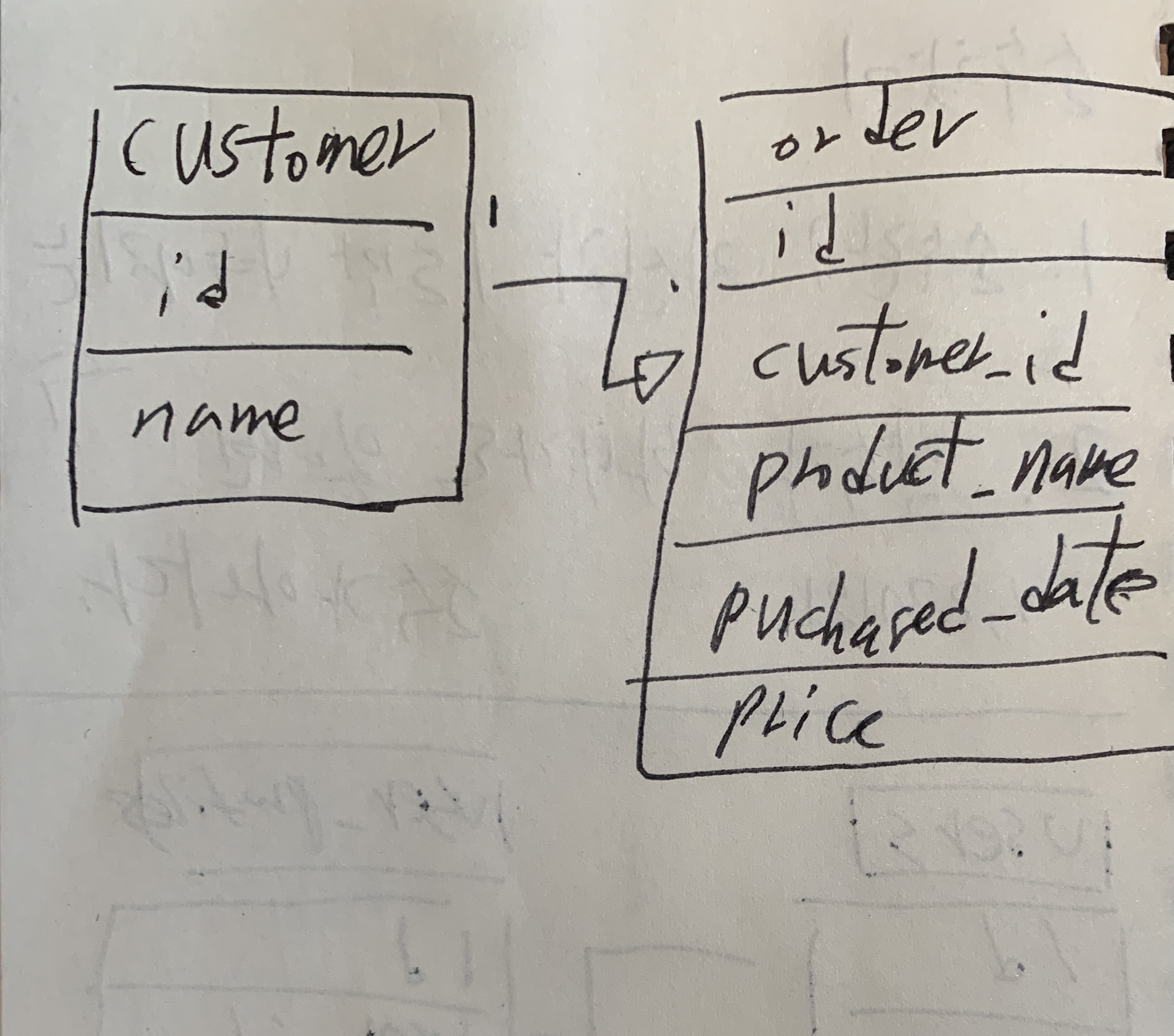
one to many
- 테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계
-
many to many
- 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결되는 관계
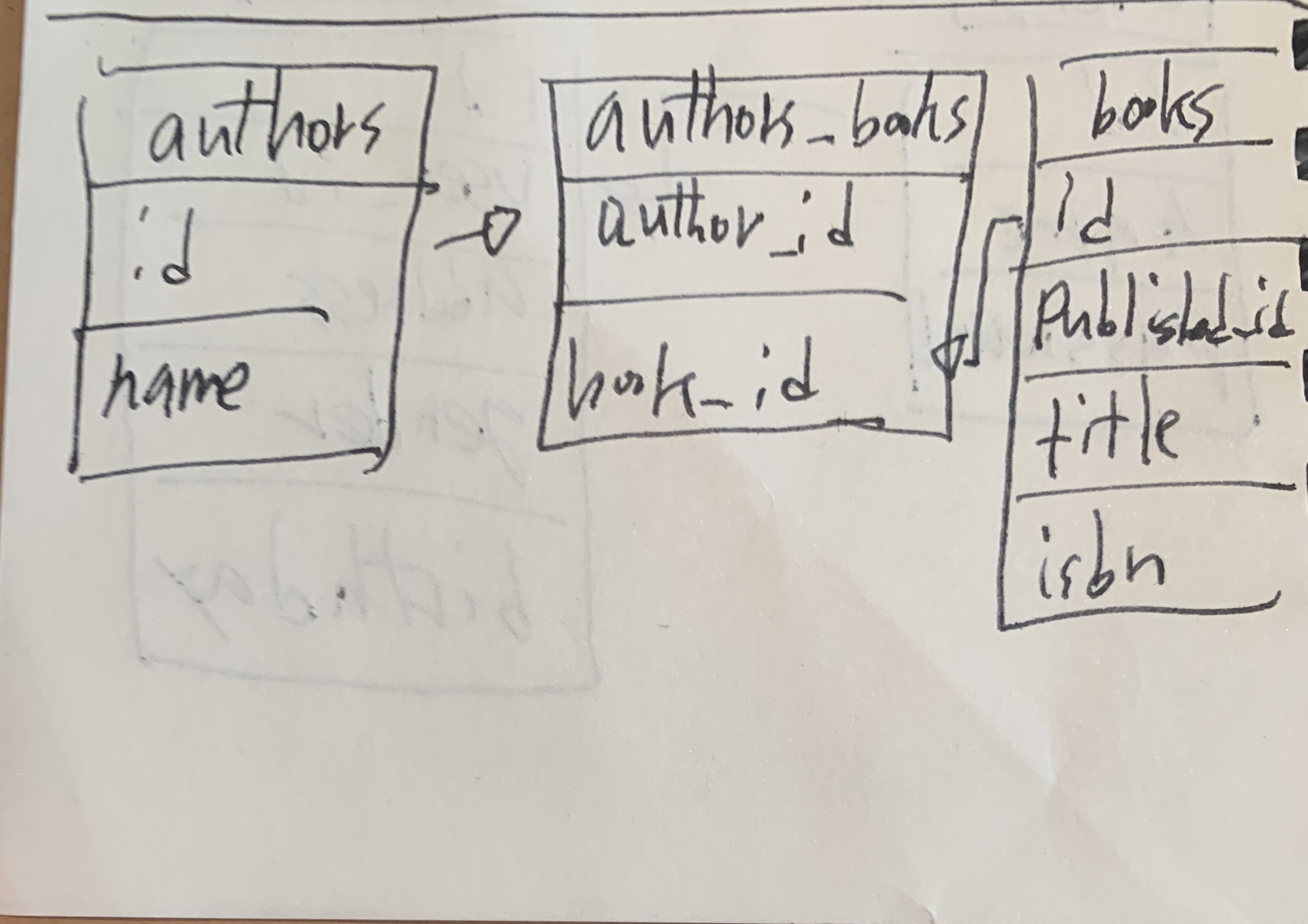
- 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결되는 관계
-
어떻게 테이블과 테이블 연결되나?
외부키(FK)를 사용하여 연결한다. 예를들어 1:1 예시에서 user_profises 테이블의 user_id 컬럼은 users 테이블에 걸려있는 외부키다!
즉, 테이터베이스에게 user_id의 값은 users 테이블의 id값이며 그러므로 users 테이블의 id 컬럼에 존재하는 값만 생성될 수 있다.
- 왜 테이블을 연결할까?
하나의 테이블에 모든 정보를 다 넣으면 동일한 정보가 불필요하게 중복 저장된다. 예를들어 고객의 아이디는 동일한데 서로 다른 로우가 있드면 어떻게 할까?
여러 테이블에 나눠 저장하고 필요한 테이블끼리 연결 하면 된다! 이것을 정규화라고 함
비관계형 테이터베이스
NoSQL라고 한다. 대표적으로 MongoDB, Redis, Cassandra
SQL VS NoSQL
- SQL
- 장점 : 쳬계적, 효율적, 데이터 완전성 보장, 트랜잭션 등등
- 단점 : 덜 유연함, 확장성 낮음
- 결론 : 정형화된 데이터 저장하기 유리하다
- NoSQL
- 장점: 구조 변화 유리함. 확장 쉬움, 방대한 데이터 저장 유리
- 단점: 완전성 덜 보장, 트랜잭션 불안정,
- 결론: 로그 데이터 저장에 유리
개념 정리
예를들어 "시작일"이란 건 구체적인 데이터가 아니라 날짜를 대표하는 하나의 단어다. 이런 것은 Attribute, 속성 또는 컬럼이라고 부른다.
후보키란 식별자가 될 수 있는 후보들! 그 키만으로 row들을 구분할 수 있는 유일한 정보를 담고 있는 키. 그 후보키들 중에서 선택한 것이 기본키! 나머지 후보키들은 대체키다.
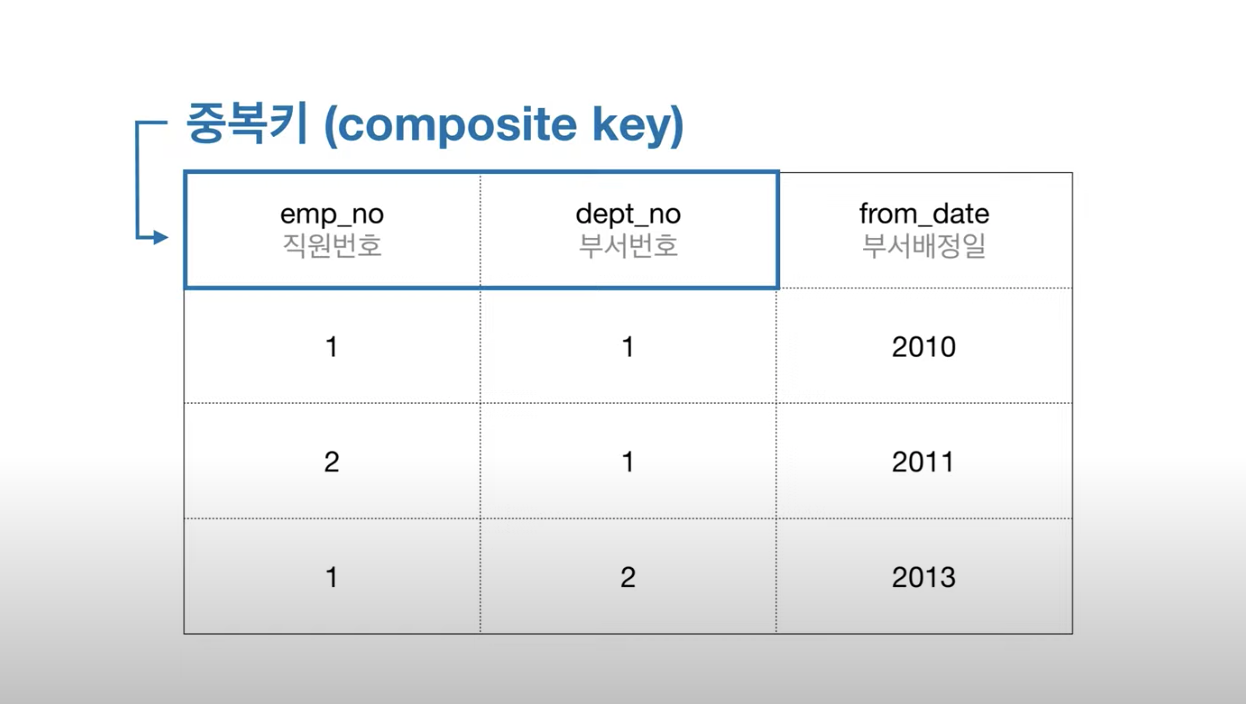
예를들어 위 테이블에서 각 컬럼은 기본키가 될 수 없다. 하지만 두 개의 컬럼을 합치면 유일한 식별자가 될 수 있다. 이런 식별자를 중복키라고 한다!
모델링 연습
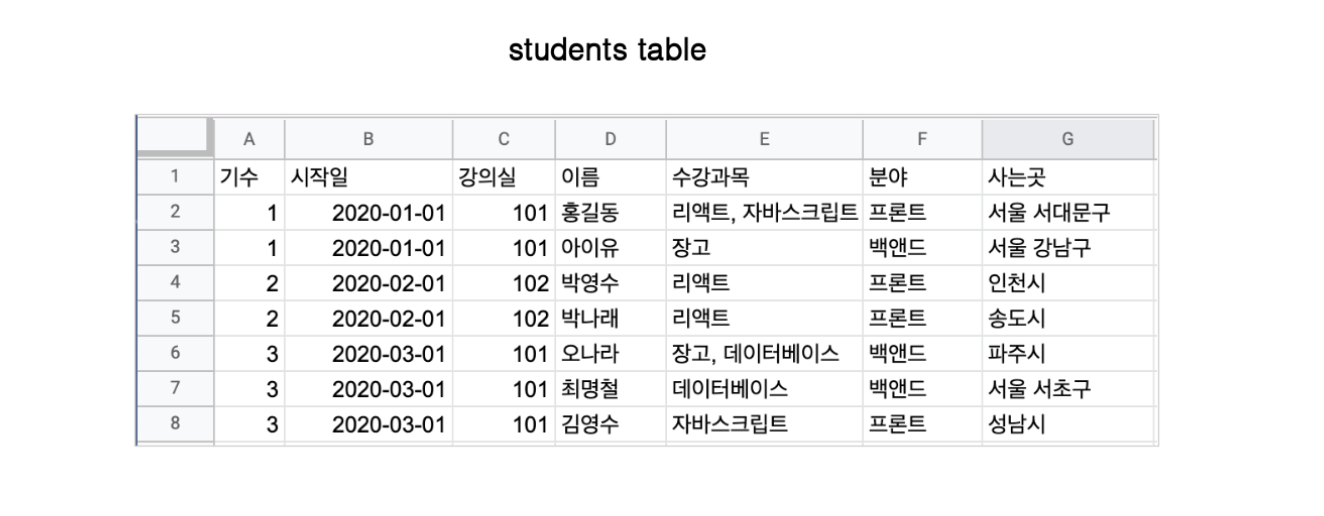
학생 테이블이 있다. 컬럼의 값(?)이라고 해야하나 정확한 표현을 모르겠지만... 겹치는 값들이 있으니 정리해야 한다! 이제 정규화를 해야하는데 정규화는 중복된 것을 합치는 일! 테이블을 만들 때, 포린키가 없는 테이블을 먼저 만드는 것이 좋다.
예를들어 기수, 시작일, 강의실, 분야는 겹친다. 이를 어떻게 표현해야 할까?
- 1차 정규형
각 로우마다 컬럼의 값이 1개씩만 원자값을 갖는다고 표현한다. 각각의 컬럼의 값들은 값을 하나만 가져야 한다.
- 겹치는 컬럼의 값을 뽑아서 새로운 테이블을 만든다!
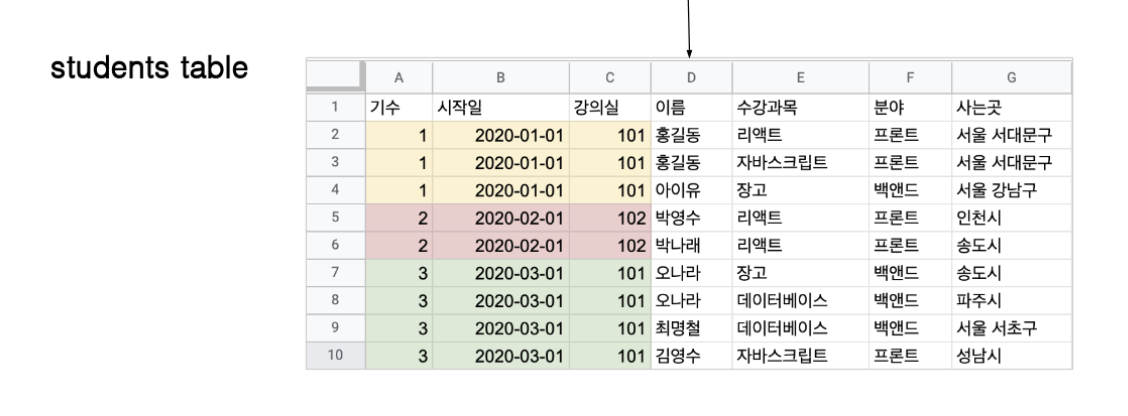
값을 여러개 값는 컬럼을 나눈다.
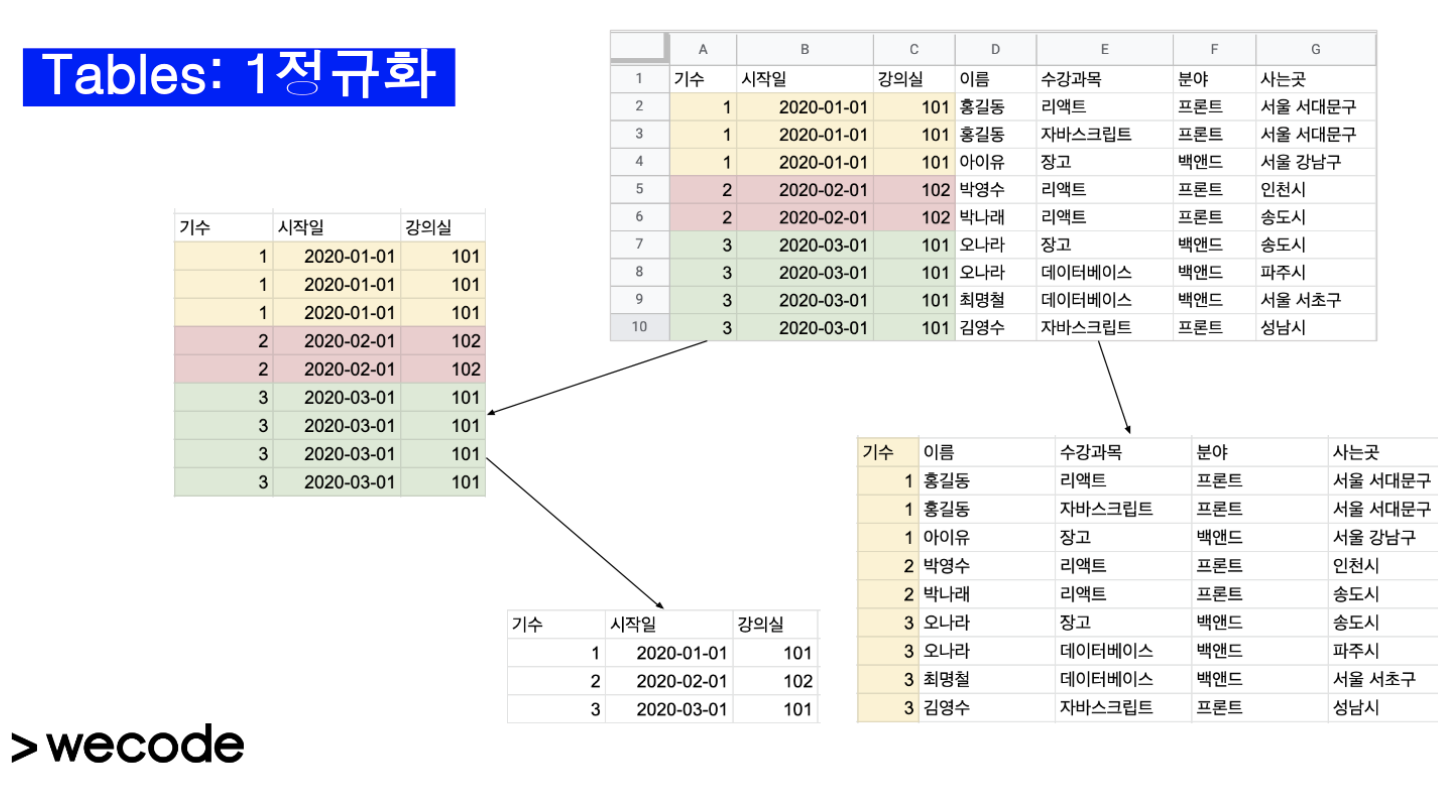
- 2차 정규형
컬럼의 값들이 중복이 발생하는 이유는 부분 종속성 때문이다. 모든 속성은 기본키에 종속! 기본키가 복합키가 되었을 때 복합키에 의존하지 않고 일부에 의존적인 로우가 있으면 이를 제거해야한다. 복합키가 되었을 때 일부에 의존적인 열은 따로 테이블을 만든다!
생활코딩에서 가져온 예시를 살펴보자
예시

보라색 컬럼의 값은 중복이 발생한 부분이다. 중복된 값은 MySQL 이란 제목에 의존하고 있다. title의 값을 알면 그 행의 값들, 중복된 값들을 알 수 있다!. 즉, type이 무엇인지랑은 관계가 없다! 중복된 컬럼의 값은 title이란 컬럼에만 부분적으로 종속되고 있다.
그럼 topic 테이블의 존재 의의는 무엇이냐!? 바로 price 컬럼 때문이다. price는 type에 따라 달라진다. 즉, topic은 title, type, price를 위한 테이블이라고 해도 무방쓰

이렇게 부분적으로 종속된 정보만 가져온다. 그리고 price의 경우 title과 type에 의존하니까 따로 테이블을 만든다.


기본키란 각 테이블에 유일한 특성을 나타낼 수 있는 값. 기본키가 여러 개면 그것을 모아 복합키라고 한다.

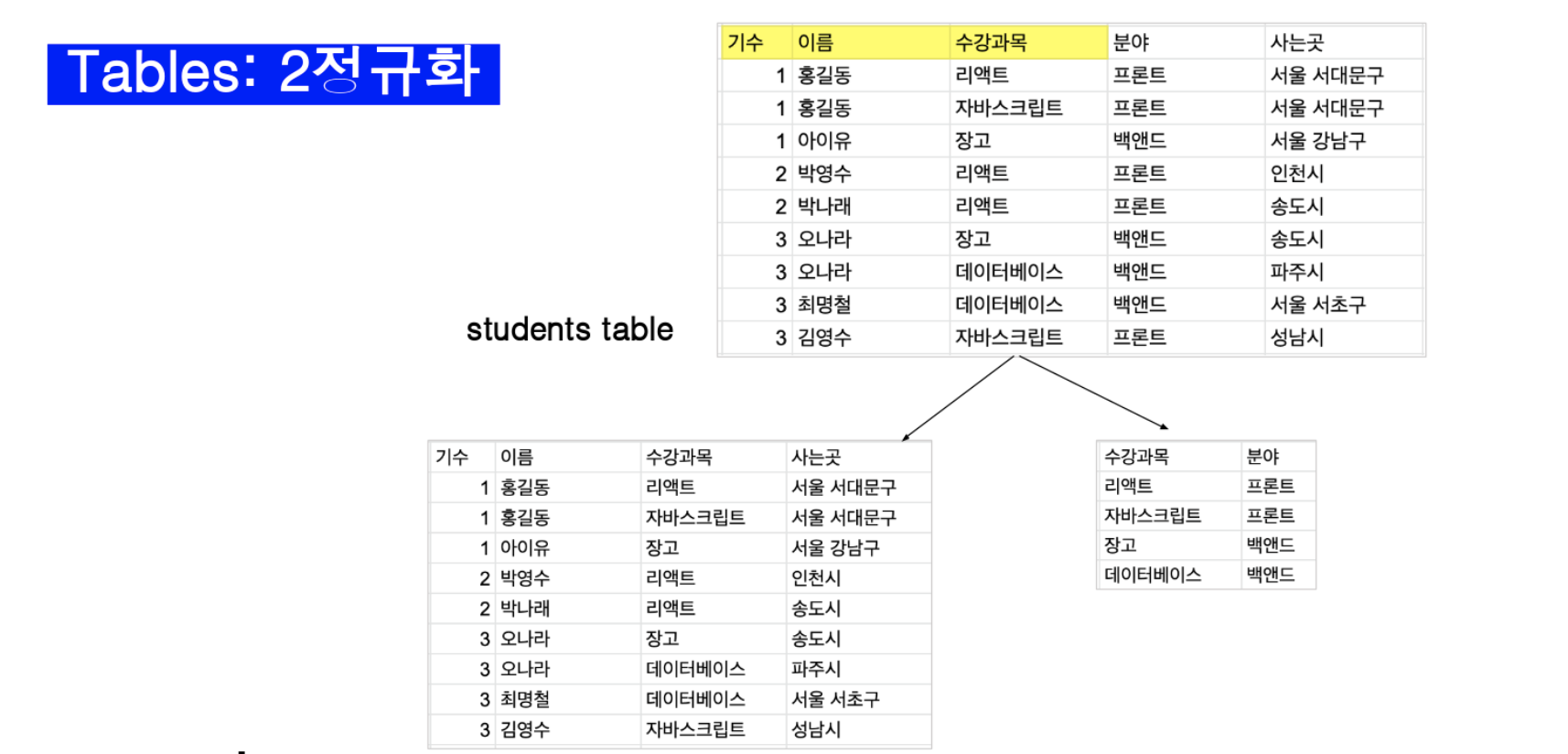
수강 과목과 분야는 일부에 의존적이다. 예를들어 사는 곳 은 지역에 따라 구분이 되지만 분야는 같은 분야라고 해도 이름(기본키)이 아니라 수강 과목 으로 구분이 가능하기 때문에 수강 과목, 분야는 따로 빼야한다.
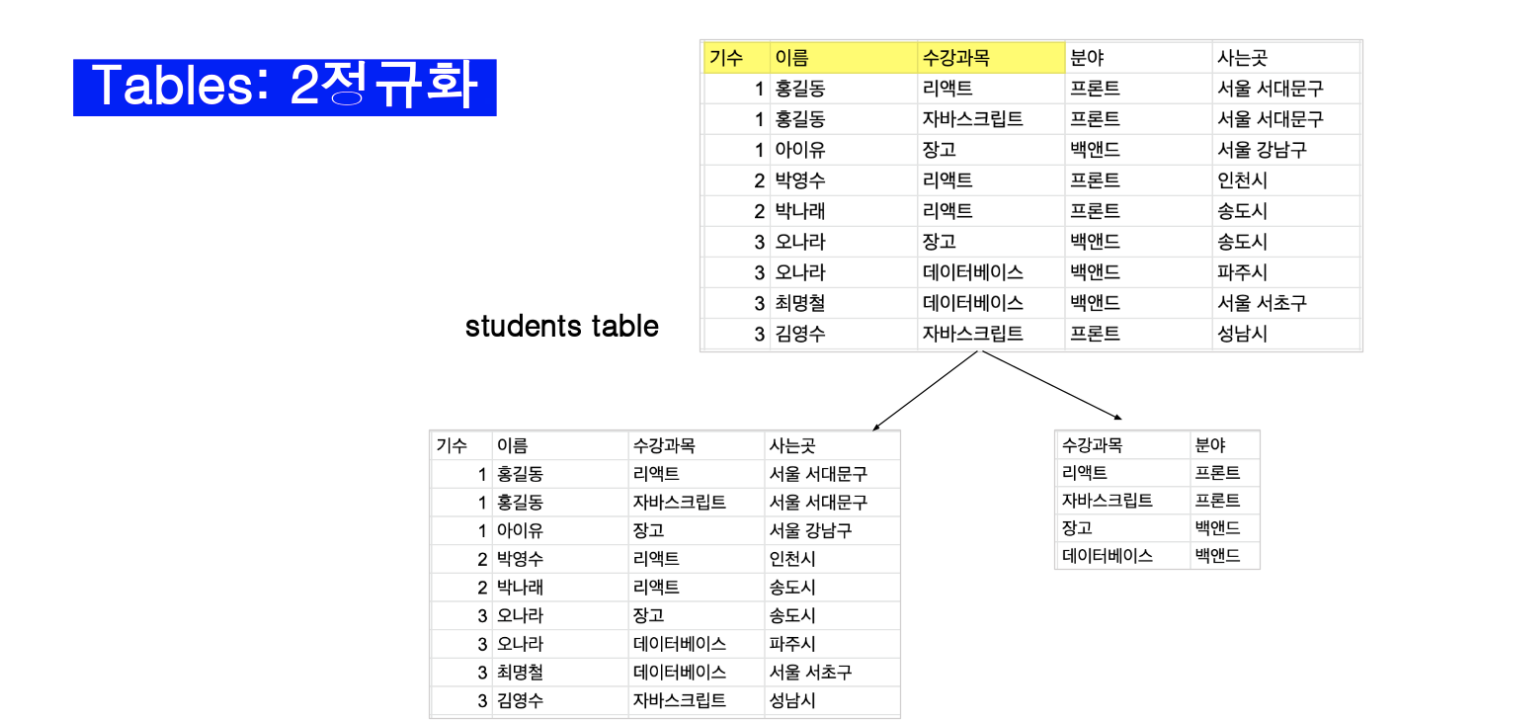
그리고 사는 곳과 수강 과목이 둘 다 이름에 종속되었기 때문에 나눌 수 있다고 한다.(길 잃음)
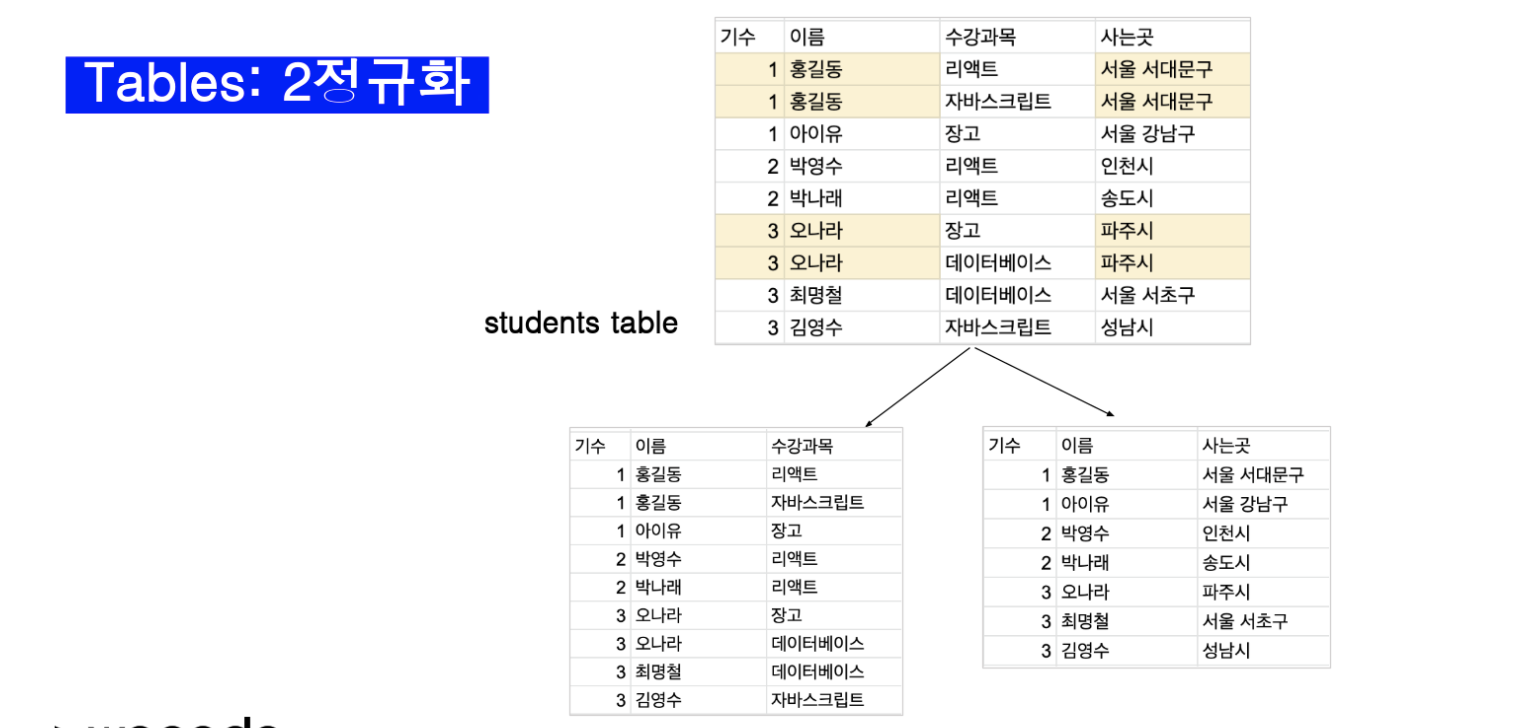
으렵다... 다음에 또 공부해야지..
출처 : 위코드 세션, 생활코딩

그의 엄청난 포스팅