
본격적으로 MCP를 배워보기 위해 Kent 선생님의 Epic AI를 시청 후 학습한 것을 정리해봄
MCP
MCP(Model Context Protocol)란 쉽게 말해 AI 모델을 외부 데이터와 도구에 연결할 수 있도록 설계된 표준 인터페이스다.
MCP는 흔히 AI계의 USB 포트라는 비유를 사용하는데, 즉 LLM이 외부 세상과 연결되는 방식을 표준화한 것이라고 할 수 있다.
그렇다면 MCP가 왜 필요할까?
기존의 LLM을 사용했던 방식을 생각해보면 AI 모델이 외부 데이터에 접근할 수 없기에 프롬프트에 데이터를 매번 복붙하거나, 매 프로젝트마다 새로운 프롬프트가 필요했다.
결국, 이러한 문제점을 MCP라는 표준 인터페이스로 해결하려고 하는 것!
MCP 구성
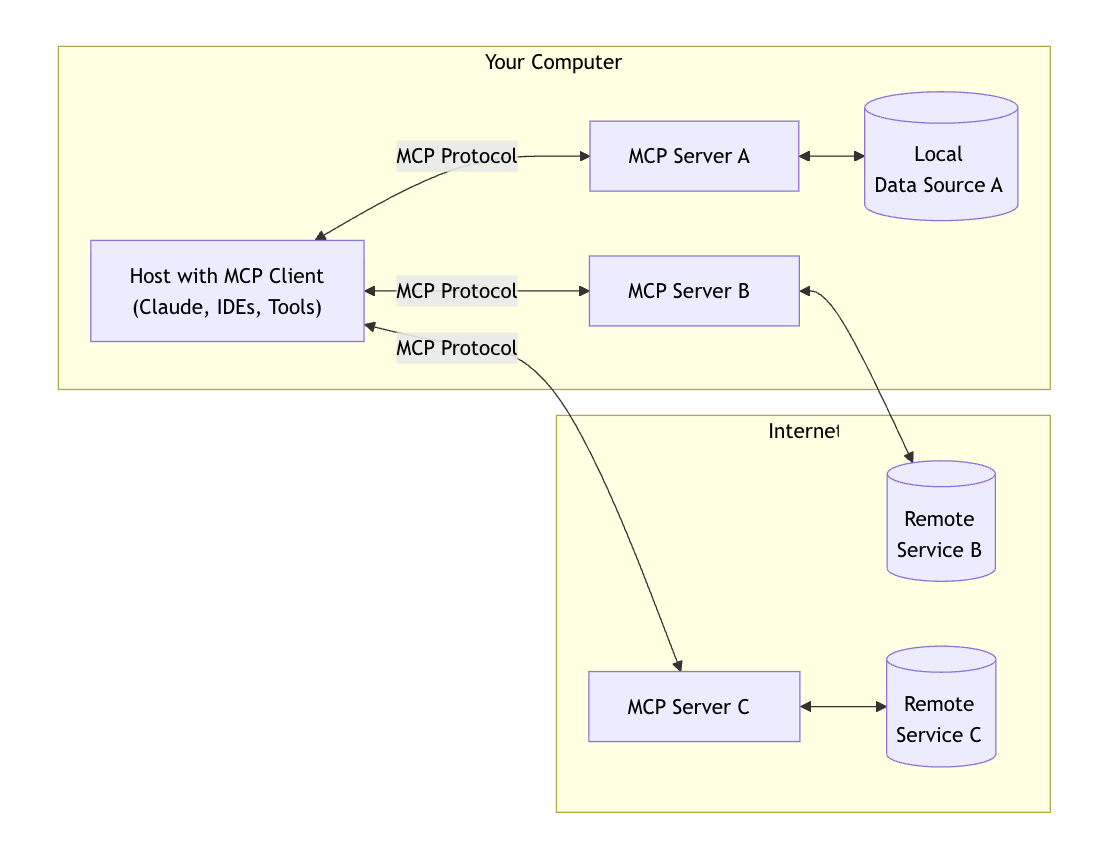
MCP는 3가지로 구성된다. 호스트, 클라이언트, 서버
호스트는 LLM이 실행되는 환경이다. 보통 개발자가 쓰는 IDE라고 생각하면 된다.
그리고 호스트 내부에 MCP 서버와 통신하는 클라이언트가 존재한다.
여기서 USB 포트인 MCP 인터페이스를 이용하여 MCP 서버와 연결한다. 실제 기능을 제공하는 백엔드다. 이를통해 로컬 파일이나 데이터에 접근하게 된다.
또한, 외부의 데이터까지 접근이 가능하다!
실습을 통해서 MCP 서버를 만들 것이다. MCP 서버는 컨텍스트 상태를 계속 유지하기 위해 MCP 클라이언트와 세션 기반으로 JSON-RPC 양방향 통신으로 이루어진다.
클라와 서버는 어떻게 요청을 주고 받을까? 실습에서는 stdio를 사용한다.
동작 방식 대략 이러하다.
- 클라가 새로운 프로세스를 생성하여 서버를 실행한다
- STDIN/STDOUT 스트림을 통해 JSON-RPC 메시지를 주고받음
실무에서는 HTTP 기반 MCP 서버를 만들지만, 실습에선 stdio를 사용한다. 하지만 내부 동작은 동일하다!
MCP Inspector
우리가 만들 건 MCP 서버다. 그렇다면 서버가 제대로 동작하는지 어떻게 확인할 것인가. 바로 MCP Inspector가 필요하다
MCP Inspector는 MCP 공식팀이 제공하는 디버깅 툴로 위 실습에서는 인스펙터를 통해 서버와 제대로 연결이 되었는지 확인할 것이다.
Tools
MCP에서 가장 큰 기능은 툴이다. MCP에서 툴은 서버가 정의한 함수로, LLM이나 클라 사이드에서 호출이 가능하다. JSON으로 입력을 받고 텍스트, 이미지, 오디오 등 다양한 형태로 반환한다.
툴의 특이한 점으로는 MCP가 어떤 도구를 호출할지 스스로 결정하고, 그 결정한 도구를 인자까지 포함해서 실제로 호출한다는 것이다.
Tools 동작방식
동작 방식은 대략 이러하다
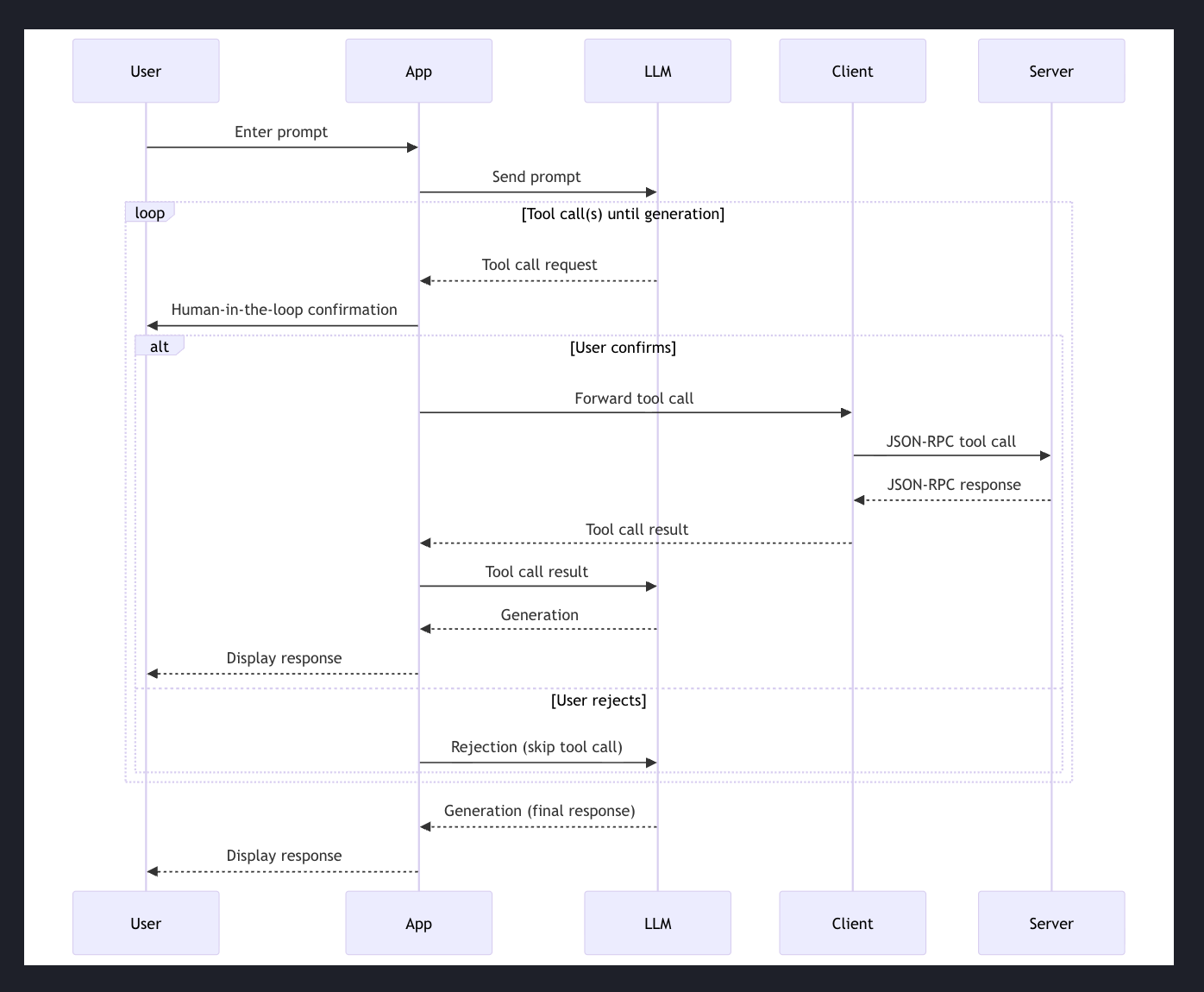
사용자가 프롬프트를 입력하면, 앱이 그 프롬프트를 LLM에 보낸다. 그러면 루프가 돌면서, 그 프롬프트를 바탕으로 도구 호출이 생성된다.
즉 LLM은 프롬프트와 다른 컨텍스트를 바탕으로 사용자의 질문에 맞는 도구를 호출해야 한다고 결정한다.

도구를 호출 전 사용자에게 이 도구를 사용할까? 라고 되묻는다. 이 과정을 human-in-the-loop라고 부른다.
사용자가 확인하면 앱은 그 도구 호출을 클라이언트로 전달하는데, 앱은 LLM이 생성한 인자와 함께 도구 호출 요청을 클라이언트로 넘긴다.
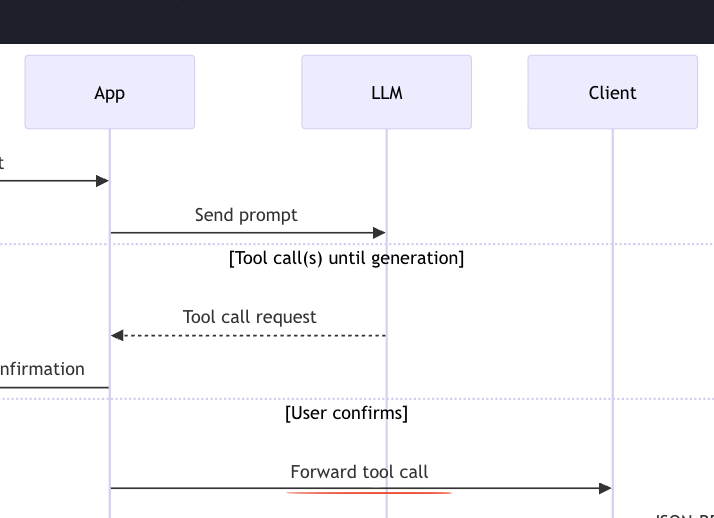
앱은 여전히 그 클라이언트를 관리하고 있으니, 여기서 앱 <-> 클라이언트 사이의 통신은 그 앱이 정한 프로토콜이다.

이제 도구 호출을 받은 클라이언트는 서버로 RPC, 정확히는 JSON-RPC 호출을 보낸다.
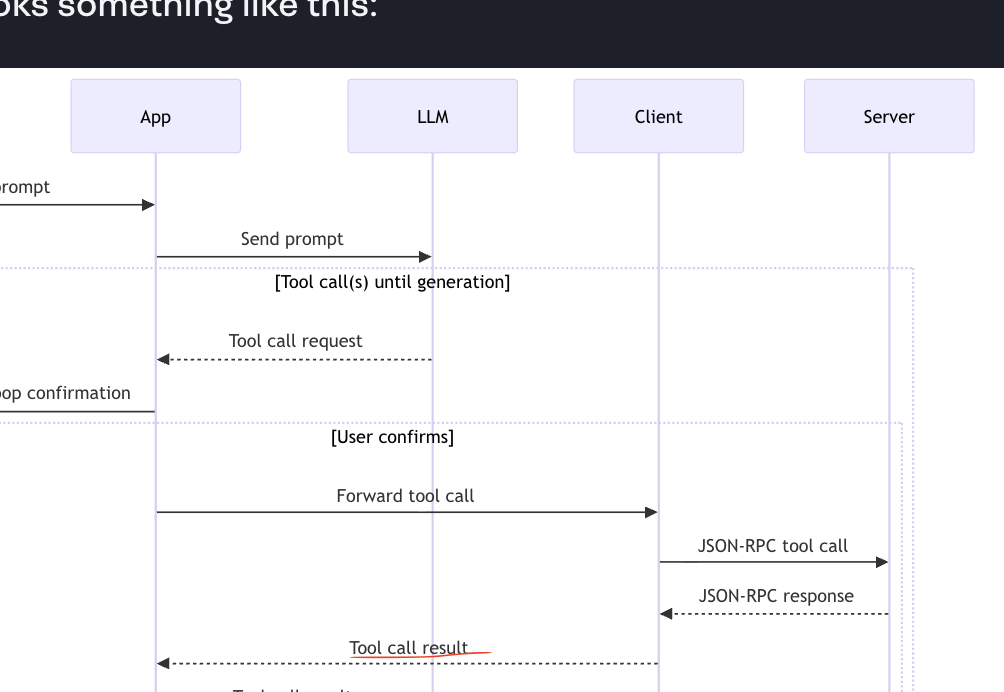
서버가 응답하면, 그 결과가 앱으로 다시 전달되고
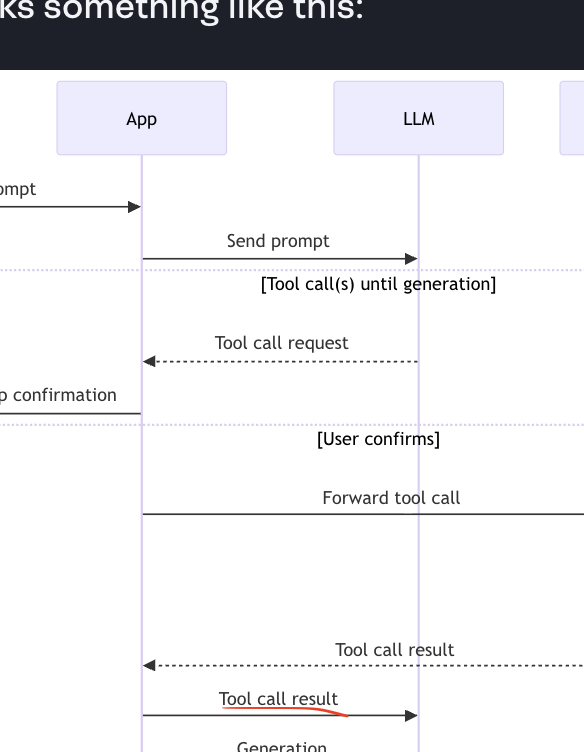
앱은 그 결과를 LLM에 다시 보내며
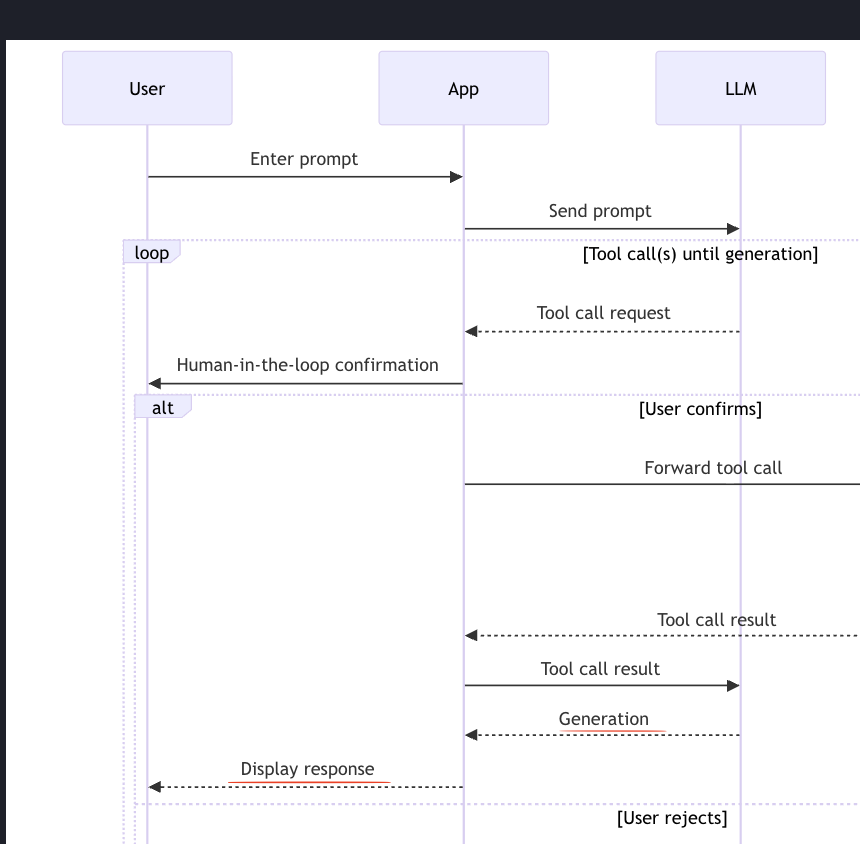
LLM은 추가 텍스트를 생성하고, 그 응답이 사용자에게 보여지게 된다.
Tools 생성
도구를 생성하는 방법은 간단하다.
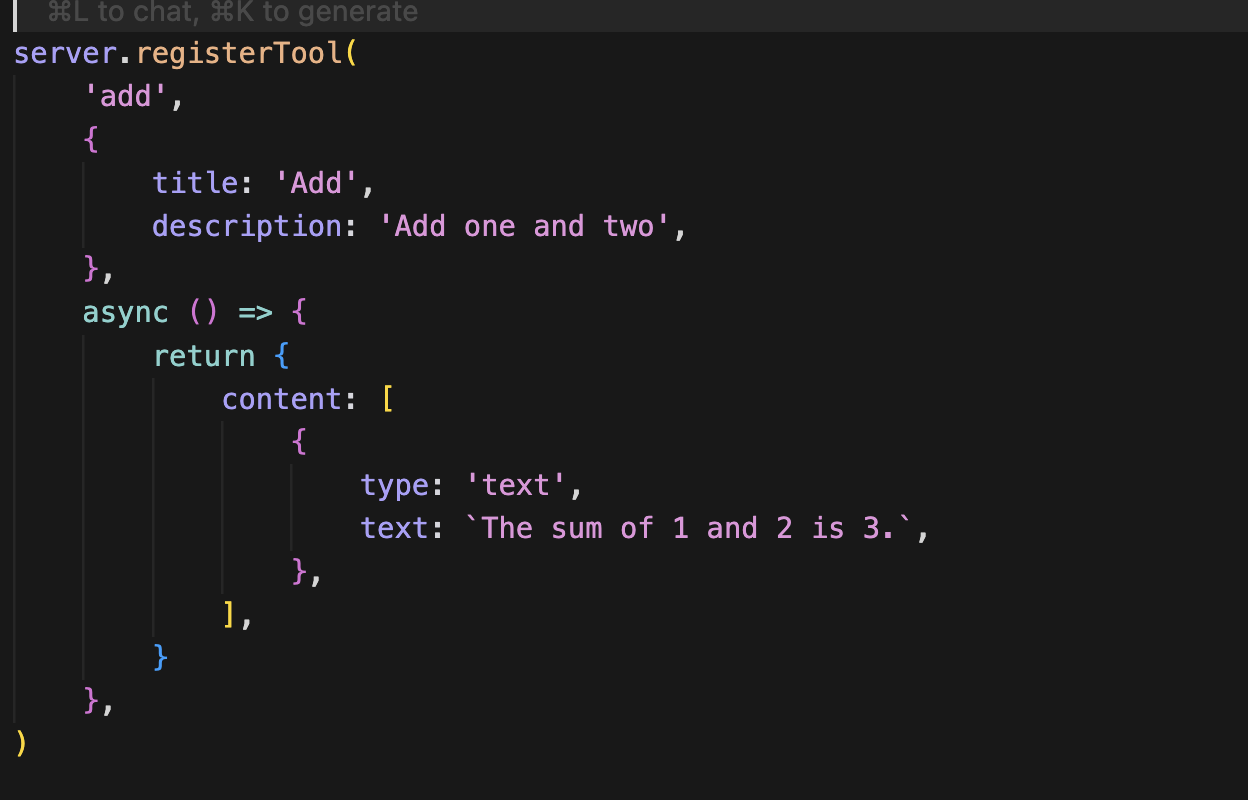
이렇게 MCP 서버에 Tool을 등록하면
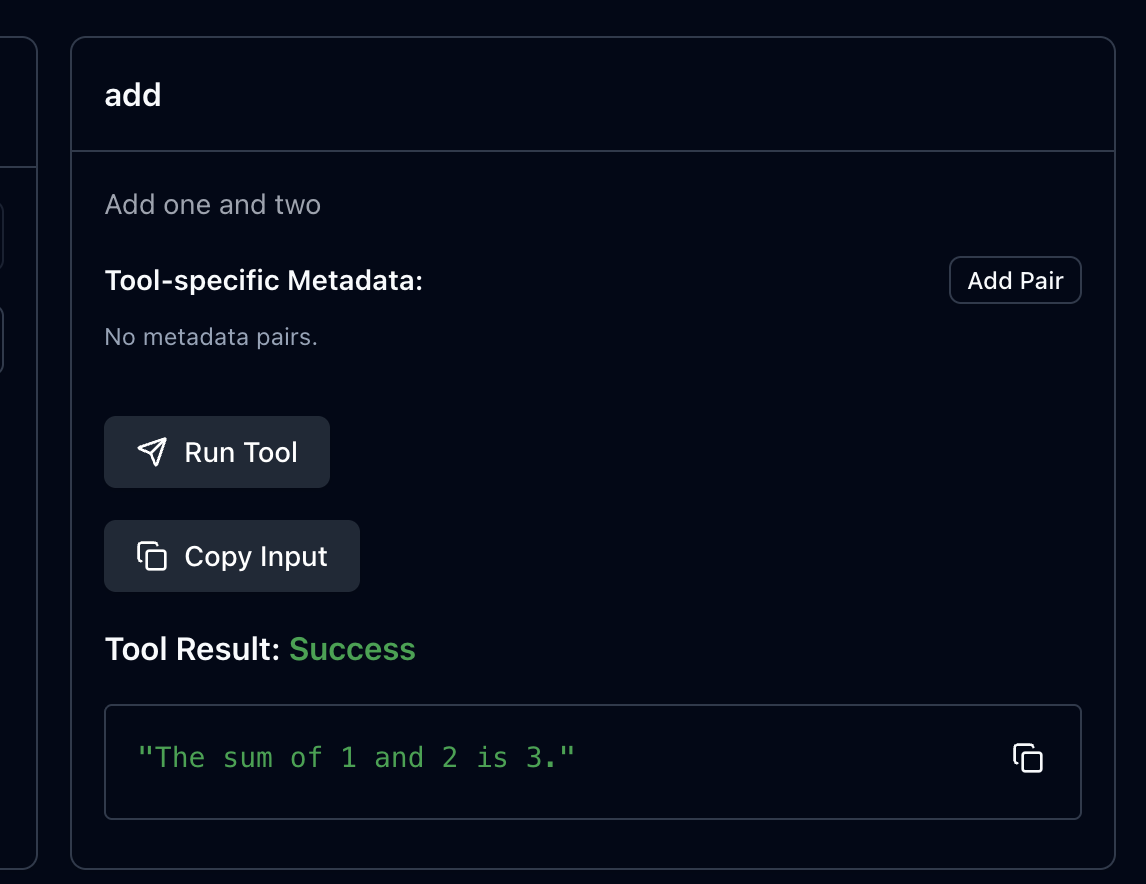
MCP Inspector에 정적 도구가 생성된다.
Tools 인자
여기서 인자를 추가해보자.
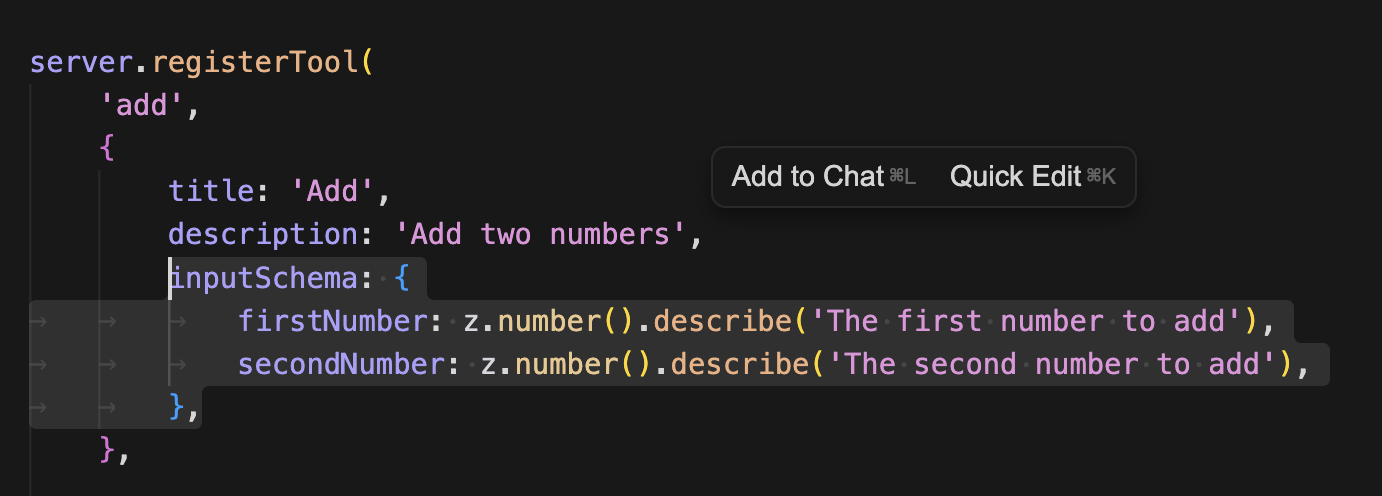
아까 만들었던 registerTool에 zod로 스키마로 주입한다. zod를 사용하는 이유는 타입 검증과 안정성인데, LLM용 스키마의 역할도 한다.
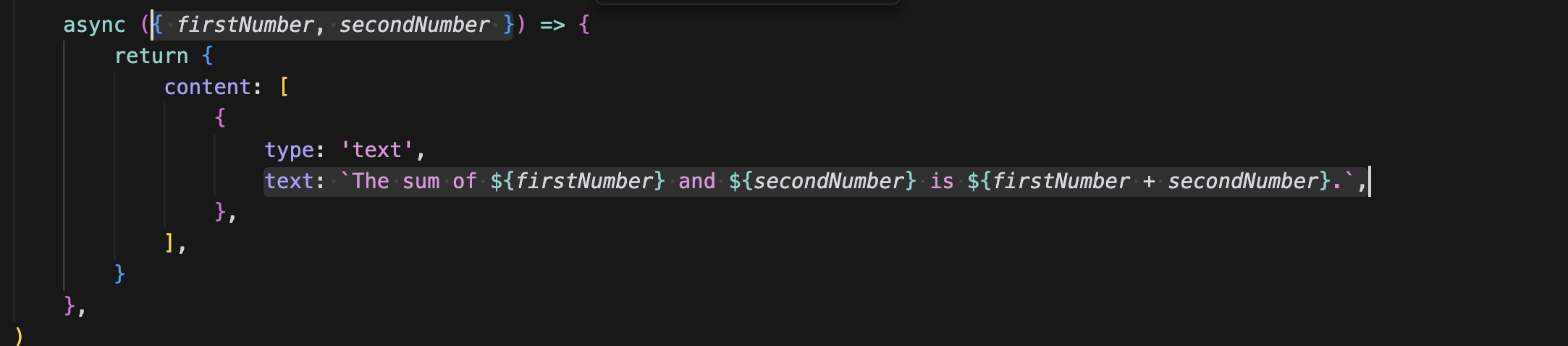
마지막으로 콜백에 인자를 받아서 return 부분을 수정하면

계산기 기능이 있는 툴이 완성된다. 여기서 중요한 점은 zod에 describe()은 LLM에게 이 도구를 언제 써야 하는지 가르치는 지침이라는 점이다.입력 프로퍼티마다 description을 달아주면 LLM이 훨씬 정확히 사용할 수 있다.
단, zod 스키마를 너무 복잡하게 만들수록, JSON Schema로 변환이 실패할 가능성이 커지기 때문에 입력 스키마는 최대한 단순하게 유지하고, 복잡한 검증은 콜백 함수 안에서 직접 처리하는 걸 권장한다.
Tools 에러 핸들링
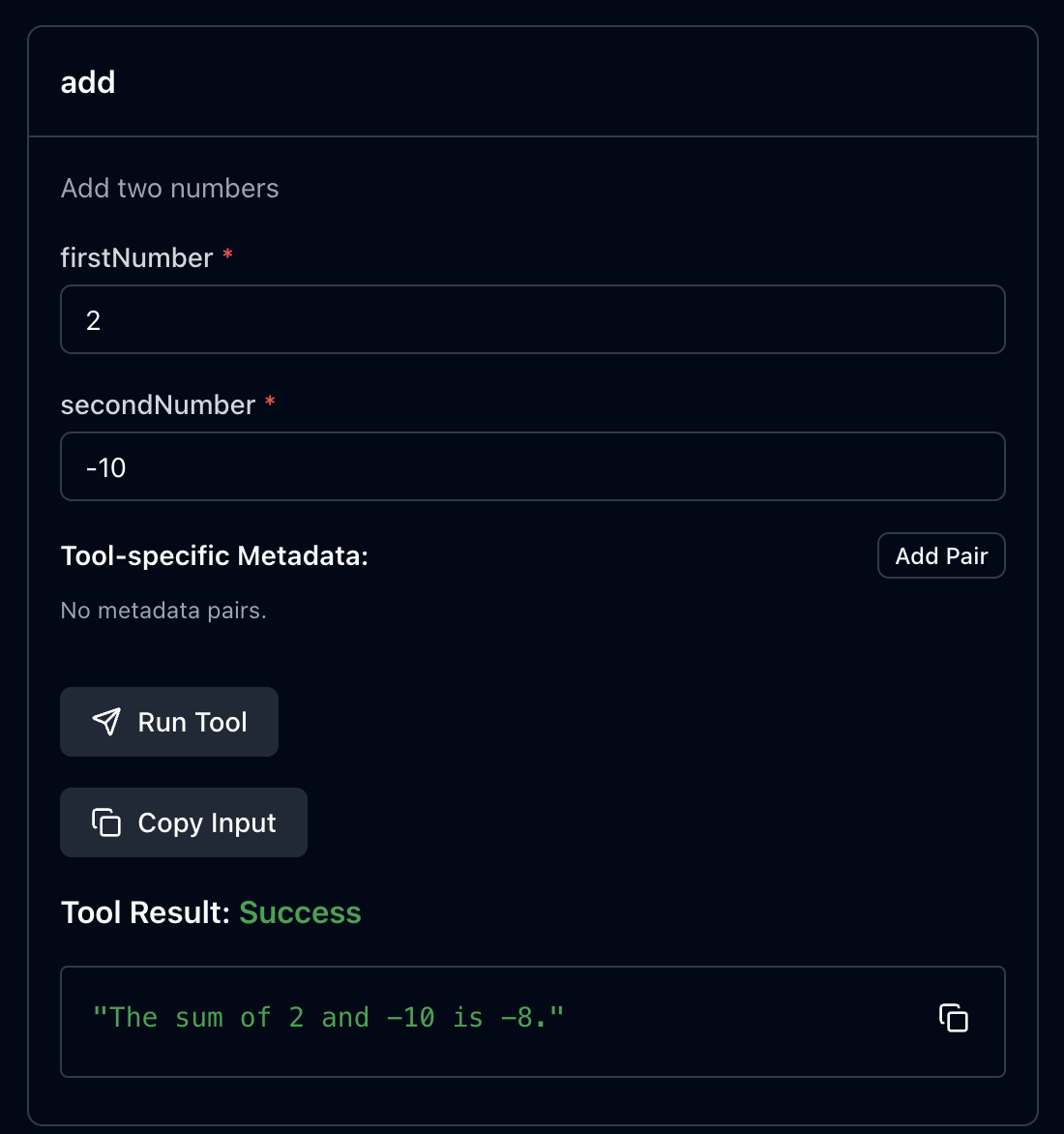
이처럼 음수가 들어갔을 때는 에러를 뱉어보려고 한다.
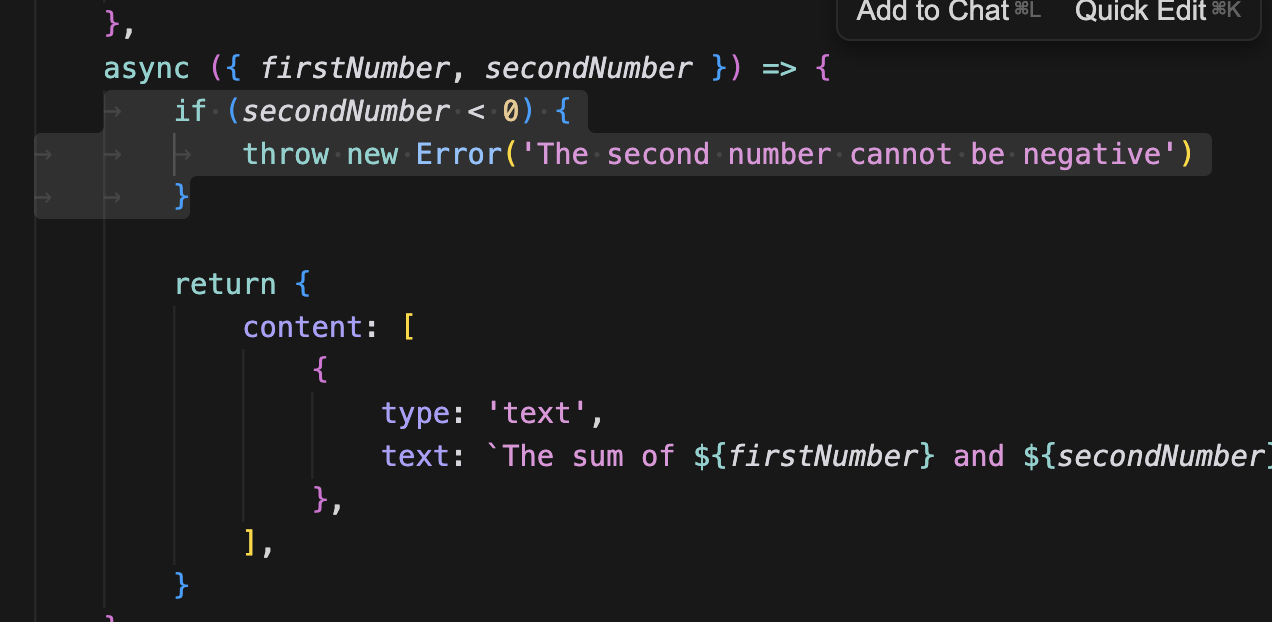
아주 간단하다. 콜백 부분에 예외 처리를 해주면 된다. 이렇게 되면 실제 응답에서 isError: true을 포함하게 되고 MCP TypeScript SDK가 에러 응답 형태로 변환해준다.
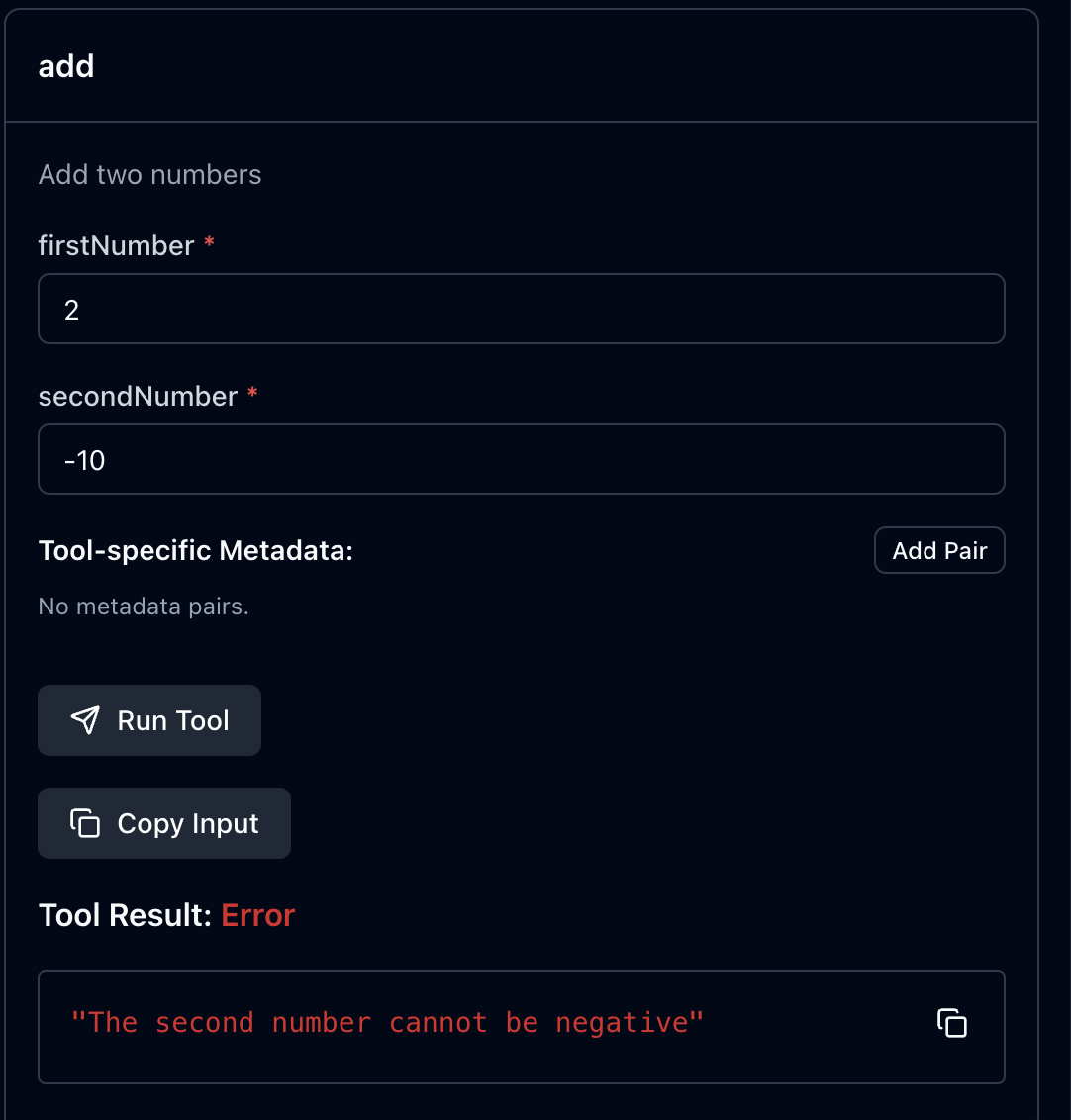
호스트 애플리케이션은 이 에러를 LLM에게 전달하면서 방금 시도한 게 실패했고, 이유는 이것이다라는 식으로 알려준다.
사람이 읽을 수 있고, LLM이 파싱 가능한 JSON 구조의 에러는 LLM이 스스로 전략을 세울 수 있도록 한다!
Resources
사용자가 만약 아주 특정한 리소스 선택하려고 할 때를 상상해보자. 예를 들어 index.ts를 편집하려고 했을 때 프로젝트에 index.ts 파일이 수 천개 있을 수가 있다. 그래서 LLM에서 어느 index.ts를 말하는지 정확히 지정해줘야 한다.
즉, 사용자 <-> LLM 커뮤니케이션 레이어를 더 명확하게 해야한다. 이런 방식으로 사용자가 컨텍스트에 포함시키고 싶은 것을 더 구체적으로 지정할 수 있는데, 이것을 우리는 리소스 라고 부른다.
워크플로우

대략적인 워크플로우는 대략적으로 아래와 같다
- 사용자가 컨텍스트에 포함해달라는 요청을 한다
- 애플리케이션이 list resources라는 RPC 요청을 호출한다.
- 클라이언트가 그 요청을 서버로 전달한다.
- 서버가 사용 가능한 리소스 목록을 모두 돌려주고
- 클라이언트가 그걸 앱으로 전달한다
- 사용자는 그중 하나를 보거나 선택하게 된다.
리소스도 결국은 또 하나의 JSON-RPC 요청이다. 리소스를 읽을 때 params에는 해당 리소스의 URI가 들어갑니다.
{
"jsonrpc": "2.0",
"id": 2,
"method": "resources/read",
"params": {
"uri": "taco://menu/items/carne-asada"
}
}예를 들어 taco://menu-items/carne-asada 같은 URI를 넣고,
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"contents": [
{
"uri": "taco://menu/items/carne-asada",
"mimeType": "application/json",
"text": "{\"name\":\"Carne Asada Taco\",\"ingredients\":[\"steak\",\"tortilla\",\"onion\",\"cilantro\"],\"instructions\":\"Grill the steak, chop into small pieces, serve on warm tortillas\"}"
}
]
}
}응답에서는 요청과 응답을 매칭하기 위한 동일한 ID가 있고, result에는 contents 배열이 들어간다.
여기서 살펴볼 점은 result에 content 내부에"uri": "taco://menu/items/... taco라고 되어 있는 스킴이다. MCP에서 스킴은 중요한 건 일관성이다. 특정 스킴을 이해하는 클라이언트와 통합하는 상황이 아니라면, 스킴 자체가 무엇인지는 큰 문제가 아니다. 중요한 것은
- 클라이언트가 그 스킴으로 요청을 만들 수 있고
- 서버가 그 요청에 대해 리소스를 돌려줄 수 있으면
그것으로 동작한다.
그럼 인스펙터로 돌아가보면

리소스 패널이 비활성화가 되어있는데 리소스를 만들어보자!
리소스 초기화 및 호출
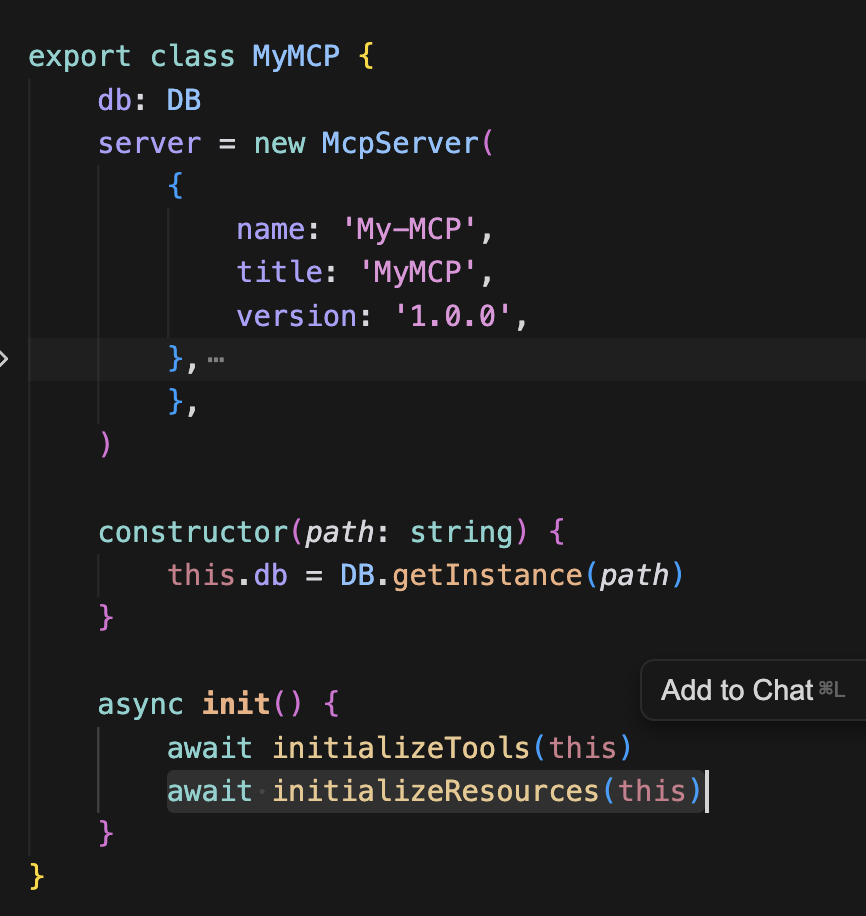
initializeResources라는 초기화 함수를 init으로 등록해두고
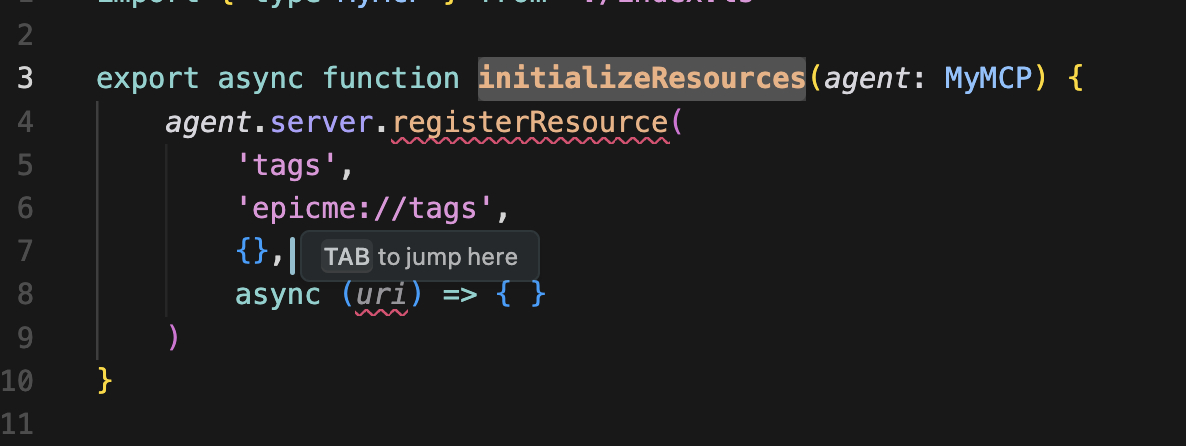
initializeResources 에선 툴 등록처럼 레지스터를 해준다.
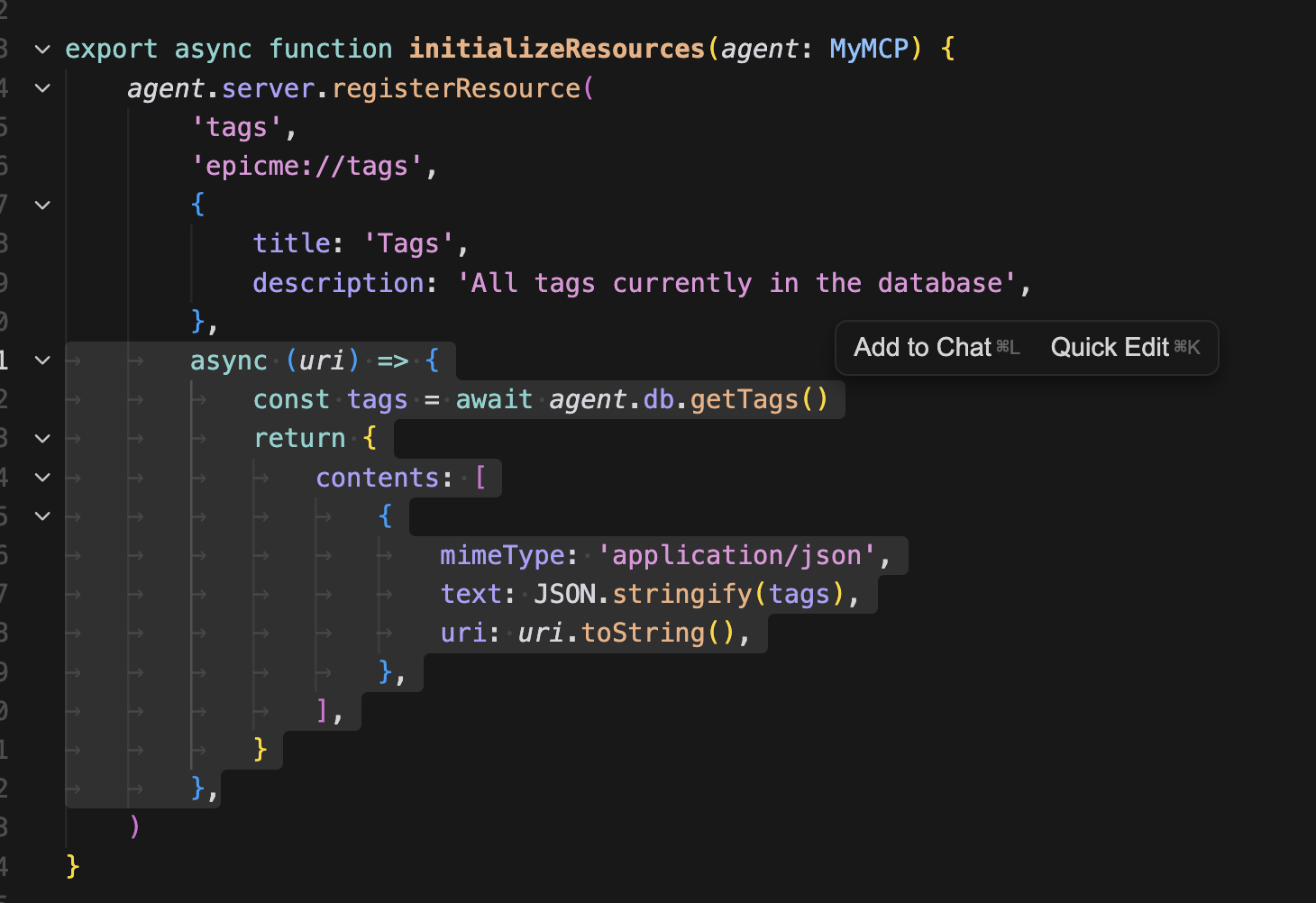
여기서 핵심은 async callback 이 실행될 때 URI를 입력으로 받게게 된다. 그리고 우리가 리턴하는 content 안에 그 URI를 포함해야 한다.
이제 인스펙터에서 리소스를 실행해보자
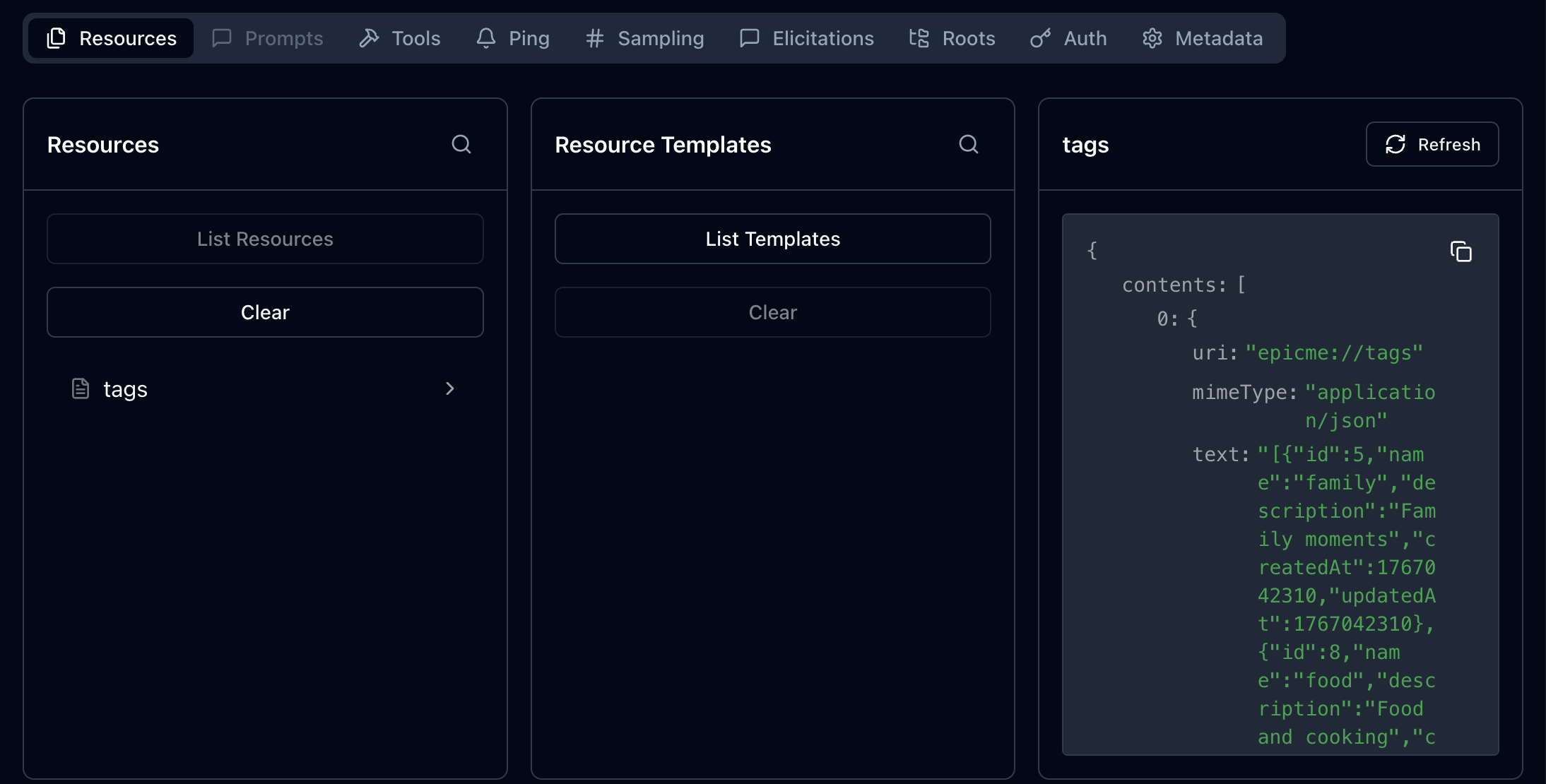
DB에 seed로 넣어뒀던 모든 태그 데이터를 가져왔다.
리소스 템플릿
DB에 있던 태그들은 이름과 설명만 있는 작은 데이터라서 tags 전체를 하나의 리소스로 제공해도 상관없었다
하지만, 데이터의 양이 늘어난다면 어떻게 해야할까? 전부를 한 번에 가져오는 것보다 좋은 방법이 있을 것이다
이때 Resource Template을 사용할 수 있다. 모든 리소스를 하나하나 registerResource로 등록하는 대신, 리소스의 Template을 만들어서 필요한 것만 가져오도록 하는 것이다.
리소스 템플릿은 URL과 개념적으로 같다. 깃헙 URL을 떠올려보자
github.com/{username}/{repo}
파라미터만 달리해도 여러 데이터를 쉽게 가져올 수 있다.

새로운 리소스 레지스터를 추가하고. SDK에서 제공하는 ResourceTemplate에 URI 템플릿을 지정해둔다.
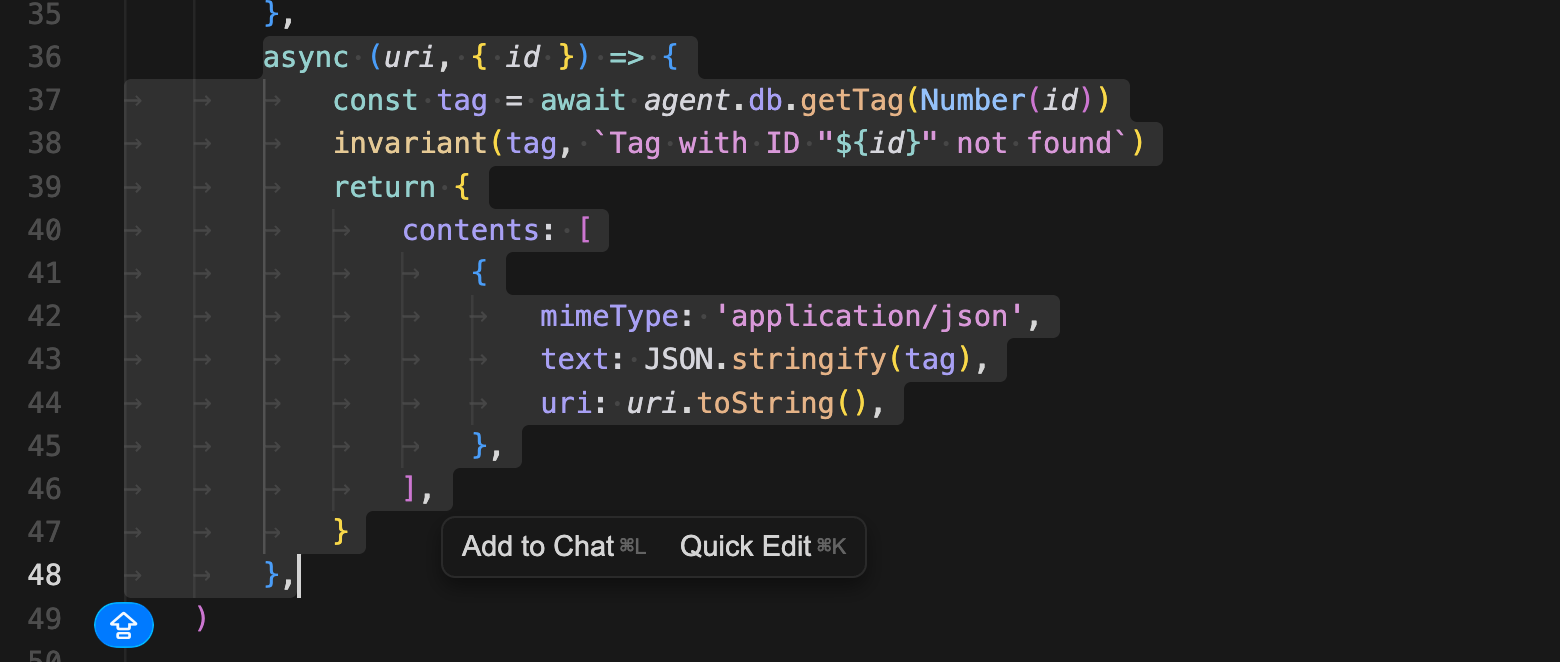
콜백에서 id를 넘기고 DB에서 조회하는 구조다. 이렇게 정적 리소스에서 동적 리소스로 확장하였다.
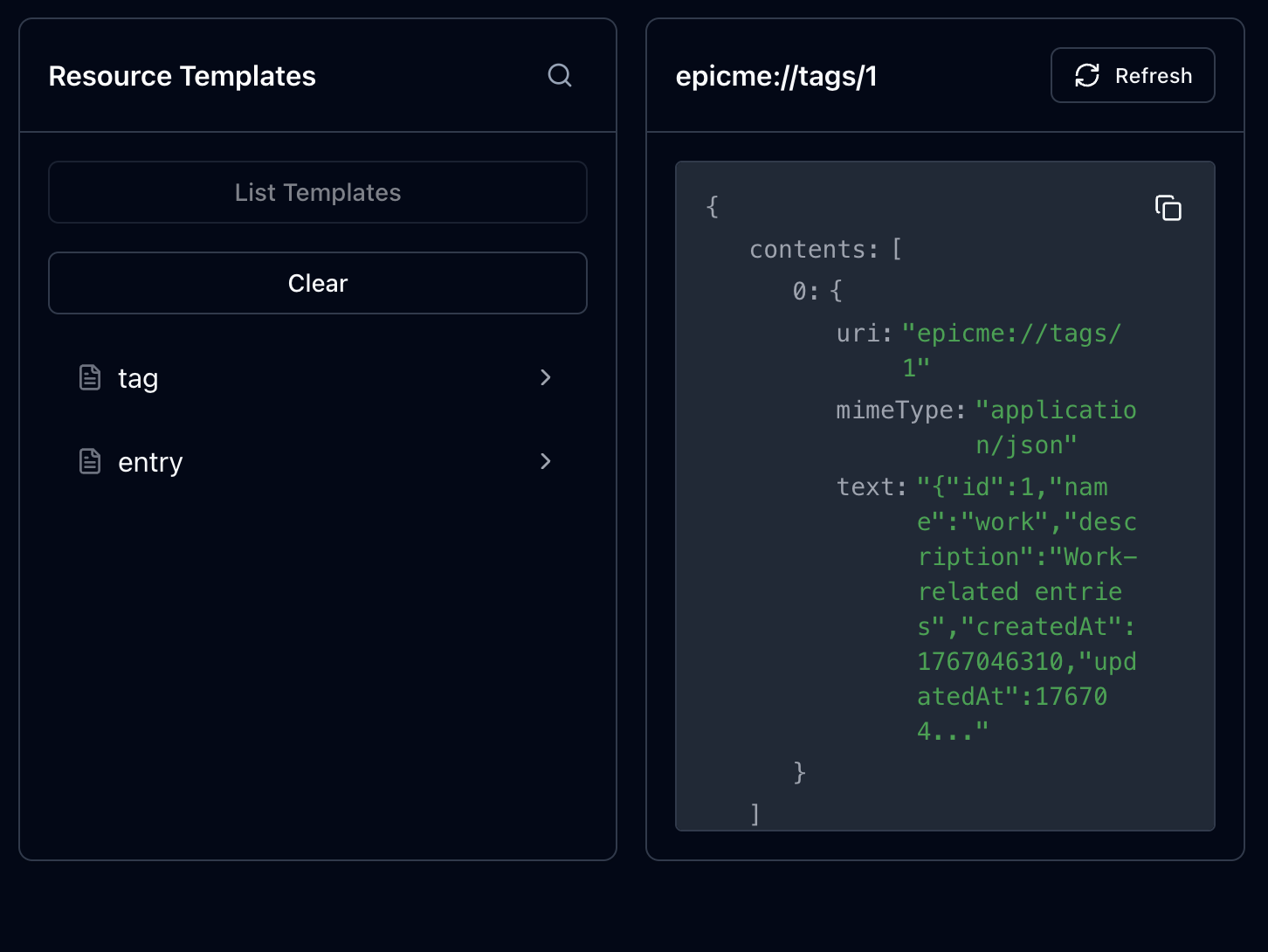
인스펙터에서 리소스 템플릿을 선택하고 id를 1로 했을 때, 1에 해당하는 데이터를 잘 가져온다.
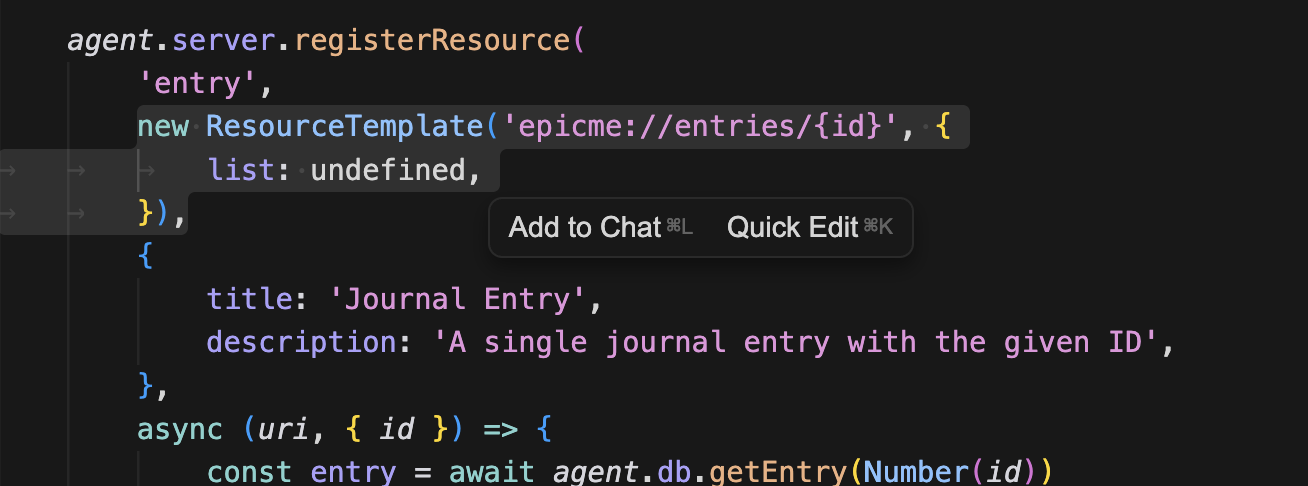
동일한 형태로 entry 에 관한 리소스 템플릿을 하나 더 생성하고
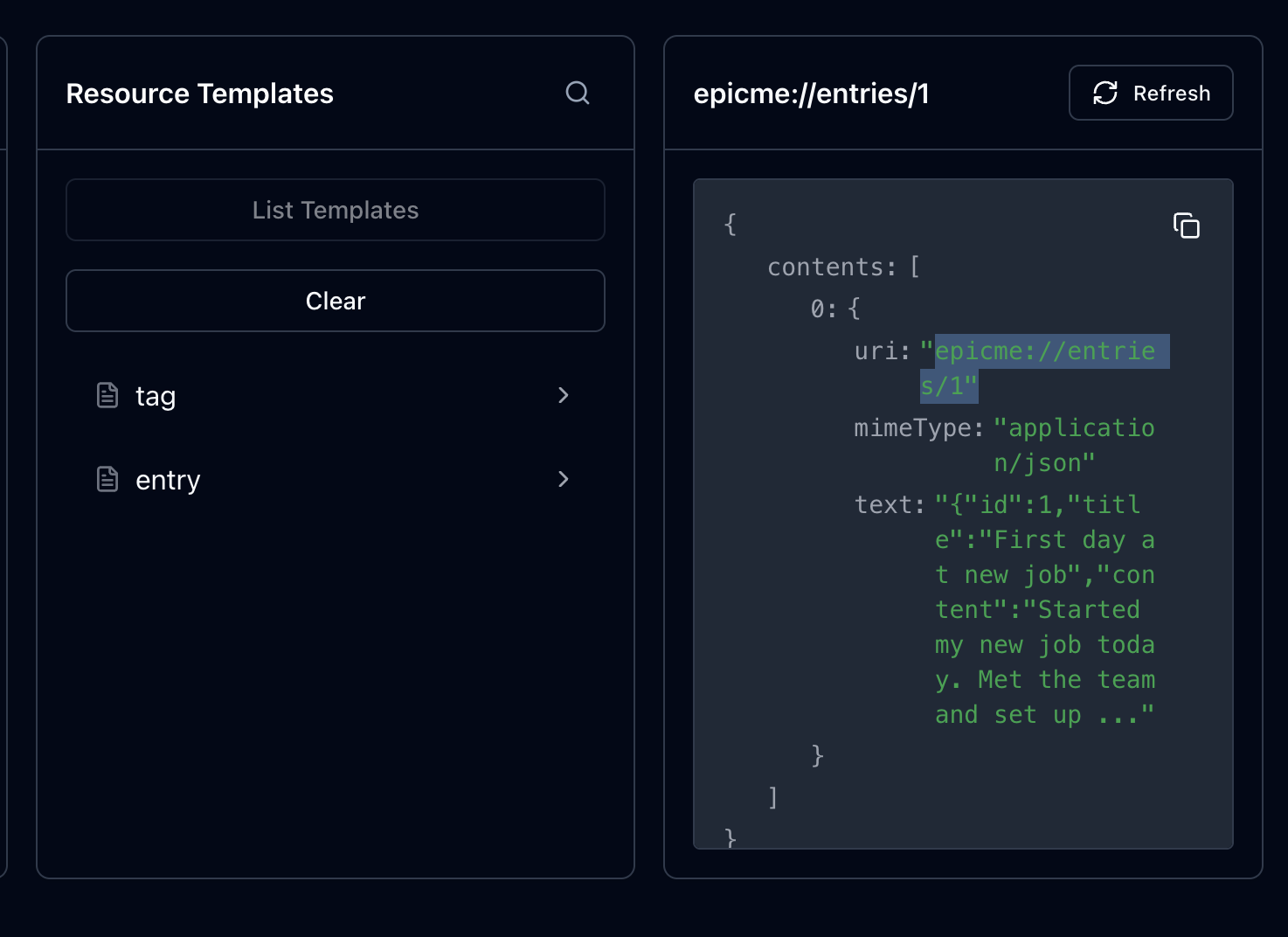
인스펙터에서 리소스를 호출해보면 entry에서 잘 가져오는 것을 확인할 수 있다.
정적 리소스에서 템플릿 리소스로 확장하면서 DB 전체를 URL 네임스페이스로 노출하는 효과를 얻는다
LLM이 필요할 때 정확한 데이터만 읽을 수 있고, 컨텍스트 로드 비용이 최소화된다! 즉, 템플릿 리소스 덕분에 DB를 파일 시스템처럼 만들어버린 것
리소스 목록
이제, 인스펙터에서 리소스를 목록으로 조회할 수 있게 확장해볼 것이다.
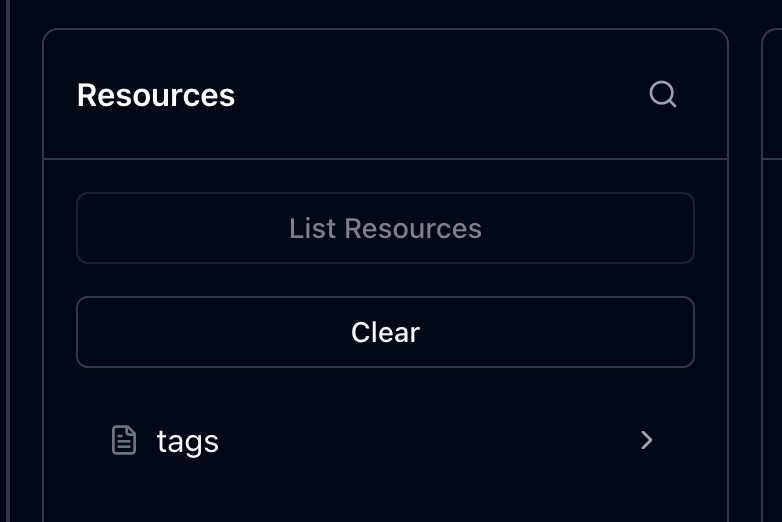
현재는 하드 코딩해둔 tags 하나만 있는데

이런 식으로 모든 태그들이 나오도록 할 것이다.
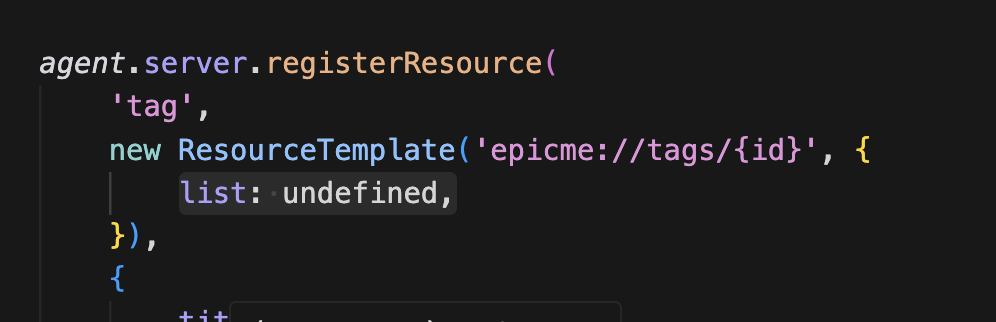

기존에 undefined로 할당했던 list의 값을 콜백으로 변경해야 한다.
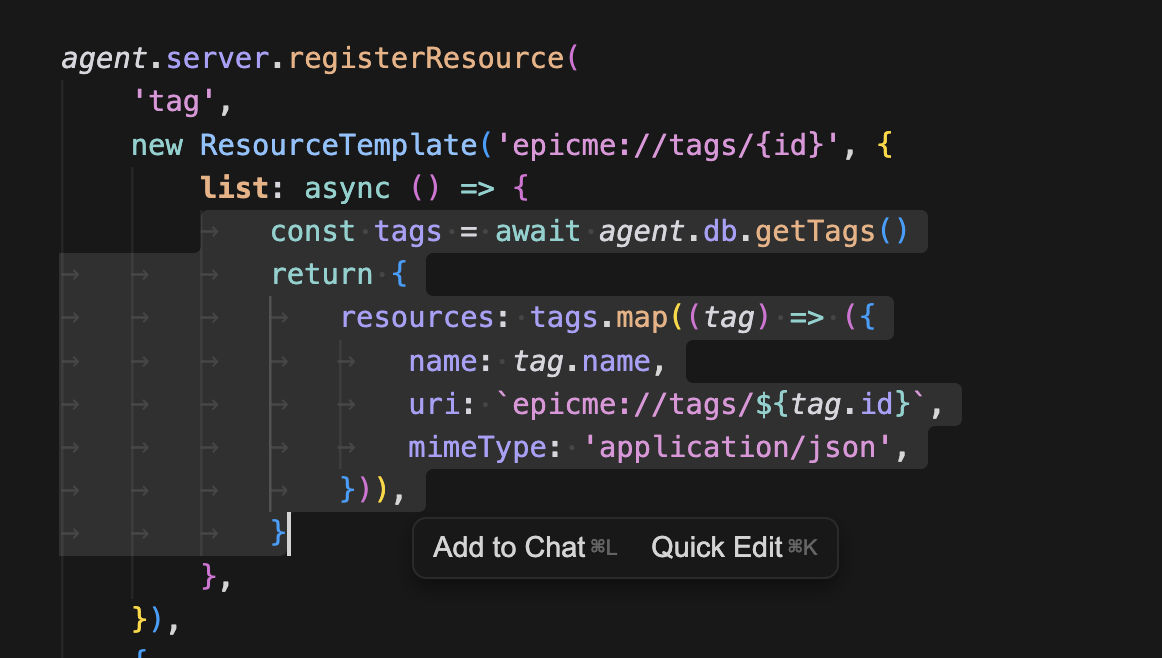
그리고 DB에서 리스트를 가져와서 리턴해준다. 여기서 여기의 mimeType/description은 리스트 항목에 대한 메타데이터다. 실제 리소스 본문은 read(uri) 콜백이 책임진다.
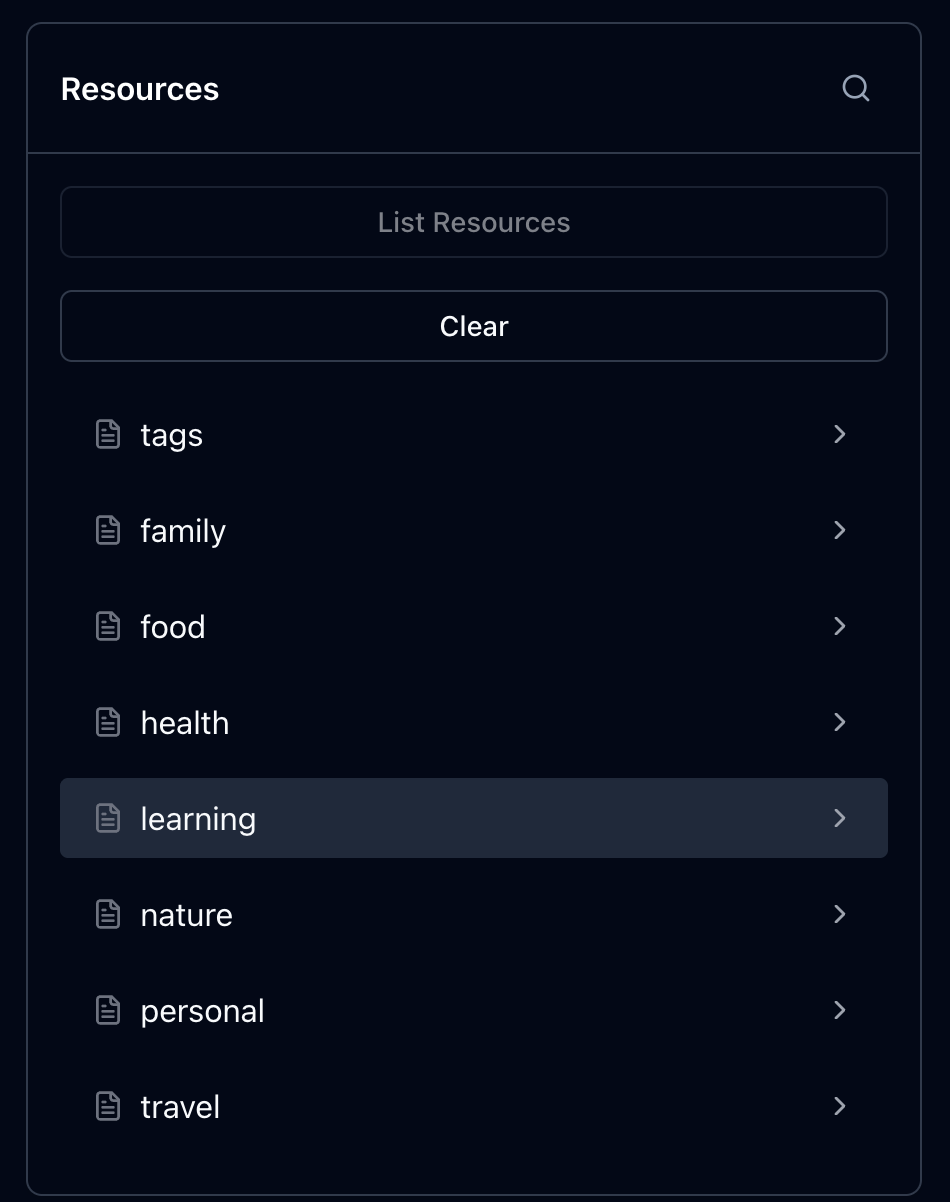
이제 리스트가 잘 나온다.
리소스 템플릿 ID 자동완성

리소스에서 ID로 검색을 한다고 가정하자. ID 몇 번이 있는지 모르니 자동완성 기능이 있다면 더 편리할 것이다. 기능을 추가해보자.
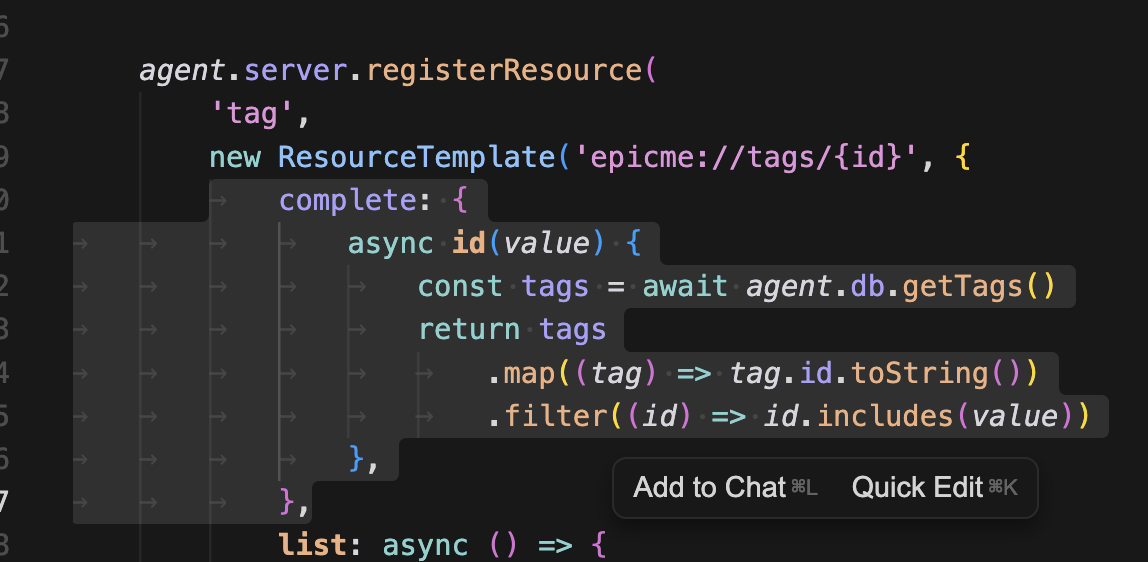
정말 간단하다. 아까 만들었던 ResourceTemplate에 complete 라는 키를 주고 filter만 해주면 된다.
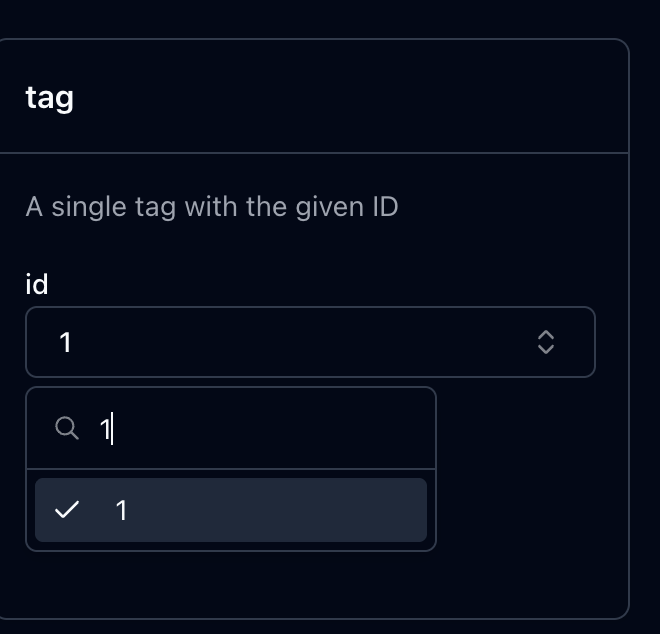
자동완성까지 했다.
