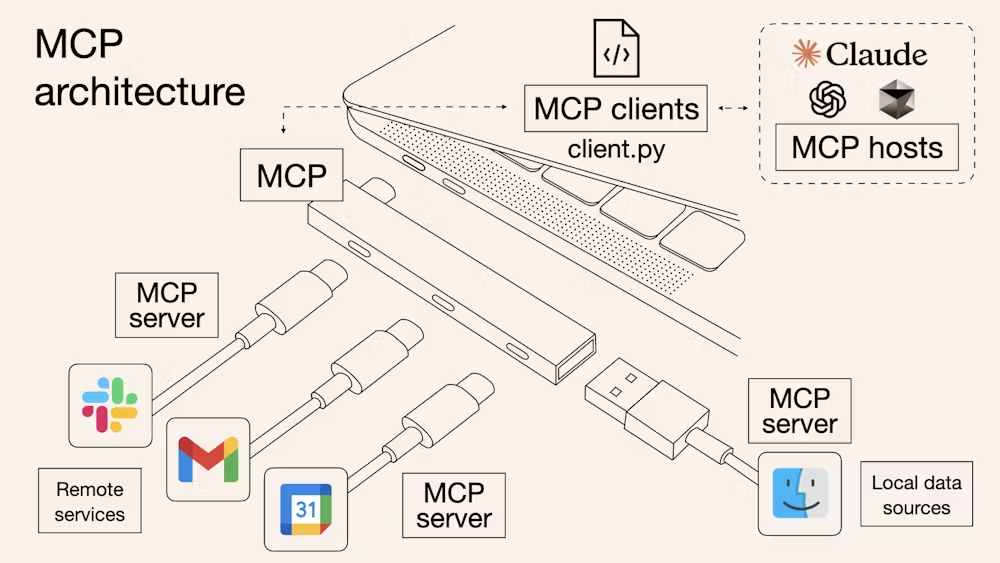
Annotations
Tool Annotations은 도구 호출 전에 LLM과 클라이언트가 이 도구가 어떤 성격인지 미리 알 수 있게 한다.
LLM과 클라이언트가 도구를 여러 번 호출해도 괜찮은지, 호출 시 destructive인지, 외부 세계와 통신하는지 등등 도구를 호출했을 때 무슨 일이 일어나는지 클라이언트가 알 수 있으면, human-in-the-loop을 판단하는데도 도움이 된다.
그럼 서버의 tools를 둘러보면서 각 tool에 맞는 적절한 annotations를 추가해보자.
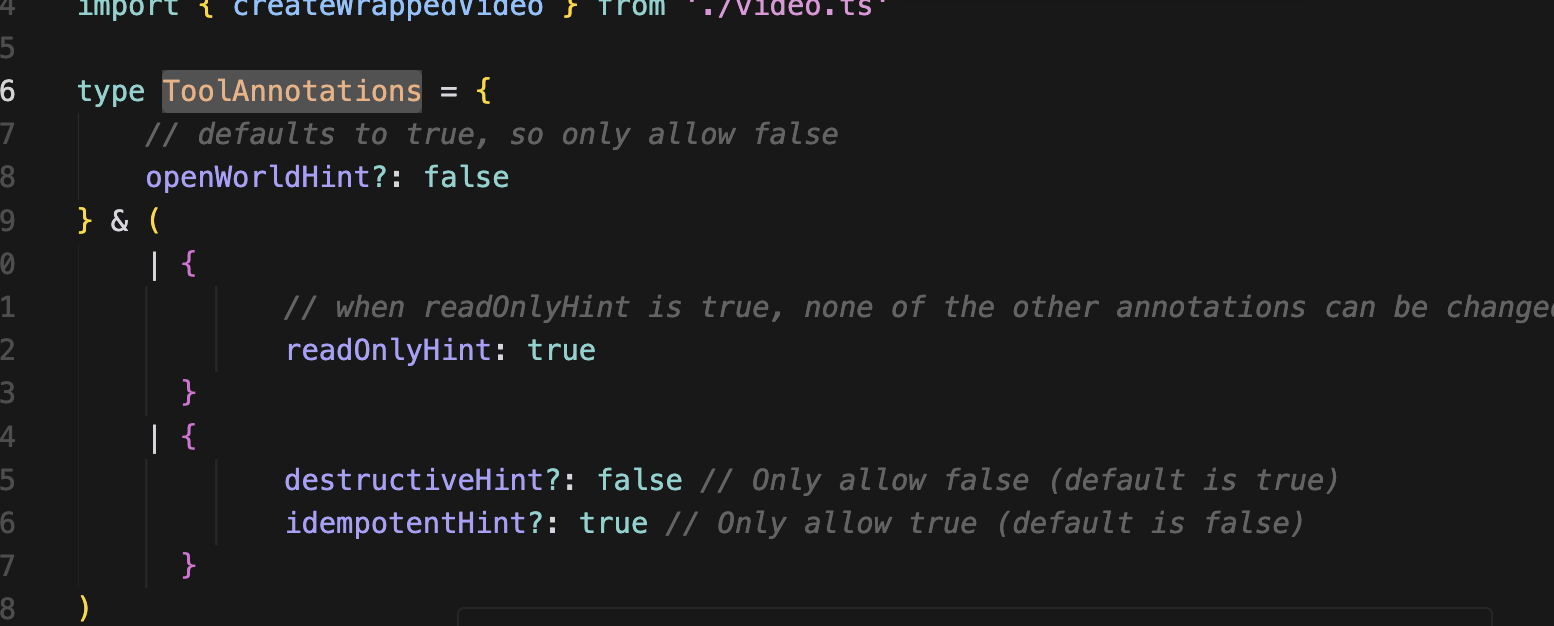
먼저 타입을 정하고 initializeTools에서 어노테이션을 정해주면 된다.
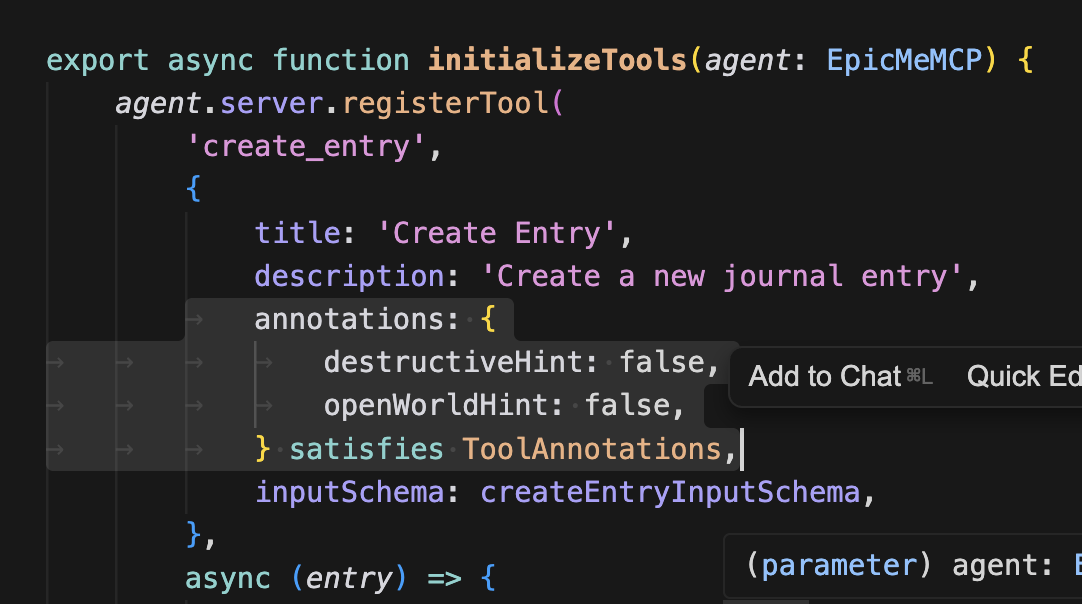
이제 각 툴의 성격을 고려해서 어노테이션을 정할 것이다. create entry의 경우 무언가 외부와 상호작용 없이 사용자가 작성한 텍스트로만 생성된다.
그래서 openWorldHint는 false고
무언가를 생성하니까 destructiveHint도 false다.
idempotent의 경우, 호출을 반복해도 동일한 결과인가인데 create entry는 DB에 새 엔트리를 만들고 있기 때문에 idempotent도 false이다.
이렇게 각 툴에 맞게 어노테이션을 붙여주면 된다.
Structured Output
tool의 기능 중 structured output이 라는 것이 있다. structured output은 기본적으로 툴 결과를 출력하는 형식을 지정해주는 것이다.
즉, 클라이언트나 심지어 LLM도 툴이 호출됐을 때 무엇이 돌아올지 미리 알 수 있다.
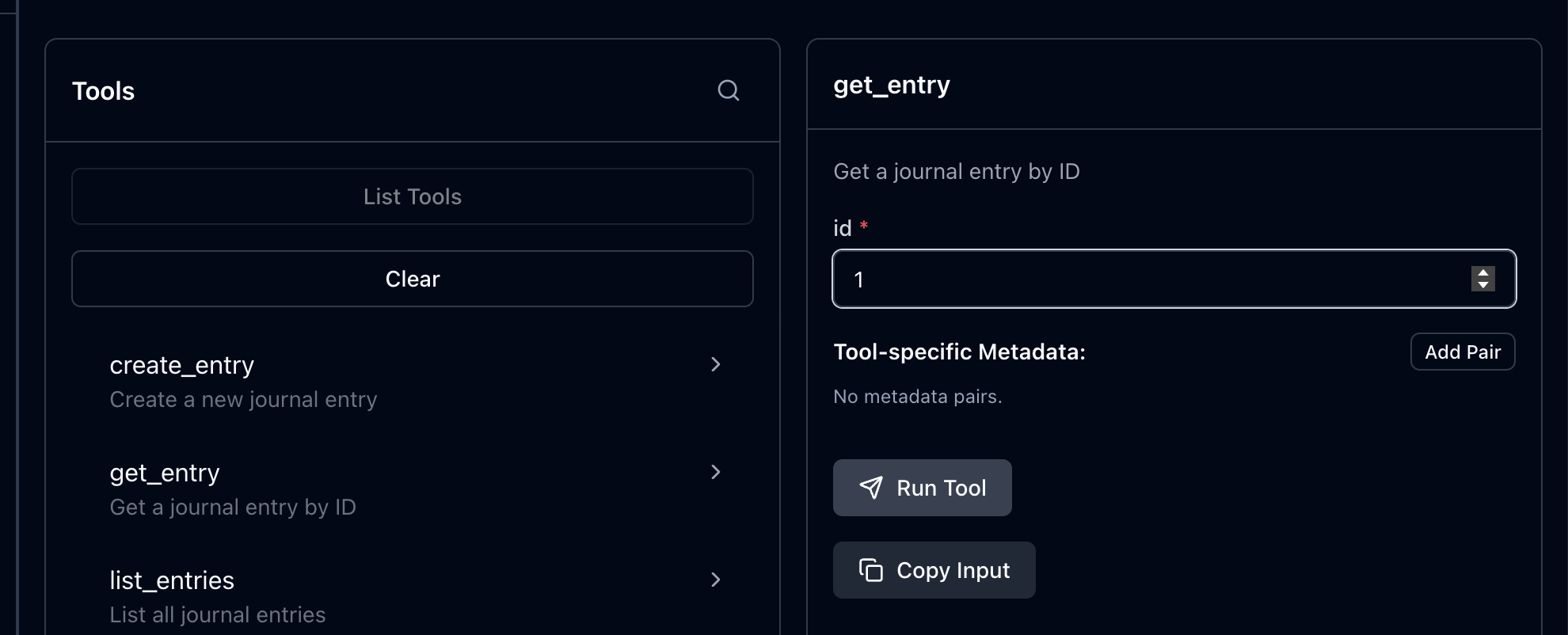
예를들어 ID가 1인 entry를 가져오는 get entry를 호출할 때, 실제로 run tool을 누르기 전까지는 무엇이 반환될지 알 방법이 없다.
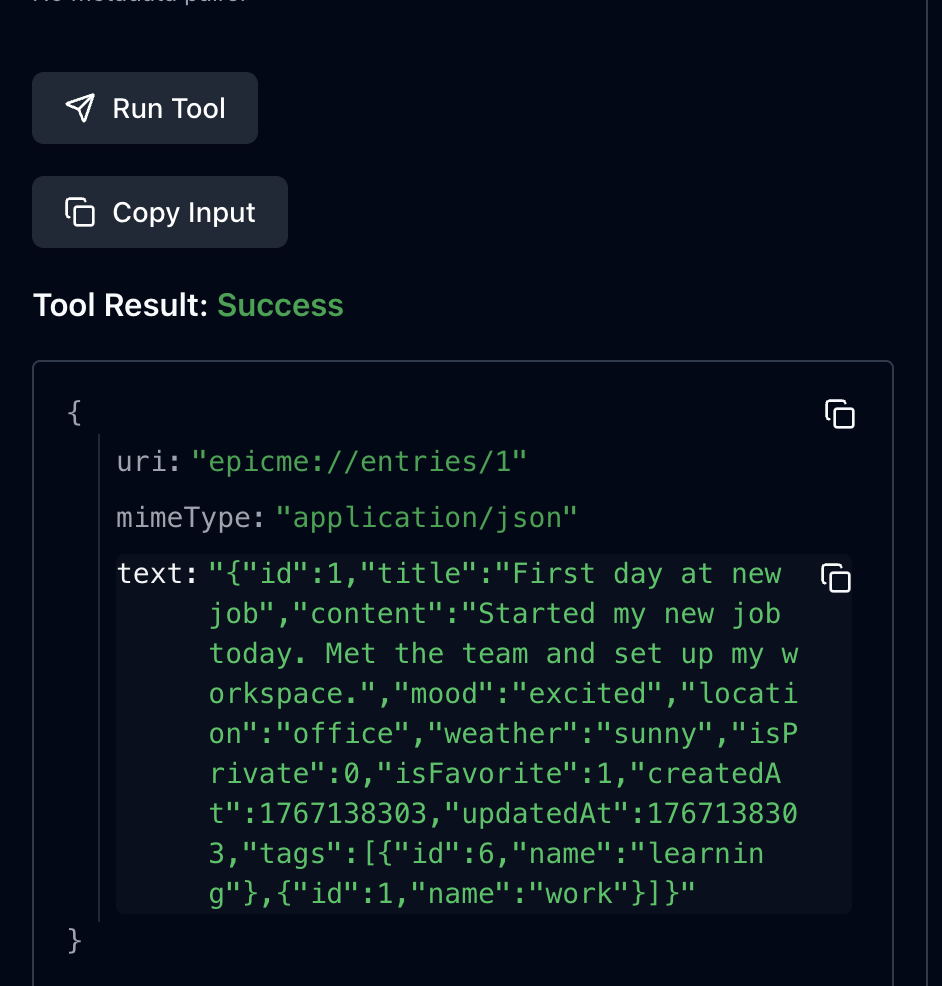
결과를 받고 나서야 JSON 객체에 어떤 프로퍼티가 있는지 알 수 있다. 즉, structured output과 output schema를 추가하여 툴을 호출하기 전부터 클라이언트나 LLM이 output schema를 미리 인지하는 것!
그럼 추가해보자.
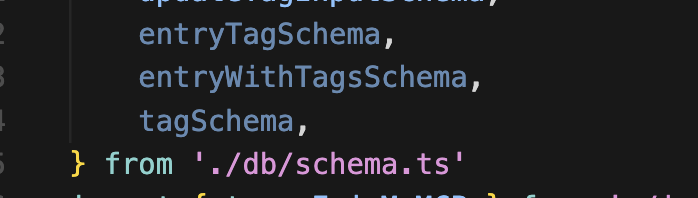
먼저 db에서 정의한 스키마를 가져온다.
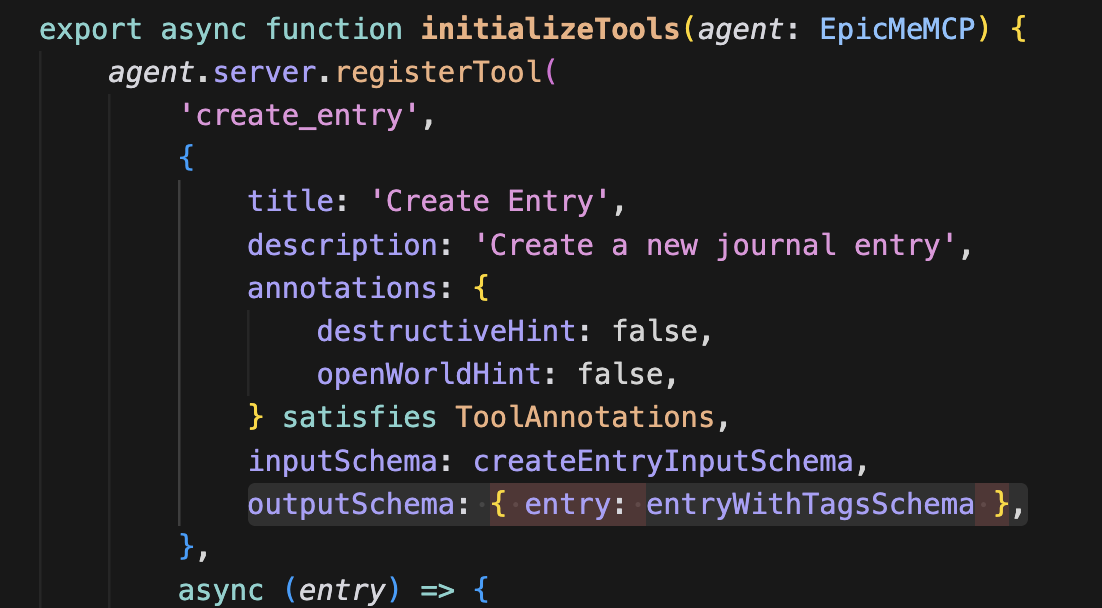
create_entry의 아웃풋 스키마에 추가하고
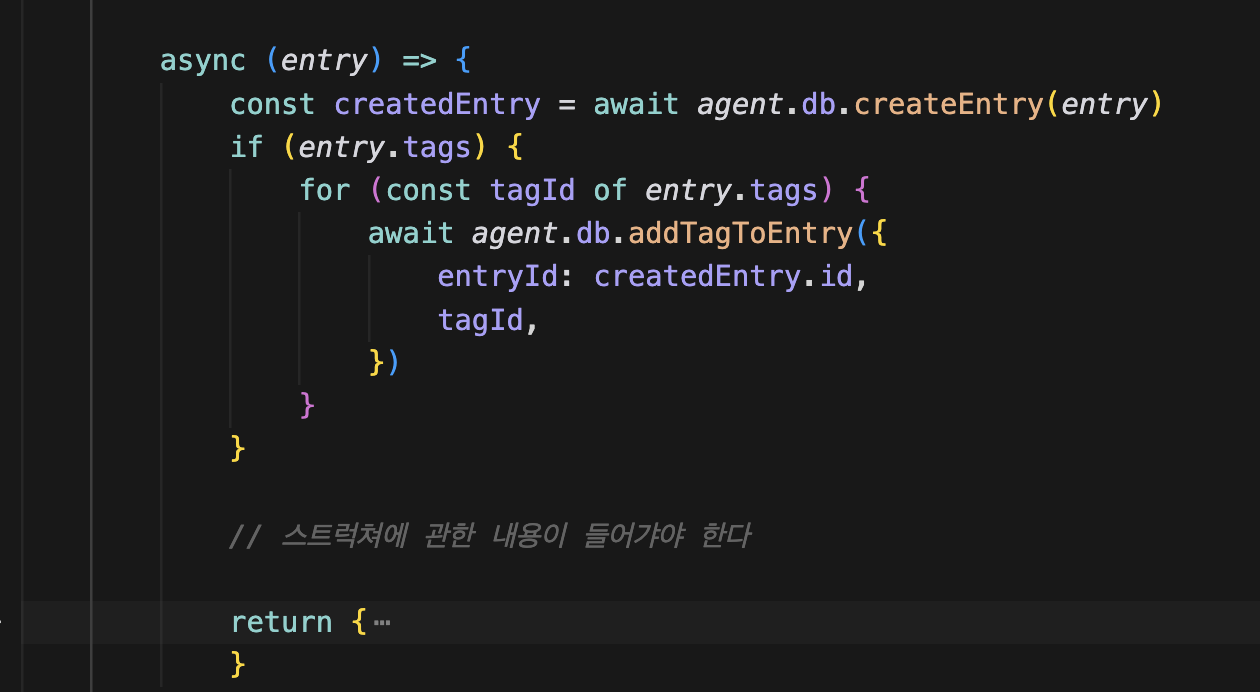
콜백에 스트럭쳐 관련 코드를 추가한다.
위 블럭에서 추가한 createEntry의 id를 가져와서 getEntry를 한다.
DB에서 가져온 값으로 structuredContent를 정의하고
structuredContent를 return에 넣는다. 이렇게 되면 정형화된 데이터 structuredContent와
content 배열의 비정형화된 데이터 둘 다 갖게 된다. 이렇게 리턴값에 정형화된 데이터와 비정형 데이터 둘 다 넣는 이유는 하위 호환성 때문이다.
structuredContent는 LLM 전용이다. 최신의 MCP는 정형화된 데이터를 읽을 수 있지만 버전이 낮다면 읽을 수 없다. 그래서 비정형화된 (약간 로우 데이터...?)도 함께 담는다.
그리고 MCP inspector가 이걸 검증하는데
output이 schema와 일치하는지, structuredContent와 텍스트 content가 호환되게 들어갔는지 체크한다.
이렇게 되면 기존의 레거시 데이터(비정형 데이터)가 타입이 완벽한 정형 데이터에도 호환될 수 있다.
이제 익스펙터로 확인해보면
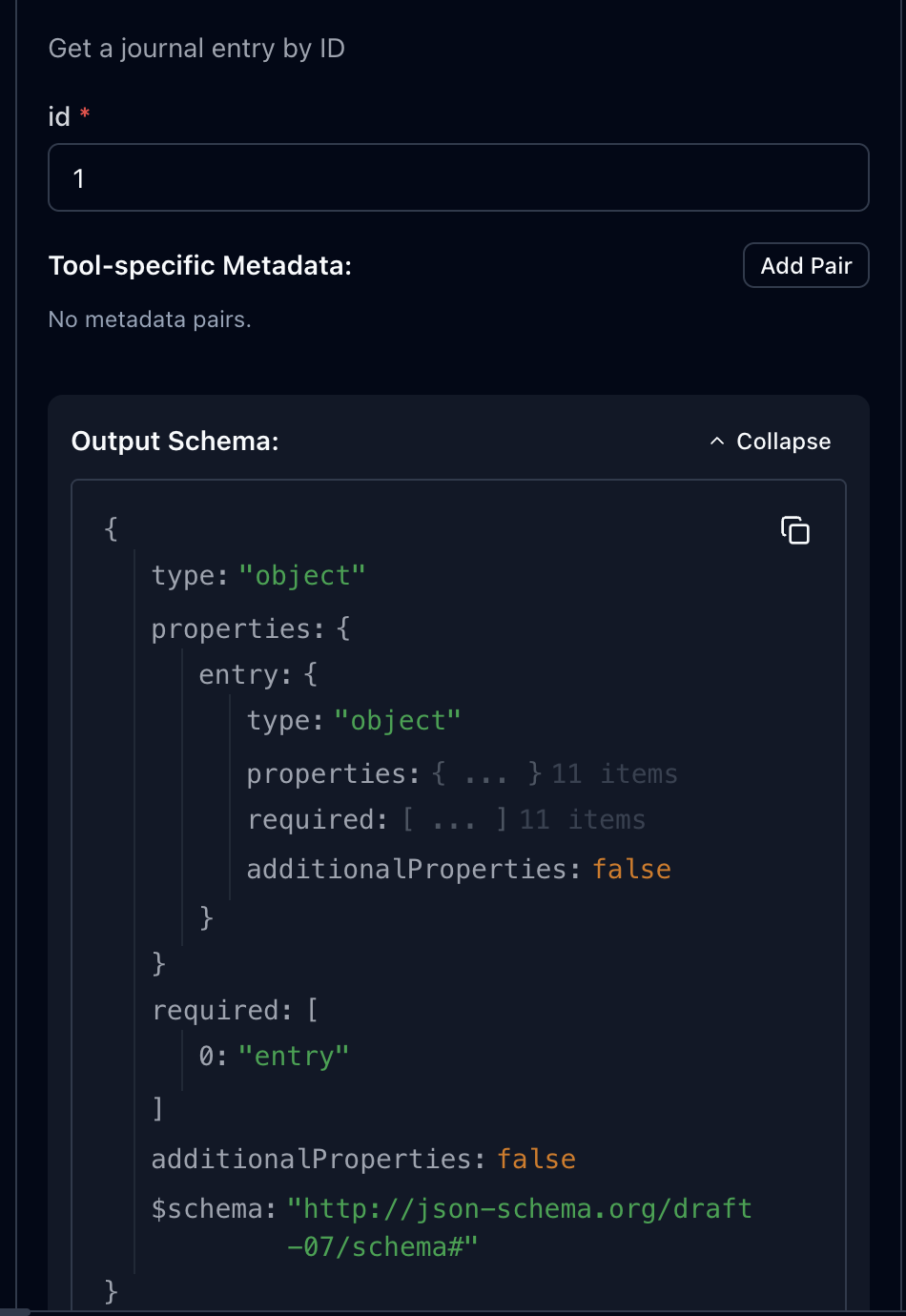
이렇게 아웃풋 스키마가 보이고(마치 스웨거처럼) 툴을 실행하면
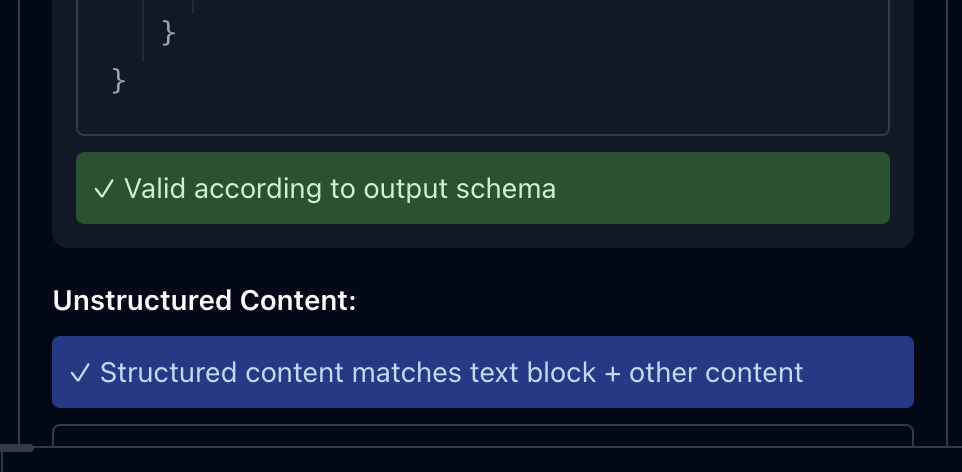
이렇게 스키마를 검증해준다.
elicitation
elicitation란 툴 호출 중에 사용자에게 추가 확인이 필요하거나, 추가 입력을 받아야 하거나, 확실히 동의를 받아야 하는 상황에서 쓰인다.
서버 쪽에서 클라이언트에 요청을 보내서, 보통은 사용자가 답하게 만드는 흐름이다.
예를들어, 삭제와 같은 툴을 사용한다 했을 때 사용자가 실수로 삭제하는 것을 방지하기 위해 사용자에게 '확인'을 먼저 하고 삭제를 하는 플로우다.
코드로 살펴보자
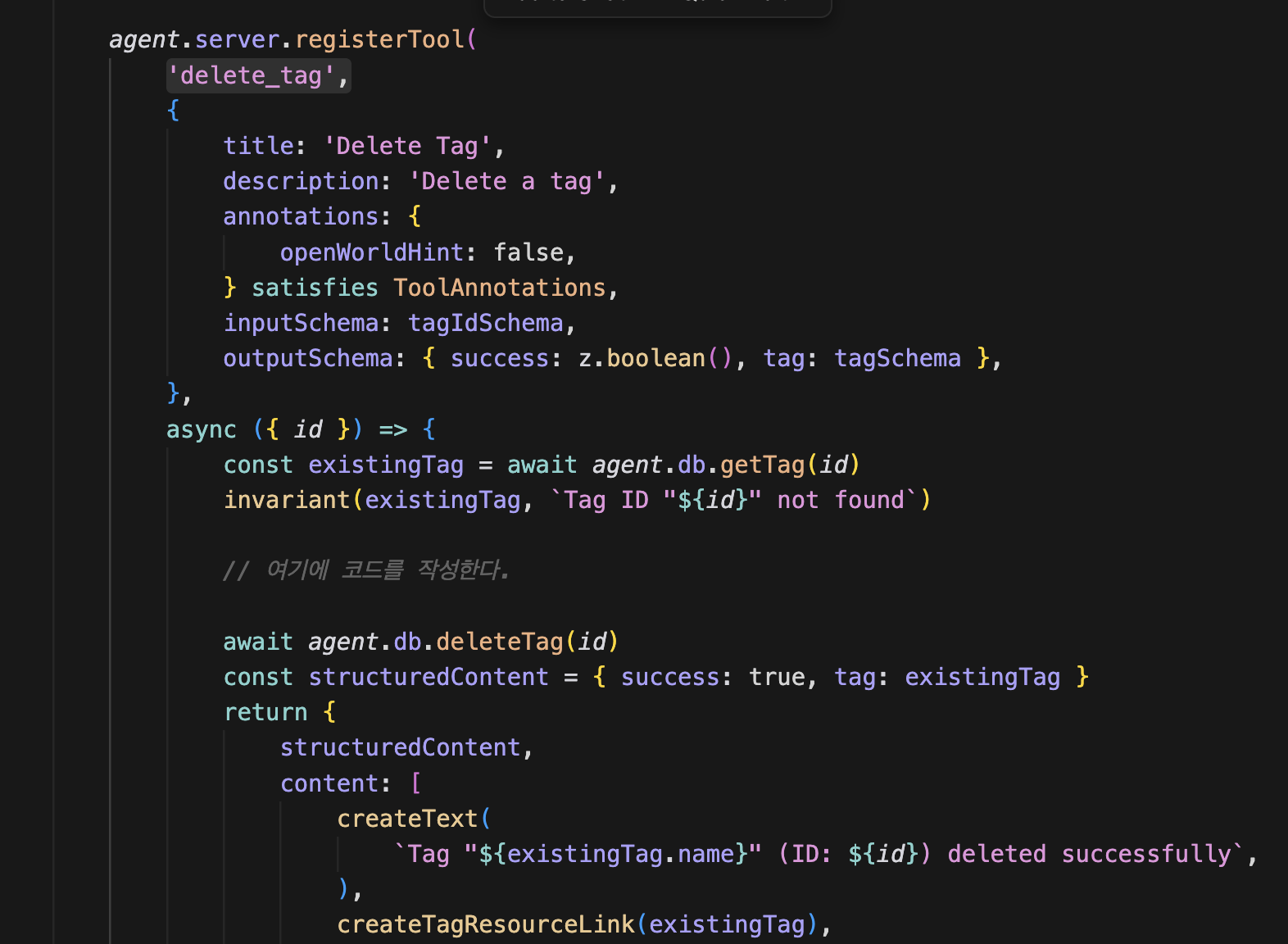
delete tag에 elicitation를 넣는다고 해보자. 콜백 부분에 코드를 추가하면 된다.
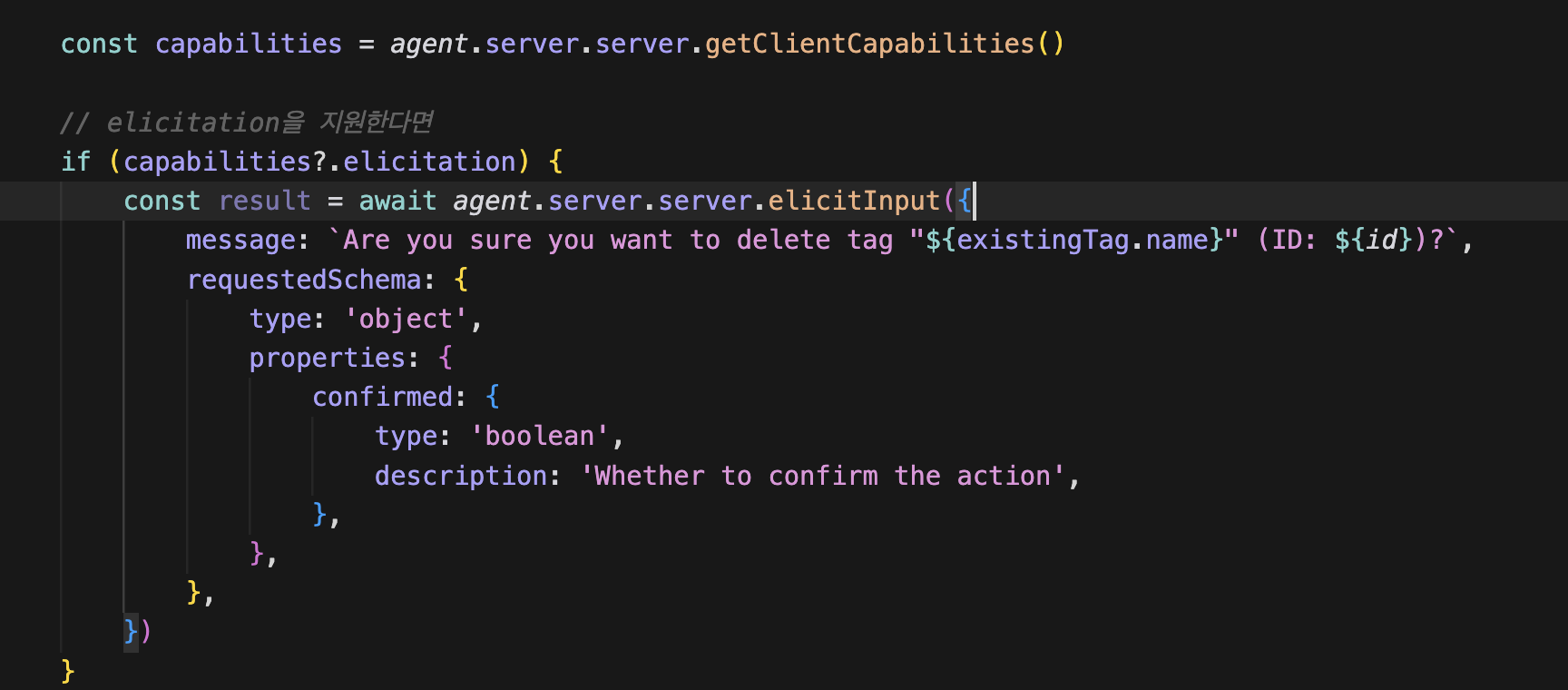
사용자에게 보여줄 확인 메시지를 추가하고
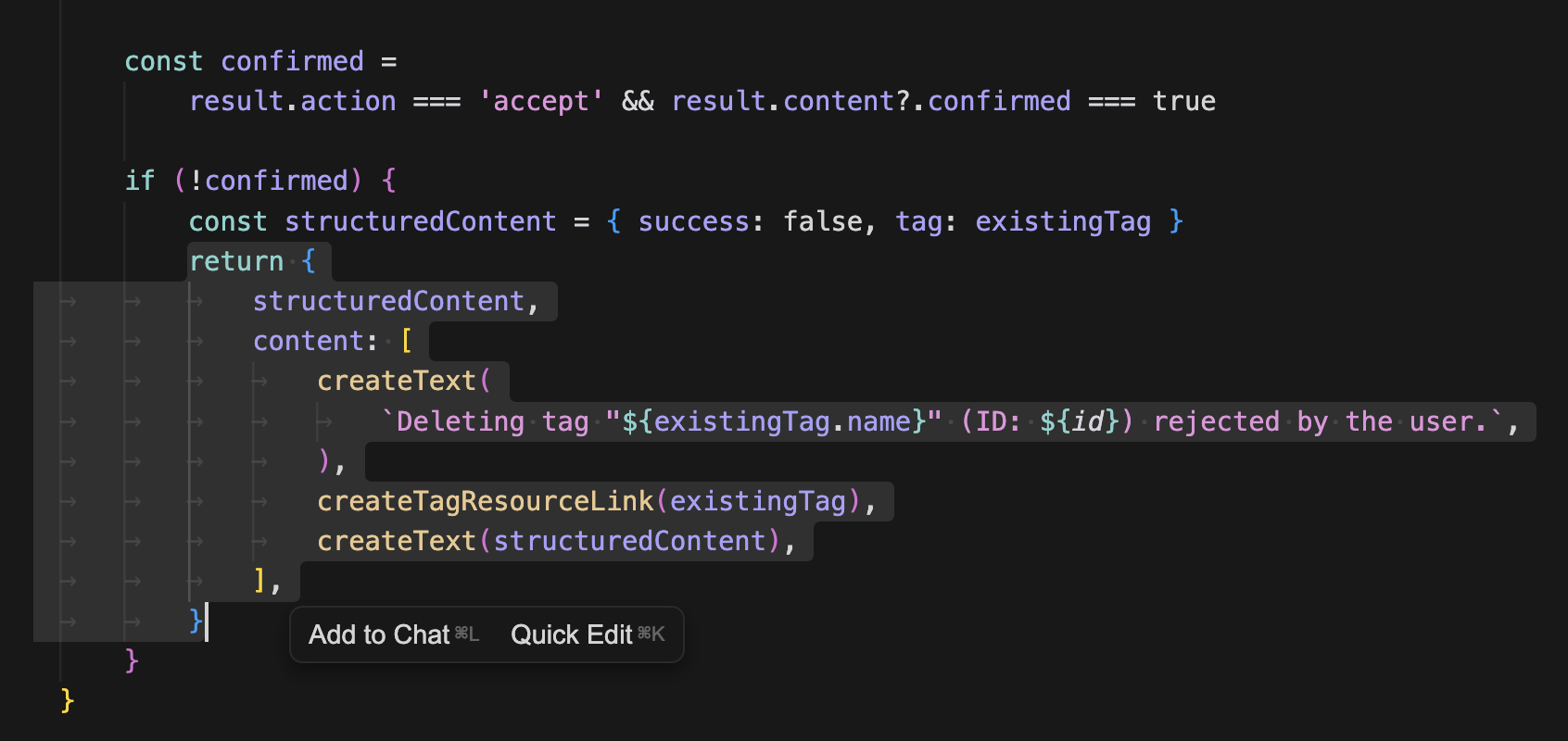
거부했다면 원래대로 데이터를 반환한다. 이제 인스펙터로 확인해보자
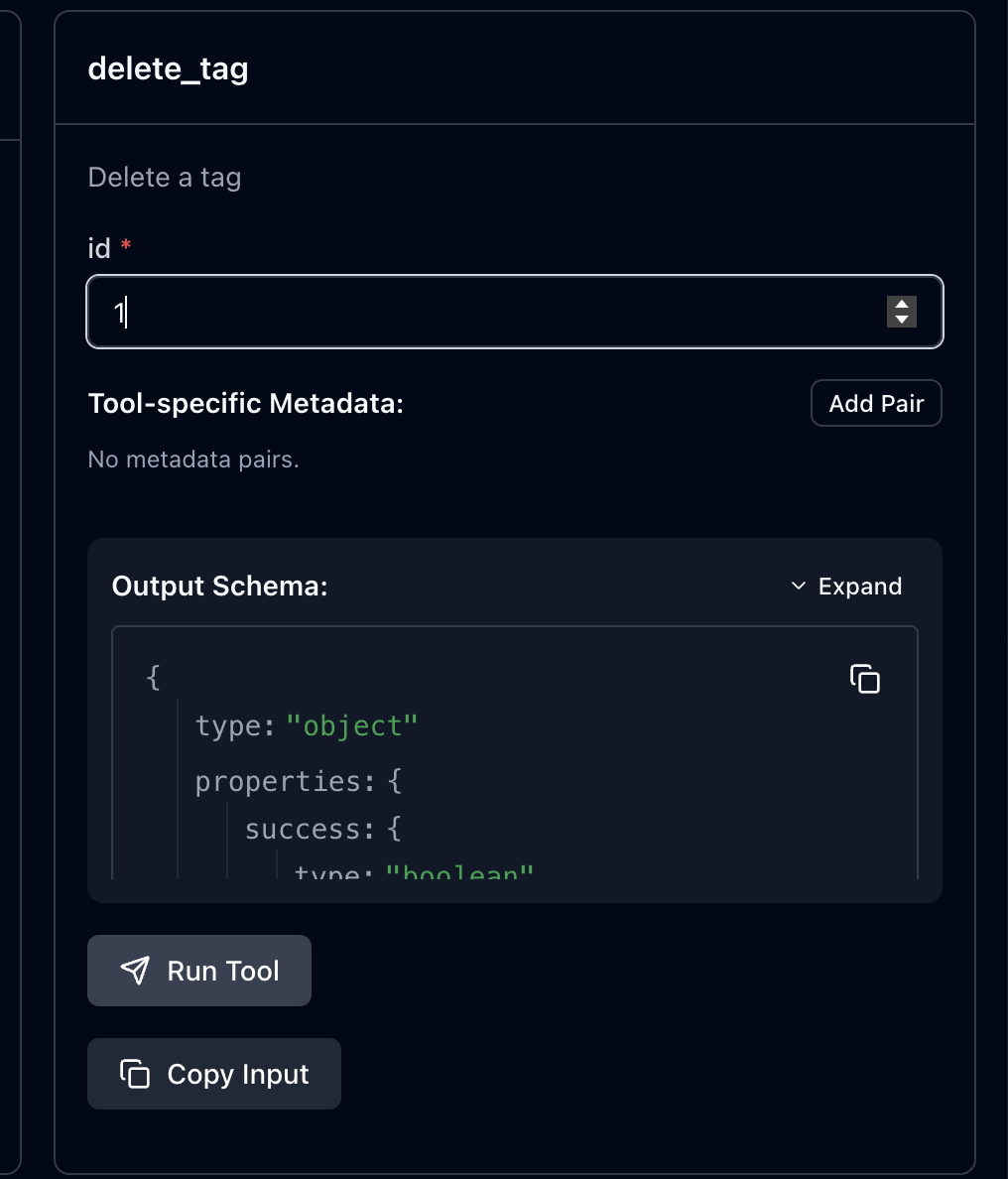
delete tag 툴을 선택하고 id를 입력하면
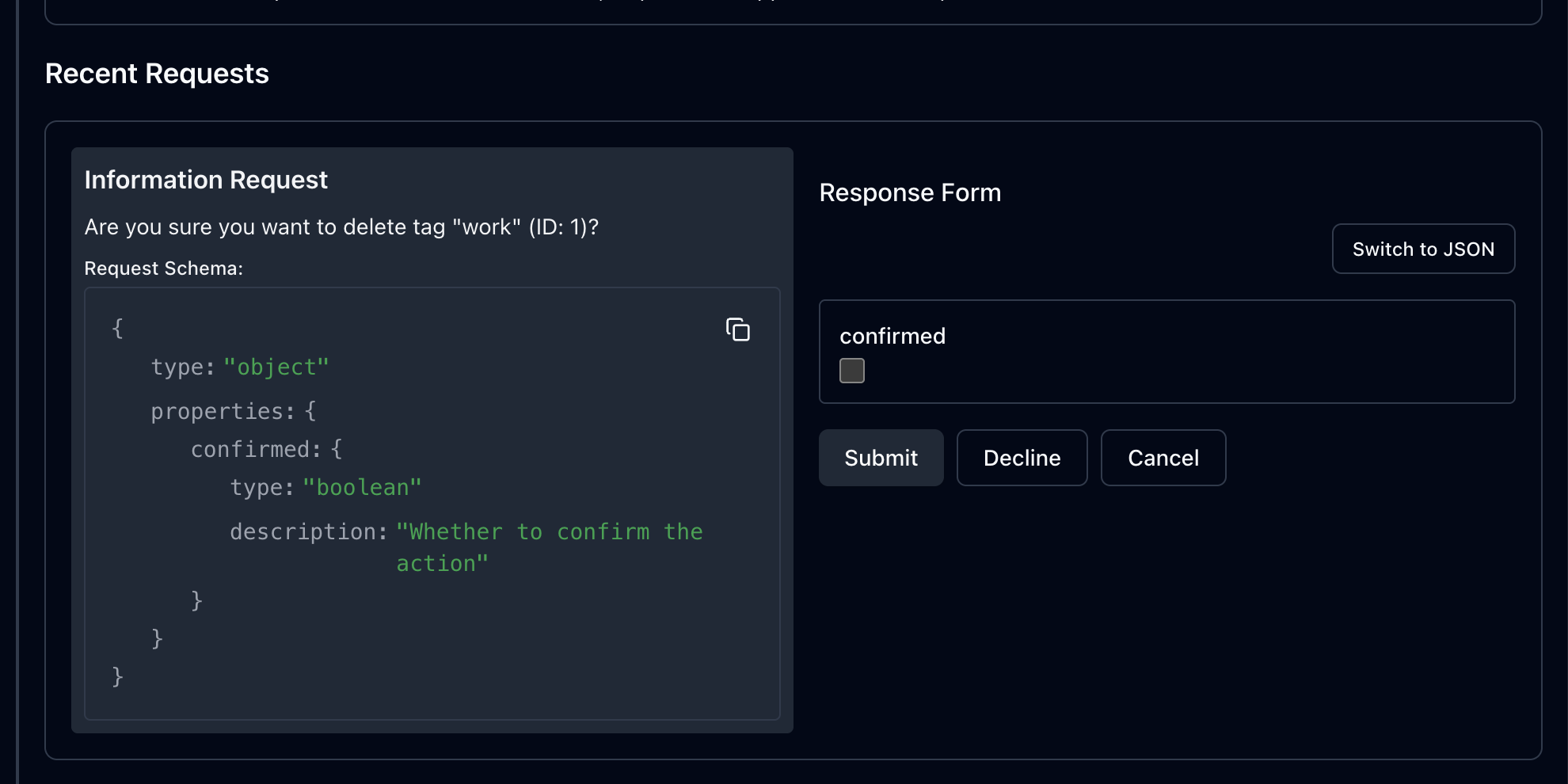
사용자의 확인을 받는 input이 나온다!
Sampling
샘플링이란 모델에게 프롬프트와 컨텍스트를 주고 응답을 받아오는 과정이다.
자세하게 얘기하자면 서버가 모델을 직접 호출하는 게 아니라, 클라이언트가 보유한 LLM을 빌려서 생성한다. 이전에 Elicitation이 중요한 행위 전에 사용자에게 '확인'을 받아내는 것이었다면 Sampling은 사용자에게 LLM 모델을 빌려 써도 되는지 '승인'을 받아 내는 것이다.
왜 Sampling이 필요할까?
가령, tag를 붙이지 않고 entry를 하나 생성한다고 가정해보자. LLM이 tag를 자동으로 부여하려면 entry의 내용을 이해해야 한다. 서버는 별도의 LLM을 사용하므로써 별도의 추가 비용을 내고 싶지 않으므로 이미 LLM을 사용중인 사용자에게 잠시 빌리는 것!
사실, 프롬프트가 있긴하지만 샘플링의 장점은 사용자가 요청 전에 선제적으로 처리한다는 데 있다.
그럼 코드로 알아보자.
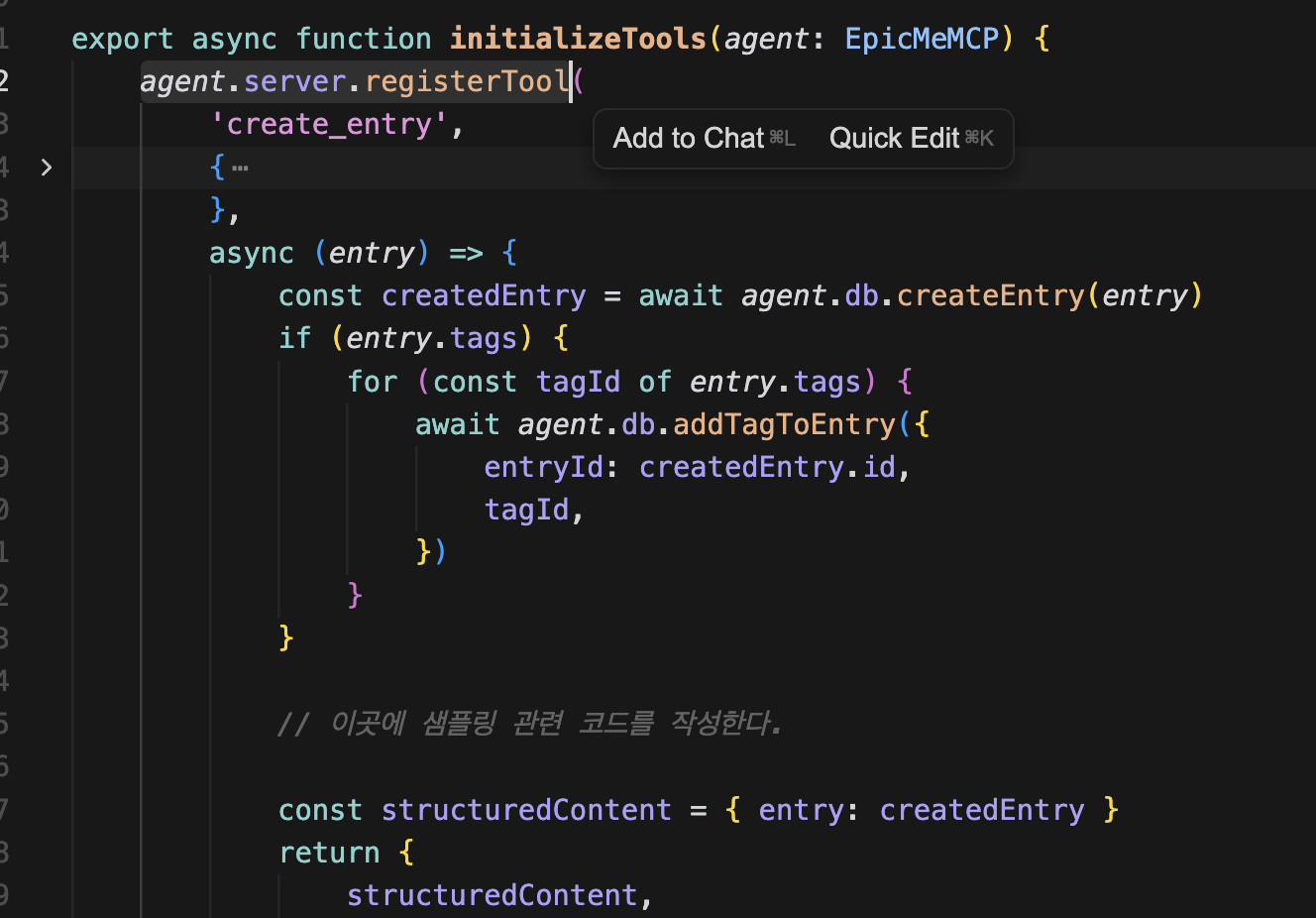
일단 Tool 관련 코드로 이동한다. create entry를 엔트리를 생성할 때 샘플링 요청이 필요하므로 콜백 내부에 작성할 것이다.
우리가 해야할 것은 리턴하기 직전에 샘플링 요청을 수행하되, 리턴이 그걸 기다리게 만들면 안된다. 샘플링을 하긴 하되, 응답은 막지 않게 한다.
그래서 엔트리를 만든 다음에, sampling 파일에서 suggestTagSampling을 가져와서 호출할 것이다.
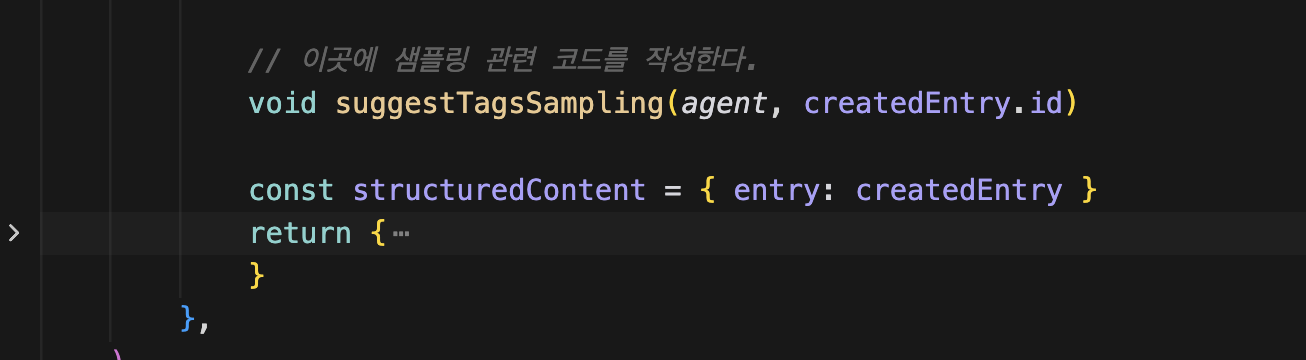
방금 생성한 entry와 에이전트를 인자로 넘기는데, void란 키워드를 사용했다.
위 함수는 비동기이지만 await을 하진 않을 것이다. 무슨 말이냐하면 만약 await을 하면 사용자는 샘플링 승인을 하기까지 생성 성공에 대한 응답을 못 받을 수 있다.
사용자가 샘플링 요청을 못 볼 수도 있고, 무시할 수도 있기 때문에 샘플링 승인에 await을 하고 싶진 않다.
그래서 대신 void를 붙인다.
void는 JS에서 함수가 무언가를 반환하지만 반환값엔 관심없을 때 사용하는 키워드다. void를 붙이는 건 필수는 아니지만, void를 붙임으로써 비동기 함수에 await을 안 한게 의도적이라는 걸 드러낼 수 있다.
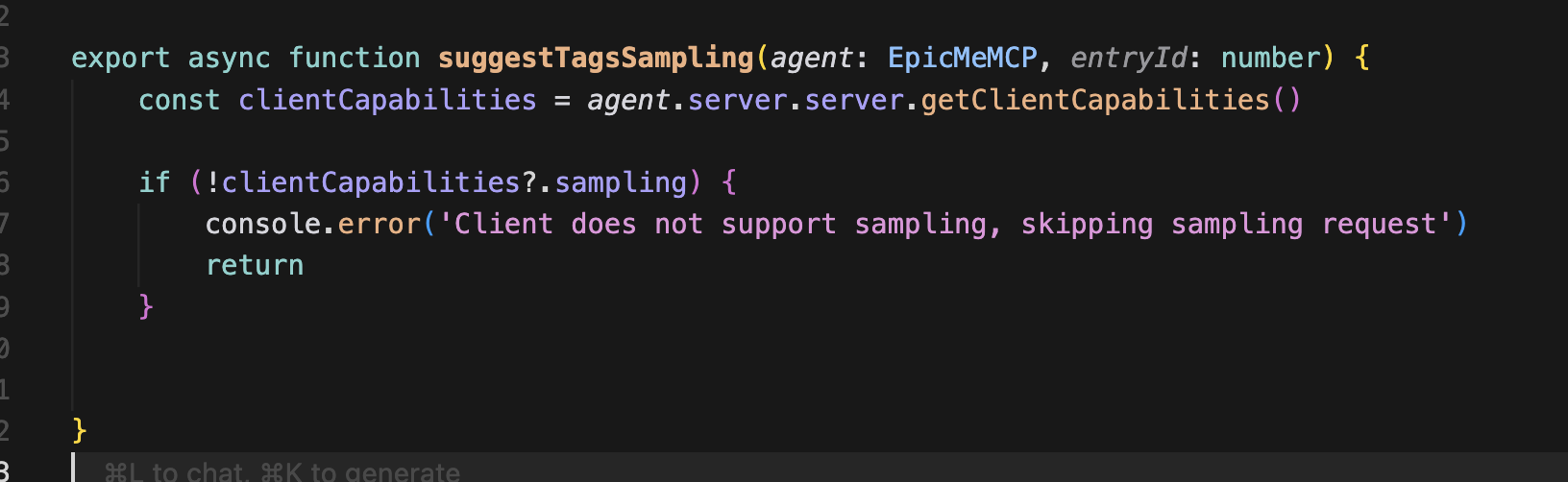
suggestTagSampling 내부는 elicitation과 동일하게 클라이언트의 capabilities 여부를 확인한다.
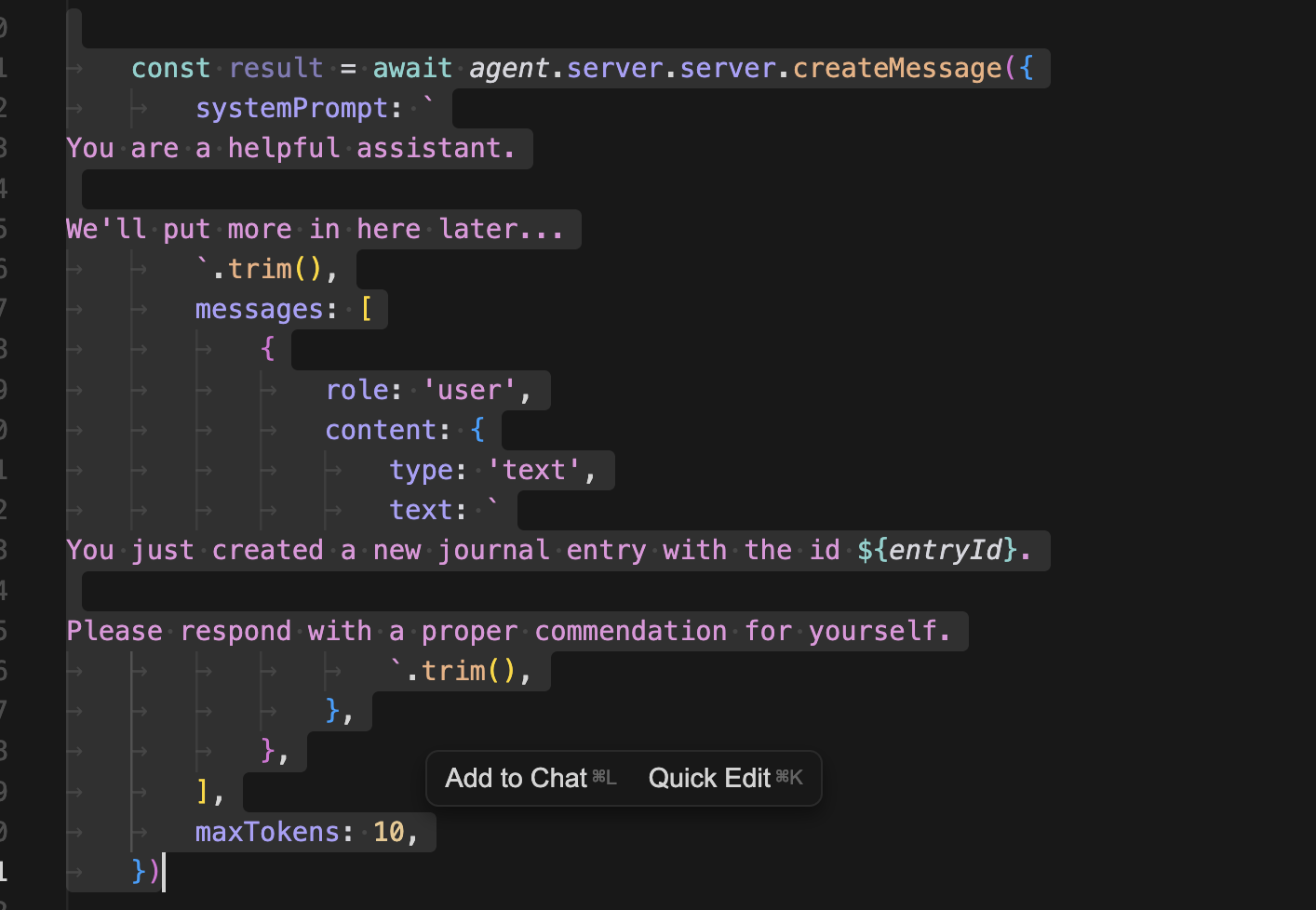
만약 지원한다면 서버에서 클라이언트로 메시지를 보내야 한다. 실제 서버 인스턴스인 agent.server.server에 접근하여 createMessage를 만든다.
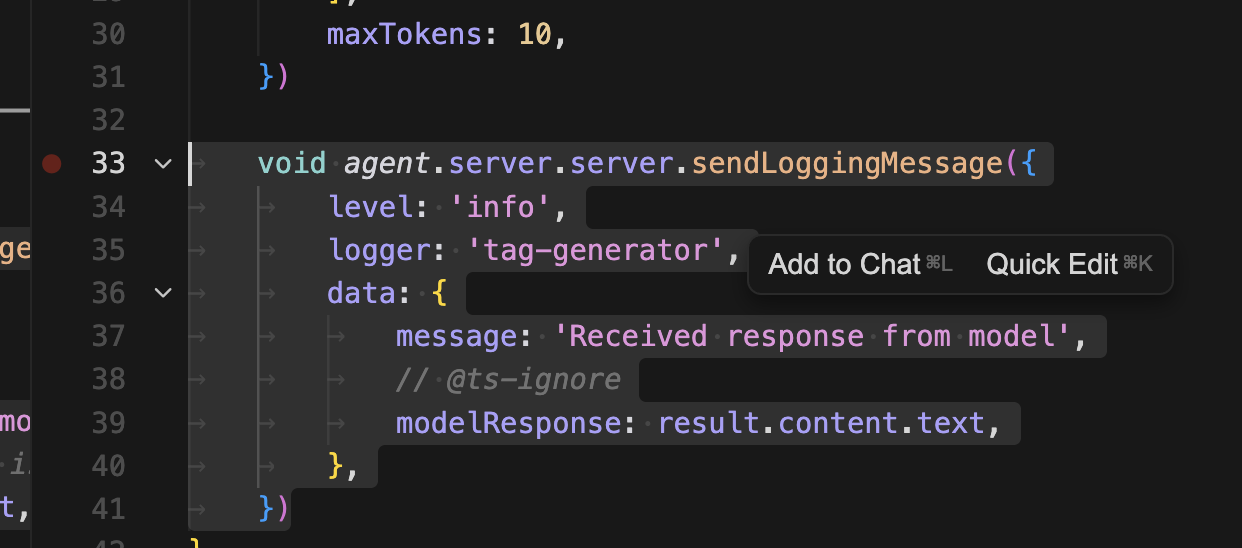
이제 result를 await으로 받고 결과를 받으면 로깅메시지도 같이 보낸다. 이제 인스펙터에서 crate entry 툴을 생성해보자
런을 하게 되면
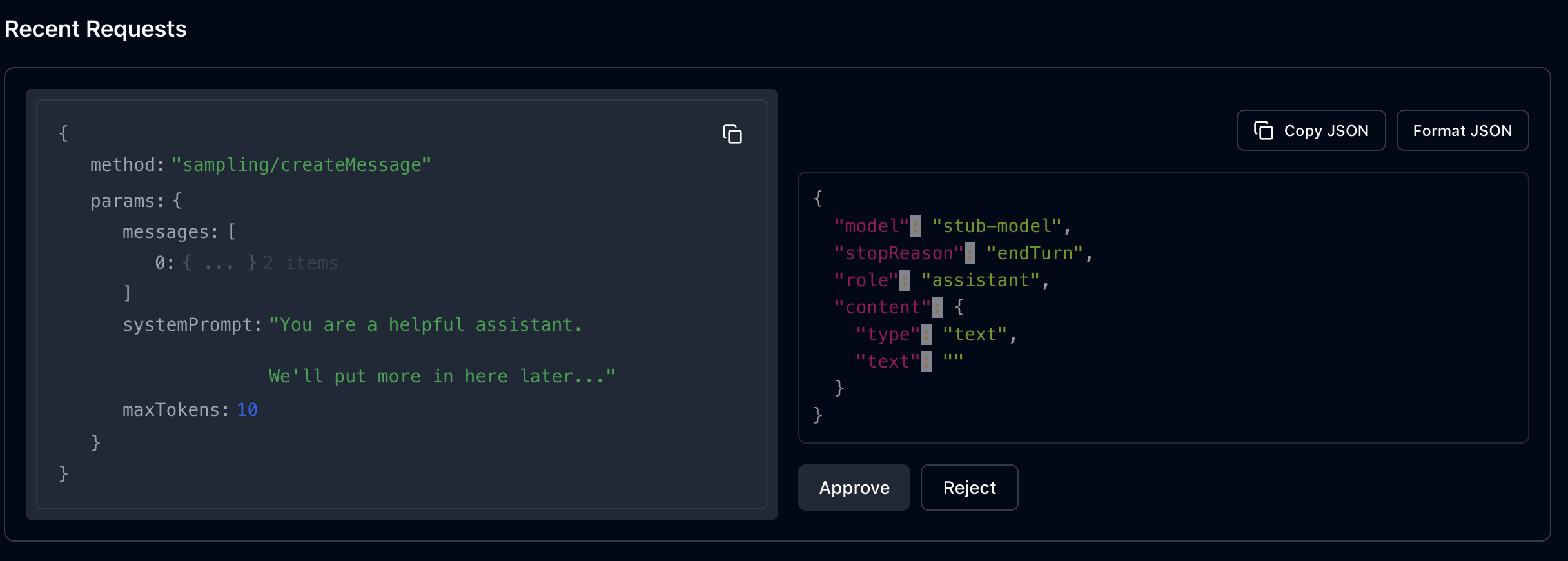
샘플링 요청이 생성되고 유저는 승인할지 거절할지를 선택할 수 있다.
Long Running Task
작업이 오래걸릴 때, 사용자에게 지연된 상황을 알려줘야 만족도가 올라간다. 오래 걸리는 태스크에 대해 MCP가 처리하는 방식을 알아보자.
클라이언트가 어떤 요청을 보낼 때, 진행 상황을 업데이트를 받고 싶다면 요청에 progress token을 포함해서 보낸다. 그러면 서버는 그 progress token을 사용해서 작업이 진행되는 동안 클라이언트로 알림을 보낼 수 있다.
이렇게 하면 클라이언트는 그 정보를 호스트 애플리케이션으로 전달할 수 있고, 호스트 앱은 이를 활용해 상태바 같은 UI를 띄워서 사용자가 태스크가 지연 중임을 알 수 있다.
'취소'도 비슷한 프로세스다. 사용자가 어떤 작업을 시작했다가 취소를 하게 되면 클라이언트는 지금 진행 중인 요청에 대해 ID를 포함한 취소 요청을 서버로 보낼 수 있다.
취소 구현에서 JS에서도 쓰이는 AbortController과AbortSignal가 사용된다.
예제
그럼 비디오와 같이 긴 작업을 실행했을 때 진행율을 유저에게 알려주는 코드로 구현해보자.
비디오를 생성하는 createWrappedVideo라는 함수 내부 몇 가지 코드를 추가한다.
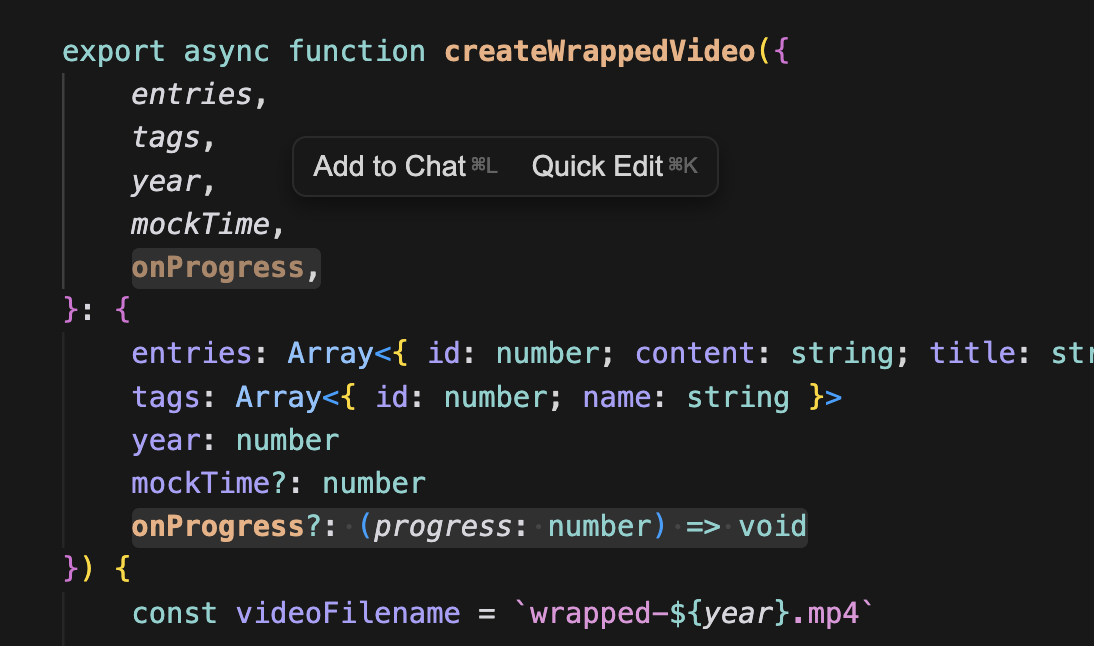
onProgress는 진행률을 알려주는 함수다. 콜백으로 넘기고 여기서 두 가지를 생각해야 한다.
- mock time
- 실제 ffmpeg
만약 실제 작업이 환경에 의존적일 때를 생각해보자. 영상 작업인데 ffmpeg가 설치 안 되어 있거나 OS의 차이 때문에 깨질 수도 있다.
그렇기 때문에 위 비디오 예제에서도 실제 ffmpeg를 실행하여 프로세스를 보여주는 것이 아니라 mock time을 활용하여 먼저 진행율을 보여준다.
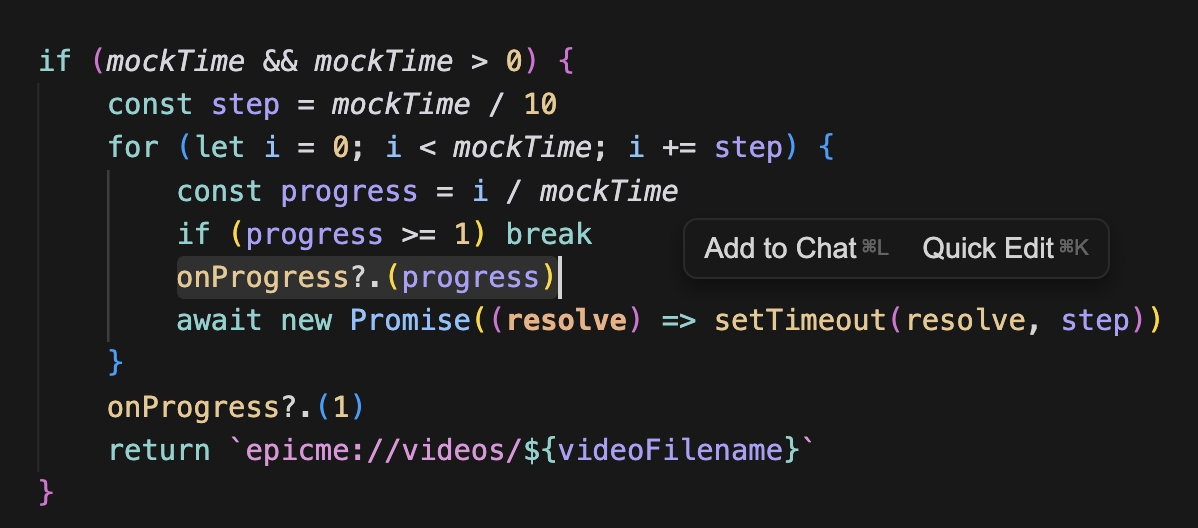
루프를 돌면서 onProgress를 호출하고 progress가 1이되면 멈춘다(=작업완료)
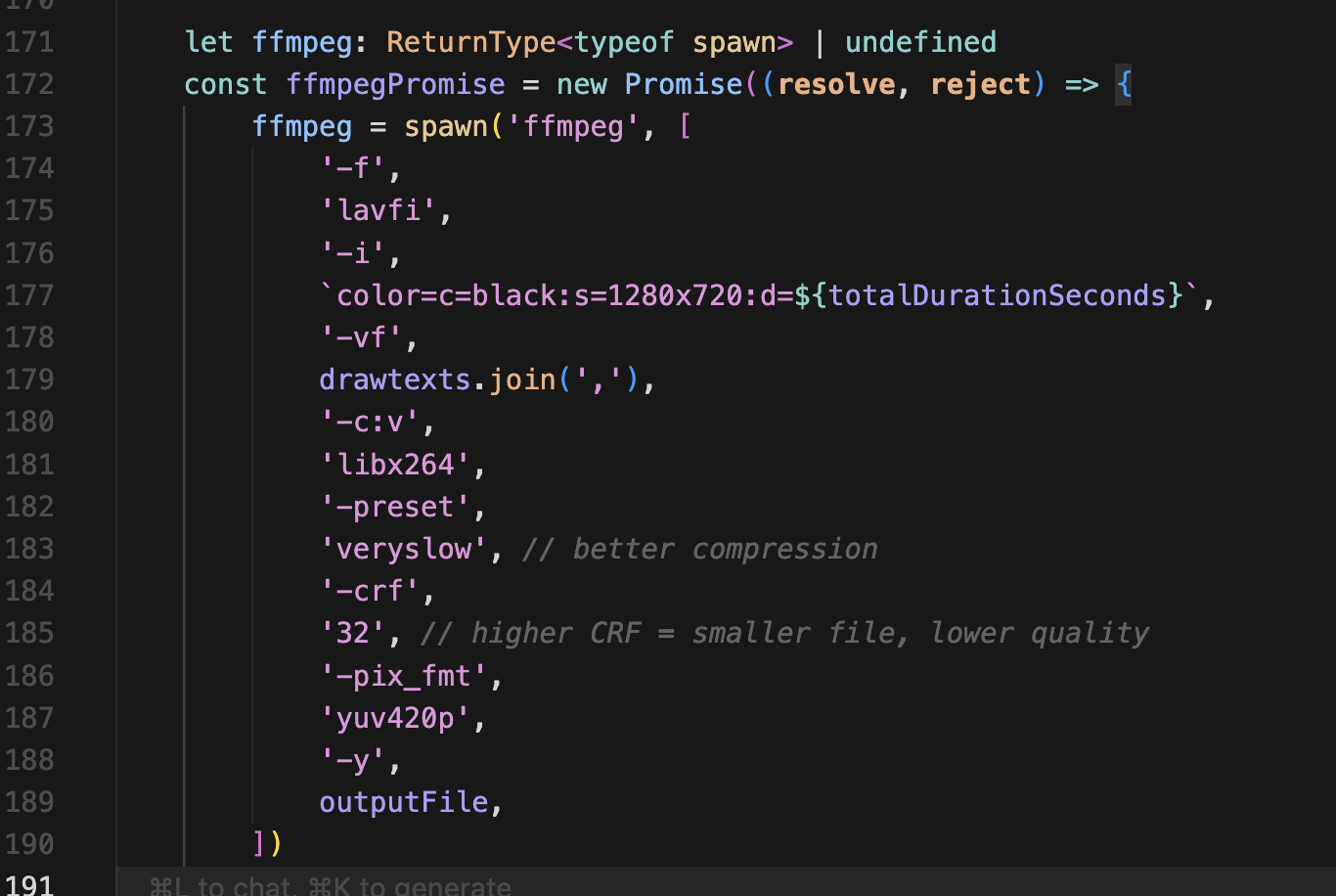
그리고 실제 ffmpeg 작업을 하는 코드에도 진행률을 추가해준다.
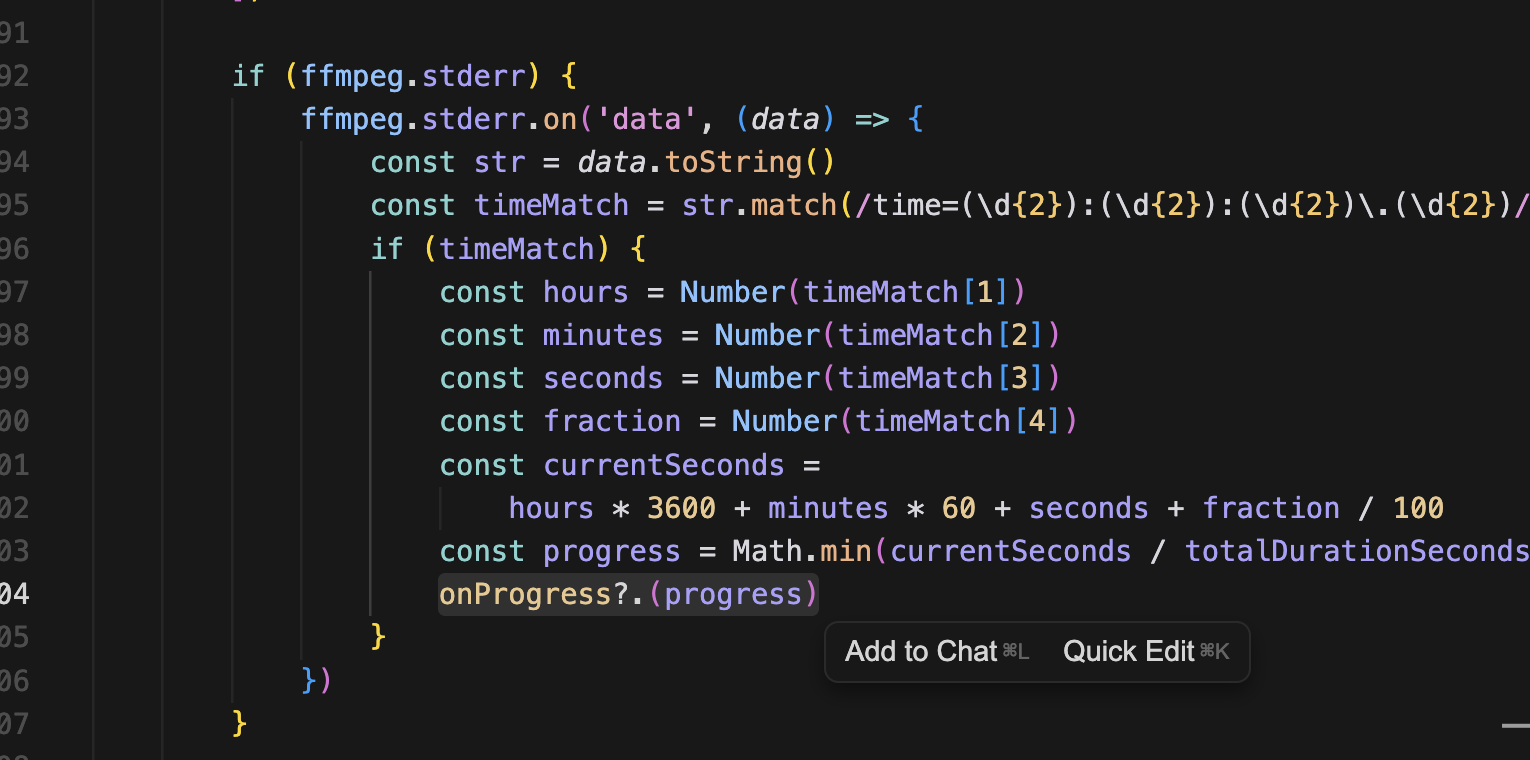
실제 작업의 진행도를 계산하여 onProgress로 넘긴다.
이제 tool의 create_wrapped_video으로 이동해서 콜백을 넘겨줄 것이다.
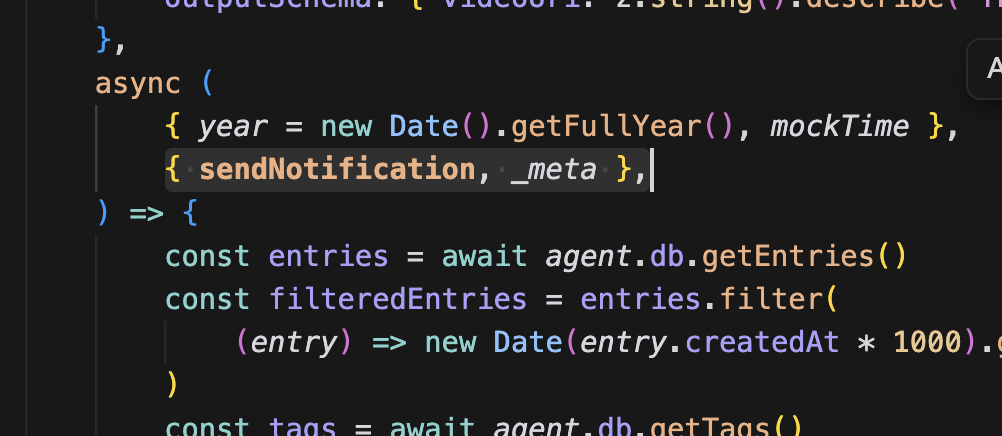
create_wrapped_video의 콜백에서 두 번째 인자에 sendNotification와 meta를 추가한다. sendNotification는 SDK에서 관리하는 함수다.
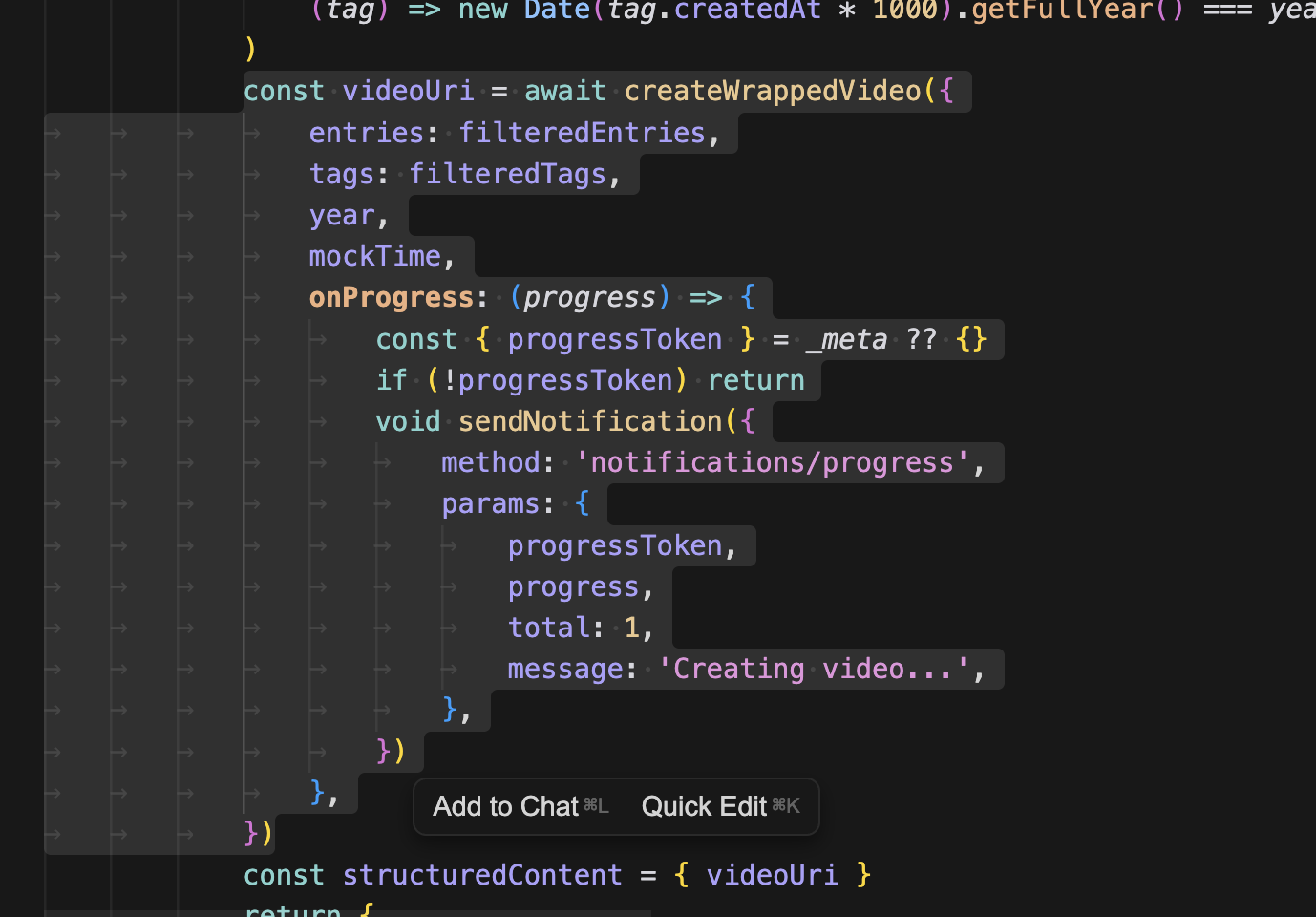
그리고 createWrappedVideo로 영상을 생성하면 되는데, onProgress 콜백으로 진행률을 받아온다. 이제 한번 테스트를 해보쟈
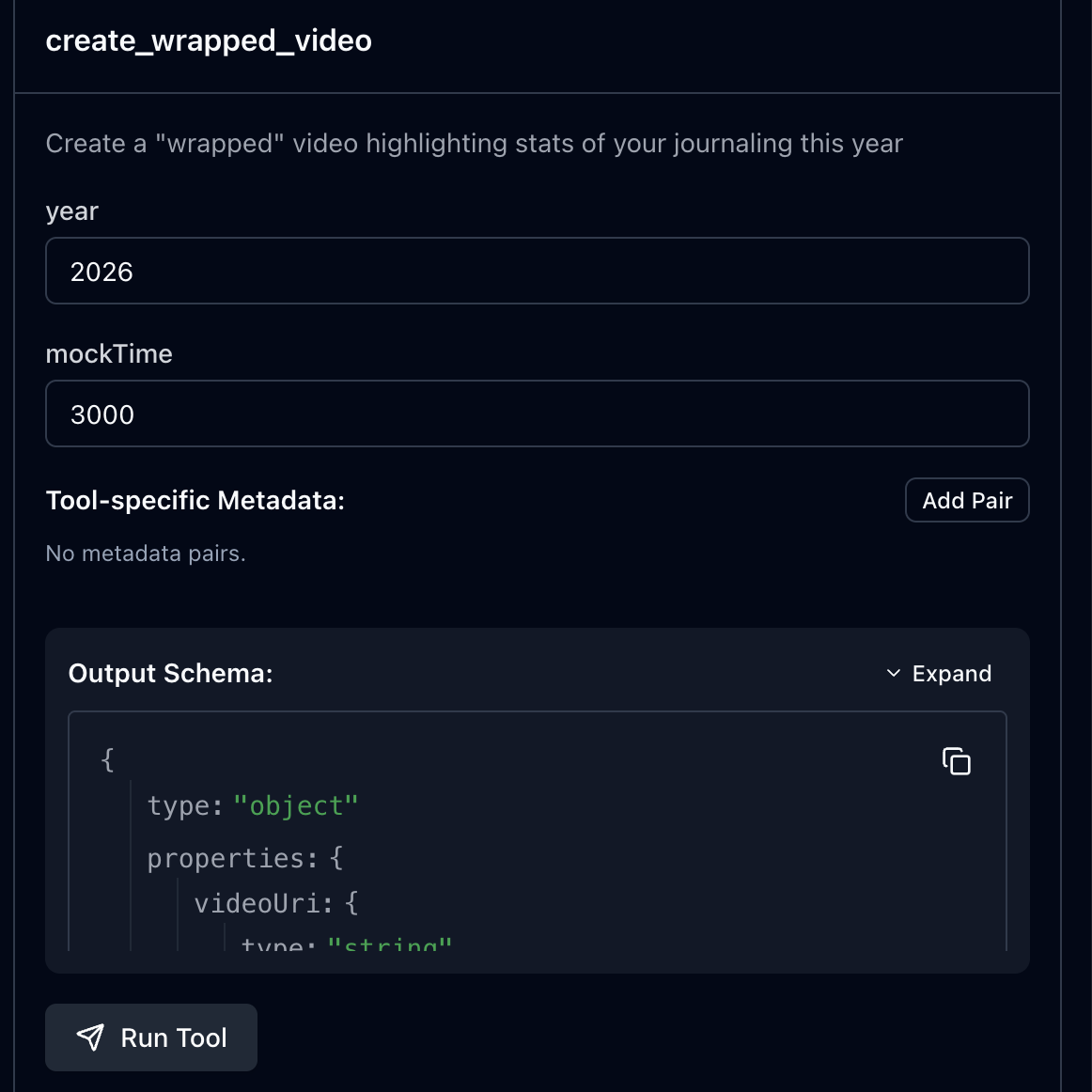
mock time을 3초라고 가정하고 create_wrapped_video을 실행해보면
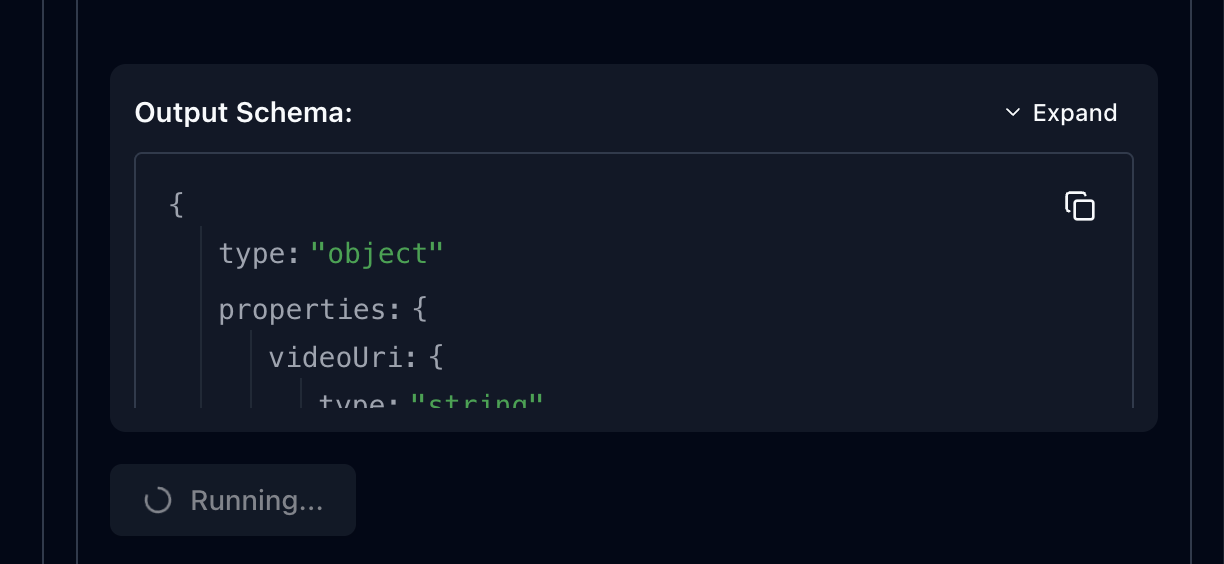
이렇게 팬딩 UI가 나온다!
Cancellation
만약 사용자가 비싼 연산 작업을 요청했는데, 탭을 닫거나 취소하게 되면 서버는 불필요한 연산을 계속 실행할 수 있다. 이러한 낭비를 막기 위해 Abort Signal을 제공한다
사용자가 탭을 닫거나 요청을 취소하게 되면 MCP Client가 자동으로 cancel notification을 보내고 SDK에서 signal.abort()를 호출한다. 그렇게 되면 서버에서 이벤트가 발생한다.
그럼, 코드로 살펴보자.
아까와 마찬가지로 AbortController가 signal을 만들고createWrappedVideo에 signal을 넘길 것이다.
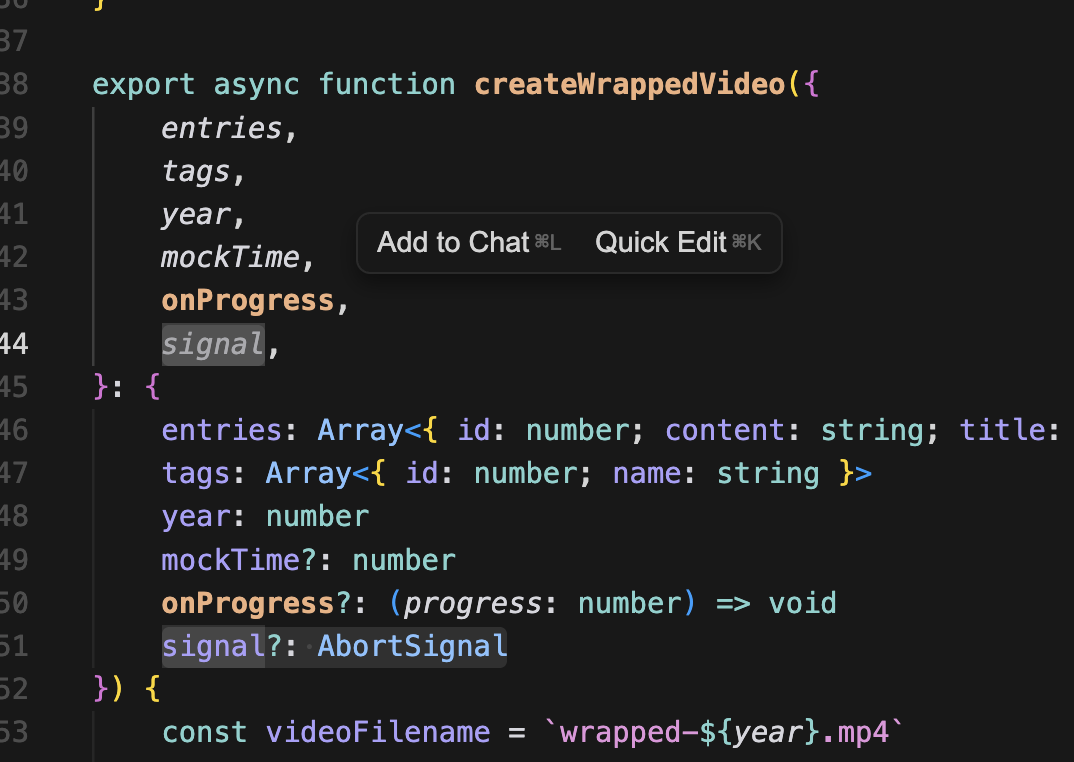
signal을 넘기고

취소된 경우 곧바로 에러를 던진다.
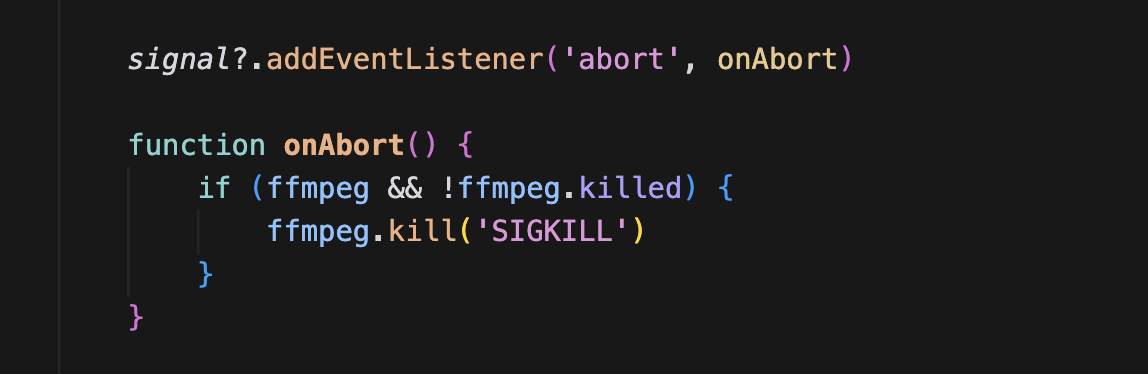
abort 이벤트 리스너를 등록해서 중단 시점에서 정리 로직을 실행한다.
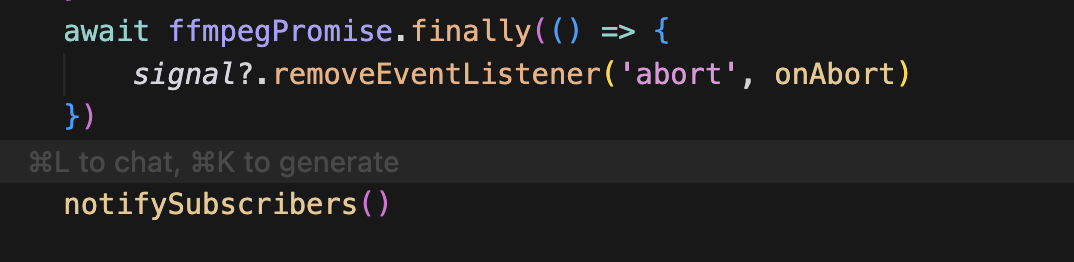
그리고 클린업까지 해주면 된다.
Change
웹앱에서 사용자의 로그인 상태, 권한, 데이터 유무 따라 버튼, 메뉴가 따라 바뀌듯,
MCP 서버도 제공하는 툴, 프롬프트, 리소스가 실시간으로 변할 수 있다.
그래서 MCP는 서버 상태 변화를 클라이언트에게 자동으로 알려주는 표준 메커니즘을 제공하는데 이걸 Change Notifications라고 한다.
크게 Tool, Prompt, Resource가 변경된다.
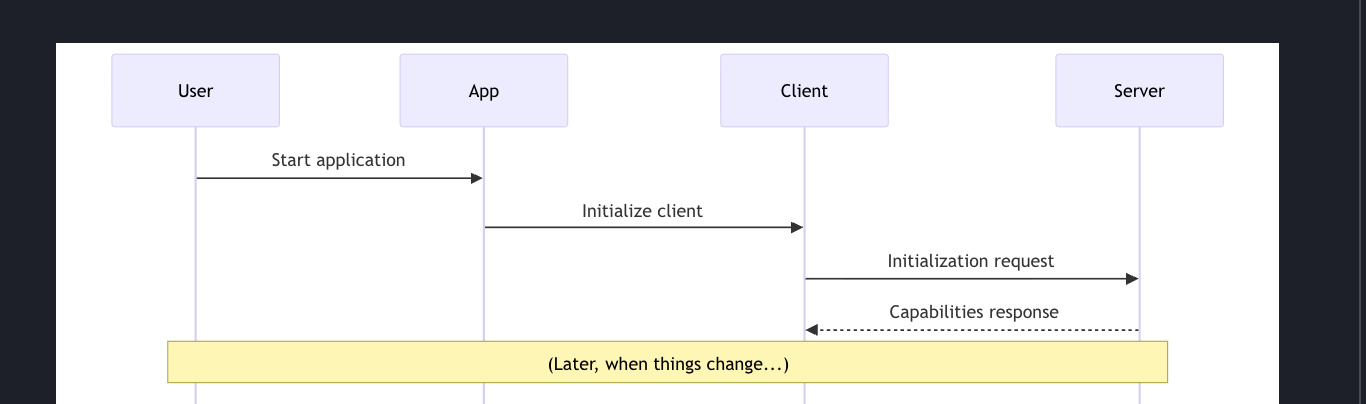
- 사용자가 애플리케이션을 시작하면,
- 애플리케이션은 클라이언트를 초기화한다.
- 그러면 서버로 initialization request을 보내고
- 서버는 capabilities을 응답한다.
그렇게 MCP가 돌아가고 어떤 시점에 tool이 호출되거나, 혹은 데이터베이스에서 뭔가가 일어났다고 가정해보자. 그렇게 되면 tools, resources, prompts가 바뀔 수 있다.
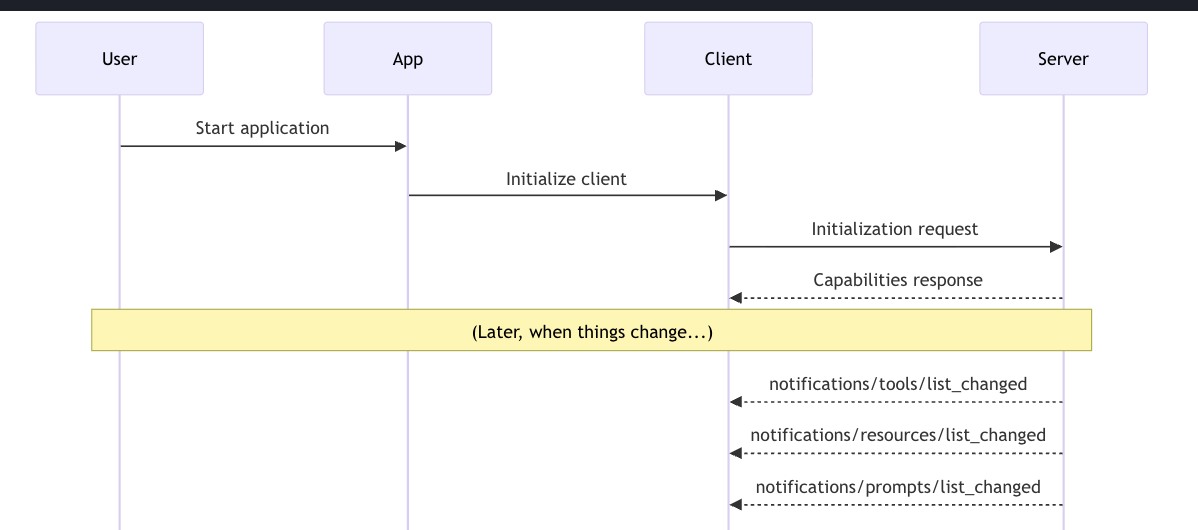
즉, 사용할 수 있는 도구, 리소스, 프롬프트의 목록과 정의가 변할 수 있다. 이러한 변화를 반영해 클라이언트가 가능한 한 최신 상태를 유지하길 원한다. 그래서 서버는 이런 변경 사항을 notification으로 클라이언트에게 보낸다.
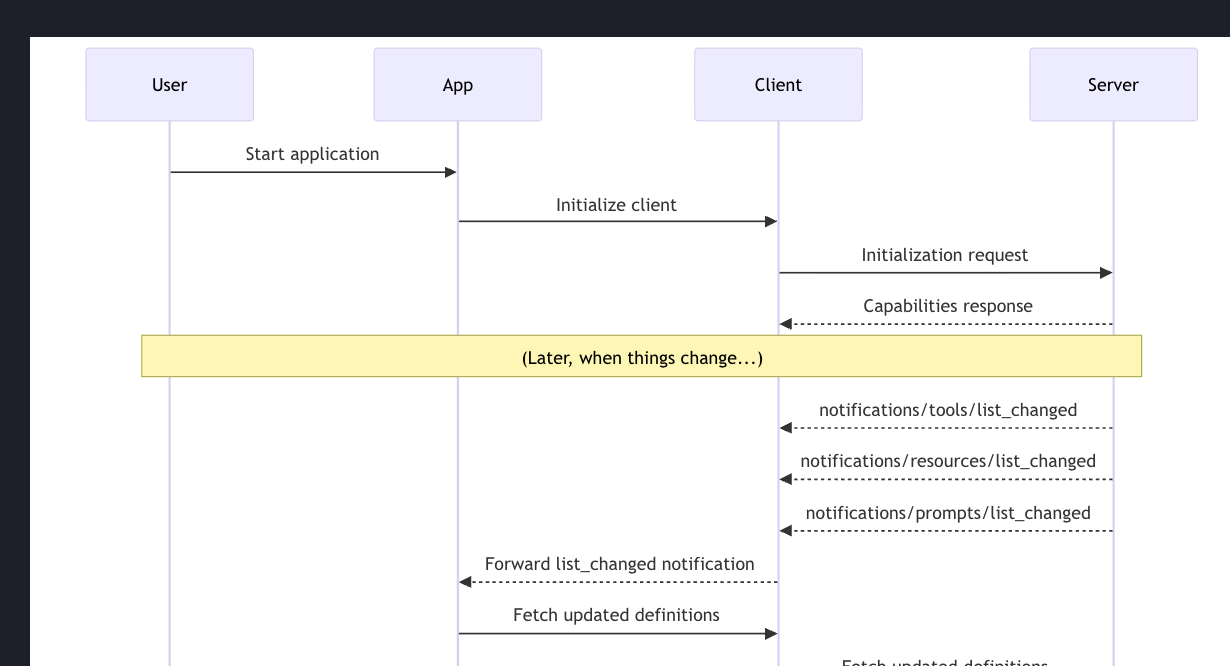
클라이언트는 그걸 앱으로 전달하고, 앱은 그걸 보고 뭘 할지 결정한다. 일반적으로 앱은 업데이트된 정의를 다시 가져온다.
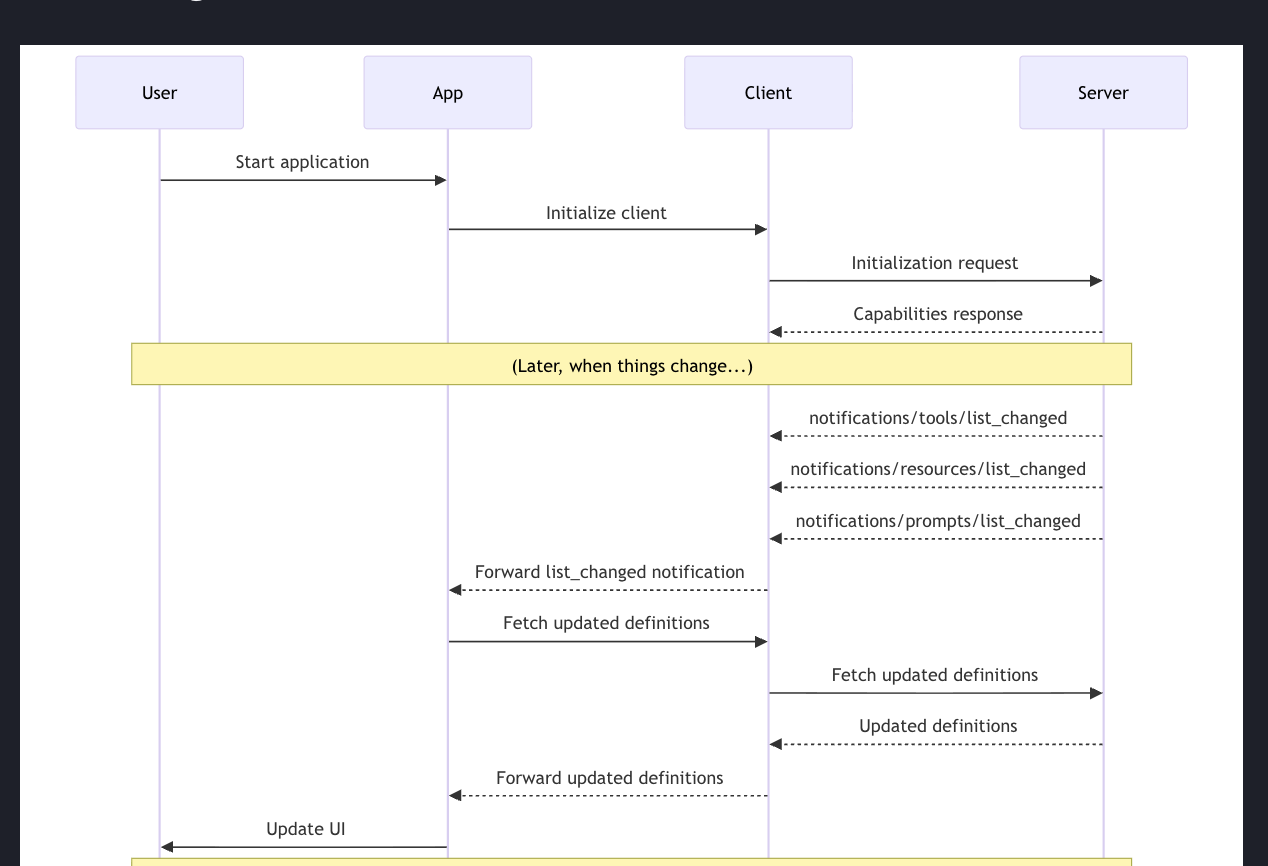
그래서 tools/prompts/resources에 대해 list 호출을 해서 최신 정의를 받아온다. 이제 그 정의를 기반으로 UI를 업데이트하거나, LLM에 반영하거나, 원하는 처리를 하게 된다. 이것이 change의 플로우다.
