개요
아이디어의 출발은 같은 팀 기획자의 SQL 공부에서 시작했다. 기획자 분이 데이터를 봐야할 때마다 서버 개발자한테 요청하는 것이 불편하여, 직접 SQL 공부를 하고 있다고 하셨다.
그런데 생각보다 학습이 더뎠고, 쿼리를 날려서 데이터를 추출해도 이게 정확한 건지 서버 개발자 분한테 다시 물어봐야 해서 리소스가 추가적으로 낭비되고 있었다. 대AI 시대에 이렇게 불필요한 리소스 낭비가 필요할까. 라는 고민에서 시작하여 일명 '자연어 검색'이라는 기능을 어드민에 추가했다.
목표
목표는 간단하다. 자연어로 물으면 LLM이 관련 테이블을 확인하여 SQL문을 생성한다.
생성된 SQL문을 반환하고 그 SQL로 DB를 조회해서 결과값과 크로스체크용으로 SQL문을 반환한다.
개발 과정
먼저 서버를 따로 만들어야 하니 Express로 서버를 띄웠다.
실제 MCP 프로토콜을 구현한 것은 아니고, tools/list, tools/call 형태의 RPC 구조만 MCP 스타일로 구성했다.
향후 Claude 같은 MCP client와 연동할 수 있도록 확장 가능하도록 MCP 스타일로 만들어보았다.
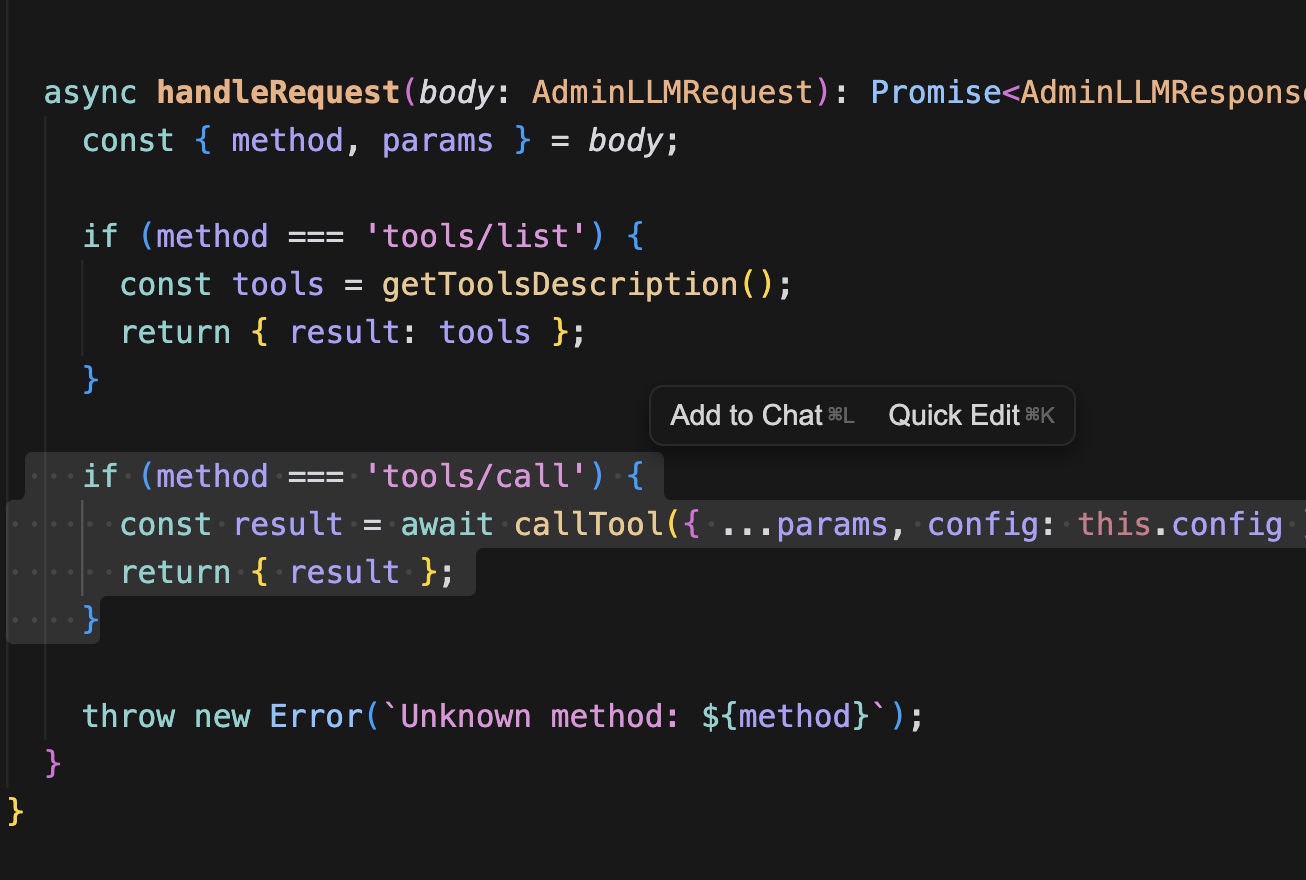
그래서 tools에 naturalLanguageFilterTool라는 함수를 하나 만든다.
프론트에서 검색하기 버튼을 통해 HTTP 요청을 보내면,

해당 엔드포인트에서 만들어놓은 MCP 서버(간이)의 핸들러에서 분기해서 naturalLanguageFilterTool를 호출한다.
LLM에게 요청 넘기기
레디스는 안 붙였기에 일단 메모리에 캐시 없다면
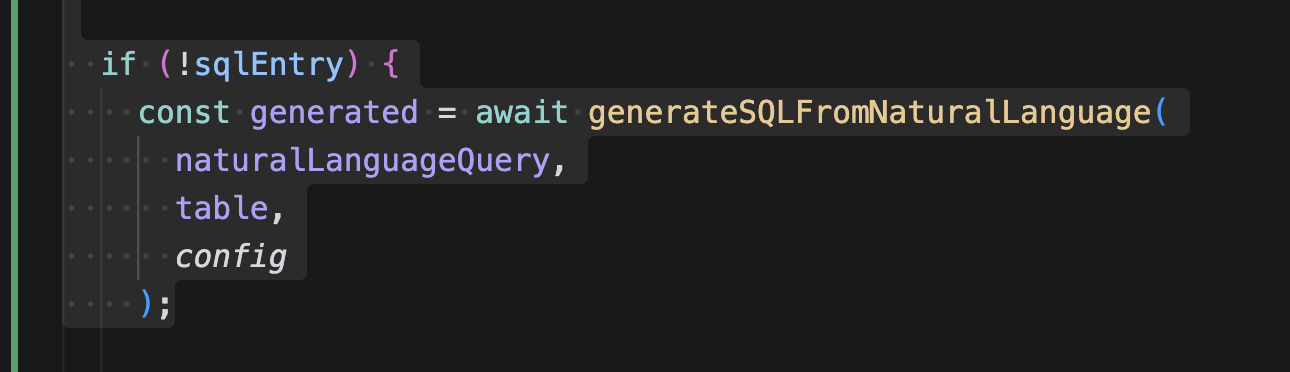
LLM에게 테이블 정보를 넘기는 함수를 호출한다. 같은 질문이 반복될 수 있기 때문에 생성된 SQL은 메모리 캐시에 저장한다. LLM은 복잡한 질문일수록 토큰을 많이 잡아먹으니 레디스가 필수인 거 같다.
이제 우리는 LLM에게 테이블 스키마를 넘겨야 하는데, 가령 자연어 질문, '이번 달 매출이 가장 많은 상품이 뭐야?' 이 들어오게 되면 그 쿼리를 작성하기 위한 테이블 스키마가 필요하다.
어떤 질문을 할지 모르니, 처음엔 모든 테이블을 조회해서 스키마를 넘겼는데 이런 식으로 테스트를 해보니 토큰 사용량이 너무 많이 나왔다. 그래서 비즈니스에 코어한 테이블만 먼저 조회하는 식으로 변경했다.
이렇게 일단 만들어두고, 테이블을 찾을 수 없는 질문이 들어오면 폴백 형식으로 전체 테이블을 조회하게 하면 토큰을 많이 절약할 수 있다.
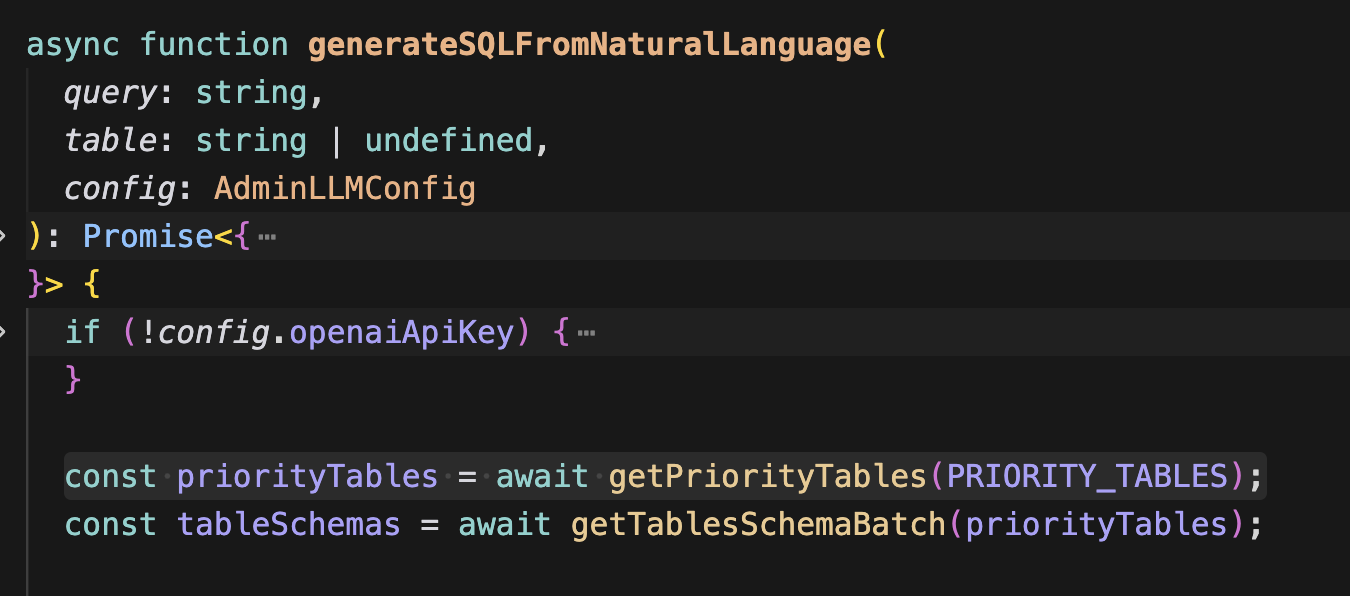
getPriorityTables라는 함수에 우선순위로 정한 테이블 이름을 넘기고 실제 DB에 테이블이 있는지 검증한다.
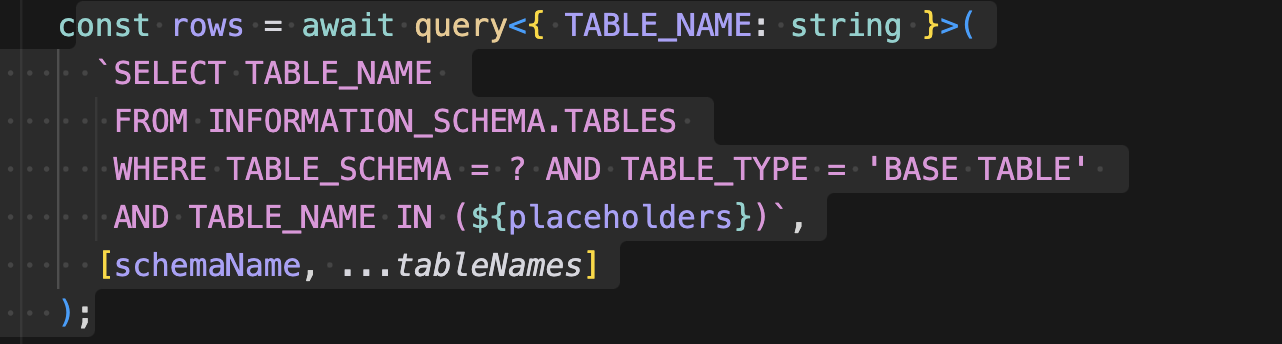
그리고 각 테이블에 대한 컬럼을 가져오면 아래와 같이 생성된다.
tableSchemas {
coupon_info: [
'COUPON_INFO_SEQ',
'MNGR_USER_SEQ',
'COUPON_START_DATE',
'COUPON_END_DATE',
'COUPON_PAUSE_YN',
...
],
order_info: [...]
...이제 LLM에 넘기기 전에 {테이블 이름 : ["컬럼", "컬럼"]} 으로 되어 있는 JSON을 텍스트 형태로 변경해야 한다.
처음엔 JSON 형태로 바로 LLM에게 넘기면서 키가 테이블 명이고, 배열 안에 컬럼명이 있으니까 되겠지 하고 바로 LLM을 호출했는데, 이러한 형식이 생각보다 토큰을 많이 잡아 먹는다고 한다.
JSON 형태로 전달하면 { } , " " 같은 구조 토큰이 추가로 발생하기 때문이다.
그래서 가장 좋은 방식은 string이고, 이게 어떤 데이터인지 힌트만 주면 훨씬 토큰을 절감할 수 있다.

buildSchemaText라는 함수에서 JSON -> String으로 변환시키면 LLM으로 넘길 준비를 마쳤다.
'coupon_info(COUPON_INFO_SEQ,MNGR_USER_SEQ,...), order_info(...) // 다른 테이블...',어떻게 요청할까
이제 open ai에서 제공하는 endpoint로 요청하면 되다. 요청 하기 전 prompt를 작성해야 하는데, 프롬프트는 두 가지가 있다.
시스템 프롬프트는 변하지 않는 정책, LLM이 해야 하는 일의 기본적인 틀을 입력해주면 된다.
{
role: 'system',
content:`
자연어→MySQL SELECT 변환.
질문형→집계,
필터형→SELECT *.
테이블 추론(상품→goods_info).
//...
매출 조회 시 STAT NOT IN (취소,반품,환불) 추가.
컬럼명 순수만.
?파라미터화. JSON만.
`,
}나의 경우는 이런 식으로 작성했다. 꼼꼼하게 작성한다고 룰을 잔뜩 쓰면 토큰 낭비가 크다. 그렇다고 너무 적게 쓰면 엣지 케이스에서 자꾸 헛발질을 하고 모든 경우를 커버해야지 하고 쭉 나열하면 토큰이 사라지고. 적절하게 핵심만 잘 전달하는 그 감을 찾는 것이 어려운 것 같다. 아무튼 토큰을 효율적으로 사용하기 위해서는 짧은 명령형의 영어가 더 좋다고 한다.
그리고 이제 실제 질문을 넣을 차례다. 유저 프롬프트는 동적인 변수 같은 것이다. LLM이 읽고 처리할 데이터와 개별 규칙을 넣어준다.
{
role: 'user',
content: `
자연어를 MySQL SELECT로 변환 // 해야 하는 역할
// 리소스
자연어: "${query}"
${table ? `테이블: ${table}` : `테이블: ${tableList}`}
${schemaText ? `스키마: ${schemaText}` : ''}
${schemaInfo ? `컬럼: ${schemaInfo.slice(0, 10).join(',')}` : ''}
규칙:
- 필터형→SELECT * |
- 매출→order_goods_info.FINAL_GOODS_PRICE |
- 시간단위→YEAR/MONTH+GROUP BY |
- 최대→DESC LIMIT 1 |
- WHERE→?파라미터화 |
- 컬럼명은 순수만(테이블명.컬럼명 금지)
// LLM이 테이블 찾을 때 헷갈려하는 것들 명시
${TABLE_RELATIONSHIP_HINTS}
// 어떤 식으로 반환하라는지 명시
JSON: {"type":"filter|question","sql":"SELECT...","params":[],"sqlWithValues":"SELECT...","question":"?"}
},이런 식으로 작성하고 Open AI api로 요청을 보내면
"type":"question",
"sql":"SELECT goods_info.GOODS_NM, SUM(order_goods_info.FINAL_GOODS_PRICE) AS total_sales ... ",
"params":[2025]",
"question":"2025년 매출이 가장 큰 상품 뭐야?"}이렇게 SQL문으로 변환하여 응답을 준다.
사실 시행찾오가 있었는데 질문의 의도와는 잘못된 테이블을 선택한다거나 없는 컬럼명을 만들어낸다거나 복잡한 조인에 실패하는 경우가 있었다.
이를 해결하기 위해 테이블 스키마 정보를 함께 제공하고, 프롬프트 규칙에 추가하여 명시해줘야 한다.
로컬에서 프로토타입을 만들 때는, express에서 DB를 직접 조회했지만 스테이징이나 상용에 올릴 경우엔 역할을 나눠서 express 서버는 LLM 호출만, 그리고 쿼리를 DB 접근이 허락된 서버에 넘겨서 DB 조회수 값을 받아야 한다.
검증하기
이제 응답으로 받은 SQL로 DB를 조회하여, 알맞은 값을 가져오면 된다.
그 전에 혹시라도 SELECT이 아닌 다른 행동이 있을 수도 있니
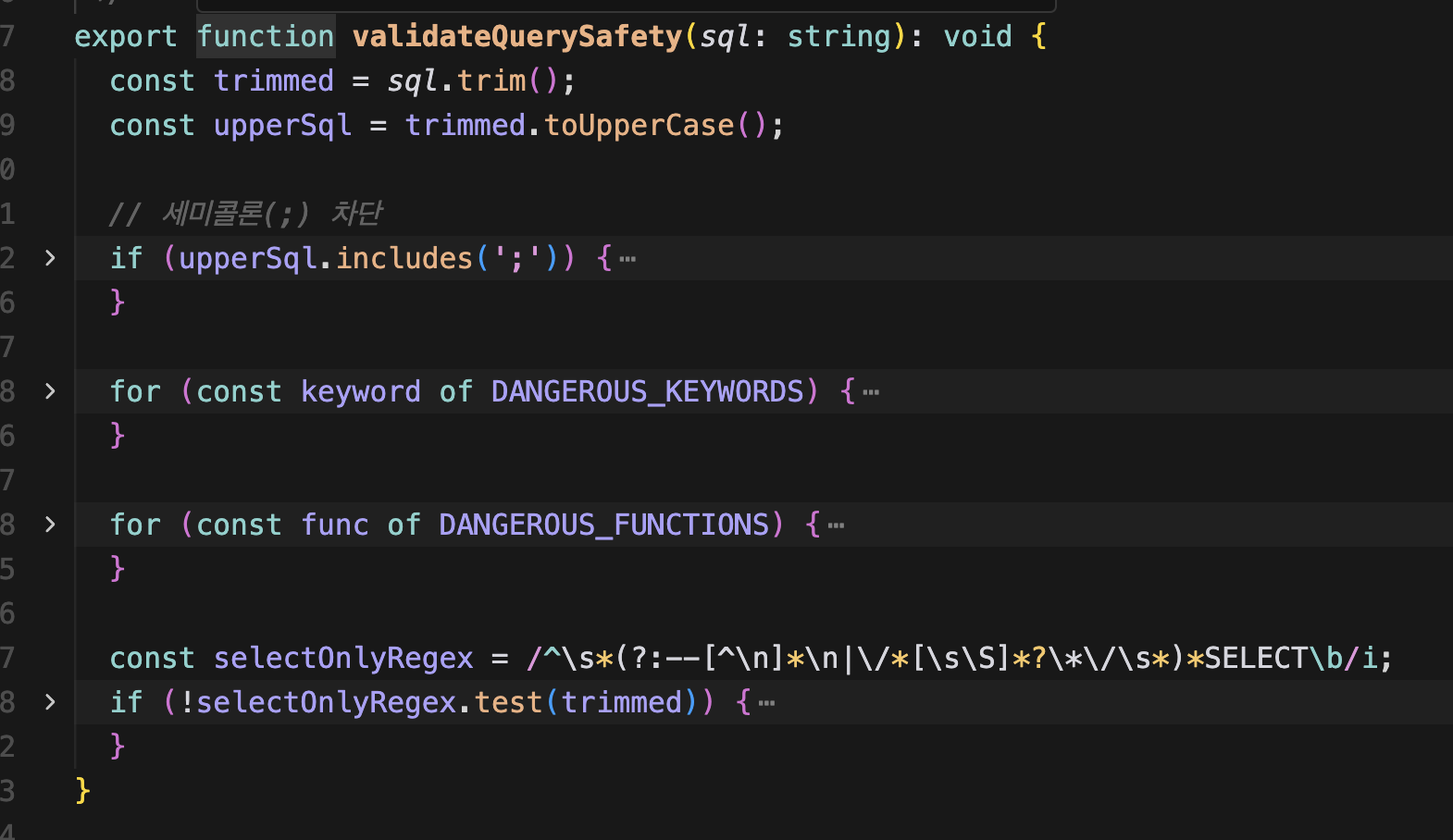
조회 전 SELECT이 아닌 키워드는 모조리 필터해준다. SQL injection의 경우, 프롬프트에 모든 WHERE 조건은 ? placeholder로 생성하도록 강제했다.
...WHERE YEAR(order_goods_info.REGST_DTT) = ?...이런 식으로 SQL 구조와 데이터가 분리되기 때문에 사용자 입력이 SQL 문법으로 해석되는 것을 방지할 수 있다.

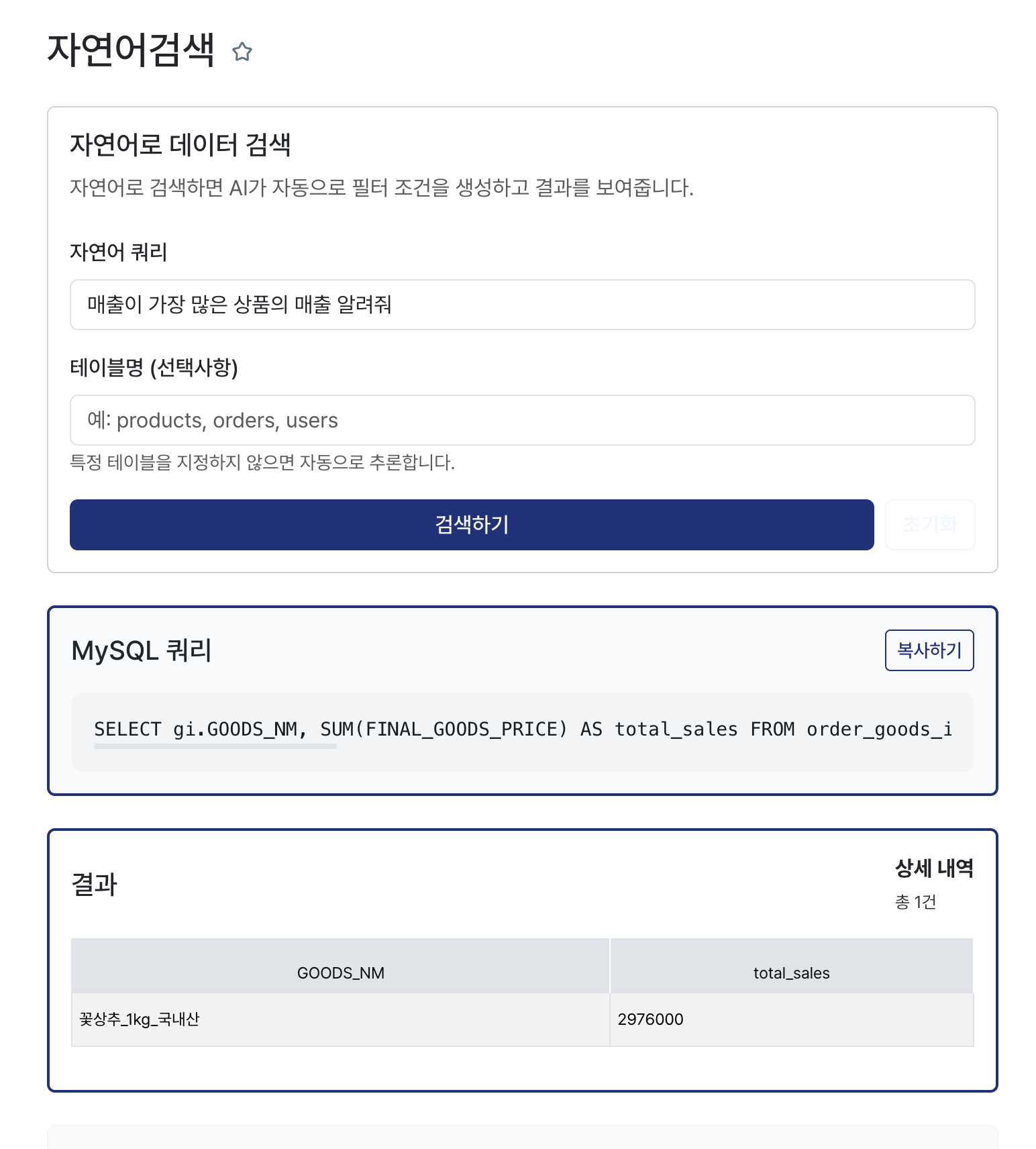
마지막으로 조회를 하면 이렇게 값이 잘 출력되고 UI에 뿌려주면 된다.
다른 쿼리도 검색해보면
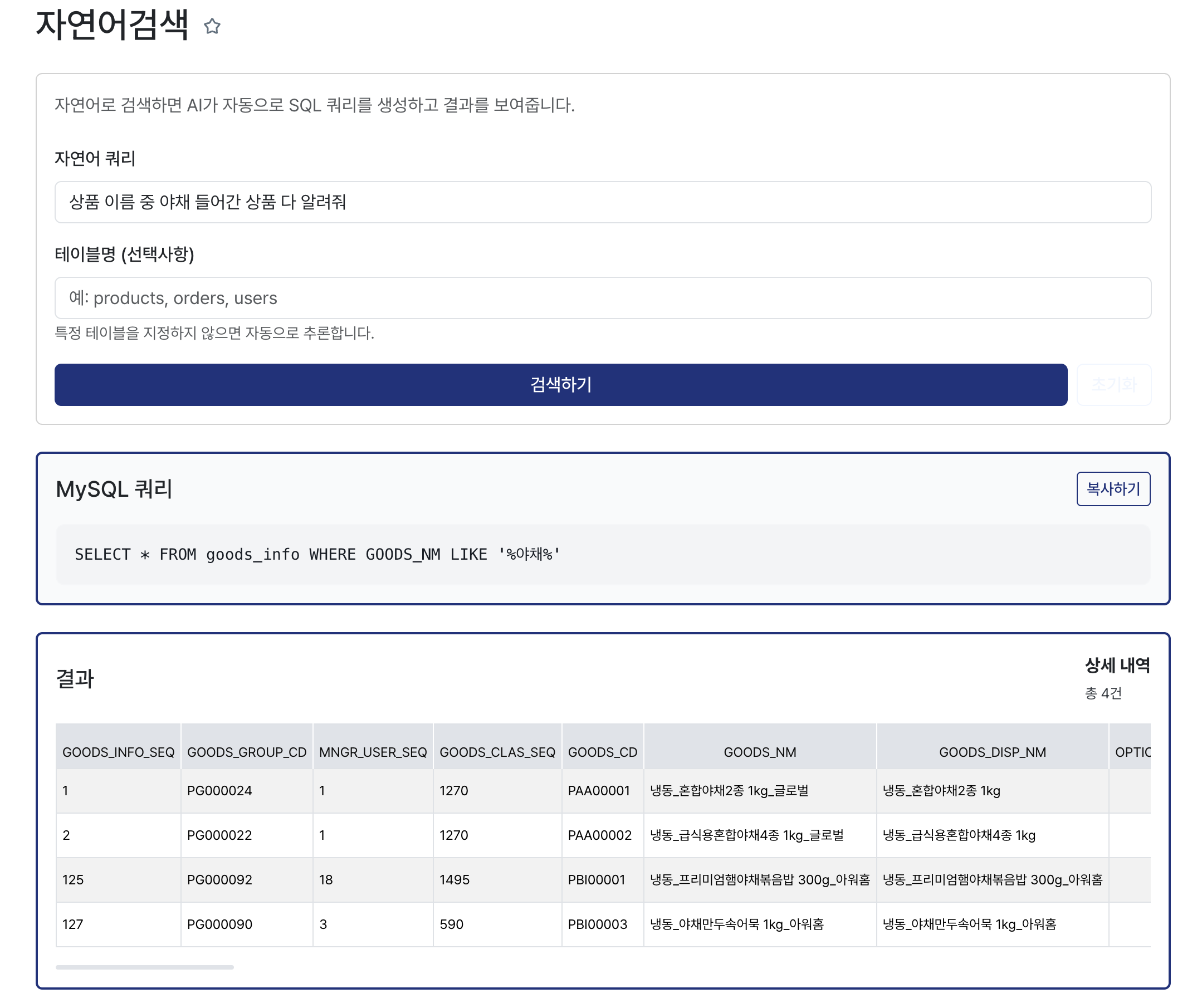
이렇게 잘 나온다. [복사하기] 버튼을 눠서 제대로 작동하는 쿼리인지 교차검증을 가능하게 했다.
마무리
LLM을 실무에 적용해본 건 처음인데, 생각보다 쉬우면서도 생각보다 어려웠다.
생각보다 쉬운 점은 사실상 Open AI를 비롯한 LLM들이 텍스트에 있어서는 만능이기 때문이다. 자연어 검색을 비롯해서 'DB 조회해서 매출 분석 후 주간 리포트 쓰기'와 같은 기능도 붙여봤는데 그냥 데이터만 던지면 무언가가 나오긴 한다.
아이디어와 적절한 룰만 있다면 뭐든지 만들어서 생산성을 높일 수가 있다.
생각보다 어려운 점은 데이터만 던지면 무언가가 나오긴 하지만 이게 정말 쓸모 있는 정보인가 혹은 적절한 토큰을 사용했는가에 대한 명확한 가이드라인이 없다는 게 어려운 점이었다.
또한, LLM이 자연어 -> 쿼리를 변경하는 과정에서 생각보다 엣지케이스가 많았고(없는 컬럼을 만들어낸다거나 이름 비슷한 다른 컬럼을 조인한다거나 등등) 그 케이스에 대해 모두 규칙을 정하자니 토큰이 많이 소모되어 이런 방법이 맞는지에 대해 살짝 의구심이 들었다.
어떻게 하면 LLM을 잘 쓸 수 있을까에 대해 계속 고민해봐야겠다.
