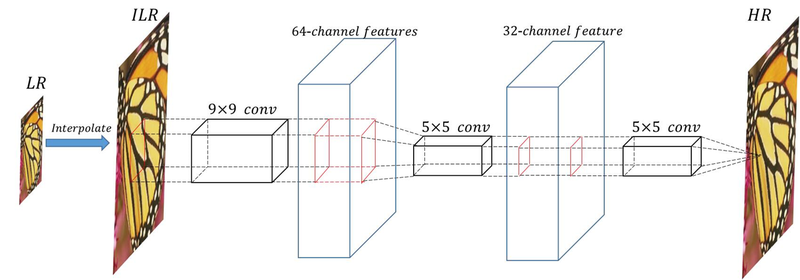
SRCNN(Super Resolution Convolution Neural Network)

SRCNN의 과정
- 저해상도 이미지 LR을 bicubic interpolation해 원하는 크기로 이미지를 늘린다.
- 늘려진 이미지 ILR을 입력으로 저해상도의 이미지에서 이미지의 특징을 가지는 patch 추출
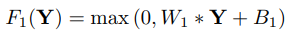 (1) Patch extraction and representation
(1) Patch extraction and representation - 2번 과정을 통해 얻은 다차원의 patch들을 Non-linear하게 다른 차원의 patch들로 매핑을 하는 과정
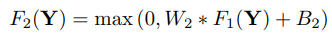 (2) Non-linear mapping
(2) Non-linear mapping - 3번 과정을 거친 다차원의 patch들로부터 고해상도 이미지를 복원시킨다.
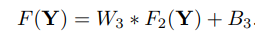 (3) Reconstruction
(3) Reconstruction - 복원시킨 고해상도 이미지와 실제 고해상도 이미지 사이의 차이를 역전파해 신경망의 가중치를 학습한다.
SRCNN의 발전
VDSR(Very Deep Super Resolution)
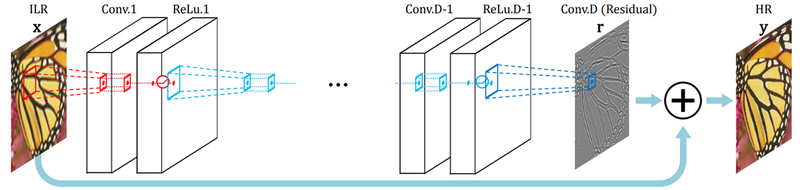
SRCNN과 동일한 방식으로 진행되지만 3개의 Convolution Layer를 지닌 SRCNN에 비해 VDSR은 20개의 Convolution Layer를 사용한다.
또한 최종 고해상도 이미지 생성 직전에 처음 입력 이미지를 더하는 Residual Learning을 이용했다.
RDN(Residual Dense Network)
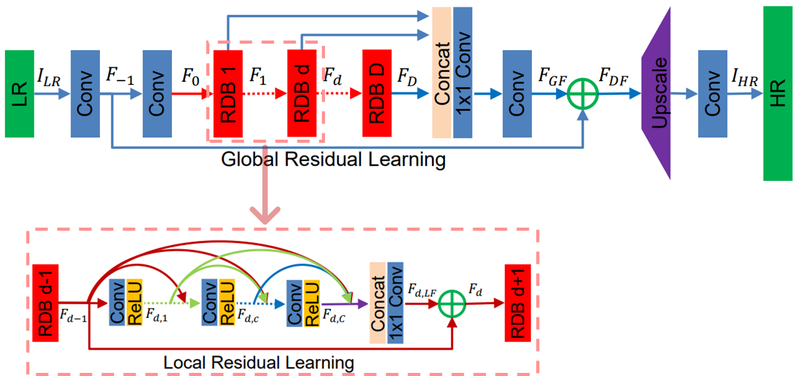
저해상도의 이미지가 여러 단계의 Convolution Layer를 지날 때, 각 Layer에서 나오는 출력을 연산 과정에 추가(재활용)한다. <각 Layer에서 나오는 출력 화살표 방향 주목>
RCAN(Residual Channel Attention Networks)
Convolution Layer의 결과인 Feature map을 대상으로 채널 간의 모든 정보가 균일한 중요도를 갖는 것이 아니라 일부 중요한 채널에만 선택적으로 집중하도록 유도한다.
