세그멘테이션(Segmentation)
이미지에서 픽셀단위로 관심 객체를 추출하는 방법.
이미지에서 개체가 있는 위치, 해당 개체의 모양, 어떤 픽셀이 어떤 객체에 속하는지 등을 알고 싶다고 가정할 때, 이미지를 분할해 이미지의 각 픽셀에 레이블을 부여하는 것이다.
이러한 세그멘테이션은 여러 가지 종류로 나뉜다.
1. 세그멘테이션의 종류
(1) 시멘틱 세그멘테이션(Sementic Segmentation)
실제로 인식할 수 있는 물리적 의미 단위로 인식하는 세그멘테이션을 시멘틱 세그멘테이션(sementic segmentation)이라고 한다.
즉, 이미지에서 픽셀을 사람, 자동차, 비행기 등의 물리적 단위로 분류하는 방법이다.
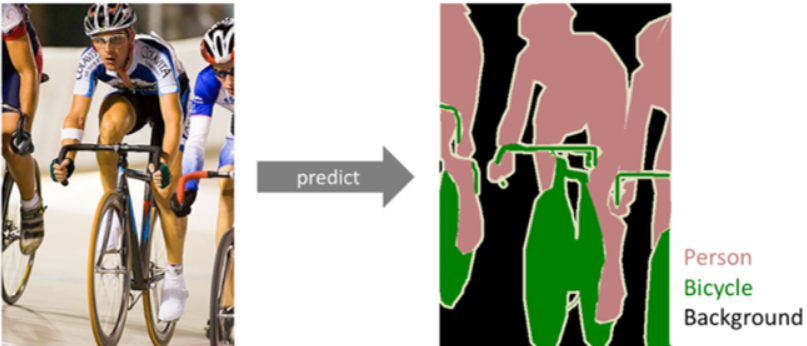
세부적으로는 모든 픽셀의 레이블을 예측하는 Dense Prediction이라고 부른다.
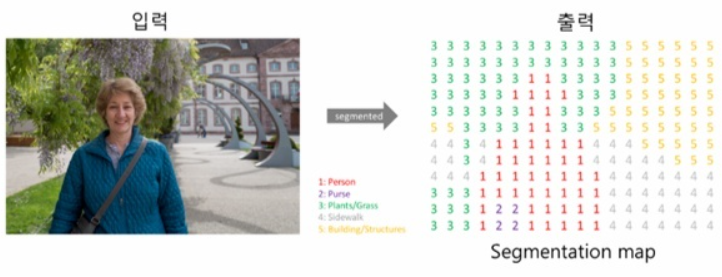
(2) 인스턴스 세그멘테이션(Instance Segmentation)

시멘틱 세그멘테이션은 사진에서 '사람'이라는 객체 자체를 추출한다. 결국 다른 사람이더라도 상관없이 같은 라벨로 표현된다.
인스턴스 세그멘테이션은 사람을 개개인별로 다른 라벨을 가지게 한다.
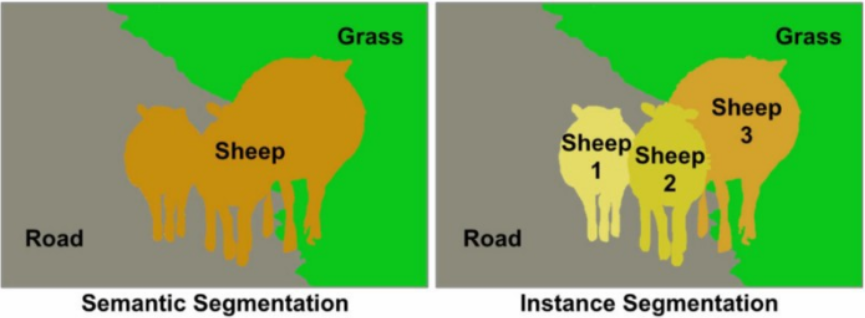
2. 시맨틱 세그멘테이션 활용
Semantic Segmentation을 해결하기 위한 방법 역시 여러가지가 있다.
그 중 DeepLab이라 불리는 알고리즘에 대해 알아보자.
DeepLab
DeepLab은 Semantic Segmentation을 해결하기 위한 방법으로 1, 2, 3, 3+ 네가지 버전이 존재한다.
DeepLab은 atrous convolution을 활용해 Semantic Segmentation을 해결한다.
DeepLab에서 사용되는 개념들은 다음과 같다.
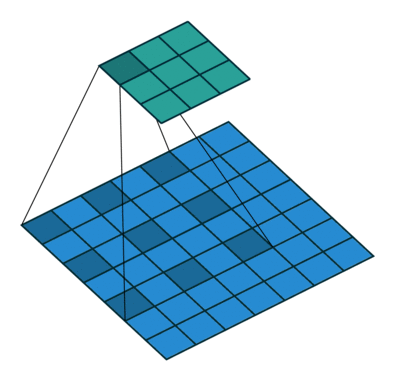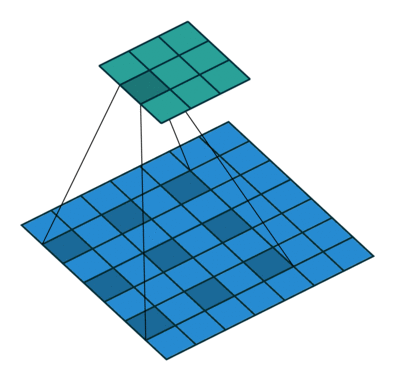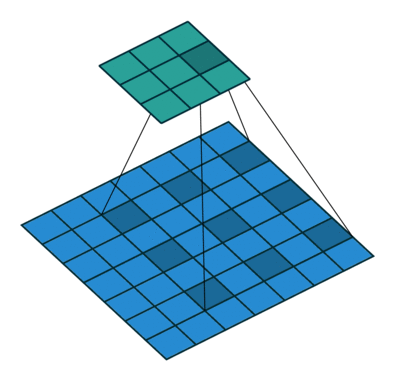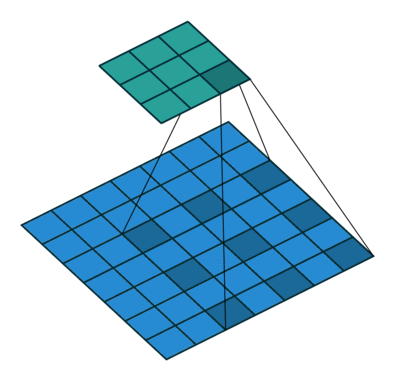
[1] Atrous Convolution(Dilated Convolution)
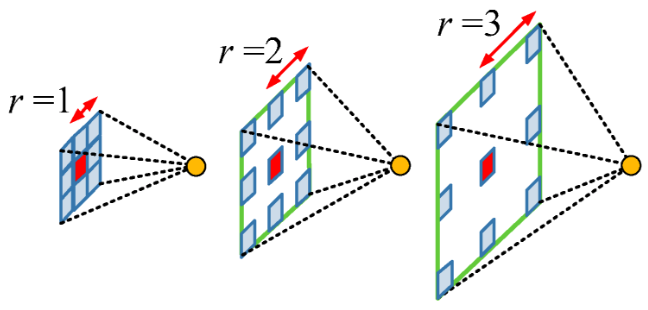
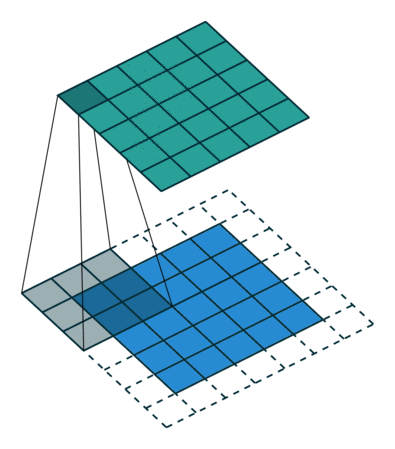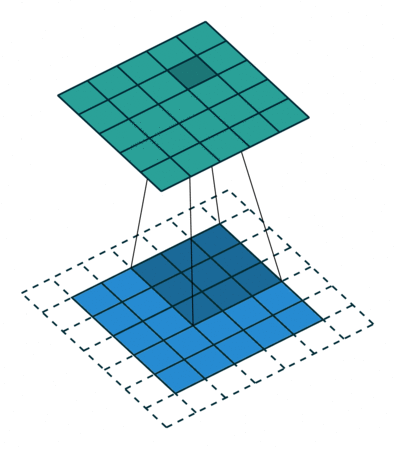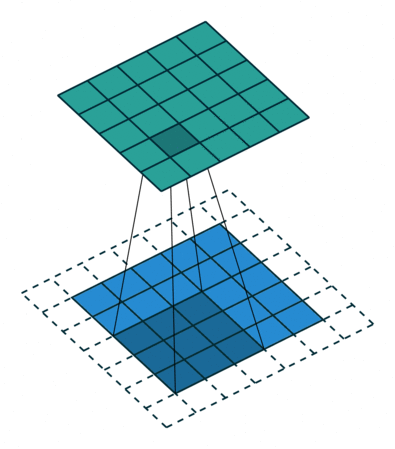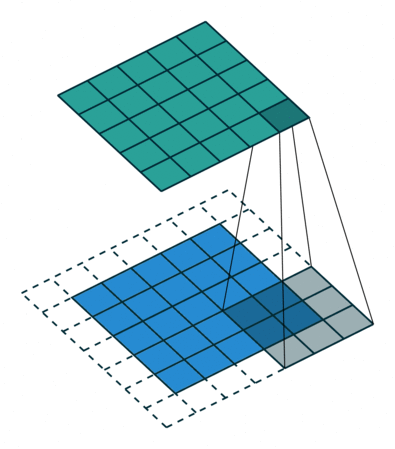
Atrous Convolution은 기존 Convolution과 다르게 필터 내부에 빈 공간을 둔 채로 작동한다.
위 사진에서 볼 수 있듯이, r(rate)라는 파라미터를 통해 얼마나 빈 공간을 둘지 설정하고 빈 공간을 제외하고 기존 Convolution과 같이 학습을 진행한다.
r = 1일 경우에는 기존 Convolution과 동일하게 학습을 진행한다.
- 이점
- 기존 Convolution과 동일한 양의 파라미터와 계산량을 유지하면서 field of view(한 픽셀이 볼 수 있는 영역)를 크게 가져갈 수 있게 된다.
- 즉, 파라미터 수를 늘리지 않으면서도 receptive field를 키울 수 있다.
- Receptive Field란?
- 필터가 한번 보는 영역으로 사진의 feature를 추출하기 위해선 receptive field가 높을수록 좋다.
- 일반적인 Convolution의 경우 위 사진과 같이 3x3 필터가 이미지 데이터를 순회하면서 Feature를 추출한다.
- 그러나 위 사진과 같이 필터 내부에 zero padding을 추가해 강제로 receptive field를 늘리면 pooling을 수행하지 않고도 receptive field를 크게 가져갈 수 있기 때문에 spatial dimension의 손실이 적고, 대부분의 weight가 0이기 때문에 연산의 효율이 좋다.
- 즉, 공간적 특징을 유지하기 때문에 Segmentation에서 많이 사용한다.
- 이런 Convolution을 Atrous Convolution 혹은 Dilated Convolution(확장된 Convolution)이라고 불린다.
- 필터가 한번 보는 영역으로 사진의 feature를 추출하기 위해선 receptive field가 높을수록 좋다.
- Receptive Field란?
[2] Spatial Pyramid Pooling
Semantic Segmentation의 성능을 높이기 위한 방법 중 하나로, 이를 사용한 SPPNet은 R-CNN의 단점을 극복하고자 나온 모델이다.
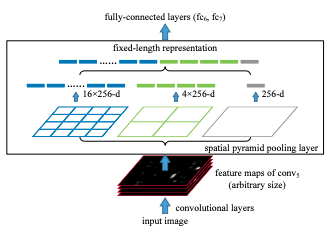
-
SPP는 Conv Layer를 거친 Feature Map을 인풋으로 받아 위와같이 4x4, 2x2, 1x1로 미리 정해진 영역으로 나눈다.
-
각각을 하나의 피라미드라고 부른다. 즉, 위 사진에서는 3개의 피라미드를 설정한 것이다.
-
위 피라미드에서 네모칸 한 칸을 bin이라고 부른다.
-
각 bin에 알맞은 크기의 Window(일종의 Filter와 같은 역할)와 Stride를 통해 Feature Map을 순회하며 MaxPooling을 수행해 그 값을 이어붙인다.
-
ex) 예를 들어 위에서 제시한 예시와 같이 64x64x256 Feature Map을 4x4, 2x2, 1x1 피라미드로 Pooling 했을 때, 최종 Output은 bin의 총 개수인 21과 Feature Map의 차원 수인 256개의 곱이된다.
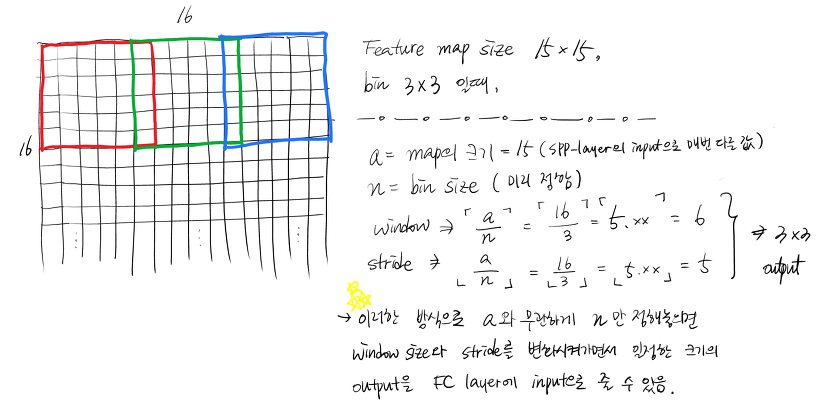
- 입력 이미지의 크기와는 상관 없이 미리 설정한 bin의 개수와 CNN 채널 값으로 SPP의 출력이 결정되므로 항상 동일한 크기의 결과를 리턴한다.
+) Selective Search(Region Proposal) 등 R-CNN과도 관련된 개념은 추후 정리 예정
