1. 반정규화(Denormalization)의 개념
반정규화란 시스템의 성능 향상, 개발 및 운영의 편의성 등을 위해 정규화된 데이터를 통합, 중복, 분리하는 과정으로 의도적으로 정규화 원칙을 위배하는 행위이다.
-
시스템 성능이 향상되고 관리 효율성 증가
-
사전에 데이터 일관성과 무결성을 우선으로 할지, 데이터베이스의 성능과 단순화를 우선으로 할지 결정
-
테이블통합, 테이블 분할, 중복 테이블 추가, 중복 속성 추가 등이 있다.
-
데이터 일관성 및 정합성 저하
-
과도한 반정규화는 성능저하
2. 테이블 통합
두 개의 테이블이 조인되는 경우가 많아 하나의 테이블로 합쳐 사용하는 것이 성능 향상에 도움이 될 경우 수행한다.
-
두 개의 테이블에서 발생하는 프로세스가 동일하게 자주 처리되는 경우, 두 개의 테이블을 이용해 항상 조회를 수행하는 경우 테이블 통합을 고려한다.
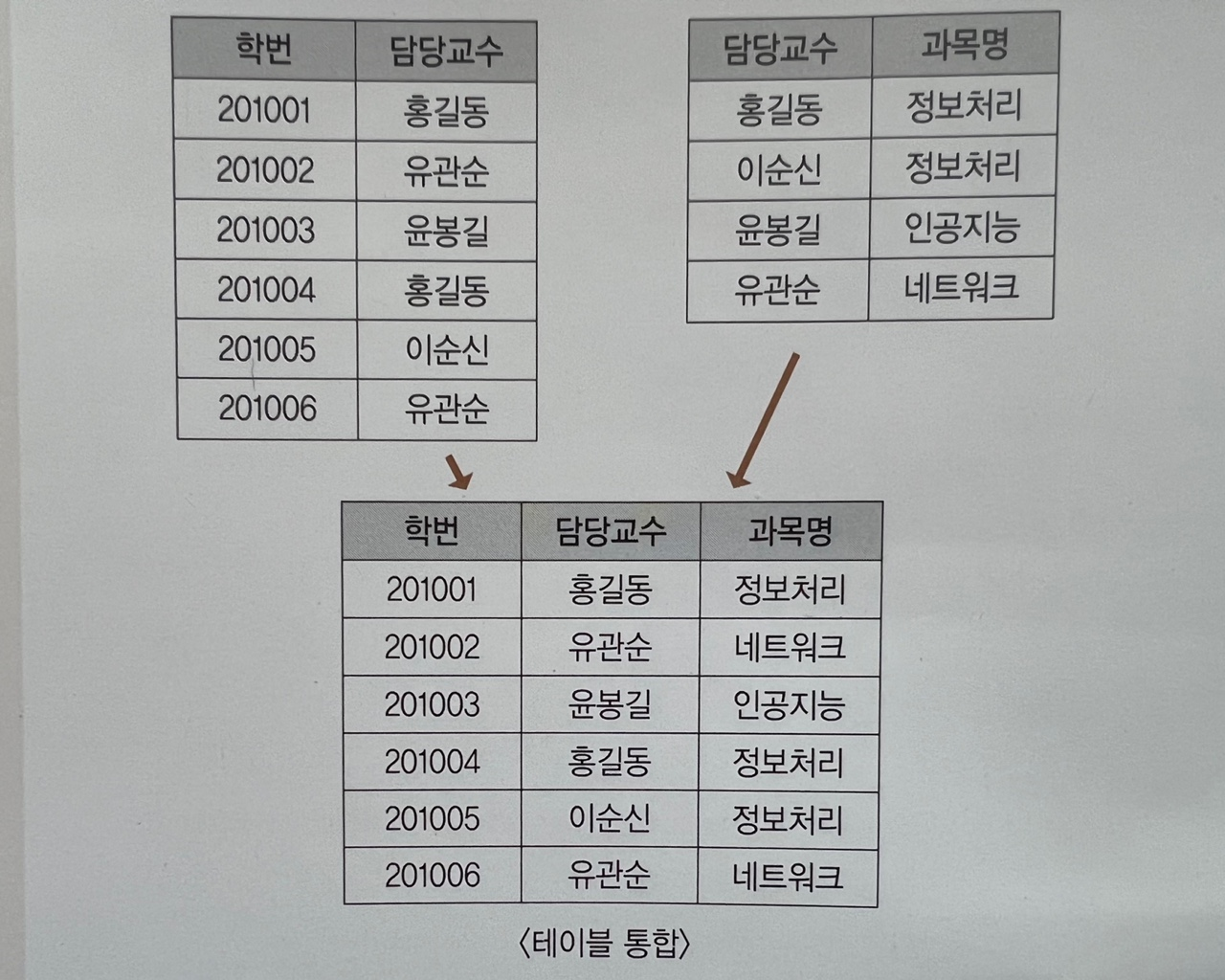
- 예) R1=학번,담당교수 R2=담당교수,과목명 으로 이루어진 두 개의 테이블을 학번,담당교수,과목명으로 통합한다
-
테이블 통합의 종류에는 1:1 관계 테이블 통합, 1:N 관계 테이블 통합, 슈퍼타입/서브타입 테이블 통합이 있다
-
테이블 통합 시 고려사항
✔ 데이터 검색은 간편하지만 레코드 증가로 인해 처리량 증가
✔ 테이블 통합으로 인해 입력, 수정, 삭제 규칙이 복잡해질 수 있음
✔ Not Null, Default, Check 등의 제약조건을 설계하기 어려워짐- Not Null: 속성 값이 Null이 될수 없음
- Default: 속성 값이 생략되면 기본값 설정
- Check: 속성 값이 범위나 조건을 설정하여 설정값만 사용
3. 테이블 분할
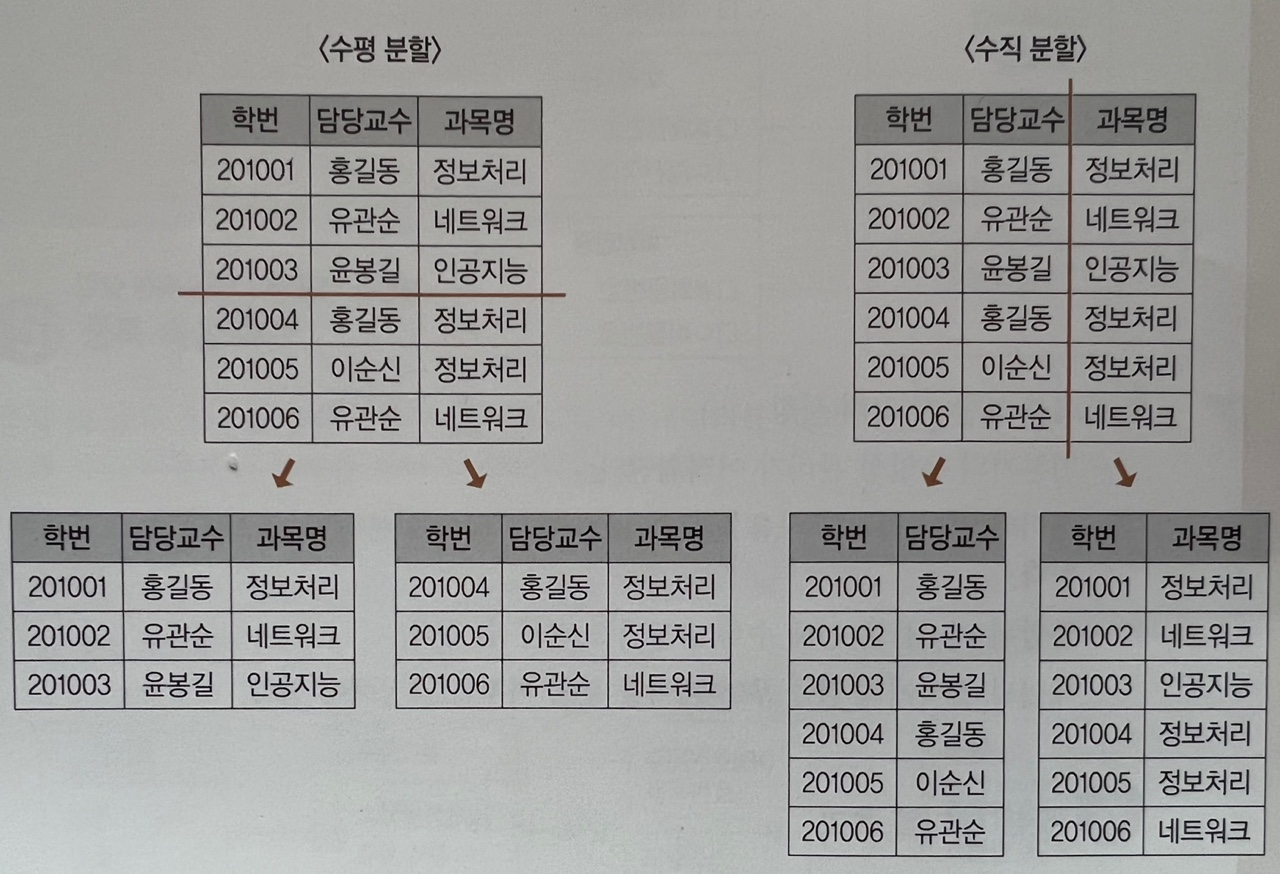
테이블을 수직 또는 수평으로 분할하는 것
- 테이블 분할 시 고려사항
- 기본키의 유일성 관리가 어려워짐
- 분할된 테이블로 인해 수행속도가 느려질 수 있음
수평분할(Horizontal Partitioning)
레코드별로 사용 빈도의 차이가 큰 경우 사용 빈도에 따라 테이블을 분할한다
수직분할(Vertical Partitioning)
하나의 테이블에 속성이 너무 많을 경우 속성을 기준으로 테이블 분할
-
갱신 위주의 속성분할: 데이터 갱신 시 레코드 잠금으로 인해 다른 작업을 수행할 수 없으므로 갱신이 자주 일어나는 속성을 수직분할하여 사용
-
자주 조회되는 속성 분할: 테이블에서 자주 조회되는 속성이 극히 일부일 경우 자주 사용되는 속성들을 수직 분할하여 사용
-
크기가 큰 속성 분할: 이미지나 2GB이상 저장될 수 있는 텍스트 형식 등으로 된 속성들을 수직 분할하여 사용
-
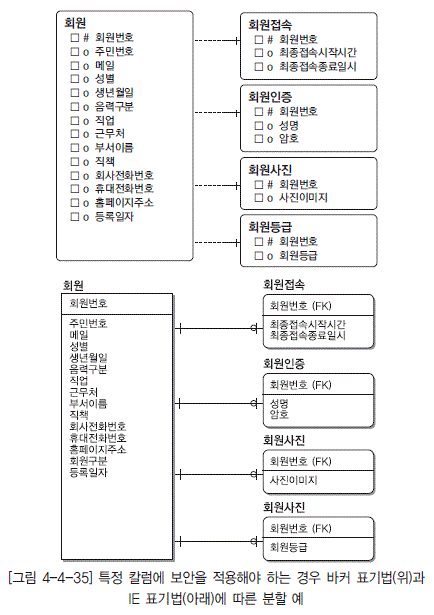
보안을 적용해야 하는 속성 분할: 테이블 내의 특정 속성에 대해 보안을 적용할 수 없으므로 보안을 적용해야 하는 속성들을 수직분할하여 사용한다
4. 중복 테이블 추가
여러 테이블에서 데이터를 추출해서 사용해야 하거나 다른 서버에 저장된 테이블을 이용해야 하는 경우 중복 테이블을 추가하여 작업의 효율성을 향상시킬 수 있다.
-
정규화로 인해 수행 속도가 느려지는 경우
-
많은 범위의 데이터를 자주 처리해야 하는 경우
-
특정 범위의 데이터만 자주 처리해야 하는 경우
-
처리 범위를 줄이지 않고도 수행 속도를 개선할 수 없는 경우
중복 테이블 추가 방법
-
집계 테이블의 추가 : 집계 데이터를 위한 테이블을 생성하고, 각 원본 테이블에 트리거(Trigger)를 설정하여 사용하는 것으로, 트리거의 오버헤드에 유의
-
진행 테이블의 추가 : 이력 관리 등의 목적으로 추가하는 테이블로, 적절한 데이터 양의 유지와 활용도를 높이기 위해 기본키를 적절히 설정
-
특정 부분만을 포함하는 테이블의 추가 : 데이터가 많은 테이블의 특정 부분만을 사용하는 경우 해당 부분만으로 새로운 테이블을 생성
5. 중복 속성 추가
조인해서 데이터를 처리할 때 데이터를 조회하는 경로를 단축하기 위해 자주 사용하는 속성을 하나 더 추가하는 것이다.
- 중복 속성을 추가하는 경우
- 조인이 자주 발생하는 속성인 경우
- 접근 경로가 복잡한 속성인 경우
- 액세스의 조건으로 자주 사용되는 속성인 경우
- 기본키의 형태가 적절하지 않거나 여러 개의 속성으로 구성된 경우
- 중복 속성 추가 시 고려사항
- 테이블 중복과 속성의 중복 고려
- 데이터 일관성 및 무결성에 유의
- SQL 그룹 함수를 이용하여 처리할 수 있어야 함
- 저장 공간의 지나친 낭비를 고려
