이번에 다룰 주제는 PostgreSQL에 고가용성 구축을 위한 Maser-Slave 구성에 대해서 얘기해보려고 한다.
pgpool
먼저 고가용성 시스템을 구축하기 위해서는 pgpool이라는 것을 알아야 되는데 간단하게 말해서 postgresql 서버와 클라이언트 사이에서 작동하는 미들웨어이다. 이를 사용하면 고가용성과 부하 분산이라는 두 가지 요구를 해결할 수 있다.
- 스케일 아웃 : 스케일 아웃은 한번쯤은 들어봤을 것이다 DB 서버를 여러대 추가하는 방식이다.
- Logical Replication : 데이터가 삽입, 수정, 삭제될 때 변경된 사항을 복제 서버에 전달하여 동기화한다.
주로 다중 리더(Multiple leader) 설정에서 유용하며, 특정 테이블 또는 데이터에 대해서만 복제를 할 수 있다.
- Streaming Replication : Streaming Replication은 데이터베이스의 물리적 변경 사항(Write-Ahead Logging, WAL)을 복제하여 실시간으로 동기화하는 방식이다.
- Logical Replication : 데이터가 삽입, 수정, 삭제될 때 변경된 사항을 복제 서버에 전달하여 동기화한다.
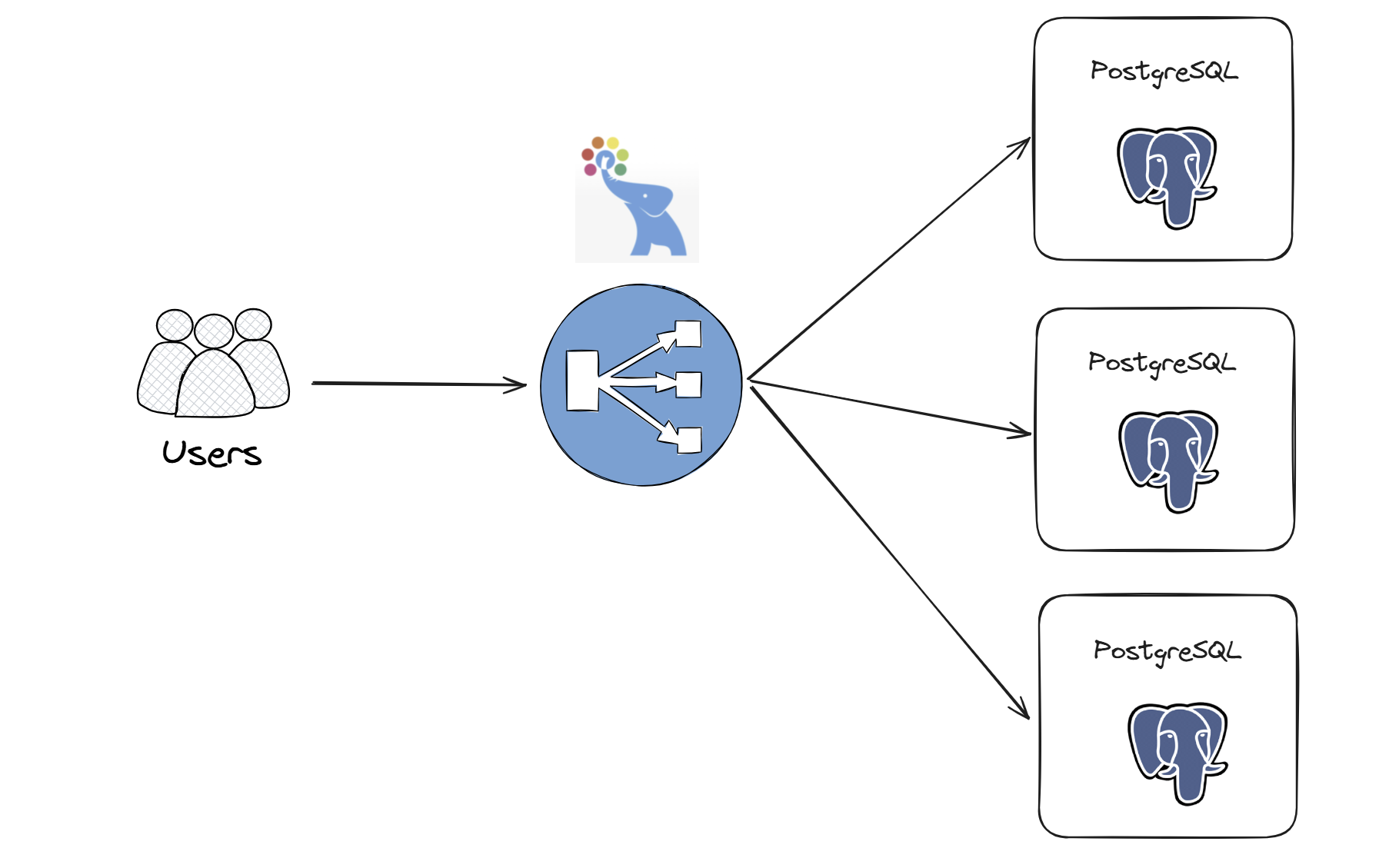
- 항상 쓰기는 마스터 서버로 이동하지만, 여러 서버에 걸쳐 선택의 균형을 맞추도록 pgpool 미들웨어 구성이 가능함
- 서버의 가중치를 할당해서 특정 서버에 얼마나 많은 부하를 보낼지 결정 가능(단 선택으로 실행되는 함수는 주의!)
pgpool에서 블랙 함수 목록을 조회하여 문제를 해결할 수 있다.
pgpool 기능
- 연결 풀링
DB 연결 획득에는 약간의 오버헤드가 있기 때문에 수천 개의 연결을 만들어야 하는 경우 연결을 재사용하는 것이 성능에 매우 중요하다.
- 기본적으로 동일한 속성을 가진 새 연결 요청이 들어올 때 연결을 줄인다. 또한 풀의 수와 풀의 연결 수를 조정하는 매개 변수가 있다.
연결 풀링만 제공하는 솔루션을 찾는다면 pgbouncer를 공부해보자.
-
Failover
기본 노드에서 장애가 감지되면 pgpool이 스크립트를 실행해서 장애를 처리할 수 있지만 스크립트를 작성해야 되지만, 대기 승격을 처리하는 방법을 결정할 수 있다. -
고가용성
pgpool은 자체적으로도 고가용성을 제공한다. 전체 시스템의 고가용성을 구현한다고 하면 pgpool 자체도 이중화해야 된다는 점! -
Watch dog
두 개 이상의 마스터 노드를 동시에 사용할 경우 스플릿 브레인이 발생한다. 이렇게 되면 각 노드는 서로 다른 정보를 갖게 되면서 클러스터의 데이터 불일치 현상이 발생한다.
위의 상황을 해결하기 위해서는 일관성과 가용성을 모두 보장하는 것은 어렵다 어느 한쪽을 우선 순위에 두느냐에 따라 다르다.
데이터 불일치 해결법
- 스트리밍 복제
데이터를 동기화한 다음 pgpool을 사용해서 로드밸런싱 및 자동 장애 조치를 수행하는 것이다. pgpool에서는 기본적으로 쓰기 요청은 기본 노드, 읽기 요청은 복제본으로 보내도록 구성이 가능하다.
Pgpool 복제도 좋은 기능이었지만, 이제 Streaming 복제가 PostgreSQL에 내장되어 있어 이를 사용하는 것이 좋다.
(부작용이나 잠재적인 문제에 대해 걱정 안해도 되기 때문에)
우선 작업
- PostgreSQL Streaming 복제
1-1. SQL 인스턴스를 기본 노드로 만들기
- postgresql 설치에 포함된 initdb 명령 도구를 활용하자!!
initdb -D /tmp/primary_db1-2. 복제를 위한 기본 서버를 미리 구성
/tmp/primary_db/postgresql.conf위 경로에 들어가서 listen_address = "*" 이 설정을 찾아서 주석을 해제하고 자신이 접속하는 서버에 IP 주소를 할당하자!
port = 5433를 찾아서 포트 충돌이 일어나지 않도록 수정하자
(로컬)쿠버네티스의 경우 쿠버네티스가 할당하는 IP를 찾아서 바꿔주도록 하자. 보통은 파드가 여러 개가 띄워지고 파드가 계속 재시작이 될 경우 IP주소가 바뀌니까 고정 IP로 설정하고 진행하면 될 것 같다.
pg_ctl -D /tmp/primary_db -l logfile start그러면 성공적으로 5433 포트에서 시작된 서버를 확인할 수 있다.
- 스트리밍 복제에 대한 전체 프레젠테이션이 실패하는 경우 복제 서버를 기본 서버로 승격할 수 있다.
1-3. 복제를 위한 별도의 사용자 만들기
psql --port=5433 (mydatabase)먼저 우리가 만들었던 primary_db에 접속하고
create user repli replication;새로운 사용자를 만들자.
/tmp/primary_db/pg_hpa.conf위의 경로에 접속해서 설정을 수정해줘야 되는데 host all all 127.0.0.1/32 trust를 복사해서
host all all 127.0.0.1/32 trust
host all repli 127.0.0.1/32 trust이런 느낌으로 새로운 사용자로 대체하자.
pg_ctl -D /tmp/primary_db restart이제 다시 서버를 시작해주면 된다.
1-4. pg-basebackup 만들기
pg_basebackup -h localhost -U repli --checkpoint=fast -D /tmp/replication_db/ -R --slot=some_name -C --port=5433- localhost에 복제를 하며 아까 새로 추가한 사용자로 복제를 진행
- fast는 즉각적인 체크포인트를 요청하여 데이터의 최신 상태를 복제
- -R은 standby.signal이러한 파일을 생성하여 기본 서버에서 변경 사항을 따라가도록 설정
- --slot=some_name은 WAL 파일을 관리하는 장소
- -C은 새 복제 슬롯을 생성하는 옵션 --slot와 같이 쓰임
1-5. 포트 충돌을 피하기 위해서 복제본의 포트 변경
/tmp/replication_db/postgresql.conf위의 경로에 들어가서 Port=5434 포트를 수정하자.
pg_ctl -D /tmp/replication_db start복제본을 시작하자. 복제본은 이제 읽기 전용 대기 모드이고 스트리밍 복제는 정상적으로 진행되고 있음을 확인할 수 있다.
- 로드 밸런싱 읽기/쓰기 분리 및 자동 장애 초지 설정
2-1. pgpool 설치
brew install pgpool-ii먼저 pgpool을 설치하자
cd /usr/local/etc
cp pgpool.conf.sample pgpool.conf복사를 하고 나면 편집을 할 수 있다.
2-2. pgpool 설정파일 수정
- listen_address = '*' 주소를 바꿔주자.
- port=9999 이는 그대로 사용하자.
- backend_hostname0 = 'localhost' 마스터 서버 주소로 바꿔주자.
- backend_port0 = 5433 기본 인스턴스를 시작한 이후
- backend_weight = 0 기본 쿼리 값을 0으로 셋팅
=> 그러면 선택쿼리가 항상 대기쿼리로 이동한다는 의미 - backend_data_directory0 = '/tmp/primary_db/'
-> 백엔드 DB가 있는 디렉터리를 기본 DB에 설정
이제 복제본을 수정
-
backend_hostname0 = 'localhost' 대기 서버 주소로 바꿔주자.
-
backend_port0 = 5434 기본 인스턴스를 시작한 이후
-
backend_weight = 1 기본 쿼리 값을 1으로 셋팅
=> 그러면 선택쿼리가 항상 대기쿼리로 이동한다는 의미 -
backend_data_directory0 = '/tmp/replication_db/'
-> 백엔드 DB가 있는 디렉터리를 기본 DB에 설정 -
log_statement = on
-
log_per_node_statement = on 노드당 로그 문도 검색
=> 이러한 변경사항을 저장하려면 프로덕션에서 로그를 꺼야 되며 피드 파일 이름도 변경해야된다. -
pid_file_name = 'pgpool.pid'
-
sr_check_user = 'repli' 사용자 이름도 변경해주자
-
health-check_period = 10 10초마다 서버가 살아있는지 확인
-
health_check_user = 'repli' 사용자 수정
이제 저장하고 끄자
- 로드밸런싱과 db 테스트
etc 경로에서 pgpool을 하게 되면 백그라운드에서 그냥 실행만 됨 로그 안뜸pgpool -n &로그를 확인하고 primary node와 standby node가 정상적으로 실행되고 있는지 확인하자
분산 시스템에 있어서 문제
- Master 손실 시 장애 조치(Failover) 과정에서 데이터 손실 방지를 위한 복구 방안이 필요하다.
- 아직 동기화되지 않은 커밋된 트랜잭션이 손실될 수 있으며, 이를 처리하거나 복구가 완료될 때까지 기다려야 한다.
- 동기식 복제를 사용하여 데이터 손실을 방지할 수 있지만, 성능 저하 및 높은 비용이 수반될 수 있다.
Primary_db 구성 파일 수정
nano /tmp/primary_db/postgresql.conf- synchronous_commit = remote_apply 원격 적용으로 수정
-> 원격 적용이란? : 기본적으로 쓰기 요청은 대기 복제본이 트랜잭션의 커밋 레코드를 수신할 때까지 기다리고 마지막 커밋이 대기의 쿼리에 표시 - synchronous_standby_names = '*' 동기 대기 이름 매개변수를 사용해서 동기화되는 복제본도 지정해야 된다. 여기에서 가능한 모든 복제본을 선택한다.
- wal_log_hints = on 약간의 성능 오버헤드를 가져온다
-> 실패한 마스터를 다시 가져오려는 경우에 이를 설정해야 된다.
pg_ctl -D /tmp/primary_db restart그리고 이제 서버를 다시 시작한다.
FailOver
장애 조치를 하기 위해 스크립트 파일을 작성해야된다.
nano /tmp/pgsql/failover.shfailed_node=$1
trigger_file=$2
if [ $failed_node = 1 ];
then exit 0;
fi
touch $trigger_file
exit 0;위와 같이 스크립트를 작성하자. 위 스크립트는 기본 노드가 실패가 되면 이 스크립트가 실행된다.
장애가 발생한 노드가 1번 노드가 보조 노드인지 기본 노드인지 확인하고 대기 실패를 처리하고 싶지 않으면 종료
trigger_file이 보조노드에 의해 발견될 경우 touch 명령을 이용해 파일을 트리거하면 스트리밍 복제가 종료되고 대기가 승격되서 마스터노드가 된다.
nano /usr/local/etc/pgpool.conf- failover_command = '/tmp/pgsql/failover.sh %d /tmp/replication_db/down.trg' 뒤는 트리거 파일 경로다.
replication_db 설정파일 수정
nano /tmp/replication_db/postgresql.conf- promote_trigger_file = '/tmp/replication_db/down.trg' 이것은 pgpool이 노드 오류를 감지할 때마다 대기 모드에서 복구를 종료하는 파일 이름이다.
pg_ctl -D /tmp/replication_db restart이제 다시 서버를 재시작하자.
마무리
- pgpool이 master_node가 down됨을 인지
- failover 스크립트가 실행
- failover 스크립트는 트리커 파일을 복제본에 생성한다.
- postgresql 복제본에서 트리거 파일로 접근한다.
- 복제본이 read/write모드가 되고 완전한 복구가 된다.
마지막으로 해결해야될 문제, 장애 복구(Failback)
일부에서 master_node를 사용할 수 없다고 가정하자.
1. 초기 상태 :
- node0이 마스터 노드로 설정되어 있고, 모든 트랜잭션과 쓰기 작업을 담당하고 있었다.
- node1은 보조 노드로 설정되어 읽기 작업을 주로 수행하고, 복제된 데이터의 백업 역할을 한다.
- 문제 발생 :
- 네트워크 문제로 인해 node0 (마스터 노드)와의 연결이 끊어졌다.
- 이로 인해 pgpool은 node0을 사용할 수 없다고 판단하고, 대신 node1을 새로운 마스터로 승격하여 작업을 수행하도록 전환(failover)한다.
- 이 상태에서 node1이 임시로 마스터 역할을 맡는다.
- 문제 해결 후 node0 복구 :
- 네트워크 문제가 해결되어 node0이 다시 연결되었지만, 현재 node1이 마스터 역할을 수행하고 있다.
- 이 시점에서 node0은 최신 상태가 아니다. 장애가 발생한 동안의 모든 쓰기 작업이 node1에서 이루어졌기 때문에 node0은 누락된 트랜잭션을 포함하지 않는다.
- 장애 복구(Failback):
- pgpool 미들웨어를 통해 원래 마스터 노드였던 node0을 복구하는 작업을 수행해야 된다.
- node0을 복구하기 위해서는 node1에 있는 모든 최신 데이터를 node0으로 동기화하고, 그 후에 node0을 다시 마스터로 지정해야 한다.
- pgpool에서는 이 과정에서 -d 옵션을 사용하여, pgpool을 다시 시작하고 node0을 마스터로 복구할 수 있다.
[참고문서]
https://www.youtube.com/watch?v=qpxKlH7DBjU&list=PLBrWqg4Ny6vVwwrxjgEtJgdreMVbWkBz0
