kotlin + jpa (2)는 우아한 기술블로그 - 코틀린에서 하이버네이트를 사용할 수 있을까? 를 읽고 따라해보며 다시 한번 정리해보는 글이다.
해당 글은 공식 문서를 기반으로 작성되어 기본적인 부분들이 잘 나타나있다고 느꼈고, 처음부터 따라해보며 체득하고 싶어져 따라한 뒤 정리하게 되었다.
(너무 똑같아서 문제가 된다면 지우겠습니다.)
1. (Kotlin) data class
- 코틀린에서 매력적인 클래스인 data class라는 것이 있다.
해당 클래스는 기본적으로 toString(), equals(), hashCode() 같은 함수들을 컴파일러가 대신 만들어준다. (직접 구현해서도 사용할 수 있다.)- 인스턴스 복사해주는 copy() 함수와 destructuring 등을 제공한다.
destructuring
인스턴스의 프로퍼티를 한 번에 가져올 수 있기 때문에 여러 프로퍼티의 값을 읽어올 때 편하다.
data class Person(
val name: String,
val age: Int,
)
fun main() {
val person = Person("kdh", 92)
val (name, age) = person
println(name) // "kdh" == person.name
println(age) // 92 == person.age
}- 구조화된 배열 or 객체를 개별적인 변수에 할당하는 것을 의미한다.
- 생성자의 프로퍼티를 기반으로 생성되기 때문에 장단점이 발생할 수 있다.
2. Hibernate (+ data class)
- Hibernate + data class 이용 시 기본으로 포함하는 함수로 인해 문제 발생
- toString() 메서드로 인해 연관 관계 매핑된 엔티티에 접근할 때 lazy loading exception이 발생
- 양방향 매핑으로 인한 stack overflow 발생
- data class를 사용하더라도 toString(), equals(), hashCode() 함수를 직접 구현해야 한다.
- data class가 아닌 일반 class를 사용하더라도 위 함수는 직접 구현해줘야 한다.
- 직접 구현해야한다면 굳이 data class를 쓸 이유가 없다.
data class를 이용해 엔티티 구현
Hibernate에서는 Reflection을 사용해 엔티티를 만들게 되는데 그 때 인자가 없는 기본 생성자(no-arg)가 필요해서 기본 생성자를 추가로 선언해야한다.
// Company 샘플 코드
@Entity
data class Company(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null,
var name: String
) {
constructor() : this(null, "")
}
// Employee 샘플 코드
@Entity
data class Employee(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null,
var name: String,
@ManyToOne(fetch = FetchType.LAZY)
var company: Company?
) {
constructor() : this(null, "", null)
}data class로 Entity 클래스 작성 시 프록시 객체 문제
FetchType.LAZY로 설정하여 fetch join으로 함께 조회하지 않은 데이터는 프록시 객체를 가져와야한다.
// sql query (or Test given)
INSERT INTO company (name) VALUES('test-company');
INSERT INTO employee (name, company_id) VALUES ('kdh', 1L);
// EmployeeJpaRepository - findById() Test
@Test
internal fun findById() {
// when
val employee: Employee? = employeeJpaRepository.findByIdOrNull(1L)
// then
assertEquals(employee!!.id, 1L) // break point
assertEquals(employee.name, "kdh")
}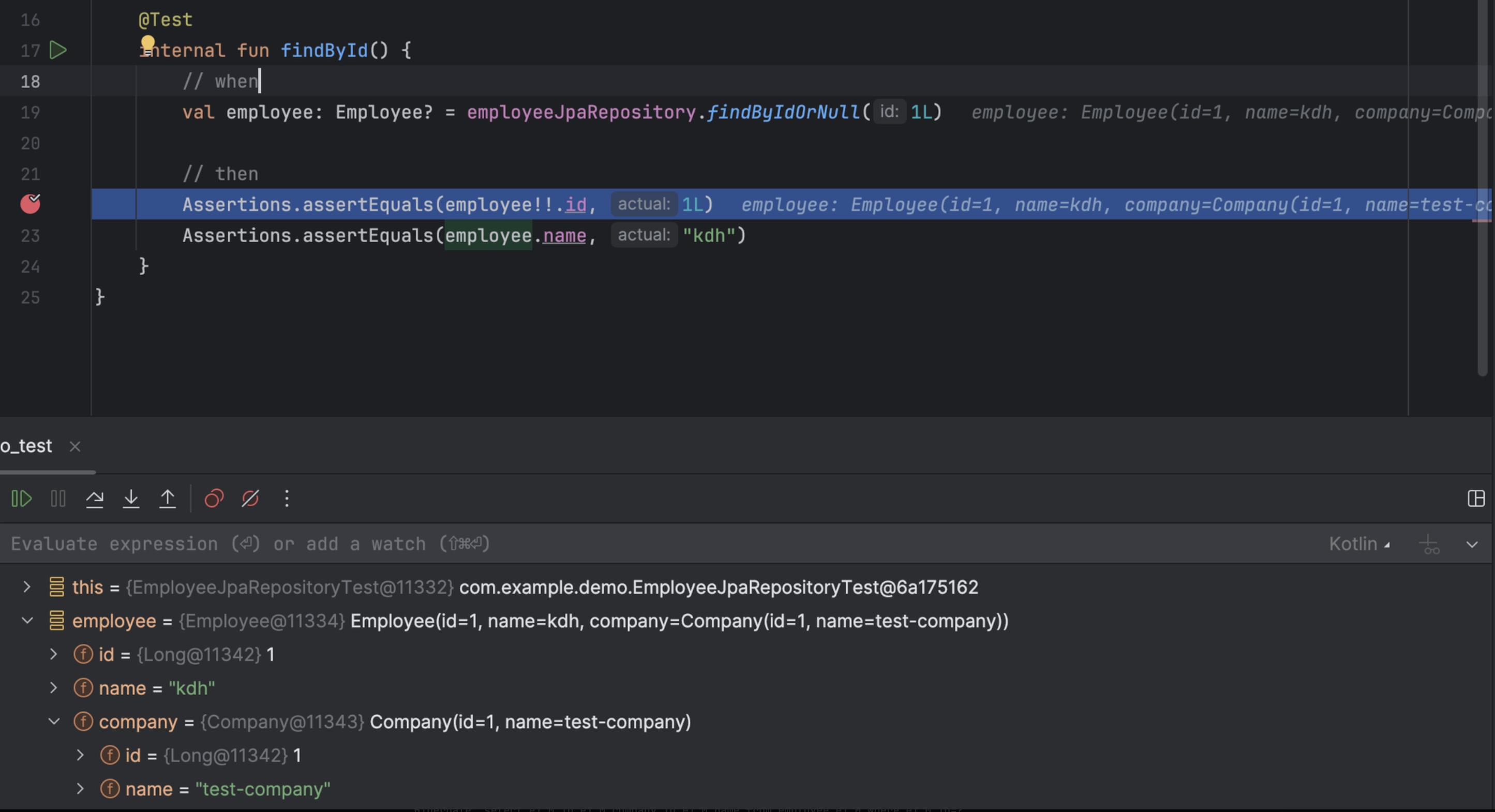
- Employee Entity는 company를 FetchType.LAZY로 설정하여 실제 사용할 때 조회하지만 employee.company에 프록시 객체가 아닌 실제 객체가 존재했다.
- employee만 조회하더라도 company 조회까지 총 2개의 조회가 발생하게 된다.

왜 그럴까?
The Java EE 5 Tutorial & Hibernate 문서에 Entity class의 요구사항이 나와있다.
Requirements for Entity Classes
An entity class must follow these requirements:
• The class must not be declared final. No methods or persistent instance variables must be declared final.Hibernate, however, is not as strict in its requirements. The differences from the list above include:
• Technically Hibernate can persist final classes or classes with final persistent state accessor (getter/setter) methods. However, it is generally not a good idea as doing so will stop Hibernate from being able to generate proxies for lazy-loading the entity.
- Entity class 요구사항에는 반드시 final로 선언하게 되어 있다.
- Entity class가 final이면 동작하지 않는 것은 아니다.
- Entity class를 final로 할 수는 있지만, lazy loading을 위한 프록시를 생성할 수 없을 뿐이다.
(= lazy loading을 제대로 사용하기 위해서는 Entity class는 final이 아니고 open 키워드를 추가로 붙여줘야 한다.)- 코틀린의 클래스와 프로퍼티, 함수는 기본적으로 final이며 상속이 불가능하다. (상속하기 위해서는 open 키워드를 사용해야 한다.)
- 클래스에 open 키워드를 붙이더라도 해당 클래스의 프로퍼티와 함수에도 상속을 허용하는 open 키워드를 별도로 추가해줘야 한다.
(spring boot kotlin tutorial allopen 플러그인을 사용하는 것을 권장한다.)- data class는 open 키워드를 추가할 수 없다.
Hibernate의 Lazy Loading을 사용하기 위해서는 Entity class에 Data class를 사용할 수 없다.
3. Hibernate (+ 일반 class)
일반 class를 사용한 Entity에는 open 키워드와 no-arg constructor가 필요하다. 이 작업은 Entity에 반복적으로 추가해줘야하는데 allopen, noarg 플러그인을 통해 자동적으로 추가할 수 있다.
// build.gradle.kts
plugins {
...
kotlin("jvm") version "1.x.x"
kotlin("plugin.allopen") version "1.x.x" // 추가
kotlin("plugin.noarg") version "1.x.x" // 추가
}
// allOpen 추가
allOpen {
annotation("javax.persistence.Entity")
}
// noArg 추가
noArg {
annotation("javax.persistence.Entity")
}- noArg 추가로 기존에 추가한 빈 생성자를 제거할 수 있다.
// Company 샘플 코드
@Entity
class Company(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null,
var name: String
)
// Employee 샘플 코드
@Entity
class Employee(
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
var id: Long? = null,
var name: String,
@ManyToOne(fetch = FetchType.LAZY)
var company: Company?
)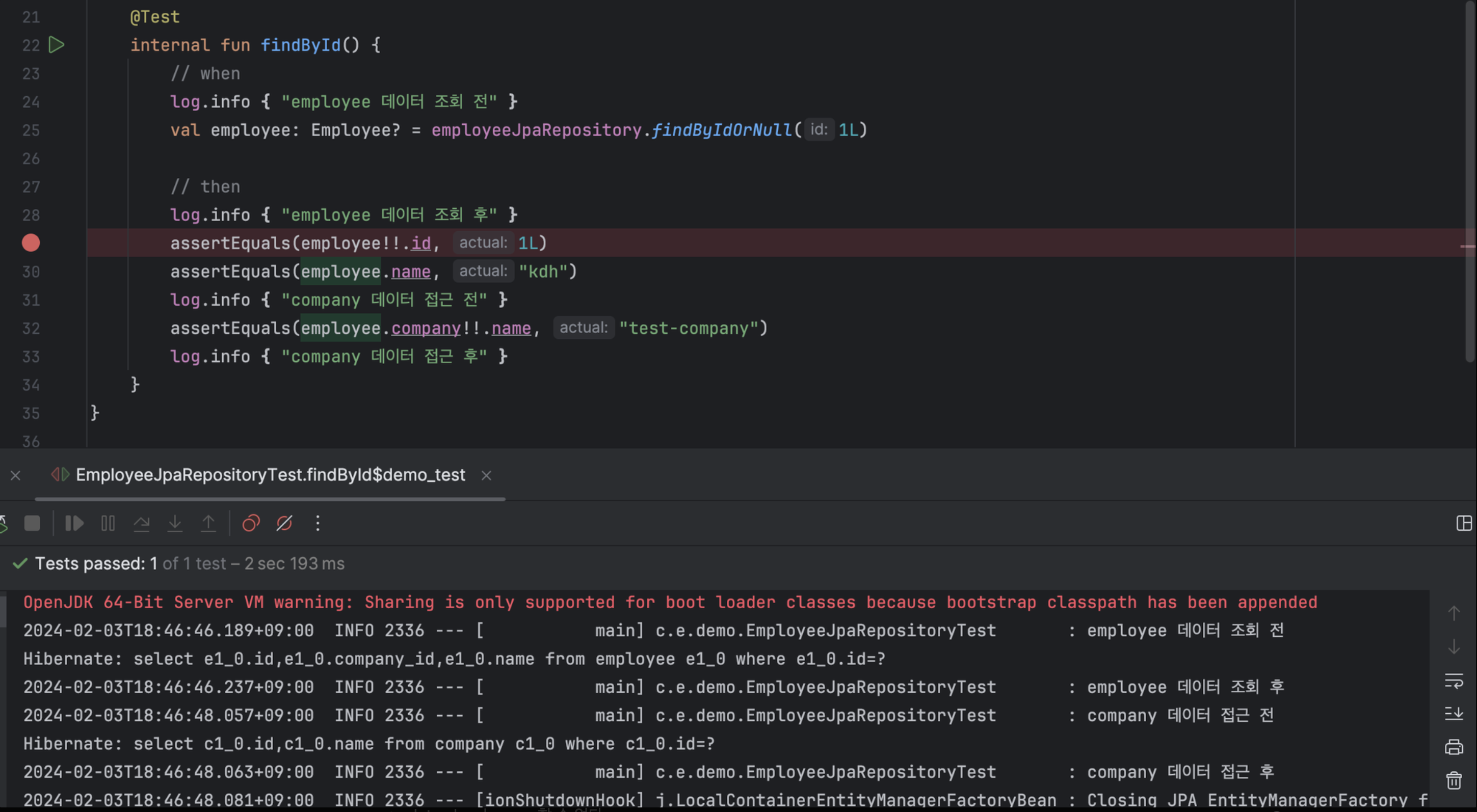
- log를 사용하여 lazy loading 동작될 경우 company 객체가 언제 조회되는지 볼 수 있다.
결론
- Hibernate에서 Entity 클래스는 final일 수 있지만, final로 된 class는 lazy loading을 위한 프록시를 생성할 수 없다.
- data class는 open할 수 없다.
(allopen 플러그인을 이용하면 data class도 open할 수 있지만 추천하지 않는다.)
(번외. 추천 X) data class에 allopen 플러그인 사용
data class에 jpa 플러그인과 allOpen 사용하면 어떻게 될까?
(jpa 플로그인 대신 allOpen, noArg를 추가해도 된다.)
// build.gradle.kts
plugins {
...
kotlin("jvm") version "1.x.x"
kotlin("plugin.spring") version "1.x.x"
kotlin("plugin.jpa") version "1.x.x" // 추가
}
// allOpen 전체 추가
allOpen {
annotation("jakarta.persistence.Entity")
annotation("jakarta.persistence.Embeddable")
annotation("jakarta.persistence.MappedSuperclass")
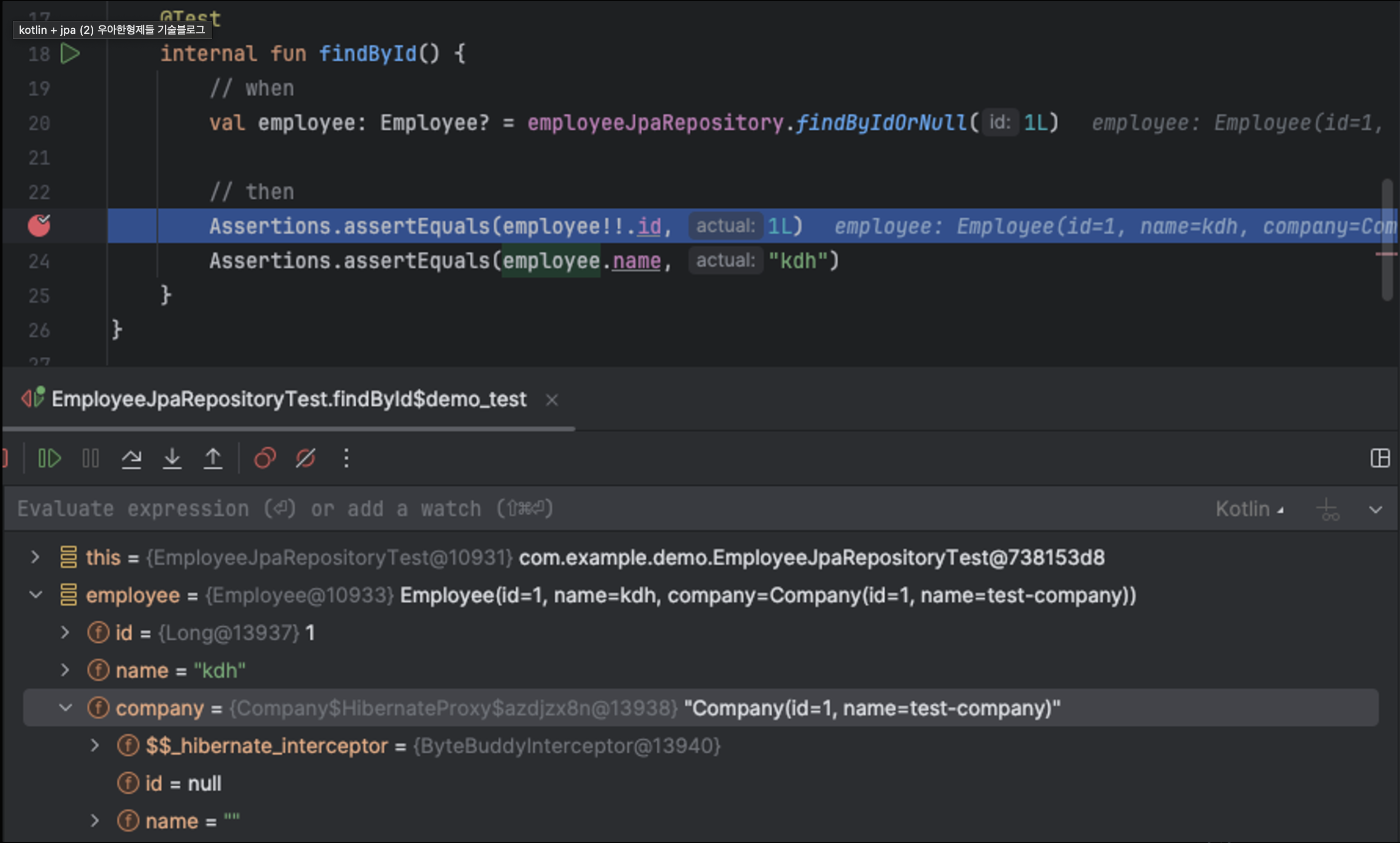
}
-
company 객체만 봤을 때는 HibernateProxy가 들어가서 data class를 쓰더라도 allOpen 플러그인을 쓰면 되는 것처럼 보인다.
-
하지만 중요한 것은 쿼리가 어떻게 발생하는지 보는 것이 중요하다.

-
company 객체에 {Company@HibernateProxy$
@}로 존재하지만 쿼리는 기존과 동일하게 2번 발생하게 된다.
chatGpt에 allOpen 키워드와 HibernateProxy 관계에 대해 검색
- allOpen 키워드 - AspectJ의
@Aspect애노테이션을 사용한 클래스에 적용되어 모든 클래스 및 메소드에 AspectJ의 프록시를 활성화한다.- 특정 어노테이션을 가진 Kotlin 클래스에 Aspect를 적용하도록 한다.
allOpen키워드를 사용하면 AspectJ가 특정 어노테이션이 지정된 Kotlin 클래스에 애스펙트를 적용할 수 있다.- Hibernate에서는 프록시 객체를 사용하여 지연 로딩을 구현하고, 연관된 엔티티에 대한 프록시를 생성한다.
allOpen키워드를 사용하면 Kotlin 클래스가 AspectJ에 의해 열리게 되어, AspectJ 애스펙트가 해당 클래스의 메소드 호출 등을 감시할 수 있다.- 따라서 Hibernate의
HibernateProxy가 필요한 경우, AspectJ가allOpen을 사용한 Kotlin 클래스를 열어놓고 애스펙트를 적용하여 해당 클래스의 동작을 확장할 수 있게 됩니다.
결론
Entity 클래스를 data class로 선언하고 allOpen 플러그인을 설정하면 원하는 지연 로딩 결과를 만들어낼 수 있다.
- 하지만 이 방법은 반쪽 짜리 방법일 수 밖에 없다고 생각한다.
- Lazy loading을 사용하는 이유는 불필요한 조회(연관 엔티티)를 하지 않기 위해 쓰는데 위 방식은 불필요한 조회를 한 뒤 Proxy 객체를 주입하는 과정으로 예상된다.
- Proxy 객체가 존재하는 것처럼 보이지만 실제로는 사용하지 않는 객체에 대해 쿼리 조회가 발생한다.

조회 후 aspect에 의해서 company에 프록시 객체가 들어간 것으로 예상된다.
위 결론은 개인적인 추측으로 정확하지 않기 때문에 정확한 답을 찾아 수정할 예정으로 참고만 하시길 추천드립니다.
이 글은 해당 내용을 위주로 정보를 찾아 쓴 글이 아닌 우아한 기술블로그를 읽고 따라하며 정리한 글입니다.
