
📙 Index란?

DB에서 Index는 데이터베이스 내에서 데이터의 검색 속도를 향상시키기 위해 사용되는 데이터 구조입니다.
일반적으로 데이터베이스 테이블은 행(row)으로 구성되어 있으며, 특정 컬럼(column)을 기준으로 데이터를 검색하고 정렬하는 경우가 많습니다. 그러나 많은 양의 데이터가 있는 경우 전체 테이블을 순차적으로 검색하는 것은 비효율적입니다.
📙 사용하는 이유?
이 때문에 Index가 사용됩니다. Index는 특정 컬럼(column)의 값과 해당 값이 저장된 행(row)의 위치를 매핑하여 빠른 검색을 가능하게 합니다. 인덱스는 일종의 색인이며, 데이터베이스 시스템이 데이터를 검색할 때 인덱스를 참고하여 검색 성능을 향상시킵니다
📙 Index의 구조?
Index는 일반적으로 B-Tree나 B+Tree와 같은 트리 기반 자료구조를 사용합니다.
📚 B-TREE란?
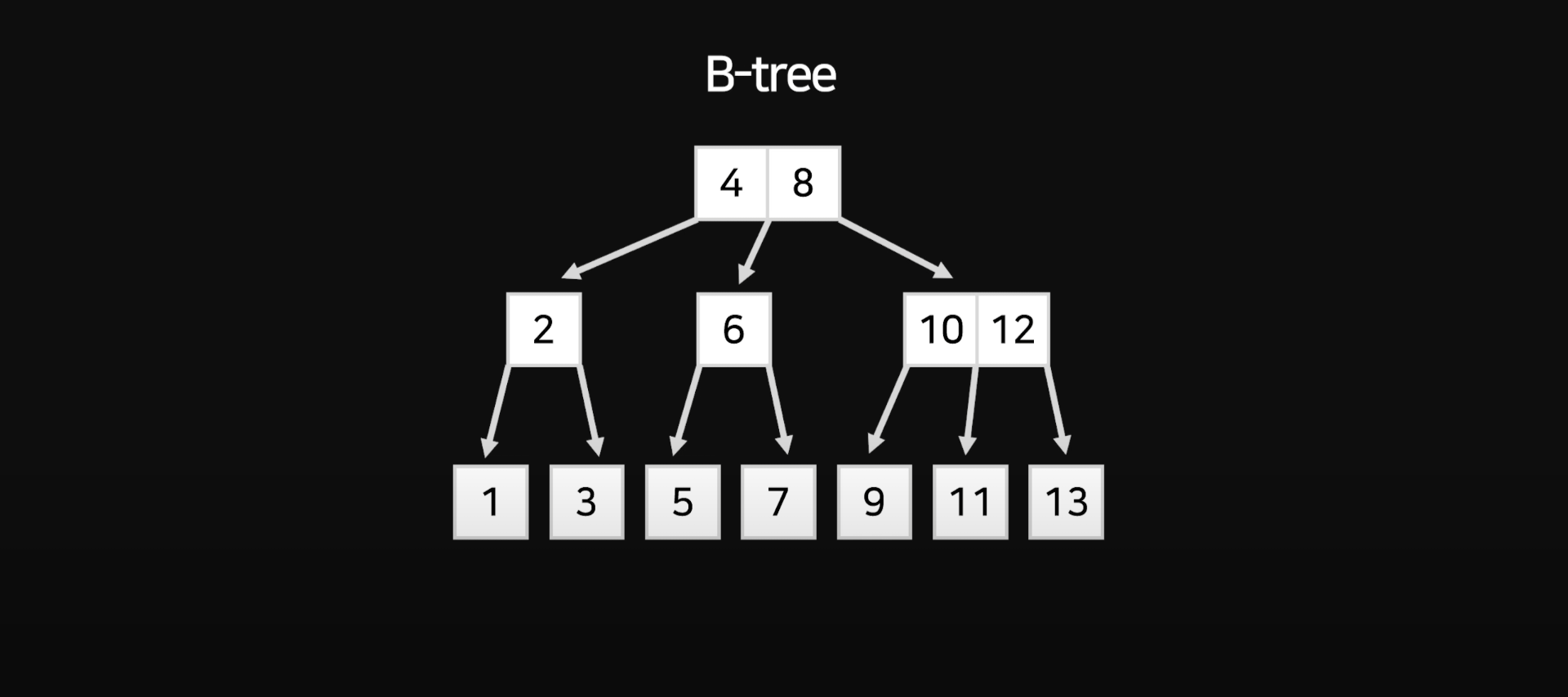
B-Tree는 데이터의 검색 및 삽입, 삭제 작업에 효율적인 성능을 제공하는 트리 기반의 자료구조입니다.
B-Tree는 균형 트리로, 각 노드에는 여러 개의 키와 데이터 위치 정보가 저장되며, 키는 정렬된 상태로 저장됩니다. B-Tree는 다단계 인덱스를 구성하여 데이터를 효율적으로 검색하고 관리합니다. 이를 통해 대량의 데이터를 빠르게 처리할 수 있습니다.
📚 B+ TREE란?
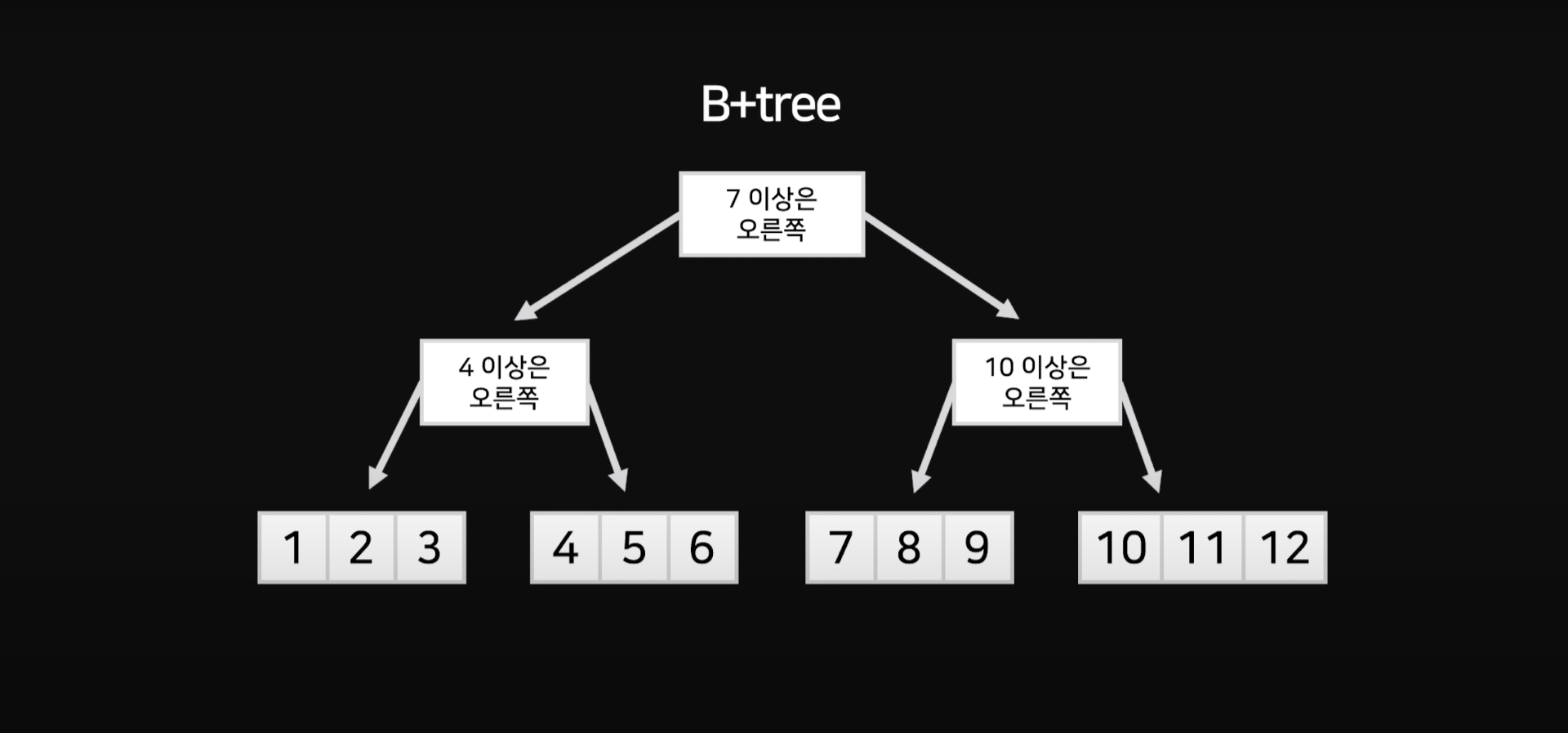
B+ Tree는 B-Tree의 변형된 형태로, 트리 기반의 자료구조입니다. B+ Tree는 B-Tree의 특징을 유지하지만 몇 가지 차이점을 갖습니다.
B+ Tree는 B-Tree와 달리 리프 노드만이 실제 데이터를 가지고 있으므로, 데이터베이스에서 범위 검색이나 순차적 접근을 더욱 효율적으로 수행할 수 있습니다. 또한, B+ Tree의 리프 노드들은 연결 리스트로 구성되어 데이터의 순차 접근이 가능하며, 범위 검색 시 효율적인 I/O 작업을 지원합니다.
📙 단점은 없을까?
Index의 사용은 데이터베이스 성능을 향상시키는 데 매우 유용하지만, 몇 가지 단점도 있습니다.
-
추가 공간 요구: 인덱스는 데이터베이스의 원본 데이터와 별도로 유지되어야 합니다. 따라서 인덱스를 생성하면 추가적인 공간이 필요하게 됩니다.
-
업데이트 성능 저하: 인덱스를 유지하려면 데이터의 삽입, 갱신, 삭제 작업이 발생할 때마다 인덱스도 함께 업데이트되어야 합니다. 따라서 데이터 변경 작업이 빈번하게 발생하는 경우, 인덱스 업데이트에 따른 성능 저하가 발생할 수 있습니다.
📙 MariaDB vs MongoDB
Index를 공부하면서 프로젝트에서 주로 사용하는 MariaDB와 MongoDB는 Index를 어떠한 자료구조에 저장하는지 궁금해서 알아보았습니다.
📚 MariaDB
MariaDB는 B+ Tree를 사용합니다.
-
범위 검색에 효율적: B+ Tree는 모든 값들이 리프 노드에 위치해 있고 인접한 키들이 인접한 리프 노드에 저장되어 있어 데이터의 효율적인 범위 검색이 가능합니다. SQL 기반의 데이터베이스 시스템에서 자주 발생하는 범위 기반의 쿼리를 처리할 때 매우 효율적입니다.
-
정렬된 저장: B+ Tree는 내부 노드에서 키를 정렬된 상태로 저장합니다. 이는 이진 탐색(binary search)을 사용하여 효율적인 검색을 가능하게 합니다.
-
다단계 인덱스 구성 가능: B+ Tree는 다단계 인덱스(Multi-level Index)를 구성할 수 있습니다. 이는 인덱스의 여러 단계를 거치는 구조로, 대용량 데이터베이스에서 많은 양의 데이터를 효율적으로 관리할 수 있도록 합니다.
-
동시성과 병행성 지원: B+ Tree는 여러 개의 리프 노드가 있기 때문에 동시성과 병행성을 지원하기에 적합합니다. 여러 개의 스레드나 트랜잭션이 동시에 인덱스에 접근하더라도 충돌을 최소화하고 효율적인 동시성을 유지할 수 있습니다.
-
널 값 처리: B+ Tree는 널 값을 처리하기 위한 추가적인 링크나 포인터를 제공합니다. 이는 NULL 값을 가지는 열을 검색하거나 필터링하는 경우에도 효율적인 인덱스 스캔을 가능하게 합니다.
📚 MongoDB
MongoDB는 B-tree를 사용합니다.
-
-유연한 데이터 모델: MongoDB는 JSON 형식의 문서를 사용하여 데이터를 저장하고 관리합니다. B-Tree는 동일한 노드에 여러 값을 저장할 수 있는 특성을 가지고 있어 다양한 형태와 크기의 문서 데이터를 유연하게 다룰 수 있고 문서 내부의 다양한 데이터를 효율적으로 관리할 수 있습니다.
-
단순한 검색, 삽입, 삭제 작업에 효율적: B-Tree는 단순한 검색, 삽입, 삭제 작업에 뛰어난 성능을 보입니다. MongoDB는 빠른 단일 문서 검색에 중점을 두고 있으며, B-Tree는 이러한 단일 문서에 대한 빠른 접근을 제공합니다.
-
데이터 정렬: B-Tree는 내부 노드에서 키를 정렬된 상태로 저장합니다. 이는 이진 탐색(binary search)을 사용하여 효율적인 검색을 가능하게 합니다.
-
다단계 인덱스 구성 가능: B-Tree는 다단계 인덱스(Multi-level Index)를 구성할 수 있습니다. 이는 인덱스의 여러 단계를 거치는 구조로, 대용량 데이터베이스에서 많은 양의 데이터를 효율적으로 관리할 수 있도록 합니다.
-
동시성과 병행성 지원: B-Tree는 여러 개의 리프 노드가 있기 때문에 동시성과 병행성을 지원하기에 적합합니다. 여러 개의 스레드나 트랜잭션이 동시에 인덱스에 접근하더라도 충돌을 최소화하고 효율적인 동시성을 유지할 수 있습니다.
📚 요약
MariaDB는 B+ Tree를 선택하여 데이터의 검색과 정렬, 다단계 인덱스, 동시성 및 병행성 지원 등을 효과적으로 처리할 수 있습니다.
그리고 범위 기반의 쿼리를 처리에 중점을 두고 있습니다..
MongoDB는 B-Tree를 선택하여 유연한 데이터 모델에 맞는 검색, 삽입, 삭제 작업, 데이터 정렬, 다단계 인덱스 구성 및 동시성 지원 등을 효과적으로 처리할 수 있습니다.
그리고 빠른 단일 문서 검색에 중점을 두고 있습니다.
😊긴글 읽어주셔서 감사합니다. 좋은 하루 되세요😊
출처-애플코딩[Index]
