0. 들어가며
- 현재 상황
- AWS MSK Cluster를 사용
- Kafka Connect는 ECS 서비스로 띄워서 사용
- kafka Connector들에 대한 설정 파일들을 따로 관리
- AWS MSK Connect를 조사해보고 관리하기 용이한지, 가격은 어느정도 되는지 등을 살펴보자.
1. MSK Connect란?
- 2021년 9월 16일에 출시되었다.
- Kafka Cluster와 외부 데이터 소스(DB, 검색엔진, 파일 시스템 등)를 연결, 별도의 코드 작성없이 데이터를 쉽게 스트리밍 할 수 있게 도와준다.
- 관리형 서비스로 사용량만큼 비용이 지불된다.
- 부하에 따라 connector를 오토스케일링 할 수 있다.
- 필요 시 AWS SSM을 이용하여 설정값들을 따로 관리할 수 있다.
- Kafka 공식 connector가 아닌 Debezium과 같이 오픈 소스로 개발된 connector를 사용할 수도 있다.
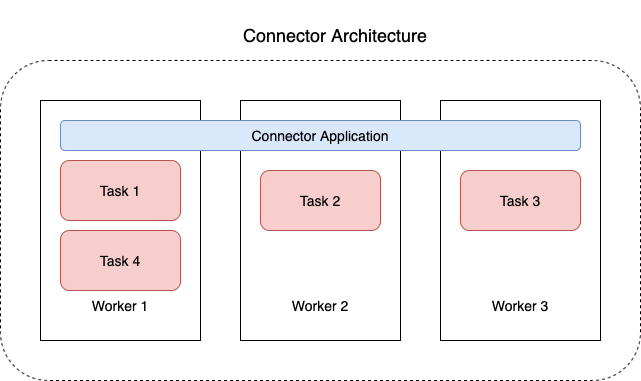
1.1 Plugin
- Connector 로직을 정의하는 코드를 포함한 리소스
- 플러그인 JAR파일(혹은 JAR를 포함하고 있는 ZIP 파일)을 S3 버킷에 업로드 한 뒤, MSK Connect에서 커스텀 플러그인을 생성할 때에 사용한다.
- Kafka Cluster와의 메시지 송수신, 그리고 어떤 데이터 소스냐에 따라서, 사용하는 플러그인이 달라진다.
- 어떤 데이터 소스 → Kafka Cluster → S3로의 메시지 전달이 필요한 경우, S3 Sink Connector가 필요하다.
- List of available Apache Kafka Connect connectors
1.2 Connector
- 데이터 소스와 Kafka Cluster 사이에 데이터를 송수신한다.
- 데이터를 전달할 때에 포맷 변환 혹은 필터링을 적용할 수 있다.
- 플러그인이 이미 S3에 업로드된 상태여야 생성할 수 있다.
1.2.1 Connector Capacity
- Connector의 용량은 Worker의 개수와 Worker 당 MSK Connect Units(MCUs)에 의존성이 있다.
- 각 MCU는 vCPU 1개와 4GB 메모리를 제공하며, Connector를 생성하기 위해서는 두 가지 모드(Provisioned Mode or Autoscaled Mode) 중 하나를 선택해야한다.
1.2.2 Provisioned Mode
- Connector 사용량이 일정한 경우 선택
- Worker와 MCU를 직접 정의한다.
1.2.3 Autoscaled Mode
- Connector 사용량이 예측 불가능한 경우 선택
- MSK Connect가 tasks.max 속성 값을 재정의하는 방식으로 Worker, MCU를 조정한다.
- 최소/최대 Worker는 정의해야한다.
- CPU 사용량에 따라 Autoscale 동작이 진행되므로, CPU 지표에 따른 스케일인/스케일아웃 퍼센테이지 정의 필요
- Worker당 MCU가 정의되어야한다.
1.3 Worker
- Connector 로직을 실행하는 JVM 프로세스
- Worker는 병렬 스레드에서 실행되는 Task를 생성하고, 데이터를 복사(송수신)하는 작업을 수행한다.
- Task는 상태를 저장하지 않아 언제든지 시작, 중지, 재시작 할 수 있어 복원력과 확장성에 유리하다.
- 오토스케일링 혹은 장애로 인한 Worker 수의 변경은 나머지 Worker에 의해 자동으로 트래킹되며, Task 수를 재조정한다.
- Connector 사용량 측정이 어려운 경우, 최소, 최대 Worker를 지정해두는 것이 좋다.
- Producer/Consumer로 사용하는 Worker에 대한 속성값을 지정해줄 수 있다.
1.4 Logging
- CloudWatch Logs, S3, Kinesis Data Firehose 중 선택하여 로깅할 수 있다.
1.5 Monitoring
- Amazon CloudWatch를 이용하여 지정된 지표가 사용자가 지정한 임계치에 도달할 때에 사용자에게 알림을 보낼 수 있다.
- MSK Connect가 CloudWatch에 보내는 데이터들은 15개월 동안 유지된다.
2. MSK Connect 생성 준비
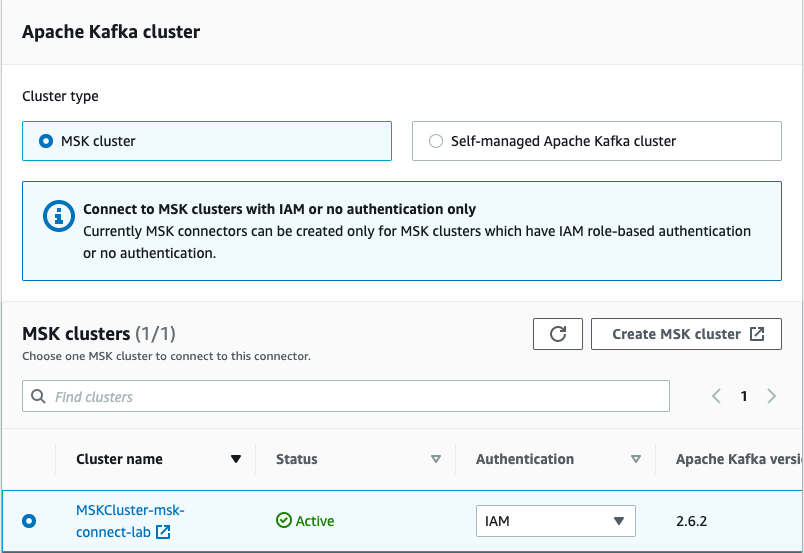
2.1 MSK Cluster
- MSK Cluster는 이미 생성된 상황이어야한다.
2.2 S3
- (Custom) Plugin Bucket: connector에 대한 jar 또는 zip 파일을 S3에 업로드한다.
- Target DB/Storage: S3의 경우, 데이터를 적재할 bucket
2.3 VPC Endpoint
- MSK Cluster가 위치한 VPC와 S3를 연결하기 위해 S3 Gateway Endpoint가 필요하다.
2.4 IAM
- S3 접근 Policy + MSK Connect Assume Role: S3에 MSK Connect가 접근할 수 있도록 정책과 Role이 필요하다.
모든 자원을 생성한 뒤, MSK Connector 생성이 가능하다.
3. MSK Connect Demo
3.1 Demo 설명
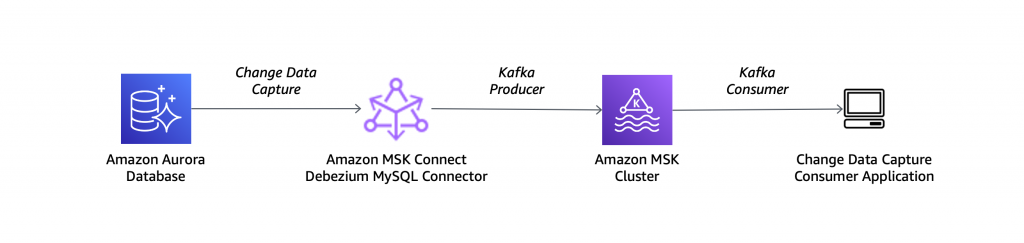
- RDS Aurora DB의 데이터를 Connector를 사용하여 MSK로 보내고 이 데이터를 S3로 저장하는 데모
3.2 Source Connector Setup
- MSK Cluster, VPC, IAM은 설정되었다고 가정
- S3에 plugin bucket과 target bucket이 생성되었다고 가정
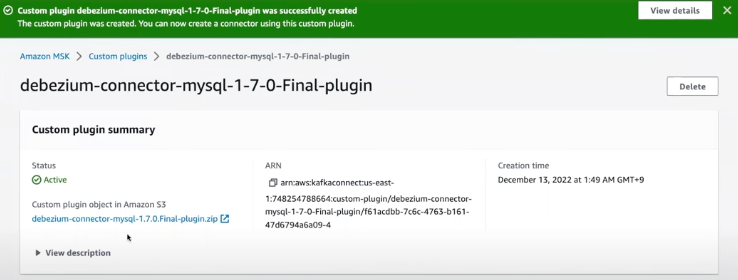
3.2.1 Costom plugin 생성

3.2.2 Work Configuration 생성

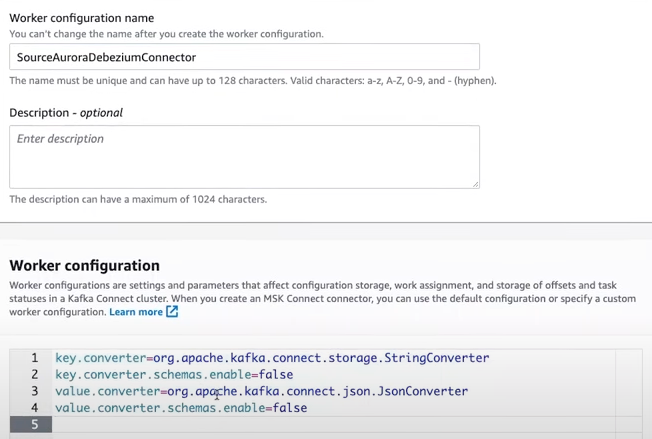
기본적인 구성
key.converter=org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable=false
value.converter=org.apache.kafka.connect.storage.StringConverter
value.converter.schemas.enable=false추가적인 구성은 아래의 링크 참고
Supported worker configuration properties
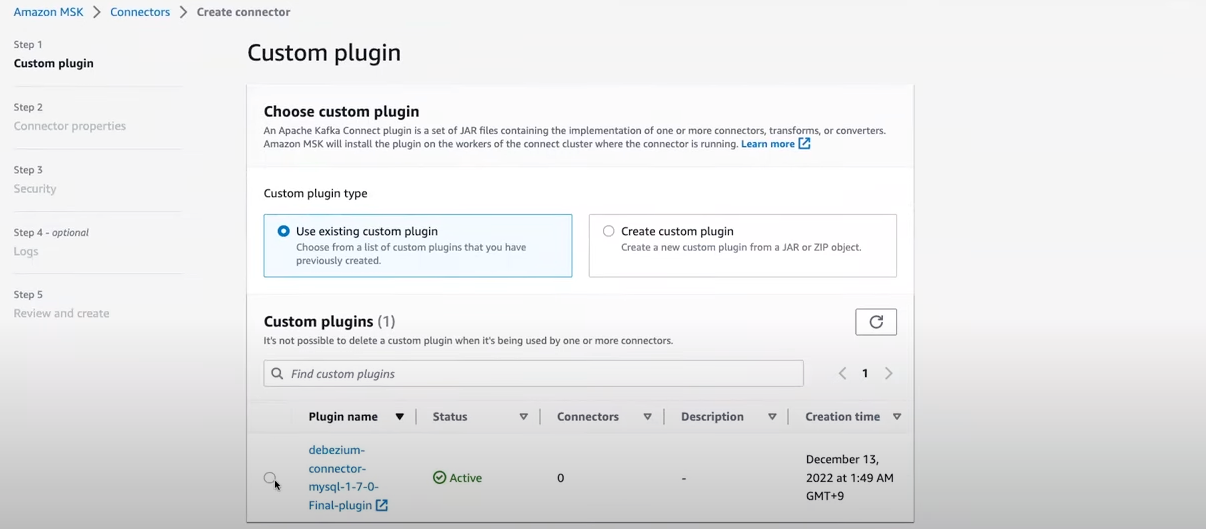
3.2.3 Connector 생성
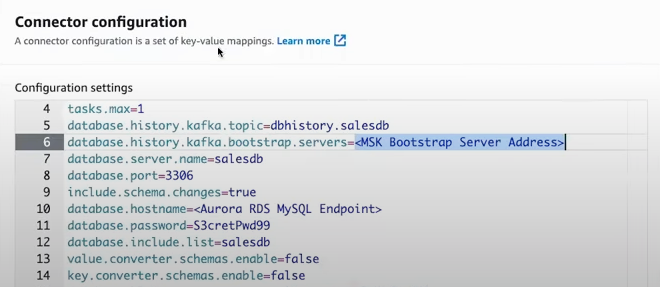
connector.class=io.debezium.connector.mysql.MySqlConnector
tasks.max=1
include.schema.changes=true
topic.prefix=salesdb
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter=org.apache.kafka.connect.storage.StringConverter
database.user=master
database.server.id=123456
database.server.name=salesdb
database.port=3306
key.converter.schemas.enable=false
database.hostname=< Your Aurora MySQL database endpoint >
database.password=< Your Database Password >
value.converter.schemas.enable=false
database.include.list=salesdb
schema.history.internal.kafka.topic=internal.dbhistory.salesdb
schema.history.internal.kafka.bootstrap.servers=< MSK Bootstrap Server Address >
schema.history.internal.producer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.consumer.sasl.mechanism=AWS_MSK_IAM
schema.history.internal.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
schema.history.internal.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
schema.history.internal.consumer.security.protocol=SASL_SSL
schema.history.internal.producer.security.protocol=SASL_SSL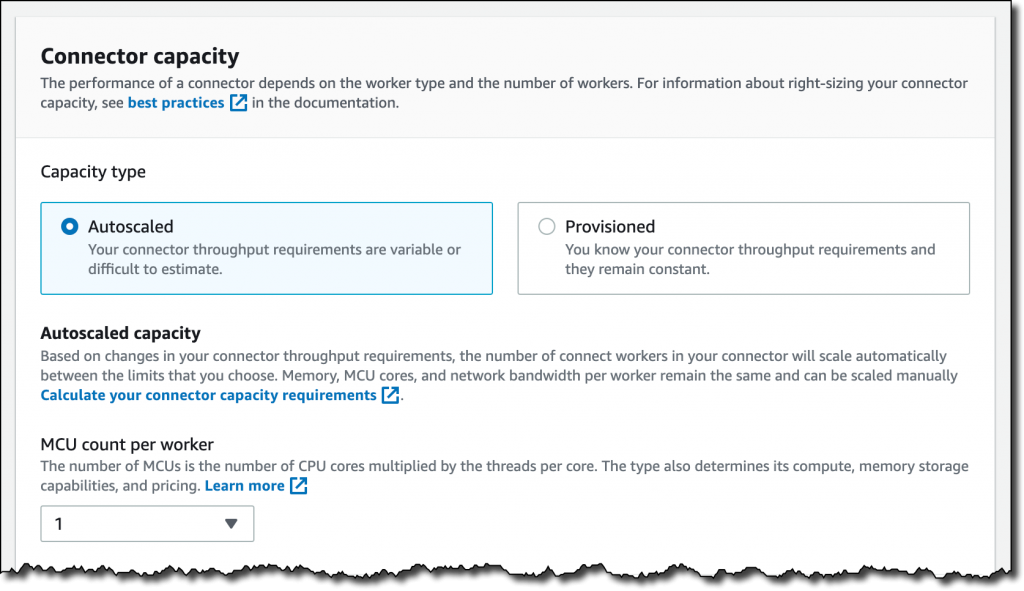
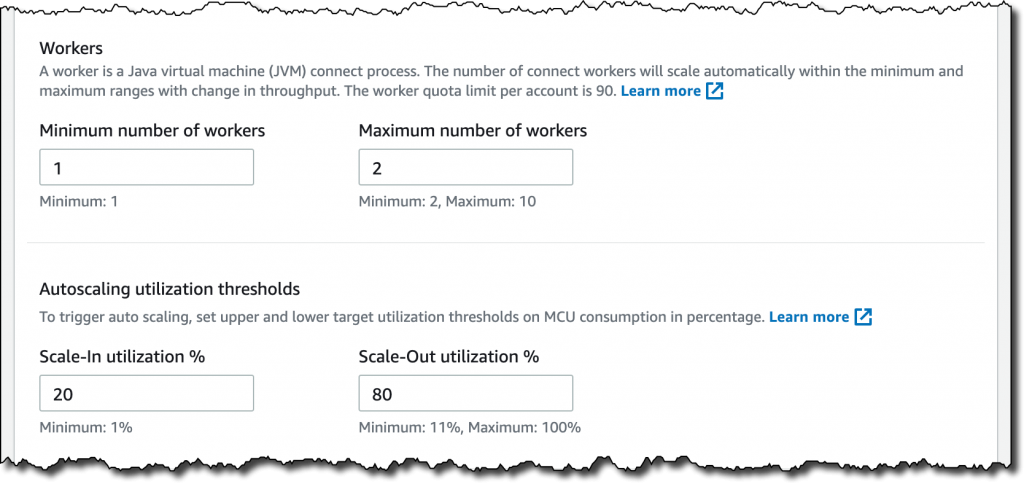
- Worker당 MCU 개수 설정 - 각 MCU는 1개의 vCPU로 구성된 컴퓨팅과 4GB의 메모리를 제공
- 최소 및 최대 Worker의 수(number of workers) 설정
- Autoscaling utilization thresholds – autoscaling을 트리거하는 MCU 소비에 대한 상위 및 하위 목표 사용률 임계값(%)
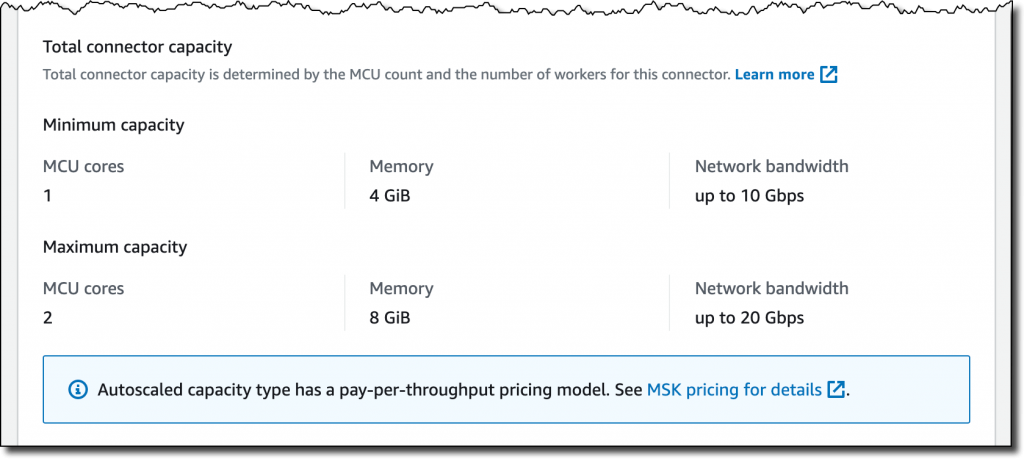
- 마지막으로 Connector에 대한 최소 및 최대 MCU, 메모리 및 네트워크 대역폭의 요약도 해준다.
4. 가격 비교
4.1 MSK Connect
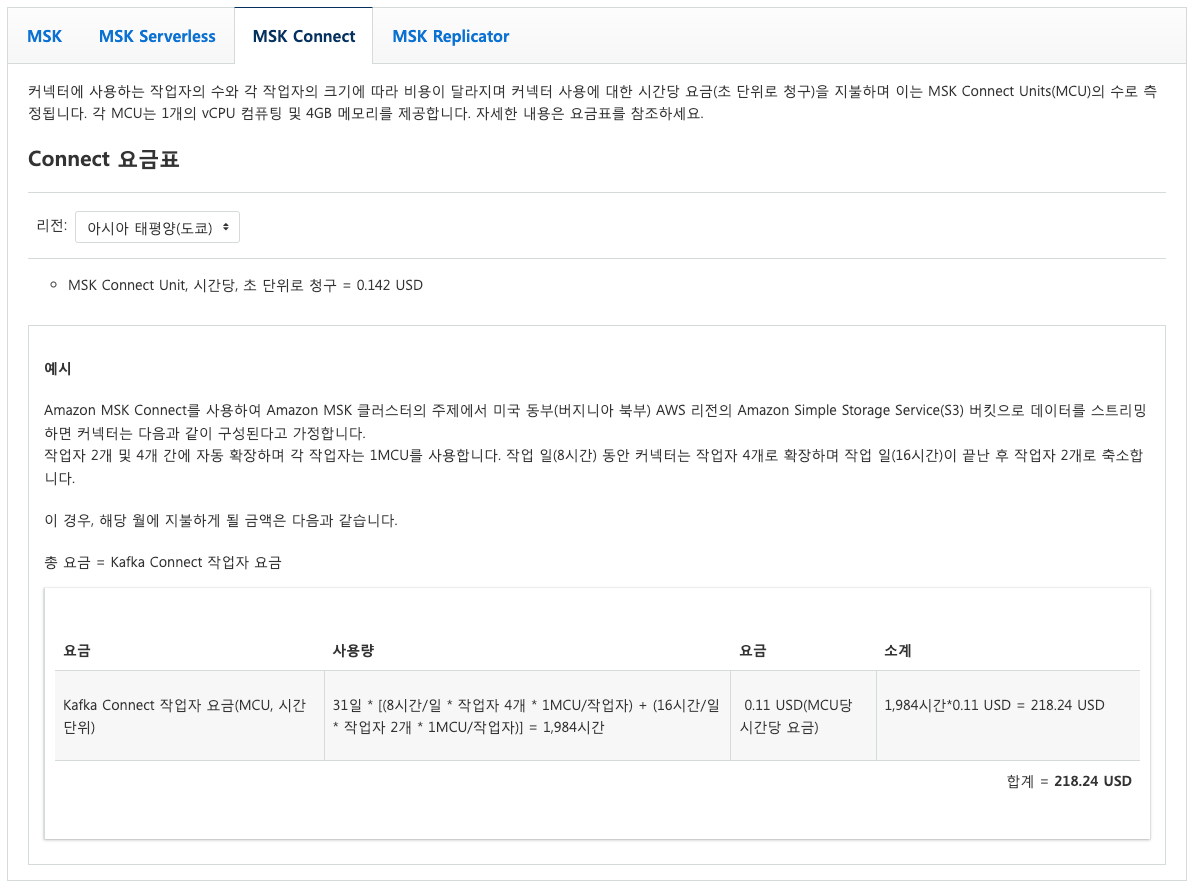
- 커넥터 사용에 대한 시간당 요금(초 단위로 청구)을 지불하며 이는 MSK Connect Units(MCU)의 수로 측정된다. 각 MCU는 1개의 vCPU 컴퓨팅 및 4GB 메모리를 제공한다.
- https://aws.amazon.com/ko/msk/pricing/
4.2 ECS Service
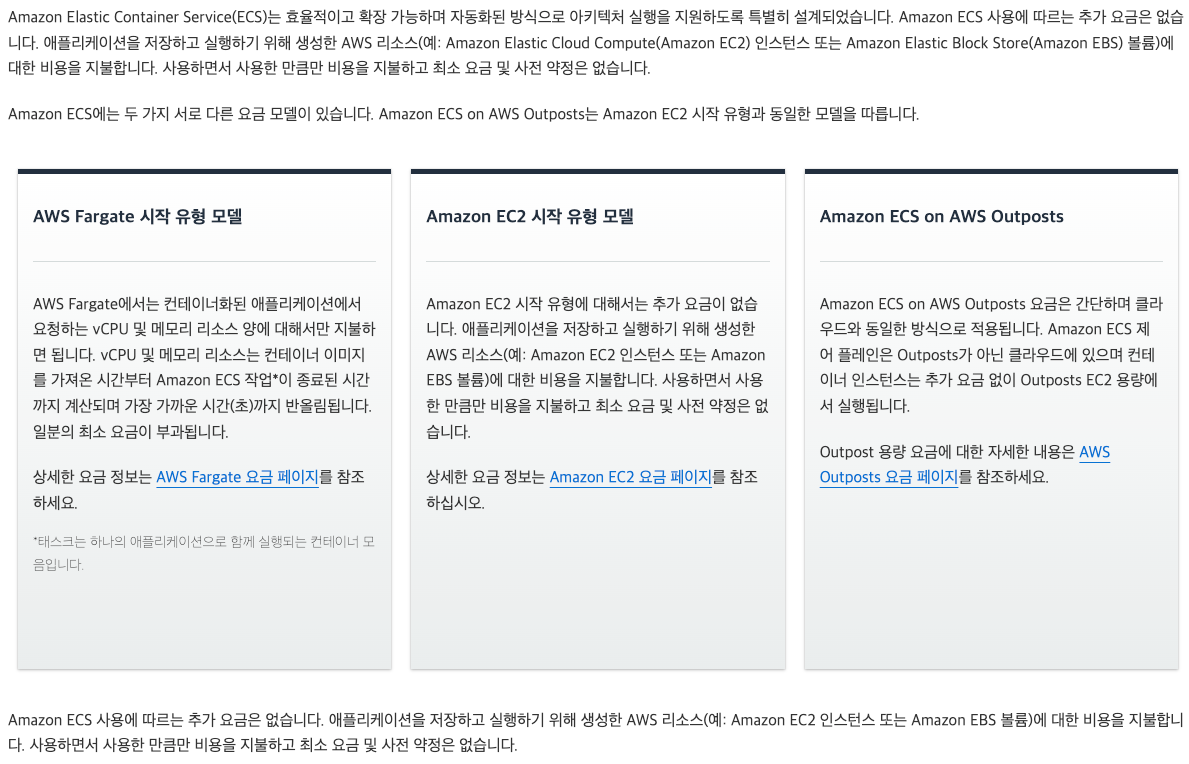
- vCPU 및 메모리 리소스 양에 대해서만 지불하면 된다.
- https://aws.amazon.com/ko/ecs/pricing/
5. 결론
- 마이그레이션 할 때 생각보다 할 일들이 많아서 빠르게 마이그레이션이 되지는 않을 것 같다.
- 그 중에 하나는, ECS Service Kafka Connect의 경우 한꺼번에 jar or zip을 Dockerfile로 build해서 Connect를 만들고 Connector만 각각 띄우면 되는 반면, MSK Connect는 어떻게 보면 Dockerfile도 각각 만들고 Connector도 각각 띄워야하는 상황
- 가격적인 면에서는 ECS Connect가 더 적게 나올 것 같다.
- MSK Connect의 경우 무조건 Connector 하나 당 MCU 하나를 사용해야해서 요금이 더 나올 것 같다.
- 나중에 EKS 도입 시, 인프라 관리 측면에서 신경써야할 포인트가 더 늘어난다.
따라서 기존에 ECS Connect를 통한 Connector 사용 방식을 채택!
6. 기타
6.1 그렇다면 Schema Registry는?
- ECS Service (현행 유지)
- AWS Glue Schema Registry 사용 (새롭게 도입)

현재는 어떻게 운영하고 계신가요?
저도 msk connector를 여러 개 운영하는 것이 그리 좋지 않아보여서 ecs connector, registry를 따로 구성하려고 합니다!