개요
- 클라우드 기반 데이터 플랫폼 구축을 위해 AWS 서비스를 활용하여 데이터 수집, 정제, 분석 환경을 구성하였다. 특히, S3, Glue, Athena를 통해 데이터 레이크를 구성하고, 생성형 AI(Bedrock)를 활용한 Text-to-SQL 기능 설계를 포함하여 AI 기반 협업 시나리오도 고려하였다.
- 본 문서에서는 구현 과정을 실습 중심으로 정리했으며, 관련 테이블 통합 방식에 대한 블로그 포스팅도 함께 진행하였다.
Architecture
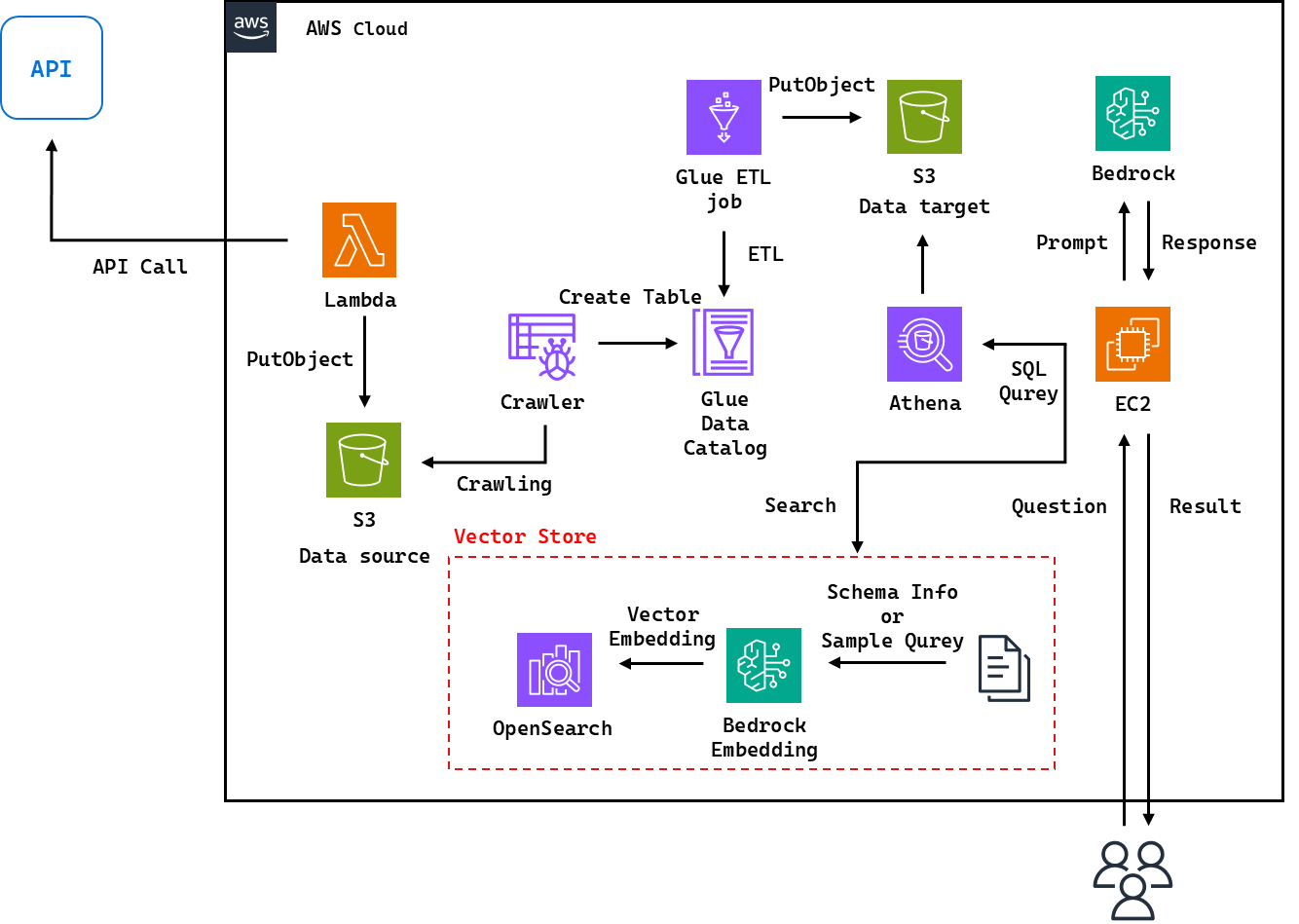
본 실습에서는 Lambda를 활용한 실시간 데이터 수집 대신, S3에 정적 예제 데이터를 업로드하여 데이터 파이프라인 전반과 Bedrock을 사용한 SQL 쿼리 생성을 검증하였다.
순서
데이터레이크 구성
- 데이터 수집
- Lambda 함수가 외부 API를 호출하여 데이터를 수집
- 수집한 데이터를 S3 Data source 버킷에 PutObject로 저장
- 데이터 카탈로그화
- AWS Glue Crawler가 S3 Data source 버킷을 크롤링하여 데이터 스키마를 분석
- Glue Data Catalog에 테이블을 생성
- 데이터 처리 (ETL)
- Glue ETL Job은 JSON 데이터를 Parquet 포맷으로 변환하고, 필드 정제 및 타입 변환 등의 처리를 수행
- 처리된 결과는 S3 Data target 버킷에 저장
- 데이터 분석
- Amazon Athena는 Glue Data Catalog의 테이블 정보를 기반으로 쿼리를 실행
- 사용자 또는 시스템은 Athena를 통해 S3에 저장된 데이터를 SQL로 분석
Text to SQL 과정
- 자연어 질문
- 사용자는 애플리케이션에 자연어 질문을 전달
- Opensearch 검색
- OpenSearch를 조회하여 관련 정보 수집 및 조회
- 유사 질문 검색, 스키마 정보 조회
- 애플리케이션 프롬프트
- 애플리케이션은 사용자 질문을 바탕으로, Bedrock 언어 모델에게 SQL 생성을 요청하는 프롬프트를 구성
- Bedrock으로 SQL 쿼리 응답
- Bedrock은 제공된 프롬프트를 기반으로 SQL 쿼리를 생성하여 응답하며, 이때 OpenSearch에서 수집한 예제 쿼리나 컬럼 정보가 정확도 향상에 기여
- 애플리케이션 쿼리
- Athena 를 통해 쿼리 수행하여 완성된 답변을 사용자에게 제공
참고사항
- Glue ETL Job은 일반적으로 Crawler 실행 이후, 생성된 테이블 메타데이터를 기반으로 수행된다.
- Athena는 S3 데이터를 직접 조회하지만, Glue Data Catalog에 등록된 메타데이터를 기반으로 쿼리를 실행하므로 카탈로그 등록이 필수적이다.
- Glue Crawler는 데이터 수집(source)과 처리 결과(target) 모두에 적용할 수 있으며, 주기적인 데이터 구조 업데이트에 유용하다.
AWS Service
AWS Glue
AWS Glue는 서버리스 기반의 완전관리형 데이터 통합 서비스로, 데이터를 수집(Extract), 변환(Transform), 적재(Load)하는 ETL 작업을 자동화할 수 있도록 도와준다.
- 서버리스 환경이므로 별도의 인프라 구축이나 유지 관리가 불필요
- Apache Spark 기반 분산 처리 엔진을 사용하여 대용량 데이터도 빠르게 처리
- Amazon S3, Amazon RDS, Amazon Redshift, DynamoDB, JDBC 연결 데이터베이스 등 다양한 소스와 연동 가능
- Glue Crawler, ETL Job, Data Catalog, Athena 등과 통합 작동하여 데이터 레이크 아키텍처의 핵심 구성요소로 활용
Glue는 단순한 ETL 도구를 넘어서, AWS 데이터 분석 생태계의 허브 역할을 한다.
Glue Crawler
AWS Glue Crawler는 S3나 JDBC 연결 데이터베이스 등 다양한 소스를 주기적으로 스캔하고, 데이터의 구조(스키마)를 자동으로 인식하여 Glue Data Catalog에 테이블로 등록해주는 기능을 제공한다.
- JSON, CSV, Parquet, ORC 등 다양한 파일 포맷을 자동 인식
- 필드명, 데이터 타입, 파티션 구조 등을 추론하여 테이블 정의를 자동 생성
- 기존 테이블을 업데이트하거나 새로 생성가능
- 생성된 테이블은 Glue ETL Job 또는 Athena 쿼리에서 바로 사용가능
반복적인 스키마 정의 작업 없이, 신규 데이터가 유입될 때마다 자동으로 카탈로그화할 수 있어 운영 자동화에 유리하다.
Glue ETL Job
AWS Glue ETL Job은 Glue에서 제공하는 핵심 기능으로, 데이터를 추출, 변환, 적재하는 작업을 코드 기반으로 자동 실행할 수 있게 한다.
- Spark, Python(PySpark), Scala 언어로 작성할 수 있으며, Jupyter 노트북 형태의 개발 환경도 지원
- 주요 기능:
- 데이터 필터링 및 정제
- 포맷 변환 (예: JSON → Parquet, CSV → ORC 등)
- 필드 병합/분할, 컬럼명 변경, Null 처리, 타입 변환
- 복수 테이블 간 Join 및 Aggregation(집계)
- 처리된 결과는 S3, Redshift, RDS 등 다양한 대상에 저장 가능
- Glue Data Catalog의 메타데이터를 참조하여 자동으로 입력/출력 스키마를 설정 가능비정형/반정형 데이터를 정형화하고, 분석 가능한 형태로 변환하는 데 사용된다.
Glue Data Catalog
AWS Glue Data Catalog는 AWS 전역에서 공유되는 중앙 메타데이터 저장소로, 테이블, 스키마, 파티션 등의 정보를 저장하고 관리한다.
- Crawler가 자동 생성하거나, 수동으로 테이블을 등록 가능
- Athena, Redshift Spectrum, EMR, Glue ETL Job 등에서 동일한 카탈로그를 공유하여 통일된 데이터 정의로 작업 가능
- 테이블마다 데이터 위치(S3 경로), 포맷, 열 이름/타입, 파티션 키 등의 정보가 저장
Glue Data Catalog는 "데이터에 대한 설명서"이자, 분석 도구의 인덱스 역할을 한다.
Athena
Amazon Athena는 S3에 저장된 데이터를 SQL로 직접 분석할 수 있는 서버리스 쿼리 서비스다. 즉, 데이터를 이동시키지 않고도 분석할 수 있어 데이터 레이크 분석에 적합하다.
- Glue Data Catalog에 등록된 테이블을 기반으로 SQL 쿼리를 수행
- 인프라 설정 없이 즉시 사용 가능, 사용한 쿼리 시간에 비례해 비용 부과 (pay-per-query)
- S3에 있는 CSV, JSON, Parquet, ORC, Avro 등의 데이터를 바로 분석 가능
- 쿼리 결과도 S3에 저장되므로 다른 애플리케이션이나 시각화 도구에서 재사용 가능
- BI 도구(예: QuickSight, Tableau 등)와 연동하여 실시간 시각화 가능
SQL만 알면 대용량 데이터를 빠르게 분석할 수 있는 매우 강력한 도구이다.
Bedrock
Amazon Bedrock은 생성형 AI 서비스를 손쉽게 애플리케이션에 통합할 수 있도록 지원하는 완전관리형 서비스이다. 다양한 기성 모델(Foundation Models, FMs)을 API 기반으로 제공하며, 사용자는 별도의 인프라 설정 없이 생성형 AI 기능을 애플리케이션에 바로 연동할 수 있다.
- Anthropic Claude, Mistral, Meta Llama 등 여러 모델 제공
- 서버리스 환경으로 모델 호스팅/배포, GPU 인프라 관리 없이 사용 가능
- AWS IAM 및 VPC 연동으로 보안 및 권한 제어 용이
- 다양한 용도(예: 텍스트 생성, 요약, 분류, 질의응답, 코드 생성 등)에 활용 가능
예시로, 자연어 질의(NLQ) → SQL 변환(Text-to-SQL) 과 같은 LLM 기반 인터페이스를 구축할 때, 언어 이해 및 생성 능력을 제공하는 핵심 서비스이다.
Bedrock Agent
Amazon Bedrock Agent는 LLM 기반 애플리케이션에 “작업 실행 능력”과 “지식 기반 접근”을 부여하는 완전관리형 구성 요소로, 사용자의 자연어 요청을 분석하고 외부 API 호출, 데이터베이스 질의, 지식 참조 등 복잡한 작업을 자동으로 처리할 수 있게 한다.
- 사용자의 질의 의도를 이해하고, 필요한 작업을 자동 계획 및 실행
- AWS Lambda, 외부 API, 데이터베이스 쿼리 등과 연동하여 액션 수행 가능
- Bedrock Knowledge Base와 통합되어, 정확한 문서 기반 응답 제공 가능
- 추론 단계에서 Tool 사용(예: 검색, 호출, 계산) → 최종 응답 생성 과정을 자동화
- Agent를 위한 API 스키마, 워크플로우 등을 콘솔에서 손쉽게 정의 가능
- 서버리스 구성으로, 별도의 인프라 없이 손쉽게 구축 및 운영 가능
주요 구성 요소:
- Action Group: Agent가 호출할 수 있는 외부 기능(API 호출, Lambda 함수 등) 집합
- Knowledge Base 연동: 벡터 기반 검색을 통해 LLM이 배경지식 또는 예시 데이터를 기반으로 응답 가능
- Prompt orchestration: 사용자 요청에 따라 Agent가 적절한 순서로 작업을 실행하고 응답 생성
Text-to-SQL 시스템에서 Bedrock Agent는 다음과 같이 활용될 수 있다:
질문 : "지난 분기의 제품별 매출을 알려줘"
→ Bedrock Agent는 지식 기반에서 과거 쿼리를 검색하고, 필요 시 Lambda를 호출해 테이블 스키마를 확인한 뒤, 정보를 바탕으로 SQL을 생성해 Athena에 질의한다.
Bedrock Agent는 LLM이 단순한 질문 응답을 넘어, “지능형 업무 수행자”로 진화하도록 만드는 핵심 서비스이다.
Bedrock Agent의 장,단점
장점:
- 작업 자동화 및 오케스트레이션: Bedrock Agent는 복잡한 작업 자동화를 처리하는 데 최적화되어 있다. 사용자 요청을 여러 단계로 나누고 통합 API 호출을 통해 이러한 작업의 실행을 관리할 수 있다. 따라서 동적 작업 오케스트레이션 및 대화 상호 작용이 필요한 응용 프로그램에 매우 적합하다.
- RAG(Retrieval Augmented Generation)와 기술 자료 통합: 상담원은 RAG 기술을 사용하는 지식 기반으로 강화될 수 있으며, 이를 통해 매우 정확하고 상황에 맞는 응답을 검색하고 제시할 수 있다. 따라서 복잡한 쿼리를 처리하는 데 더 깊은 수준의 컨텍스트와 지식이 필요한 시나리오에서 특히 효과적이다.
- 높은 사용자 정의: Bedrock Agents는 작업 실행의 여러 지점에서 Lambda 함수를 통합할 수 있는 유연성을 제공한다. 이를 통해 고급 사용자 지정 프롬프트를 생성하고 작업 처리 방법을 정의하여 정교한 워크플로우를 관리할 수 있는 강력한 방법을 제공할 수 있다.
- 대화 능력: 상담원은 사용자와의 지속적인 대화형 대화를 위해 설계되었다. 애플리케이션이 여러 상호 작용 또는 작업에 대한 컨텍스트 유지 관리에 의존하는 경우 에이전트는 이러한 요구 사항을 더 잘 처리할 수 있다.
단점:
- 비용 고려 사항: Bedrock Agent는 기능이 더 풍부하기 때문에 비용이 많이 들 수 있으며, 특히 고급 대화 기능이 필요하지 않은 애플리케이션의 경우 더욱 심하다.
- 복잡성: 다단계 워크플로, 사용자 지정 Lambda 통합 및 RAG를 사용하여 에이전트를 설정하는 것은 간단한 지식 기반 설정에 비해 더 복잡하고 시간이 많이 소요될 수 있다.
Bedrock Knowledge Base
Bedrock Knowledge Base는 생성형 AI가 신뢰할 수 있는 사전 정의된 데이터에 기반하여 응답할 수 있도록 지원하는 기능으로, LLM + 벡터 기반 검색(RAG)을 결합하여 정확하고 맥락에 맞는 응답을 생성하도록 설계된 구성 요소이다.
- S3, Amazon OpenSearch, Amazon Aurora 등 다양한 데이터 소스를 연동 가능
- 연동된 데이터는 임베딩(Embedding)을 통해 벡터화되어 저장되며, 이후 LLM이 질의 시 가장 유사한 문서나 쿼리를 검색해 참고함
- RAG(Retrieval-Augmented Generation) 아키텍처를 자동화된 방식으로 구축할 수 있음
- 사용자는 별도의 서버나 파이프라인 구축 없이, "자연어 질문 → 관련 문서 검색 → LLM 응답 생성" 흐름을 자동화할 수 있음
- Bedrock에서 지원하는 Foundation Model과 연동되어 응답 생성 품질이 높음
- IAM 기반 권한 제어 및 네트워크 제약(VPC)도 설정 가능하여 보안도 우수
Text-to-SQL 시스템에서는 사용자가 "작년 5월 매출 알려줘"이라는 질의를 입력하면, Knowledge Base가 과거 SQL 예제 또는 스키마 문서 등을 참조해 LLM이 더 정확한 SQL 쿼리를 생성할 수 있도록 도와준다.
Knowledge Base는 단순 문서 검색을 넘어서, SQL 스키마 참조, 샘플 쿼리 제공, 시스템 호출 정보 등 실시간 의사결정을 위한 핵심 메타데이터 제공 역할을 수행하며, 생성형 AI의 정확도와 신뢰성을 높이는 핵심 도구이다.
Bedrock Embedding
Bedrock Embedding 기능은 입력된 텍스트를 벡터(Vector) 형태로 변환하는 임베딩 모델을 제공하며, 문맥 기반 검색 및 의미 기반 질의 대응을 가능하게 한다.
- 텍스트를 고차원 벡터로 변환하여 유사도 계산이 가능
- 예:
"매출이 높은 상품은?"→ 의미 유사한 과거 질문을 벡터 기반으로 매칭 - Cohere Embed, Titan Embeddings 등 선택 가능한 모델 제공
- 생성된 벡터는 OpenSearch, Pinecone, FAISS 등 벡터 검색 엔진과 연동 가능
Text-to-SQL 시스템에서, 사용자의 질의를 벡터로 변환하여 기존 쿼리/문서와 유사도 기반 검색(RAG 방식)을 수행하여 정확도 향상에 활용된다.
그리고 Bedrock의 RAG의 전반적인 이해를 위한 유튜브 링크도 참고하면 이해에 도움이 될 것이다.
OpenSearch Service
Amazon OpenSearch는 검색 및 분석을 위한 오픈소스 기반 분산 검색 엔진 서비스로, 대규모 텍스트 데이터 및 벡터 데이터에 대한 빠른 검색이 가능하다.
- Elasticsearch 오픈소스 포크 기반
- 텍스트 및 벡터(Embedding) 기반 검색을 동시에 지원
- 벡터 서치 기능 지원
- Bedrock에서 생성된 임베딩 벡터를 저장 및 검색하는 백엔드로 활용 가능
- S3, CloudWatch, Kinesis 등 AWS 서비스와 통합 가능
특히, RAG(Retrieval-Augmented Generation) 구조에서, OpenSearch는 유사한 자연어 질의 또는 예제 SQL을 빠르게 검색하여, Bedrock의 생성 모델이 더 정확한 SQL을 생성하도록 지원한다.
실습
실습에 필요한 샘플 데이터 및 코드 예시는 Github 링크를 참고하길 바라며, 본 문서에서는 해당 샘플을 기반으로 단계 별 실습을 진행한다.
시나리오
- S3 에 있는 데이터를 통해 Glue Crawler를 사용하여 데이터의 구조(스키마)를 자동으로 인식하여 Glue Data Catalog에 테이블로 등록한다.
- AWS Glue ETL Job을 사용하여, 두 개의 json 을 통합하고, 파켓(parquet) 형태로 포맷을 바꾼다.
- 통합한 데이터를 신규 S3에 저장하여 Athena를 사용하여 테이블의 정보를 확인한다.
- Python의 streamlit 앱을 사용하여 자연어 기반으로 Bedrock이 SQL문을 작성하여 사용자에게 결과값을 반환
S3
데이터 경로 : glue-cralwers-src/user_info/user_info.jsonl
데이터 경로 : glue-cralwers-src/add_info/addd_info.jsonl
각각의 경로에는 sample_data폴더 아래에 있는 실습 파일이 있으며, 예시 데이터는 아래와 같다.
# user_info.jsonl
{"id":"Denise1","name":"Denise Hall","Age":35,"Gender":"F","Email":"jonathansims@hotmail.com","Country":"Japan"}
{"id":"Scott2","name":"Scott Walker","Age":53,"Gender":"M","Email":"elainesmith@yahoo.com","Country":"UK"}
...
]
# add_info.jsonl
{"id":"Denise1","JoinDate":"2022-02-05","IsActive":"TRUE","Role":"Viewer","Score":73.4}
{"id":"Scott2","JoinDate":"2023-04-27","IsActive":"FALSE","Role":"Admin","Score":81.2}
...
]왜 json 형식은 Athena에서 불리한가?
→ JSON 배열은 구조를 미리 알 수 없어 schema 추론이 어렵고, 분산처리 성능도 떨어지기 때문이다.
| 항목 | JSON | JSONL |
|---|---|---|
| 구조 | 배열로 한 번에 감쌈 | 각 줄마다 독립 객체 |
| Athena 호환성 | 낮음 | 높음 |
| 처리 성능 | 낮음 | 높음 |
| 크롤링 가능성 | 낮음 | 높음 |
Glue
Glue Crawlers

먼저 데이터를 수집하기 위한 Crawlers 설정을 진행한다.
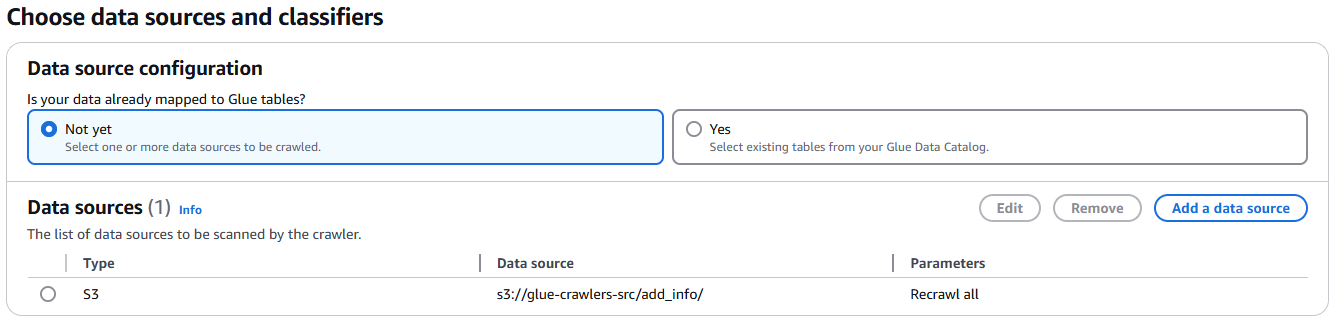
크롤링을 위해 Data source는 이전 S3에 업로드했던 경로를 선택하고, user_info, add_info 경로를 각각 선택하여 크롤러를 2개를 생성한다.
실습은 각 경로에 있는 jsonl 파일로 Gule ETL Job 으로 id값을 기준으로 통합하겠다.
생성할 크롤러
1. crawler-add_info
2. crawler-user_info
# Glue Crawler IAM Role
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::glue-crawlers-src/*",
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::glue-crawlers-dst/*"
]
}
]
}크롤러를 실행하기 위해서는 위와 같은 S3에 대한 권한이 있어야 하며, AWSGlueServiceRole 정책도 함께 필요하다. 왜냐하면 크롤러 실행 이후 Glue ETL 작업도 추가적으로 수행해야 하기 때문이다.
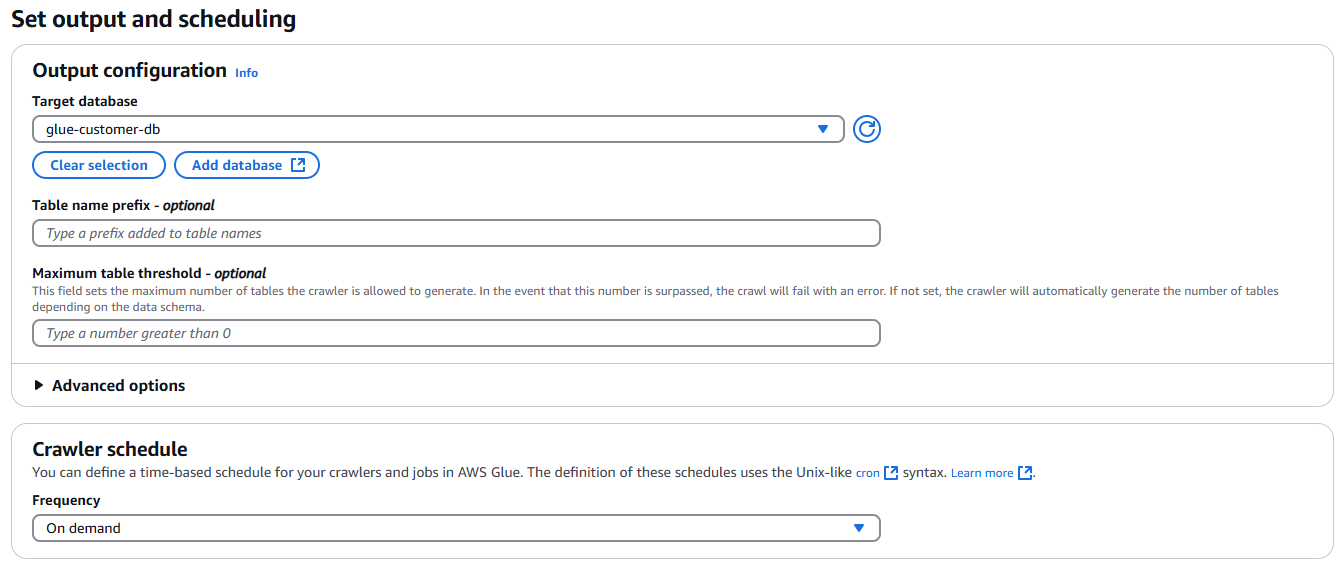
크롤링한 데이터를 저장할 대상 데이터베이스를 선택을 한다면 Crawlers 설정은 끝이다.
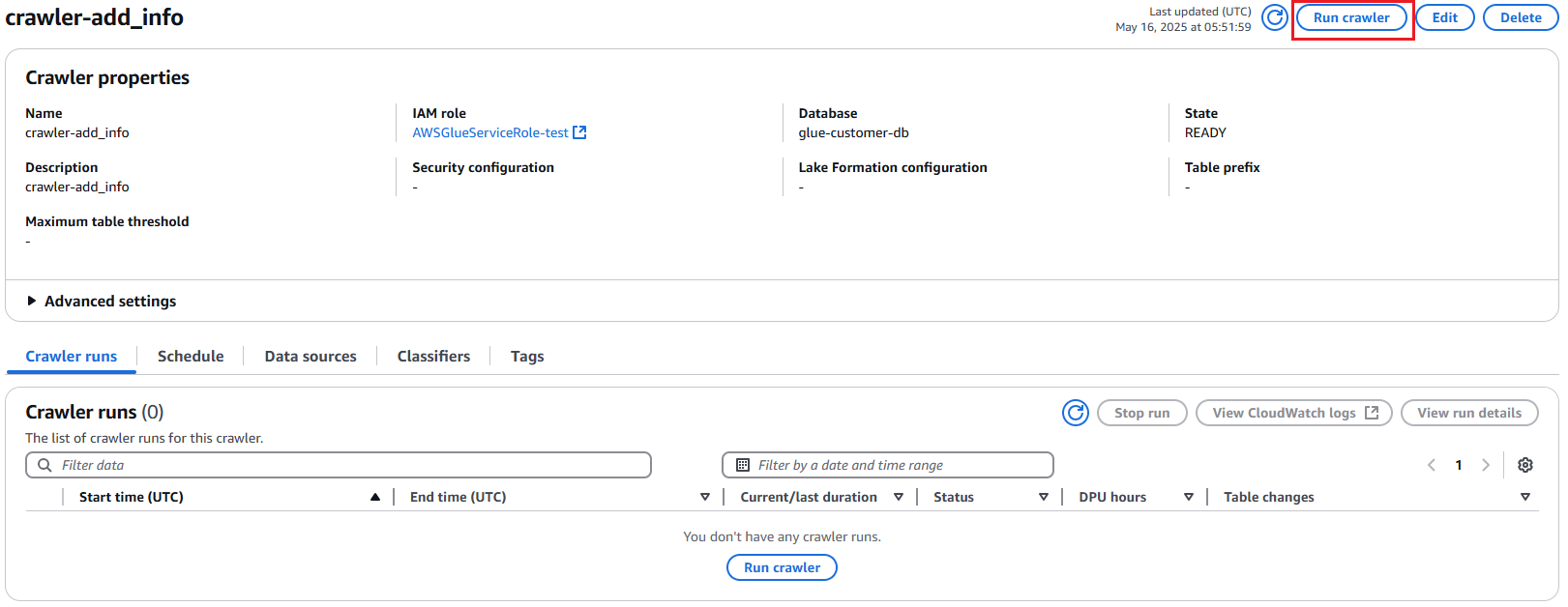
화면과 같이 각각의 크롤러를 선택 후 Run crawler를 클릭하여 실행한다.
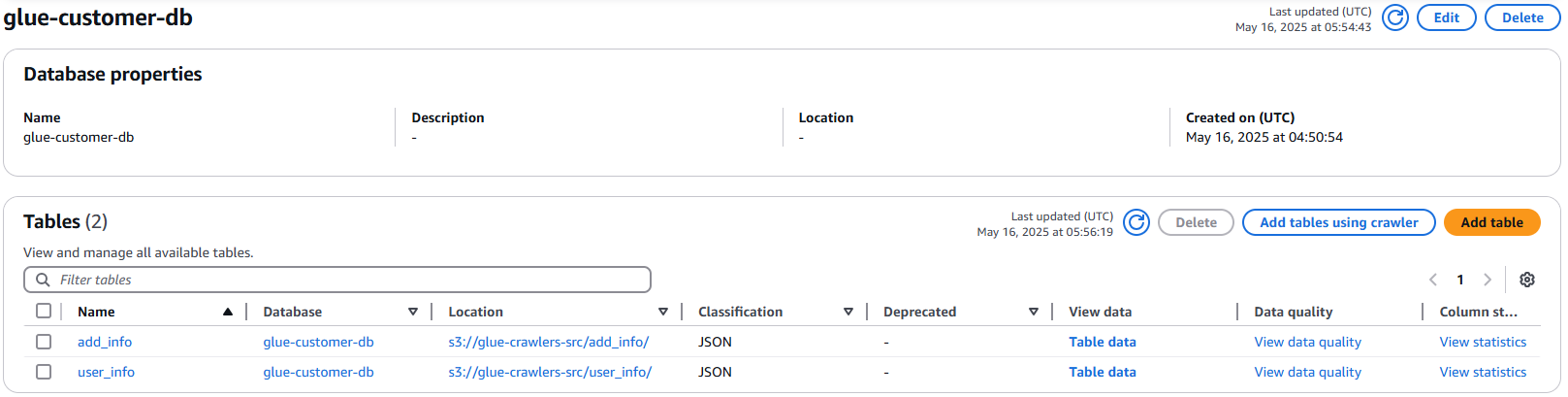
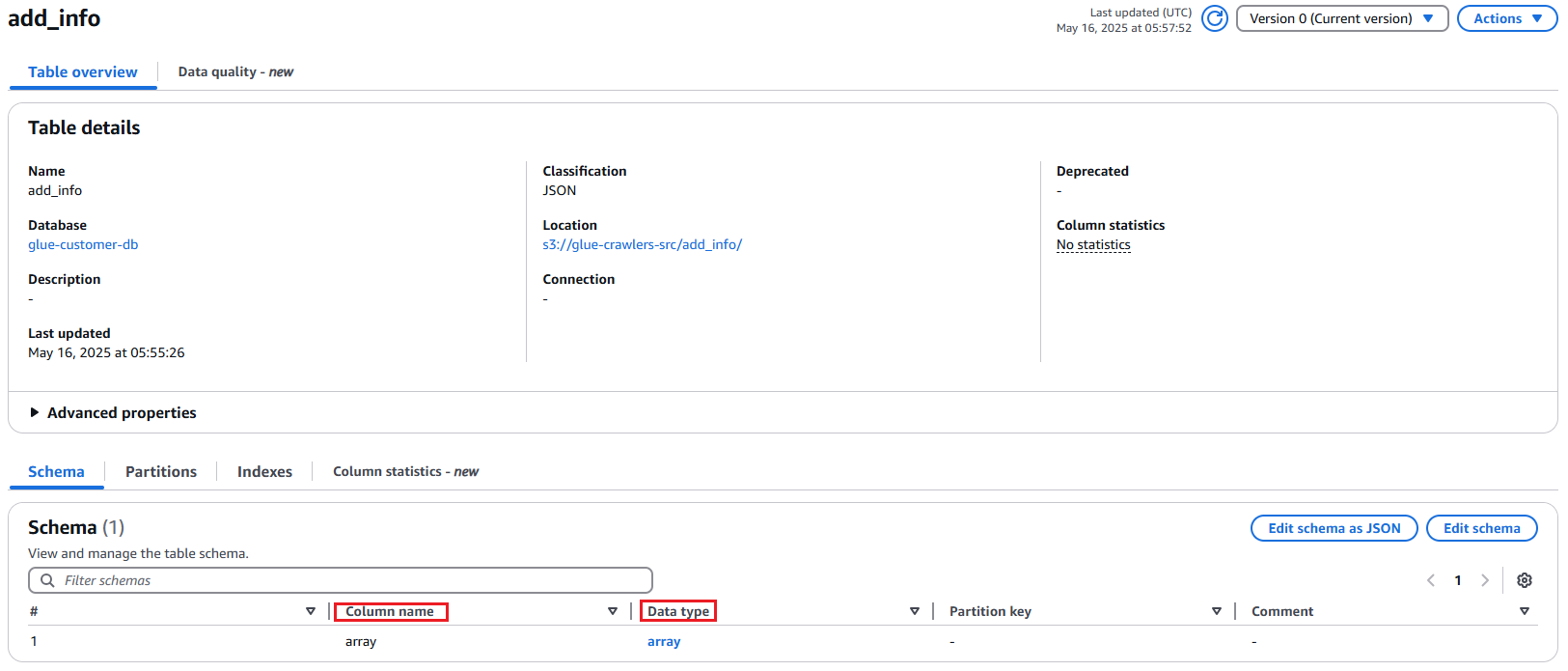
glue-customer-db에 있는 Table 정보이며, 각각의 크롤러를 생성 후 실행하여 2개의 경로에 테이블이 생성이 된 것을 확인할 수 있다.
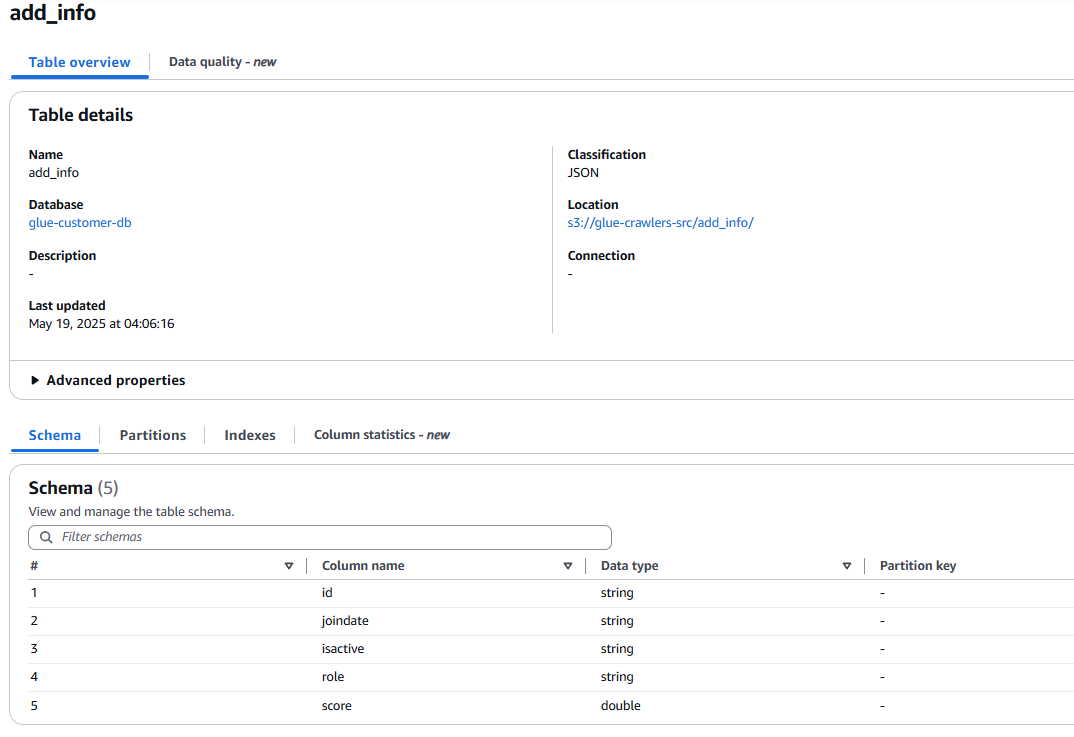
Column : id, joindate, isactive, role, score
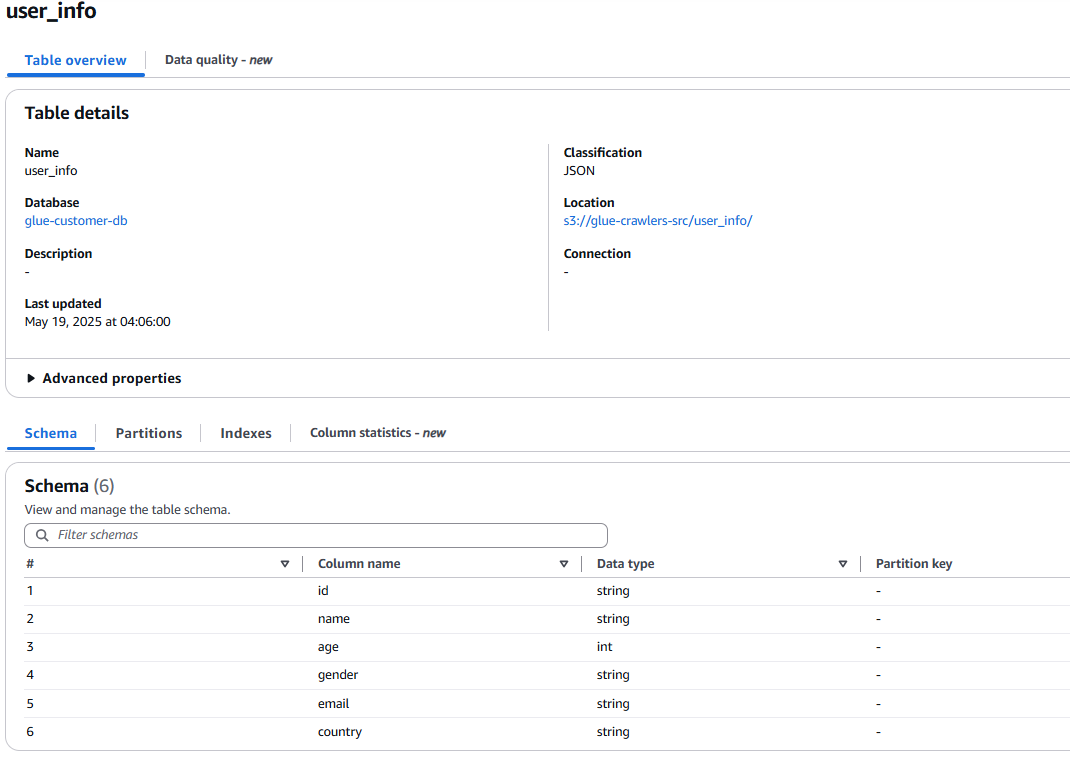
Column : id, name, age, gender, email, country
여기서, add_info, user_info 테이블을 기준으로 Column name에는 id, name, joindate, 등 값이 있고, Data type에는 각 데이터의 타입을 자세히 확인할 수 있다.
JSON 포맷을 아래 jsonl 형태로 만들 시 Column name, Data type이 지정한 테이블 선택 시 형태가 보이는 것을 확인할 수 있었다.
# user_info.jsonl 포맷 예시
{"id":"Denise1","JoinDate":"2022-02-05","IsActive":"TRUE","Role":"Viewer","Score":73.4}
{"id":"Scott2","JoinDate":"2023-04-27","IsActive":"FALSE","Role":"Admin","Score":81.2}Athena에서는 배열 형태의 JSON은 파싱이 불가능하므로, 각 객체가 한 줄씩 기록된 JSONL 형식이 요구된다.
만약 json 으로 하더라도, 테이블에서 datatype 을 미리 볼 수 없다는 것을 참고해야한다.
# user_info.json 포맷예시
[
{
"id": "Denise1",
"JoinDate": "2022-02-05",
"IsActive": "TRUE",
"Role": "Viewer",
"Score": 73.4
},
{
"id": "Scott2",
"JoinDate": "2023-04-27",
"IsActive": "FALSE",
"Role": "Admin",
"Score": 81.2
}
]
add_info 테이블에서 json 을 예시 json 처럼 S3에 업로드 후 크롤링을 한다면 위와 같이 컬럼에 대한 이름과 데이터 타입이 다른 것을 확인할 수 있다.
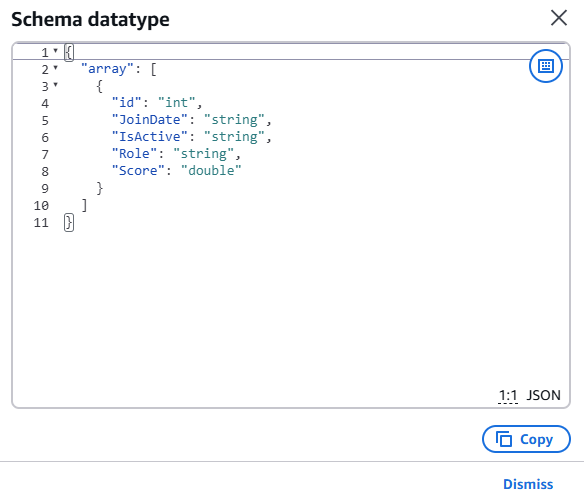
실제 데이터를 수집한 데이터는 array 인 배열 형태로 저장이 되는 것을 확인을 할 수 있다.

위와 같이 쿼리 시 실패가 되었고, 일반적인 json 포맷이 athena 에서 지원하지 않기 때문이다.
Glue ETL jobs
우리는 위와 같이 데이터를 유효한 형식으로 변환해야 athena를 사용하여 쿼리를 할 수 있는 것을 확인하였다.

user_info와 add_info 테이블은 공통 ID 값을 기준으로 병합할 수 있으며, 이 작업은 Glue ETL Job을 통해 수행된다. 병합된 결과는 분석에 적합한 Parquet 포맷으로 저장된다.
먼저, Script editor 를 선택 후 Engine은 Spark 로 선택을 한다.
etl_script/customer-etl-spark.py 파일을 사용해 테이블을 병합하는 스크립트이며, Job details 에서 사용할 IAM Role 및 실행한 스크립트 파일, 로그 등 저장할 S3 를 선택하여 저장 후 실행을 한다.
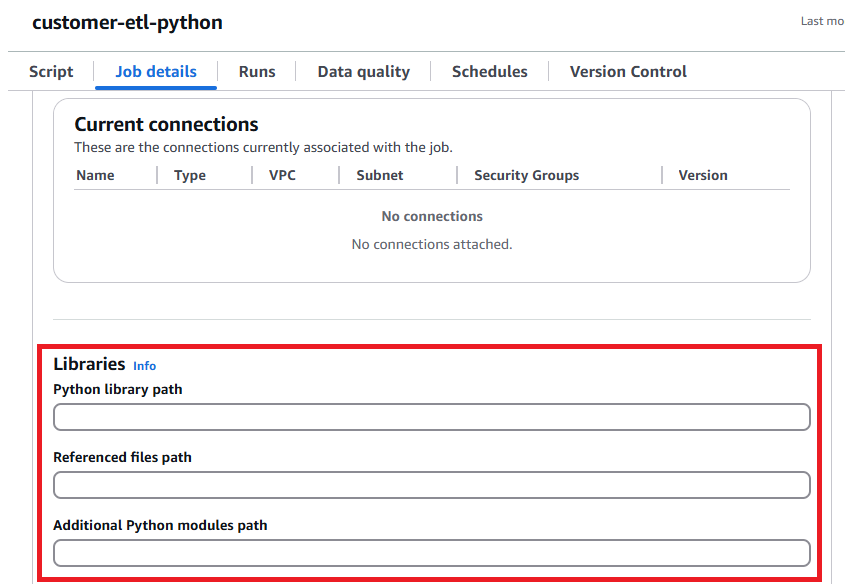
추가적으로 etl_script/customer-etl-python.py 파일을 통해서도 가능하지만, Glue Python Shell은 기본적으로 pandas, pyarrow가 없기에, .zip 파일로 압축 후 S3에 업로드하여 Glue Job의 Python library path를 지정해야한다.
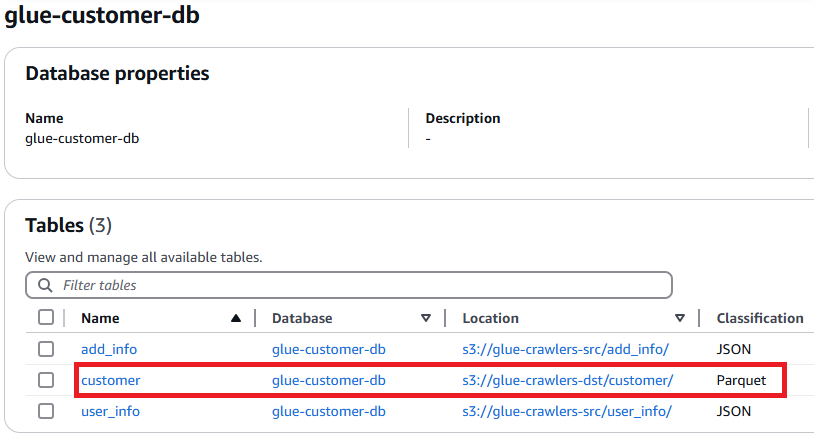
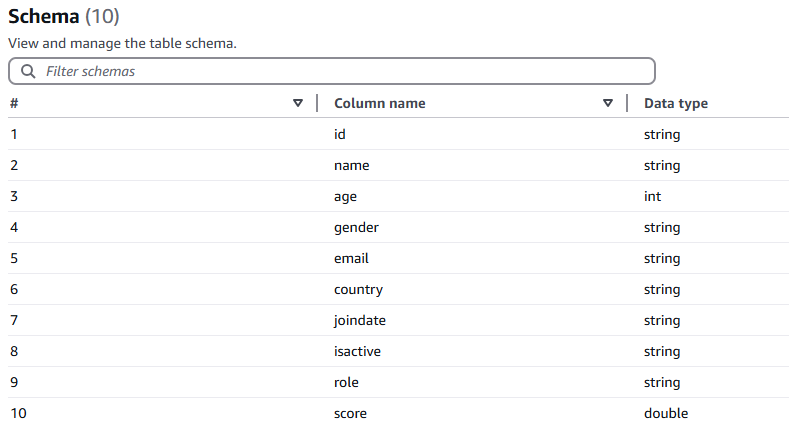
ETL 작업이 끝난 후, glue-crawlers-dst/customer/ 아래의 데이터를 크롤러를 통해 데이터 카탈로그화하고, 지정한 DB에서 확인한 화면이며, 해당 테이블의 스키마 정보를 확인 시 user_info, add_info 테이블을 "id" 기준으로 join 하여 총 10개의 컬럼이 있는 것을 확인할 수 있다.
참고로, Parquet(파켓) 형태로 저장한 이유는 압축률이 높고, 쿼리 성능을 향상시키며, 효율적인 데이터 액세스를 제공하여 많은 이점을 가지고 있기 때문이다.
만약 해당 포맷을 하고 싶지 않다면, ETL 작업 시 다른 포맷을 꿔서 작업을 진행하면 된다.
glueContext.write_dynamic_frame.from_options(
frame=joined_dyf,
connection_type="s3",
connection_options={"path": "s3://<DestinationBucket>/<DestinationPath>/"},
format="parquet" # 필요 시 format 변경
)Athena

먼저, Athena를 사용하기 위해서 쿼리 결과를 저장할 버킷을 설정해야 쿼리가 가능하다.
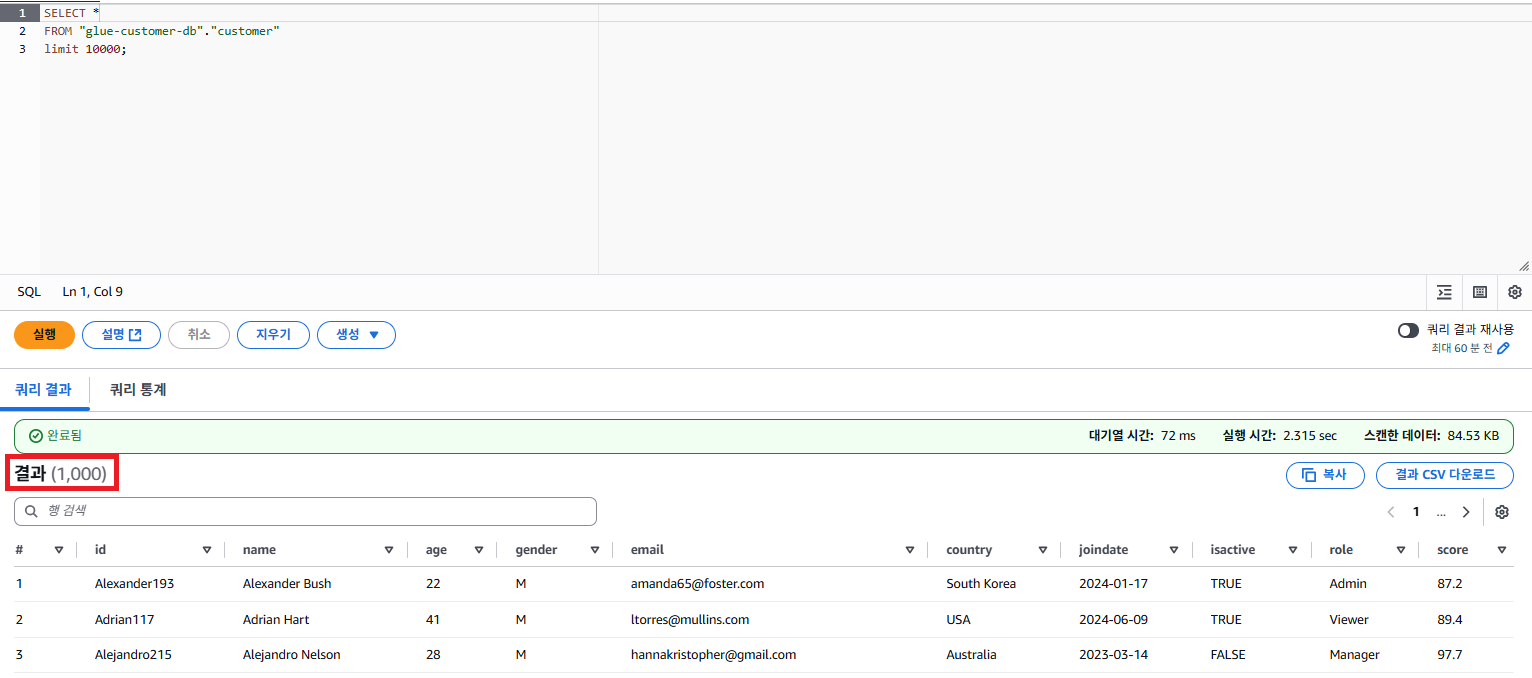
SELECT *
FROM "glue-customer-db"."customer"
limit 10000;쿼리문은 간단하게 Select 문을 통해 모든 데이터를 확인 시 모든 데이터에 대한 정보가 확인되는 것을 확인하였다.
Bedrock
Knowledge Bases
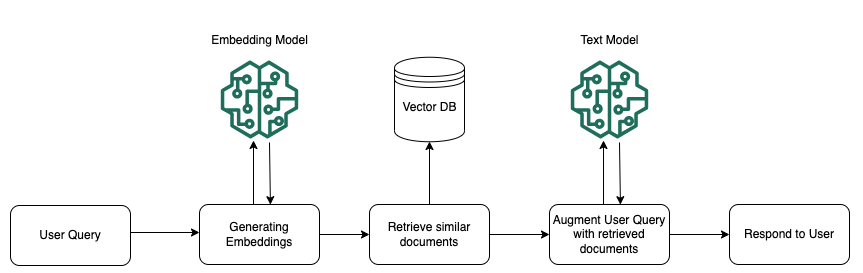
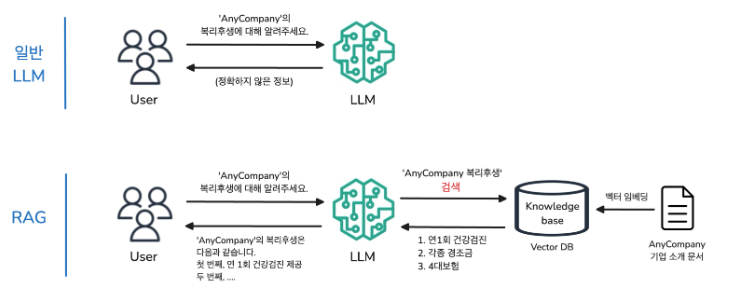
다음은 AWS 공식 문서에서 설명하는 지식 기반의 작동 방식으로, RAG(Retrieval-Augmented Generation)를 통해 사용자 쿼리에 어떻게 응답을 보완하고 증강하는지를 시각적으로 보여주는 그림이다.
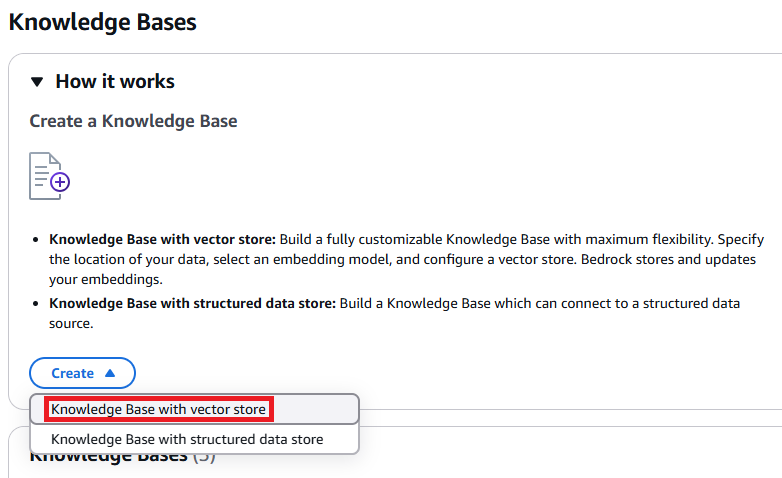
이후 생성할 Bedrock Agent 에서 SQL문에 대한 정확성과 신뢰도를 높이기 위해 지식 기반을 만들어야 한다. 자연어로 질문하면 Bedrock Agent는 쿼리할 데이터베이스에 어떤 스키마값이 정의 되어 있는지 알 수 없다. 그렇기 때문에 사전에 학습할 데이터를 추가 후 RAG(검색 증강) 기반 응답을 생성할 수 있도록 한다.
RAG(Retrieval-Augmented Generation)란?
RAG는 기존 LLM이 가진 지식의 한계를 보완하기 위해 고안된 구조이다.
단순히 모델에 질문을 던지는 것이 아닌, 질문에 관련된 외부 지식을 검색하여 함께 답변을 생성한다.
RAG 아키텍처

RAG 아키텍처 작동 흐름
- User -> Bedrock
- 사용자가 질문을 입력하면, Bedrock Agent가 이를 수신
- Knowledge Base 조회
- Bedrock은 내부에 연결된 Knowledge Base를 활용해 관련 정보를 검색
- Vector DB 등록
- Data의 경우 사전에 Vector Embedding 처리되어 Vector DB에 저장
- LLM 응답 생성
- 추출된 문서 내용을 바탕으로 Bedrock은 LLM을 호출해 정확도 높은 응답을 생성
- 응답 전달
- 사용자는 모델이 검색된 정보에 기반하여 생성된 응답을 확인
추가적인 설명이 필요하다면, Amazon Bedrock 지식 기반을 사용한 간소화된 RAG 구현해당 문서도 함께 참고하면 좋을 것 같다.
# 지식 기반의 신뢰 관계
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockKnowledgeBaseTrustPolicy",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<Account>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:ap-northeast-2:<Account>:knowledge-base/*"
}
}
}
]
}
# 지식 기반에서 사용할 IAM Role의 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockInvokeModelStatement",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel"
],
"Resource": [
"arn:aws:bedrock:ap-northeast-2::foundation-model/amazon.titan-embed-text-v2:0"
]
},
{
"Sid": "OpenSearchServerlessAPIAccessAllStatement",
"Effect": "Allow",
"Action": [
"aoss:APIAccessAll"
],
"Resource": [
"arn:aws:aoss:ap-northeast-2:<Account>:collection/<Opensearch Collection ID>"
]
},
{
"Sid": "S3ListBucketStatement",
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::<Knowledge-base-bucket>"
]
},
{
"Sid": "S3GetObjectStatement",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<Knowledge-base-bucket/prefix/*>"
]
}
]
}지식 기반에서는 위와 같은 Role, Policy를 미리 생성하거나, 지식 기반 생성 시 신규로 생성이 되도록 할 수 있다.
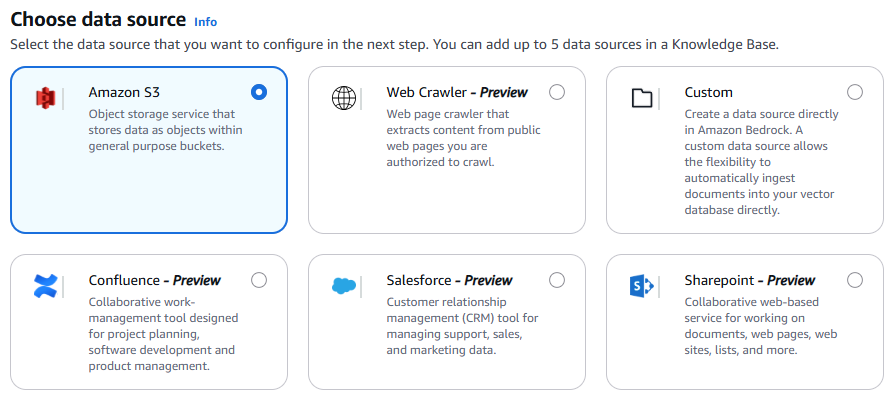
Data source는 S3를 선택하며, 지정한 버킷에 txt형태로 샘플쿼리, 샘플스키마를 업로드 할 예정이다.
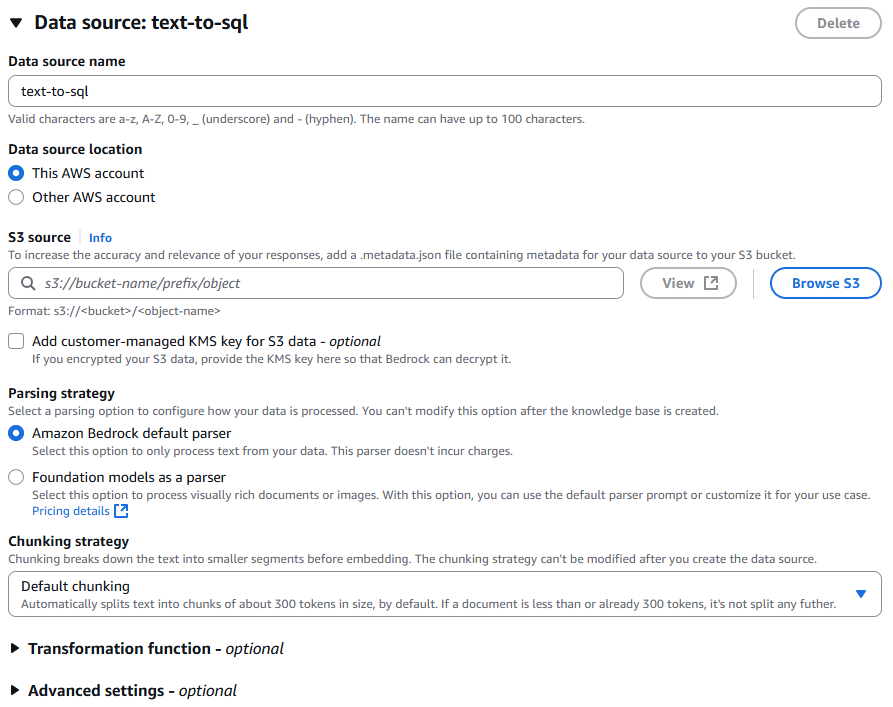
관련하여 설정을 하고, 실제 소스 버킷을 선택을 한다.
S3로 데이터 소스를 사용 시 Bedrock Knowledge Base에서는 JSON 파일 형식은 현재 지원되지 않아, 텍스트(.txt) 형식으로 변환하여 업로드해야한다. 기존 json을 txt 로 바꿔서 지식 기반을 마련하였다.
참고로, 지식 기반 데이터의 사전 조건 해당 문서에서 지원하는 확장자를 확인할 수 있다.
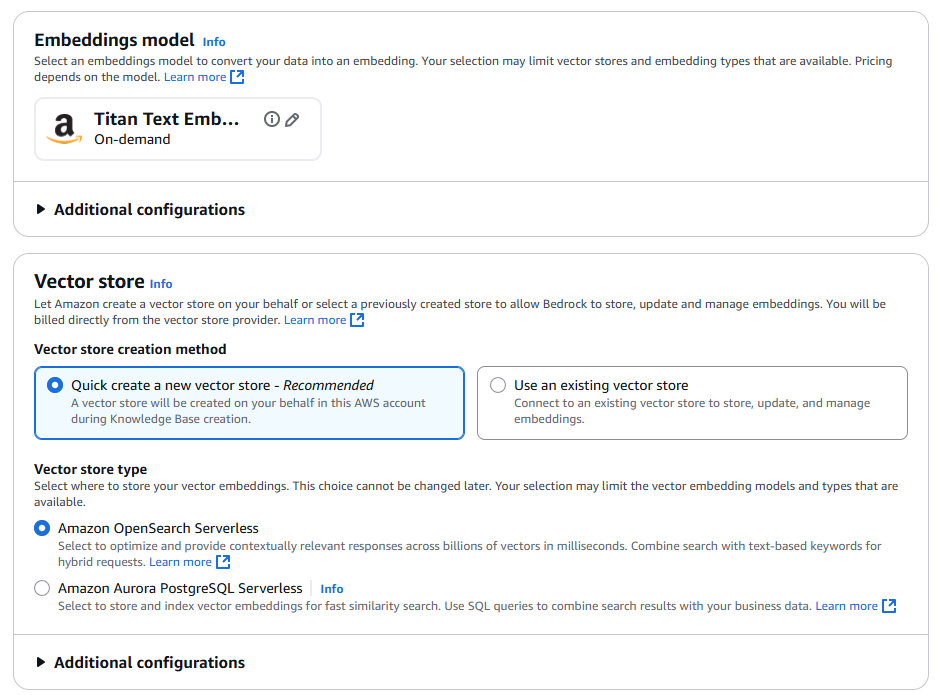
현재는 서울 리전 기준으로는 Titan Text Embeddings V2 임베딩 모델만 지원을 한다.
Vector Embedding 이란?
텍스트를 고차원 공간에서 수치화된 벡터로 변환하는 과정
텍스트의 의미와 유사성 파악을 위해 필수적인 단계이며, Embedding 결과는 벡터 공간에서 점으로 표현된다.
Vector Embedding 과정
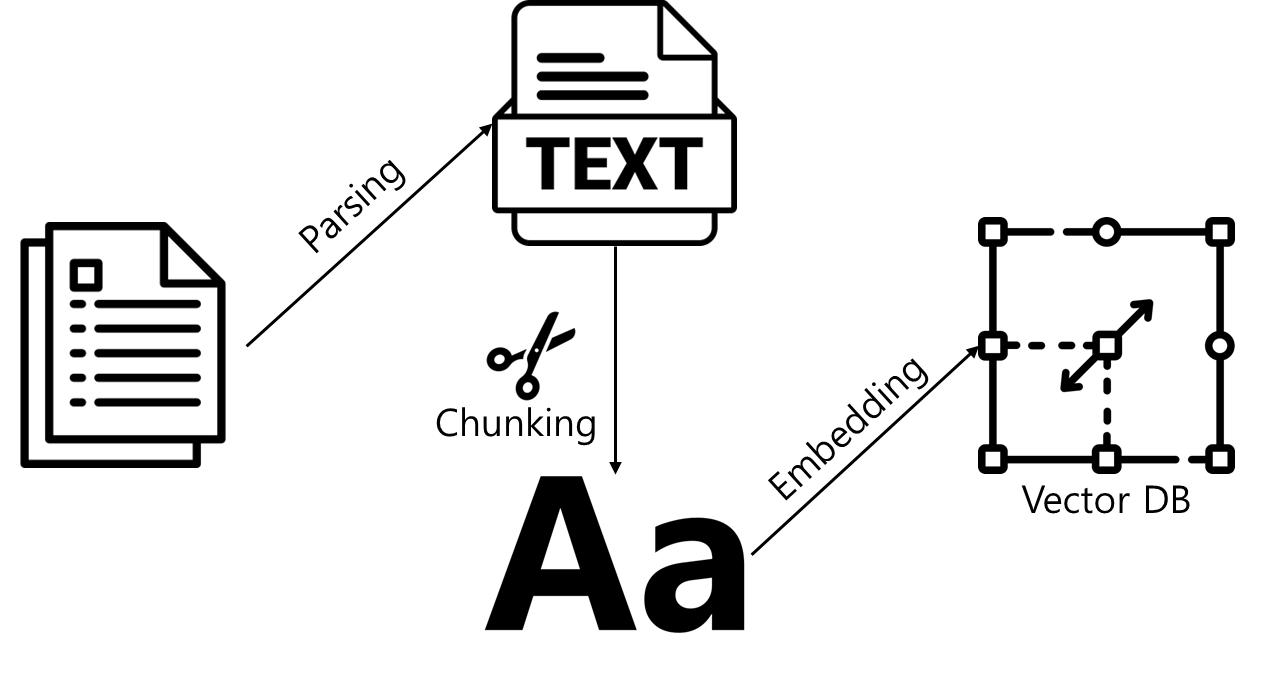
- 파싱(Parsing)
- S3에 업로드된 원시 문서에서 텍스트만 추출하는 과정
- 문서 내부의 목차, 표, 구분선 등을 고려해 가능한 자연스럽게 추출
- 청킹 (Chunking)
- 추출된 텍스트를 LLM이 처리할 수 있을 정도의 길이로 쪼개는 작업
- 기본 Chunk 크기는 약 200~300 단어 수준
- Overlap(겹침)도 설정되어 일부 문맥 연속성을 유지
- 임베딩 (Embedding)
- 나눠진 각 청크를 벡터로 변환하여 Vector DB에 저장
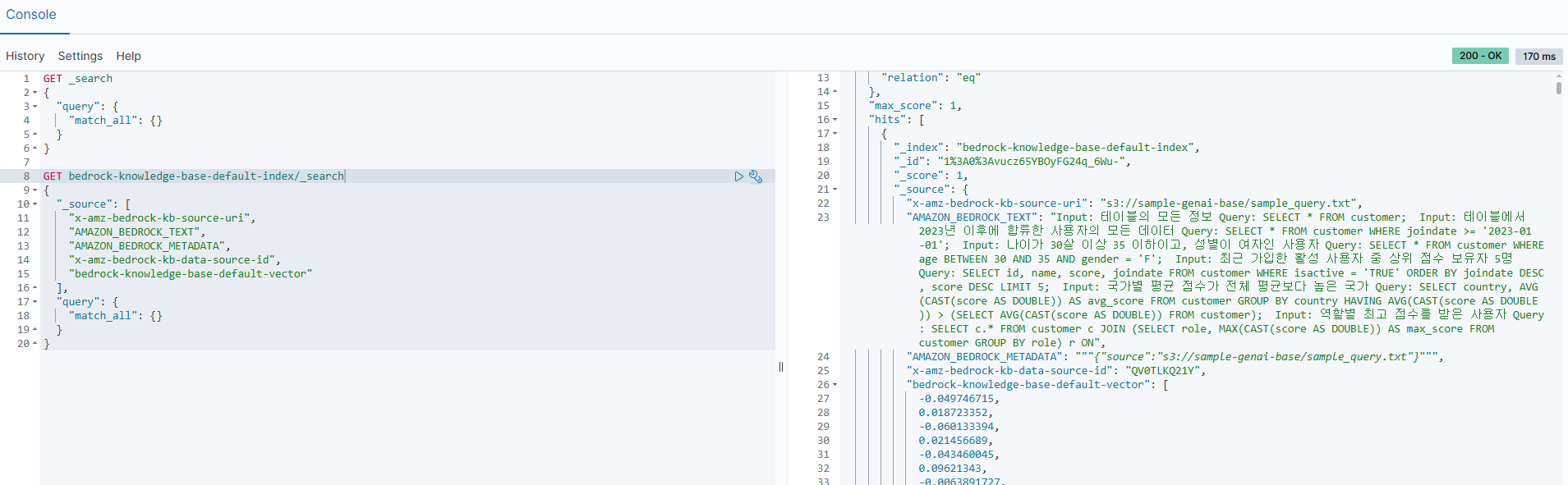
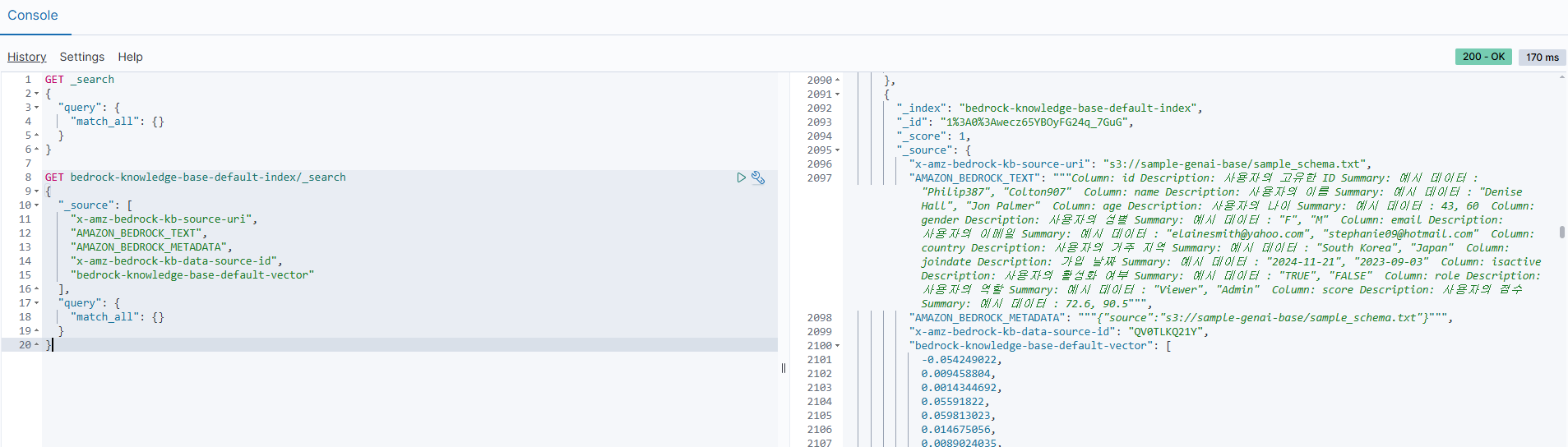
위 예시처럼 Opensearch 개발자 도구에서 샘플 쿼리에 대한 자연어 질문과 이에 매핑되는 벡터 임베딩 필드와 샘플 스키마의 경우 테이블, 컬럼에 대한 정보도 텍스트와 벡터 임베딩 필드로 저장이 된다.
해당 문서들은 LLM이 사용자의 요청에 알맞은 쿼리를 작성하기 위해 매우 중요한 사전 정보이다.
# OpenSearch 색인 데이터 조회 쿼리
GET bedrock-knowledge-base-default-index/_search
{
"_source": [
"x-amz-bedrock-kb-source-uri",
"AMAZON_BEDROCK_TEXT",
"AMAZON_BEDROCK_METADATA",
"x-amz-bedrock-kb-data-source-id",
"bedrock-knowledge-base-default-vector"
],
"query": {
"match_all": {}
}
}
# 예시 데이터
{
...중략...
{
"_index": "bedrock-knowledge-base-default-index",
"_id": "1%3A0%3Avucz65YBOyFG24q_6Wu-",
"_score": 1,
"_source": {
"x-amz-bedrock-kb-source-uri": "s3://sample-genai-base/sample_query.txt",
"AMAZON_BEDROCK_TEXT": "Input: 테이블의 모든 정보 Query: SELECT * FROM customer; Input: 테이블에서 2023년 이후에 합류한 사용자의 모든 데이터 Query: SELECT * FROM customer WHERE joindate >= '2023-01-01'; Input: 나이가 30살 이상 35 이하이고, 성별이 여자인 사용자 Query: SELECT * FROM customer WHERE age BETWEEN 30 AND 35 AND gender = 'F'; Input: 최근 가입한 활성 사용자 중 상위 점수 보유자 5명 Query: SELECT id, name, score, joindate FROM customer WHERE isactive = 'TRUE' ORDER BY joindate DESC, score DESC LIMIT 5; Input: 국가별 평균 점수가 전체 평균보다 높은 국가 Query: SELECT country, AVG(CAST(score AS DOUBLE)) AS avg_score FROM customer GROUP BY country HAVING AVG(CAST(score AS DOUBLE)) > (SELECT AVG(CAST(score AS DOUBLE)) FROM customer); Input: 역할별 최고 점수를 받은 사용자 Query: SELECT c.* FROM customer c JOIN (SELECT role, MAX(CAST(score AS DOUBLE)) AS max_score FROM customer GROUP BY role) r ON",
"AMAZON_BEDROCK_METADATA": """{"source":"s3://sample-genai-base/sample_query.txt"}""",
"x-amz-bedrock-kb-data-source-id": "QV0TLKQ21Y",
"bedrock-knowledge-base-default-vector": [
-0.049746715,
0.018723352,
-0.060133394,
0.021456689,
-0.043460045,
0.09621343,
-0.0063891727,
0.0012812513,
0.02692336,
-0.0329367,
...중략...
}
...중략...
}OpenSearch Dev Tools에서 실행한 _search 쿼리와 그 결과의 내용을 기반으로, 각 구성 요소와 의미를 정리하였다.
필드 설명
-
x-amz-bedrock-kb-source-uri
- 의미: 해당 색인 문서의 원본 데이터가 저장된 S3 URI
- 용도: Bedrock이 Knowledge Base 구축 시 참조한 실제 파일의 위치
-
AMAZON_BEDROCK_TEXT
- 의미: 해당 문서 또는 Chunk의 실제 텍스트 콘텐츠 (LLM이 응답 시 참고하는 원문)
- 용도:
- 사용자의 자연어 질문과 매칭되는 예시 쿼리나 스키마 정보가 저장
- Embedding 대상이기도 하며, LLM이 RAG 응답 생성 시 참고
-
AMAZON_BEDROCK_METADATA
- 의미: 색인 문서에 대한 추가 메타데이터 (JSON 형식)
- 용도: 검색 결과로 반환될 때 추가 정보 표시, 또는 후속 작업에서 원본 데이터의 출처를 명확히 하기 위한 용도로 사용
-
x-amz-bedrock-kb-data-source-id
- 의미: Bedrock Knowledge Base에서 이 데이터를 구성한 데이터 소스의 고유 ID
- 용도:
- Bedrock 콘솔 또는 API에서 특정 데이터 소스(S3 버킷 등)를 식별할 때 사용
- Knowledge Base 내에서 여러 데이터 소스를 관리하는 경우 추적이 가능
-
bedrock-knowledge-base-default-vector
- 의미:
AMAZON_BEDROCK_TEXT의 임베딩 벡터 (고차원 수치 표현) - 용도:
- LLM이 질문에 대한 의미 기반 유사도 검색을 수행할 때 사용
- OpenSearch 내 벡터 검색 엔진(k-NN)과 함께 작동하여 의미 유사한 문서를 검색
- RAG(Retrieval-Augmented Generation) 구조에서 핵심
- 의미:
Knowledge Bases 커스텀 청킹(선택 사항)
Knowledge Bases 에서 기본 청킹을 진행하게 된다면 텍스트를 약 300개의 토큰 크기(청크)로 분할을 한다. Bedrock 에서 테스트나 실제 사용에는 문제가 없었지만, OpenSearch에서 인덱스의 내용을 읽기에 불편함이 발생한다.

위 예시처럼 기본 청킹 결과는 한눈에 쿼리문을 확인하기 어려워, 가독성이 떨어질 수 밖에 없다.

내가 원하는 조건으로 청킹을 진행한다면, 인덱스의 정보를 더 쉽게 확인할 수 있을 것이다.
기본 청킹의 한계
문맥 단절
기본 청킹은 보통 300~500개 토큰 단위로 텍스트를 일정하게 나누기 때문에, SQL 쿼리문처럼 하나의 의미 덩어리로 묶여야 할 내용이 중간에 끊겨버릴 수 있다. 이로 인해 청크 하나만 봐서는 전체 의미를 파악하기 어려워진다.
OpenSearch에서의 가독성 저하
OpenSearch Dashboards에서는 각 도큐먼트(document)의 _source 필드를 한눈에 확인하기 때문에, 청크가 어중간하게 끊겨 있으면 input과 query 전체를 보기가 어렵고, 특정 쿼리나 질문을 바로 찾기 불편하다.
즉, 사람이 보기엔 비직관적이다.
지식 기반 응답 품질 저하 가능성
Bedrock은 청크 단위로 의미를 파악하기 때문에, 청킹된 데이터가 애매하면 응답 품질이 떨어질 수 있다.특히 질의와 응답(SQL)이 하나의 단위로 있어야 학습/검색 효율이 높아지는데, 그게 깨질 수 있다.

먼저, 커스텀 청킹을 위해서 작성자는 Opensearch Serverless를 미리 생성하였으며, 벡터 인덱스 이름, 필드 등 위와 같이 설정을 하였다. 지식 기반을 생성할 때 위와 같이 설정을 진행하였다.
벡터 인덱스 이름 : text2sql-index
벡터 필드 이름 : text2sql-vector
텍스트 필드 이름 : text2sql-text
메타데이터 필드 이름 : text2sql-metadata
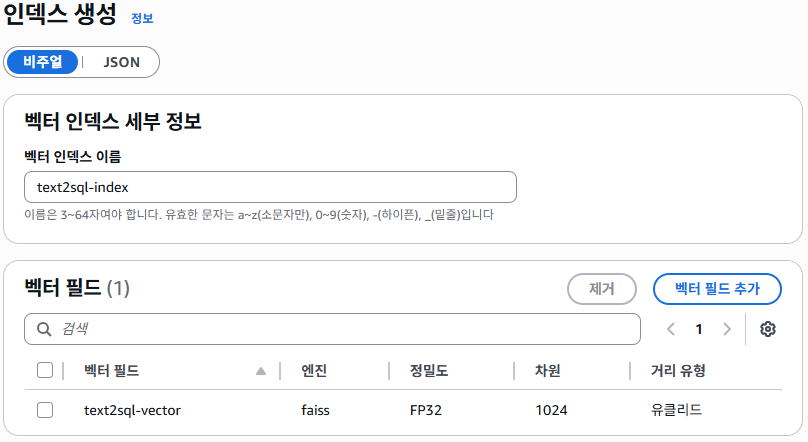
Opensearch의 컬렉션에서 인덱스 생성 시 지식 기반에서 설정한 인덱스, 필드 등 동일하게 맞춰야 한다.
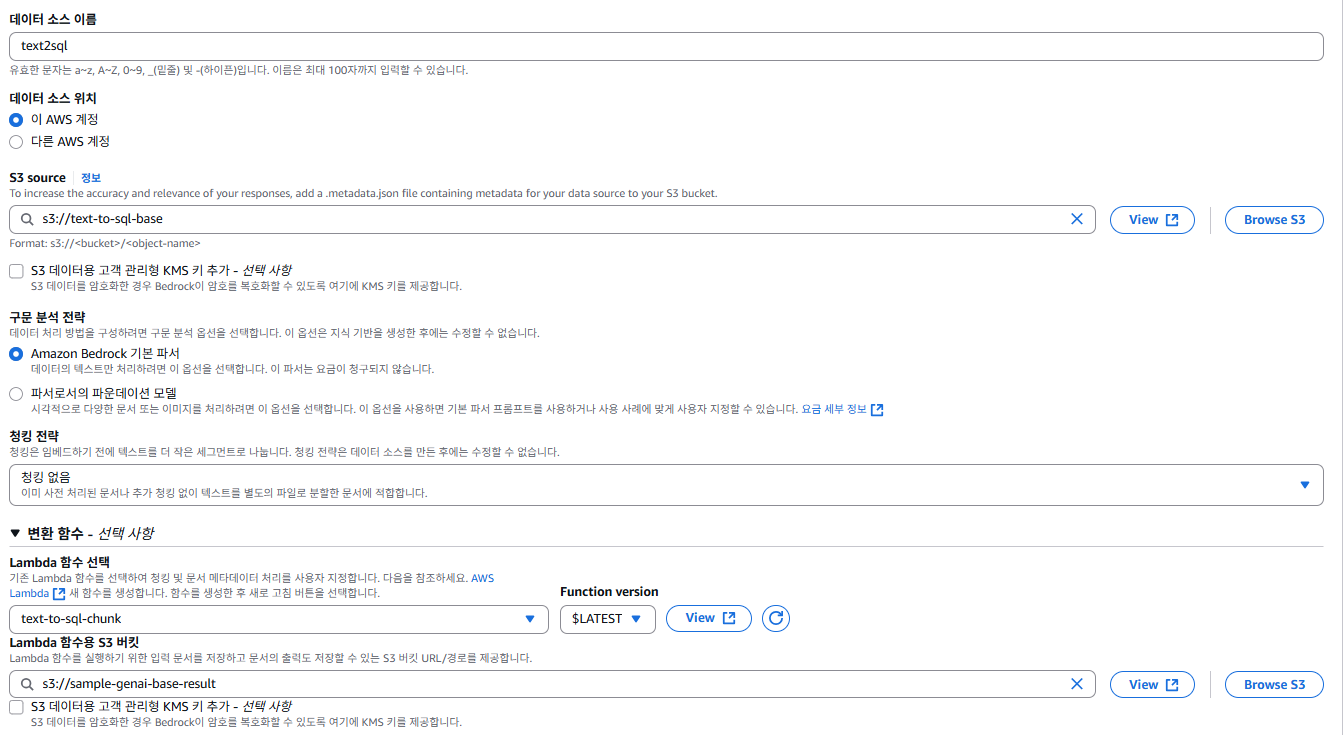
설정에서 유의할 점이청킹 전략에서 ‘청킹 없음’을 선택해야, Bedrock이 자동으로 처리하지 않고 Lambda에서 커스텀 청킹이 가능하다.
여기서 S3 source는 sample_knowedge-bases폴더 아래의 json 데이터만 있는 버킷을 지정하였다.
Lambda 함수용 S3 버킷이 필요한 이유는 기존 Source 버킷의 파일 내용을 JSON 형태로 가져와 Lambda 로 처리하기 위해 존재한다.
# Bedrock 동기화 시 Lamba 로 전달 받는 이벤트 예시
{
"version": "1.0",
"knowledgeBaseId": "KQXIRZR24J",
"bucketName": "sample-genai-base-result",
"dataSourceId": "XOJT4DO3QJ",
"ingestionJobId": "CYOVVSL4VA",
"priorTask": "CHUNKING",
"inputFiles": [
{
"contentBatches": [
{
"key": "aws/bedrock/knowledge_bases/KQXIRZR24J/XOJT4DO3QJ/CYOVVSL4VA/sample_query_1.JSON"
}
],
"originalFileLocation": {
"type": "S3",
"s3_location": {
"uri": "s3://text-to-sql-base/sample_query.json"
}
}
}
]
}내용에 대한 자세한 사항은 Lambda를 통한 데이터 청킹해당 문서를 참고하면 좋을 것 같다.
커스텀 청킹에 관련하여 내용을 이해와 return을 위한 json 포맷 많은 어려움이 있었다. Github의 Lambda 청킹 함수를 참고하길 바라며...
또한, 청킹 관련하여 좀 더 자세한 사항은 문서인 컨텐츠 청킹에서 좀 더 다양한 내용을 확인할 수 있다.
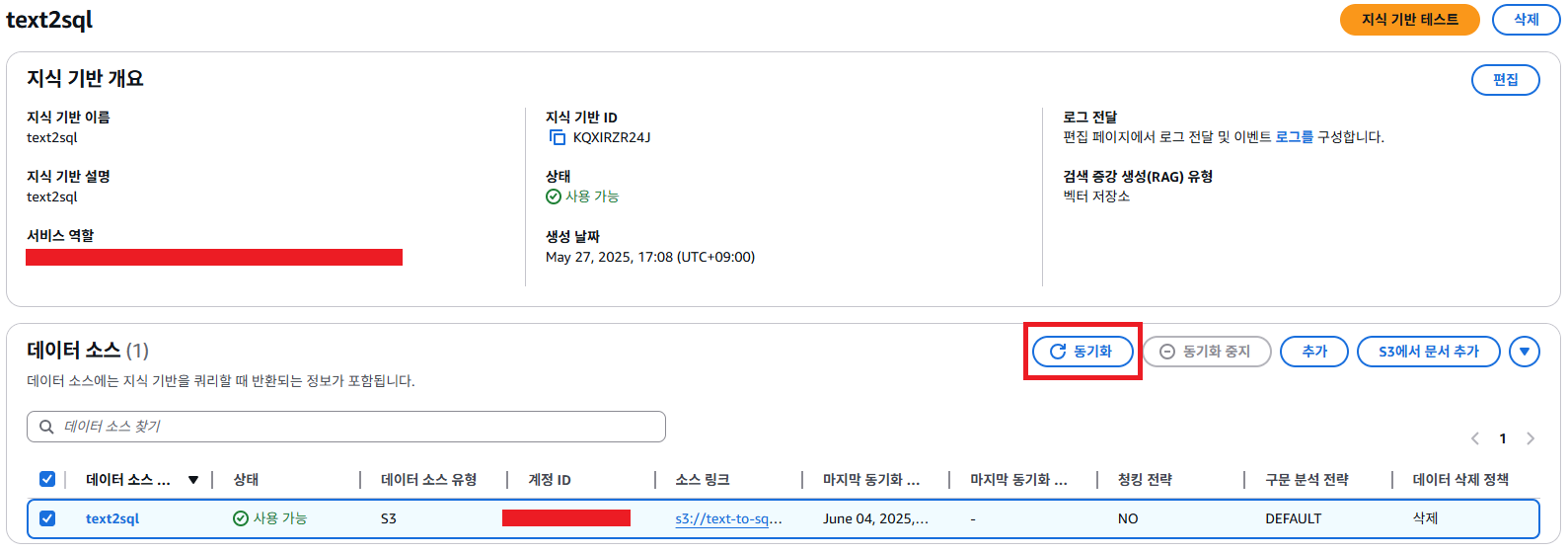
지식 기반에서 데이터 소스 생성이 완료 되었다면, 동기화를 클릭 후 Lambda가 실행이 되었다면, 아래 S3를 확인해보자.
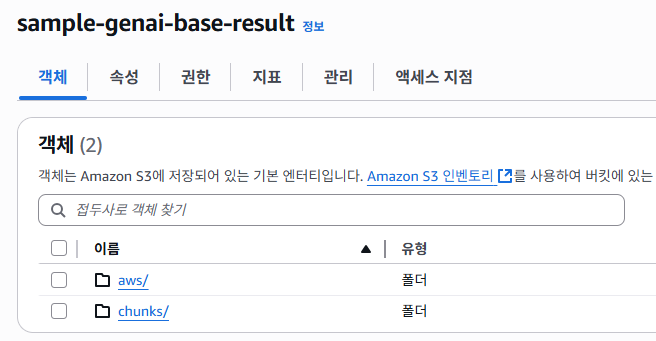
Lambda용 S3 버킷에 aws/, chunk/ 라는 폴더가 생성이 되었다.
aws 폴더에는 위 설명과 같이 Source 버킷의 파일 내용을 JSON 형태로 가져온 파일들이 있을 것이다.

aws/bedrock/knowledge_bases/<지식 기반 ID>/<데이터 소스 ID>/<작업 ID>/ 경로 확인 시 위와 같이 파일이 존재하며, 파일의 내용 예시는 아래와 같다.
{
"fileContents": [
{
"contentType": "PLAIN_TEXT",
"contentBody": "<본문 내용>",
"contentMetadata": {}
}
]
}
# sample_query_1.JSON
{
"fileContents": [
{
"contentType": "PLAIN_TEXT",
"contentBody": "[\n {\n \"input\": \"테이블의 모든 정보\",\n \"query\": \"SELECT * FROM customer;\"\n },\n {\n \"input\": \"2023년 이후에 합류한 사용자의 모든 데이터\",\n \"query\": \"SELECT * FROM customer WHERE joindate >= '2023-01-01';\"\n }\"input\": \"가장 많은 사용자를 보유한 역할과 그 사용자들의 평균 점수\",\n \"query\": \"SELECT role, ROUND(AVG(CAST(score AS DOUBLE)), 1) AS avg_score FROM customer WHERE role = (SELECT role FROM customer GROUP BY role ORDER BY COUNT(*) DESC LIMIT 1) GROUP BY role;\"\n }\n]",
"contentMetadata": {}
}
]
}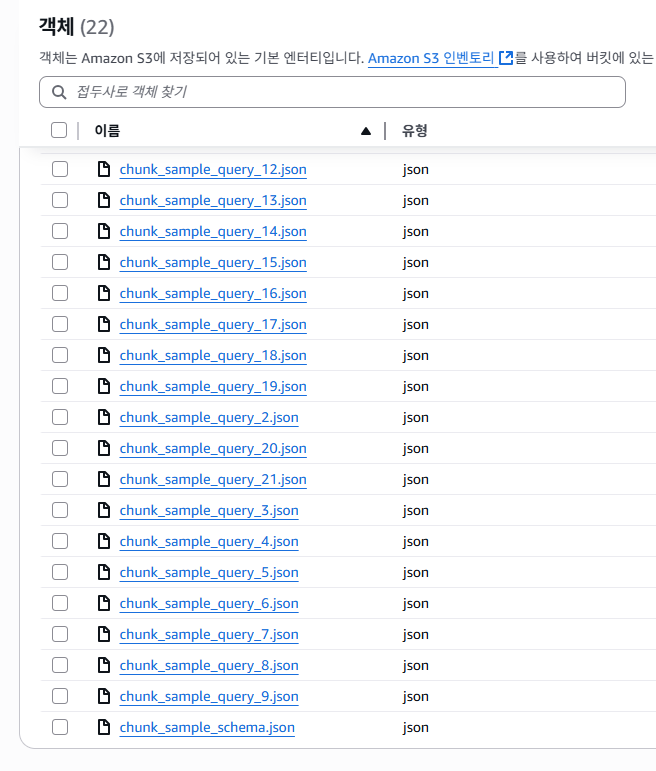
chunk/ 폴더 아래에는 커스텀하게 청킹한 22개의 객체가 있는 것을 확인할 수 있다.
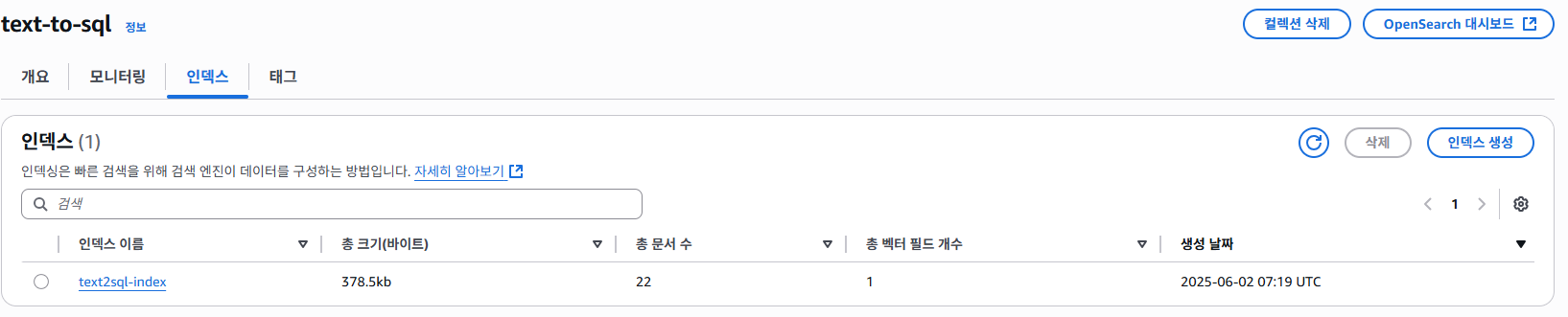
이전 생성했던 인덱스를 확인 시 문서는 총 22개로 Lambda를 사용한 커스텀 청킹 문서의 갯수 만큼 존재하는 것을 확인할 수 있다.
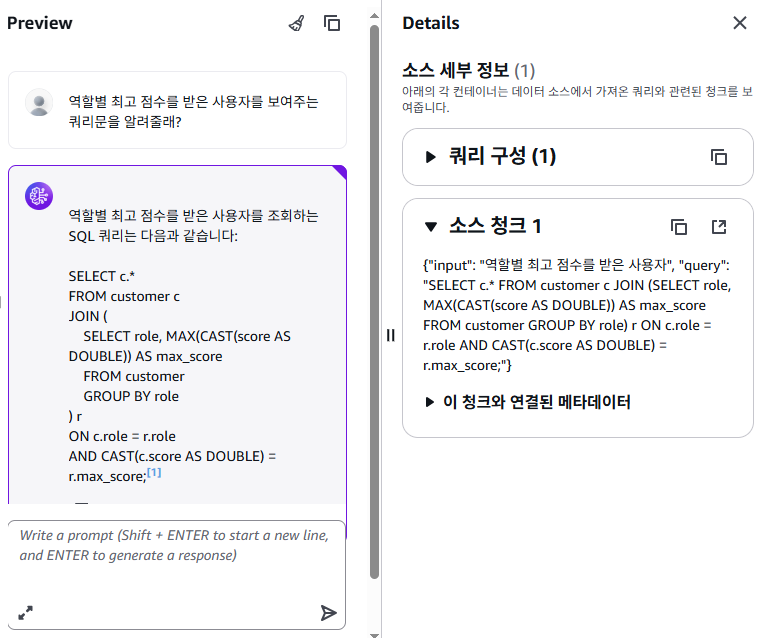
또한, 지식 기반 테스트에서는 샘플 쿼리에 대한 쿼리문 요청 시 Opensearch에 인덱싱된 필드를 참조하여 답변을 준 것을 확인할 수 있다.
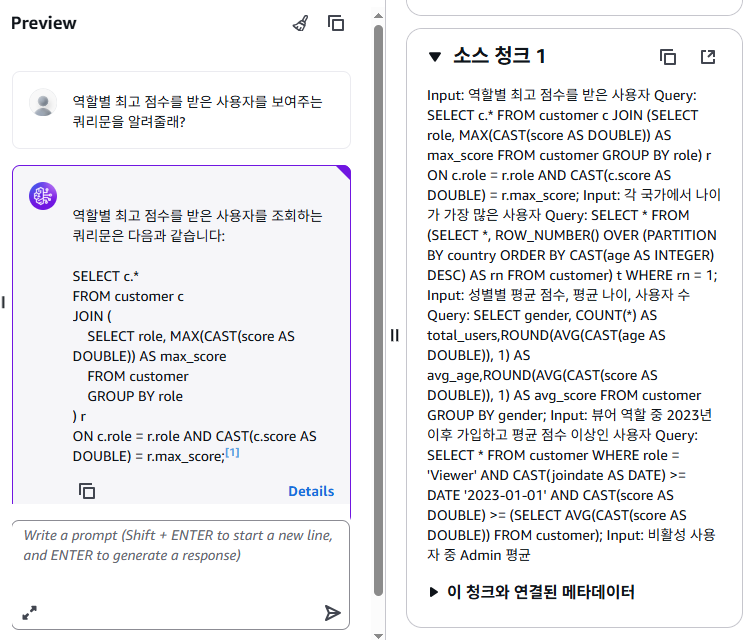
커스텀 청킹을 하지 않았다면, Details 를 눌러 어떤 소스를 참고했는지 확인 시 가독성이 현저하게 떨어지는 것을 알 수 있다.
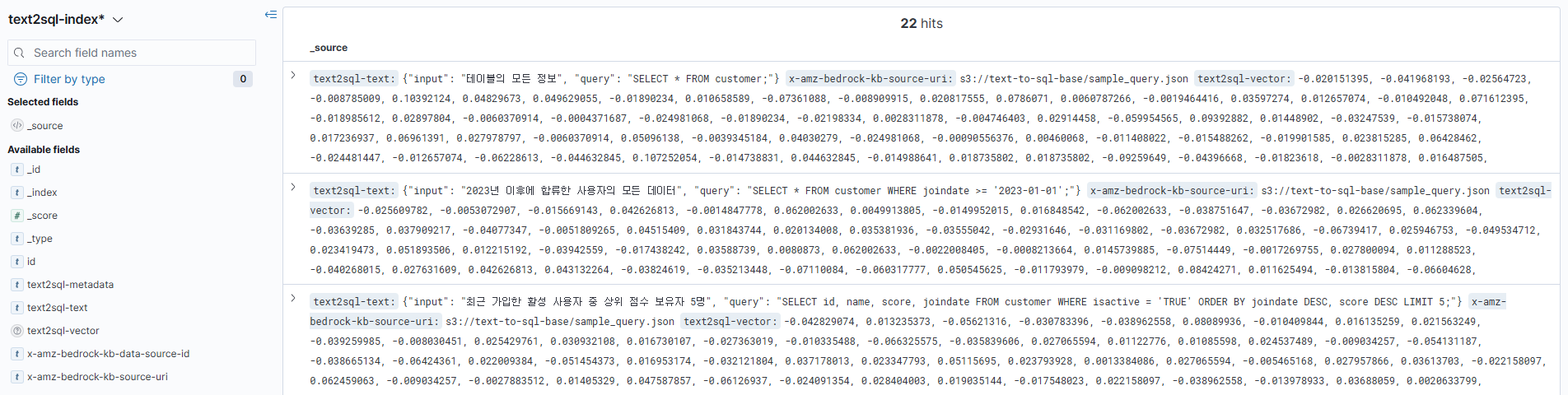
위는 Opensearch에서 index에 존재하는 각 Document와 Field에서는 샘플 쿼리에 대한 내용이 하나씩 있는 것을 확인할 수 있다.
커스텀 청킹을 통해서 Bedrock을 더 신뢰성과 정확성을 높이고자 한 내용이며, 이 부분은 사용자에 맞게 선택 사항으로 작업을 진행하면 될 것 같다.
Agent

Bedrock Agent는 프롬프트, 지식 기반, 사용자 요청을 조합하여 자동 질의응답 시스템을 구성할 수 있는 서비스이며, 사용자가 직접 Agent를 손쉽게 커스텀하여, 단순한 LLM 호출이 아니라 고급 제어와 설정을 통해서 자연어에 대한 SQL문 작성을 위해 설정을 진행한다.
# Bedrock Agent 의 신뢰 관계
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockAgentBedrockFoundationModelPolicyProd",
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "<Account>"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:ap-northeast-2:<Account>:agent/*"
}
}
}
]
}
# Bedrock Agent 의 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AmazonBedrockAgentBedrockFoundationModelPolicyProd",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [ # 사용할 모델 기입
"arn:aws:bedrock:ap-northeast-2::foundation-model/anthropic.claude-v2:1",
"arn:aws:bedrock:ap-northeast-2::foundation-model/anthropic.claude-3-haiku-20240307-v1:0",
"arn:aws:bedrock:ap-northeast-2::foundation-model/anthropic.claude-3-5-sonnet-20240620-v1:0"
]
},
{
"Sid": "AmazonBedrockAgentRetrieveKnowledgeBasePolicyProd",
"Effect": "Allow",
"Action": [
"bedrock:Retrieve"
],
"Resource": [
"arn:aws:bedrock:ap-northeast-2:<Account>:knowledge-base/<knowledge-base-id>"
]
}
]
}에이전트 빌더
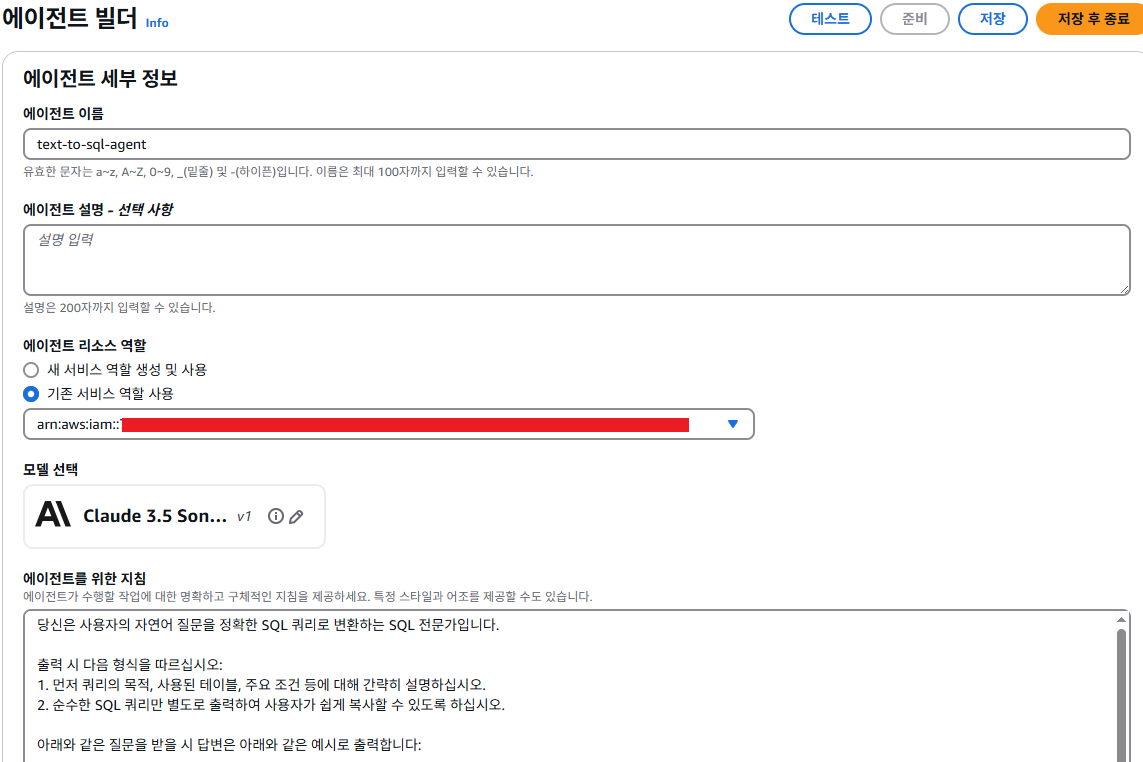
설정에서 사용할 Model 은 Claude 3.5 Sonnet이며, 에이전트 지침은 agent_instructions.txt 파일의 내용을 참고하면 좋은 응답을 받을 수 있을 것이다.
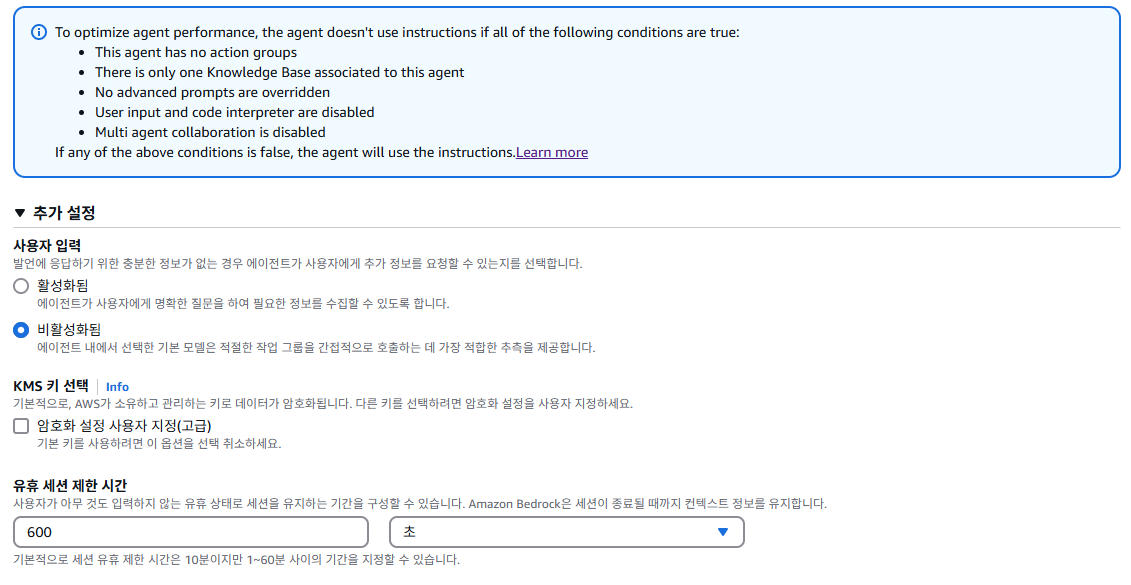
사용자 입력 기능이 비활성화된 경우, 에이전트는 명확한 추가 정보를 얻지 못해 지침을 제대로 따르지 못할 수 있다. 지침에 맞춰서 답변을 받아야 하기에 현재 설정에서 활성화가 필수이다.
조건
- 이 에이전트에는 작업 그룹이 없습니다.
- 이 에이전트와 연관된 지식 기반은 하나뿐입니다.
- 고급 프롬프트가 무시되지 않습니다.
- 사용자 입력 및 코드 인터프리터가 비활성화되었습니다.
- 다중 에이전트 협업이 비활성화되었습니다.
사용자 입력 기능
- 사용자가 질문에 충분한 정보를 제공하지 않았을 때, 에이전트가 추가 정보를 묻도록 허용하는 기능이다.
- 이 기능을 비활성화하면, 에이전트는 추가 질문을 하지 않고 단순 지침만 따르려 함.
왜 지침을 따르지 않을까?
- 컨텍스트 부족: 에이전트가 사용자로부터 명확한 정보를 받지 못한 상태에서 질문도 하지 못하므로, 지침에 따라 행동할 수 있는 충분한 조건을 갖추지 못함.
- LLM의 한계: 지침이 추상적이거나 다양한 해석이 가능한 경우, 사용자로부터 명시적인 추가 정보를 받지 못하면 작성한 에어전트 지침을 따르지 않고, 모델이 불완전하거나 엉뚱한 출력을 할 수 있음.
- Bedrock 에이전트 구성 한계: 일부 지침은 "반드시 이 조건이 충족될 때만 실행하라"처럼 설계되어 있는데, 사용자 입력 없이 조건을 판별할 수 없는 경우 무시되거나 제대로 작동하지 않을 수 있음.

이전 대화의 내용에서 사용자 요청에 대하여 정확하고 신뢰성 높은 답변을 위해서는 메모리 기능을 사용한다.
메모리 기능
Bedrock 에이전트의 메모리는 이전 대화 이력을 요약하여 저장하고, 이후 세션에서 이를 참조할 수 있는 기능입니다. 이를 통해 에이전트는 사용자와의 연속된 맥락을 인식하고 일관된 응답을 제공한다.
메모리 주요 구성 요소
- Session Summarization 활성화: 에이전트가 각 세션을 요약해 메모리에 저장.
- Memory duration: 요약을 유지할 기간 (예: 30일).
- Recent sessions 수 제한: 최근 몇 개 세션까지만 요약을 유지할지 설정 (예: 20개).
- Summarization Prompt: 세션 요약을 생성할 때 사용하는 프롬프트(기본 제공, 수정 가능).
테스트
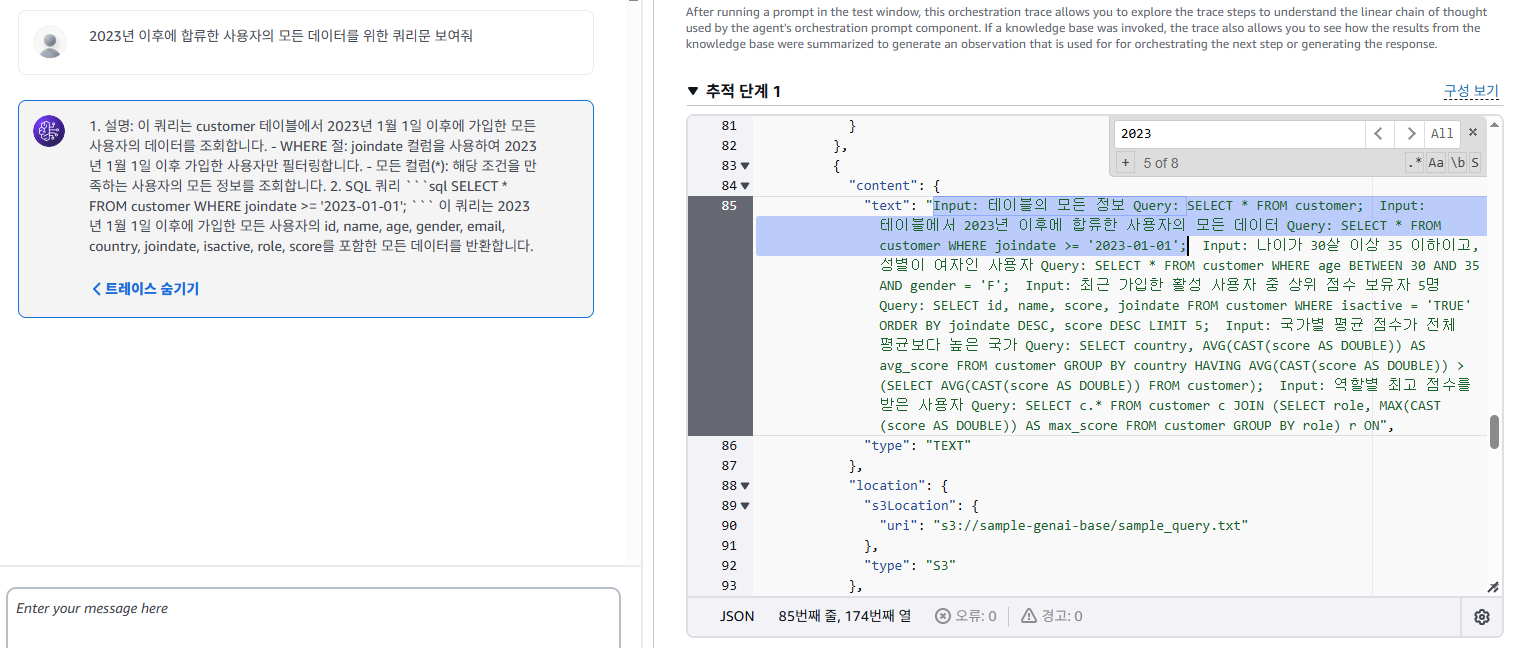
"2023년 이후에 합류한 사용자의 모든 데이터" 라는 요청을 하였고, 샘플 쿼리에 있는 내용 중 하나로 질문 시 에이전트가 지식 기반을 활용하여 질문과 가장 근접한 내용을 찾고, 이에 대한 내용을 반환하는 것을 확인할 수 있었다.
--생성한 SQL
SELECT * FROM customer WHERE joindate >= '2023-01-01';
--지식 기반에 있는 샘플 쿼리
SELECT * FROM customer WHERE joindate >= '2023-01-01';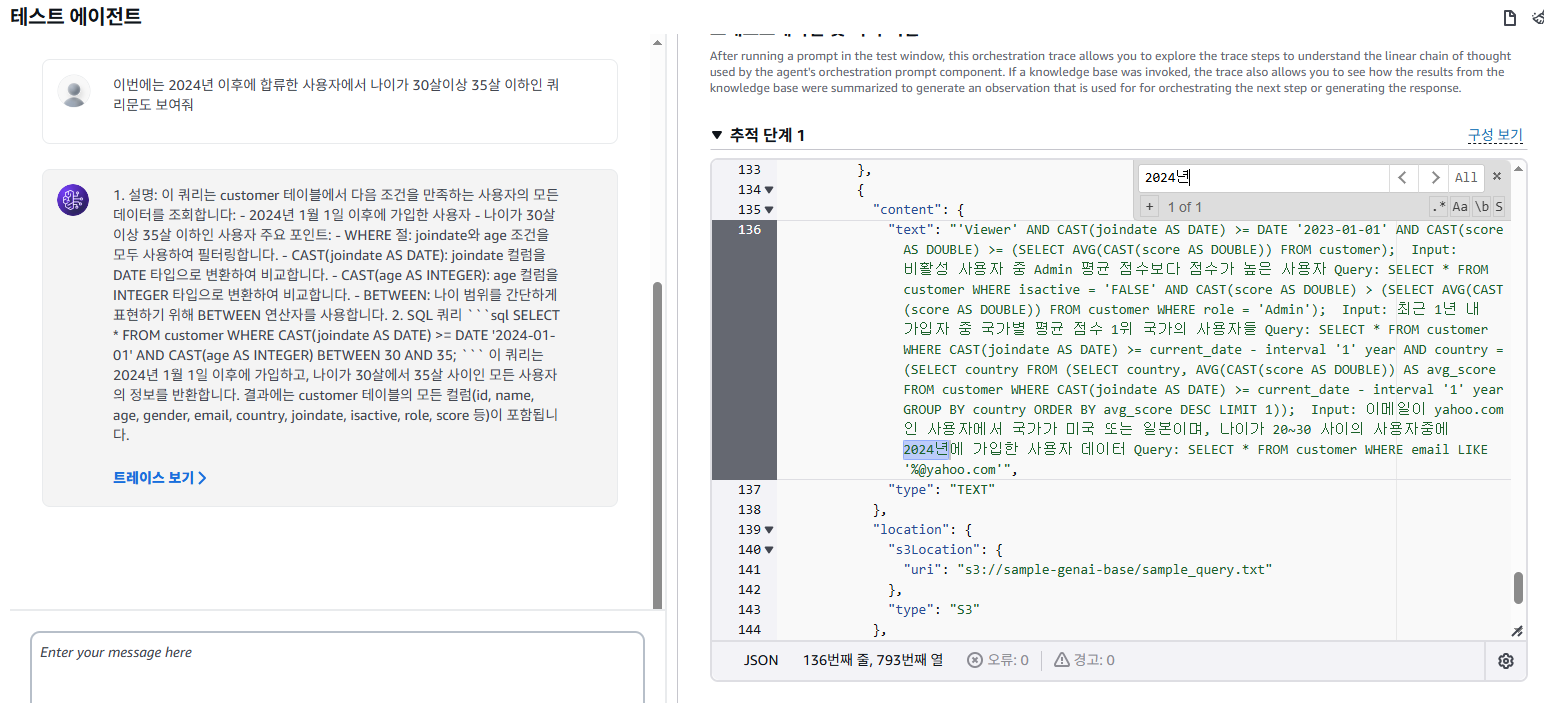
"2024년 이후에 합류한 사용자에서 나이가 30살이상 35살 이하" 인 데이터 요청 시 지식 기반에서는 샘플 쿼리가 없었는데, LLM 자체가 자연어 이해 + SQL 작성 능력을 통해 질문을 이해하고 SQL 문법을 적용해 스스로 쿼리를 생성을 한 것을 확인할 수 있었다.
--생성한 SQL
SELECT * FROM customer WHERE CAST(joindate AS DATE)>=DATE'2024-01-01' AND CAST(age AS INTEGER)BETWEEN 30 AND 35;동작 단계
질문을 이해하고 SQL 쿼리를 생성하는 프로세스는 다음과 같다.
| 단계 | 설명 |
|---|---|
| 1. 자연어 파싱 | 사용자의 질문을 문법적으로 분석하고, 핵심 조건을 추출 예: “2024년 이후”, “나이 30~35세” |
| 2. 조건 매핑 | SQL 조건으로 바꿔야 할 부분을 식별 예: 날짜 비교는 CAST(joindate AS DATE) >= DATE '2024-01-01', 나이는 CAST(age AS INTEGER) BETWEEN 30 AND 35 |
| 3. 테이블 구조 추정 | "customer" 테이블에 있는 컬럼 이름들(id, name, joindate, age 등)을 기존 답변이나 문맥에서 유추하거나 전형적인 이름을 사용 |
| 4. SQL 생성 | 위의 조건과 구조를 바탕으로 전체 SQL 문을 구성 |
| 5. 설명 생성 | 쿼리에 대한 설명을 자연어로 만들어 사용자에게 함께 제공 |
지식 기반이 없어도 답변할 수 있는 이유
- LLM은 이미 수많은 SQL 예제를 학습한 덕분에, 데이터베이스 스키마가 완전히 주어지지 않더라도 일반적인 패턴에 맞게 쿼리를 생성할 수 있다.
- "고정된 쿼리"가 없더라도, 질문에 포함된 조건을 바탕으로 즉석에서 쿼리를 생성하는 능력을 갖추고 있다.
EC2
EC2 정책
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults"
],
"Resource": "*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetDatabase"
],
"Resource": [
"arn:aws:glue:ap-northeast-2:<Account>:catalog",
"arn:aws:glue:ap-northeast-2:<Account>:table/<Glue DB Name>/<Glue Table Name>",
"arn:aws:glue:ap-northeast-2:<Account>:database/<Glue DB Name>"
]
},
{
"Sid": "VisualEditor2",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetBucketLocation"
],
"Resource": [
"arn:aws:s3:::<Athena Result Bucket>",
"arn:aws:s3:::<Athena Result Bucket>/*"
]
},
{
"Sid": "VisualEditor3",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::<Query Bucket>",
"arn:aws:s3:::<Query Bucket>/*"
]
},
{
"Sid": "VisualEditor4",
"Effect": "Allow",
"Action": [
"bedrock:InvokeAgent"
],
"Resource": [
"arn:aws:bedrock:ap-northeast-2:<Account>:agent-alias/<Agent ID>/*"
]
}
]
}Text-to-SQL 환경 구성 시 위와 같은 정책이 EC2에 부여가 되어야 한다.
Bedrock Agent를 호출하여 SQL문을 요청해야 하며, Glue, Athena, S3는 Bedrock에서 응답받은 SQL문을 통해 쿼리를 수행해야한다.
EC2 패키지 설치
# 패키지 및 개발 도구 설치
yum update -y
yum groupinstall -y "Development Tools"
yum install -y gcc openssl-devel bzip2-devel libffi-devel wget
# zlib-devel xz-devel readline-devel sqlite-devel
# Python 3.9.18 다운로드 및 압축 해제
cd /usr/src
wget https://www.python.org/ftp/python/3.9.18/Python-3.9.18.tgz
tar xzf Python-3.9.18.tgz
cd Python-3.9.18
# Python 컴파일 및 설치
./configure --enable-optimizations
make
make altinstall # 기존 python 보존
cd ..
# pip 설치
curl -O https://bootstrap.pypa.io/get-pip.py
python3.9 get-pip.py
# 심볼릭 링크 (선택적)
ln -s /usr/local/bin/python3.9 /usr/bin/python3
ln -s /usr/local/bin/pip3.9 /usr/bin/pip3
# 설치 확인 (작성자 기준)
python3.9 --version
-> Python 3.9.18
python3 --version
-> Python 3.9.22
readlink -f $(which python3.9)
-> /usr/local/bin/python3.9
eadlink -f $(which python3)
-> /usr/bin/python3.9
pip3.9 --version
-> pip 23.0.1 from /usr/local/lib/python3.9/site-packages/pip (python 3.9)환경은 AmazonLinux2023 으로 진행을 하였고, Python버전은 3.9.18버전으로 진행하였다.
작성자를 기준으로 설정한 내용이며, Python 버전에 따른 패키지 버전도 차이가 발생할 수 있다는 점을 유의해야 한다.
EC2 설정
# 홈 디렉토리로 이동
cd ~
# 프로젝트 디렉토리 생성 및 이동
mkdir text2sql
cd text2sql
# Python 3.9 기반 가상환경 생성
python3.9 -m venv venv
# 가상환경 활성화
source venv/bin/activate
# requirements.txt에 정의된 패키지 설치
pip3.9 install -r requirements.txt
# 설치된 패키지 목록 확인
pip3.9 list
# 아래 패키지는 필수 설치이며, 의존성에 의해 다른 패키지도 함께 설치가 된다. (작성자 기준)
streamlit==1.45.1
boto3==1.38.19
pandas==2.2.3
# Streamlit 앱 백그라운드 실행, nohup은 터미널 종료 후에도 계속 실행
nohup streamlit run app.py --server.port=8080프로젝트를 위한 디렉토리 설정 및 애플리케이션 기동 시 연결된 ALB, 또는 EC2 로 지정한 포트로 접속이 가능하다.
ALB 사용한다면, 80 or 443 Port로 사용하며, EC2 직접 접근 시에는 지정한 Port로 브라우저에서 접속을 진행한다.
테스트
구성도
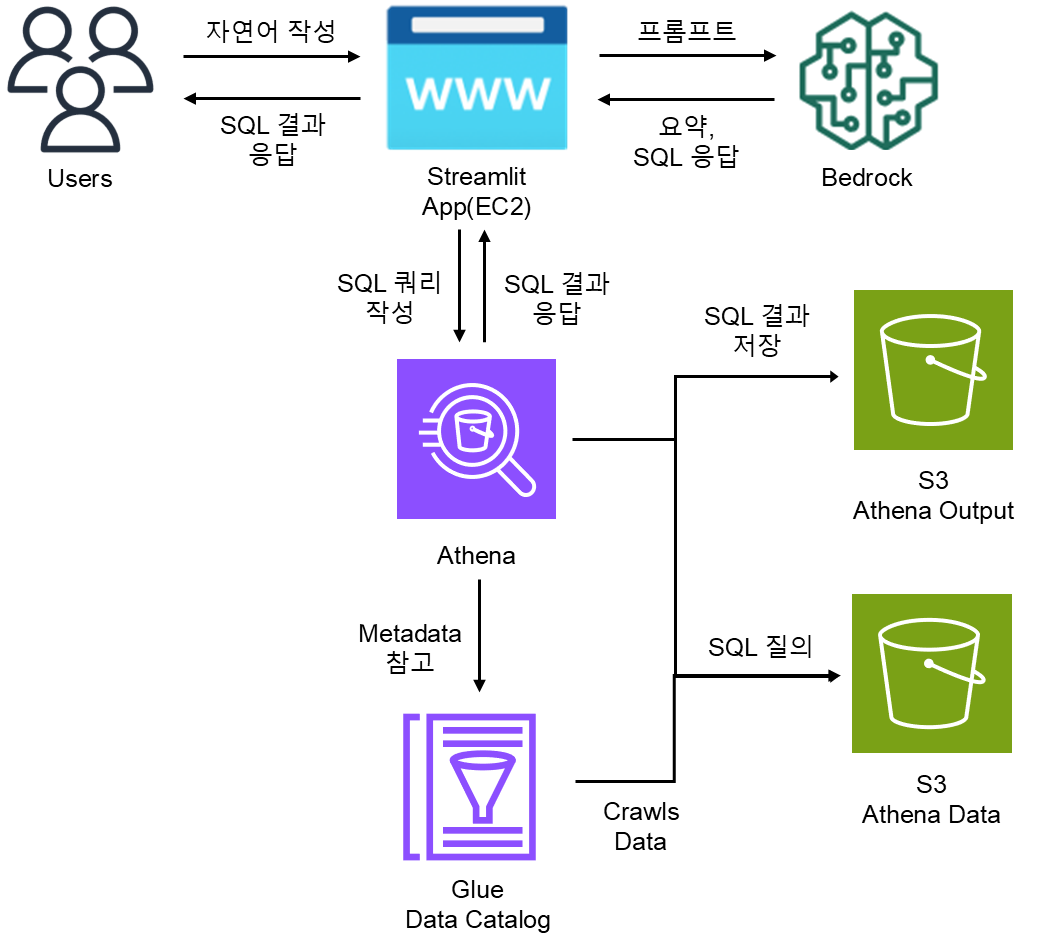
Text-to-SQL 부분을 더 자세하게 풀어낸 아키텍처이다.
샘플 쿼리 기반 테스트
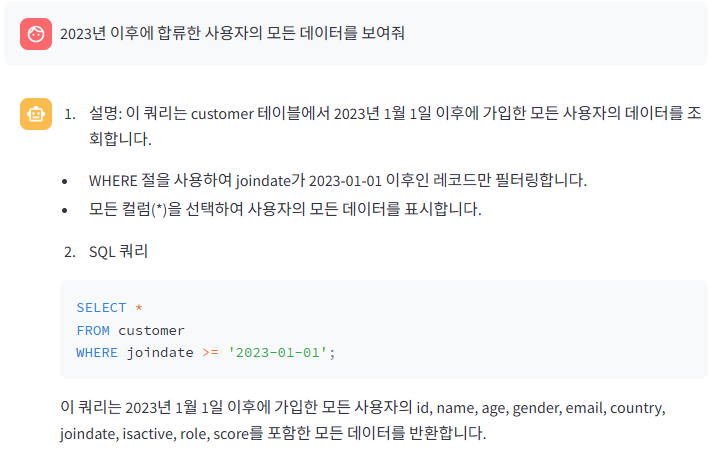
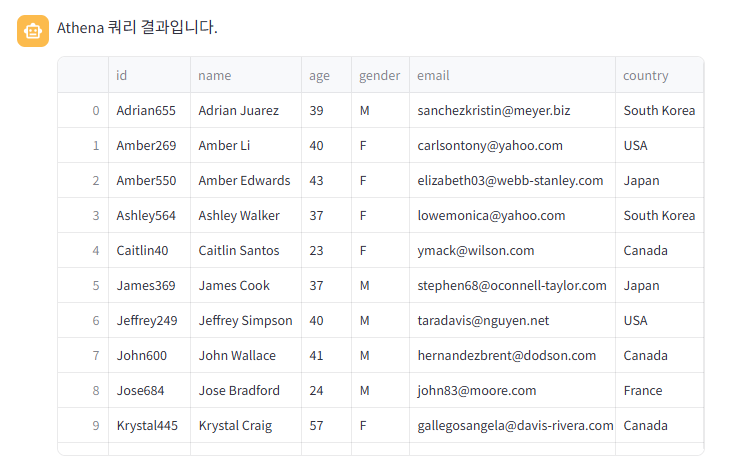
처음 질문은 지식 기반에 있는 내용이며, "2023년 이후에 합류한 사용자의 모든 데이터"를 보여달라고 하였고, AWS 콘솔에서 테스트한 쿼리문과 동일한 내용을 반환한 것을 확인할 수 있었다.
샘플 쿼리 외 테스트
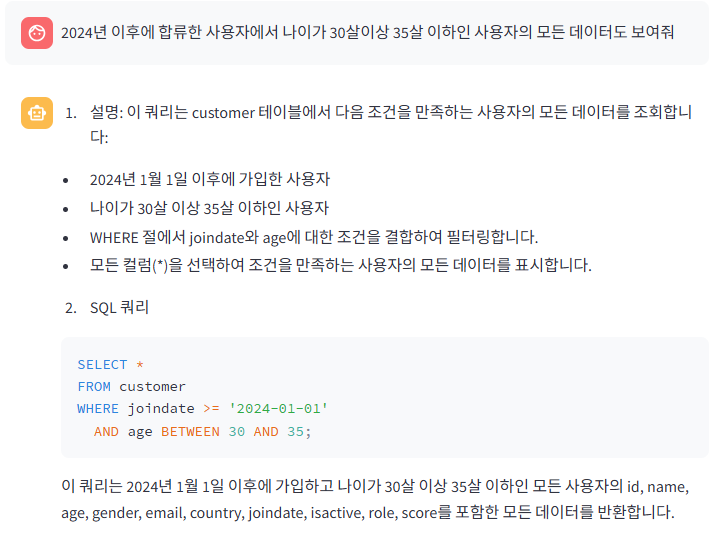
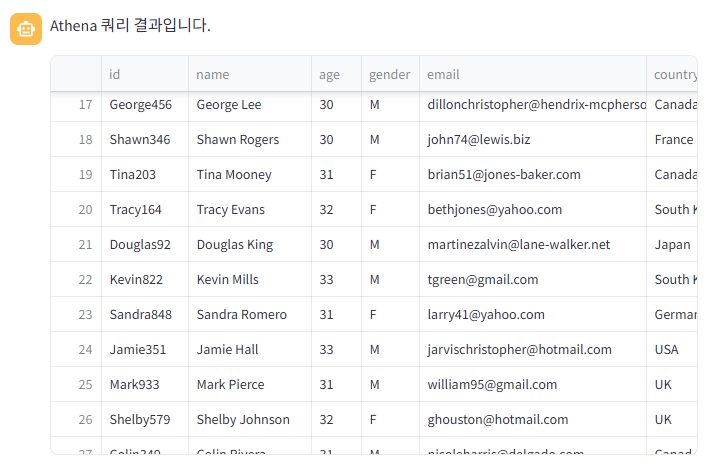
"2024년 이후에 합류한 사용자에서 나이가 30살이상 35살 이하인 사용자의 모든 데이터도 보여줘" 라는 질문을 하였고, AWS 콘솔에서 테스트한 쿼리문과는 다르지만, 결과는 동일한 쿼리문을 작성하여 데이터를 반환해준 것을 확인을 하였다.
--AWS 콘솔 기반 테스트
SELECT * FROM customer WHERE CAST(joindate AS DATE)>=DATE'2024-01-01' AND CAST(age AS INTEGER)BETWEEN 30 AND 35;
--Bedrock API를 사용한 테스트
SELECT * FROM customer WHERE joindate >= '2024-01-01' AND age BETWEEN 30 AND 35;심화 테스트
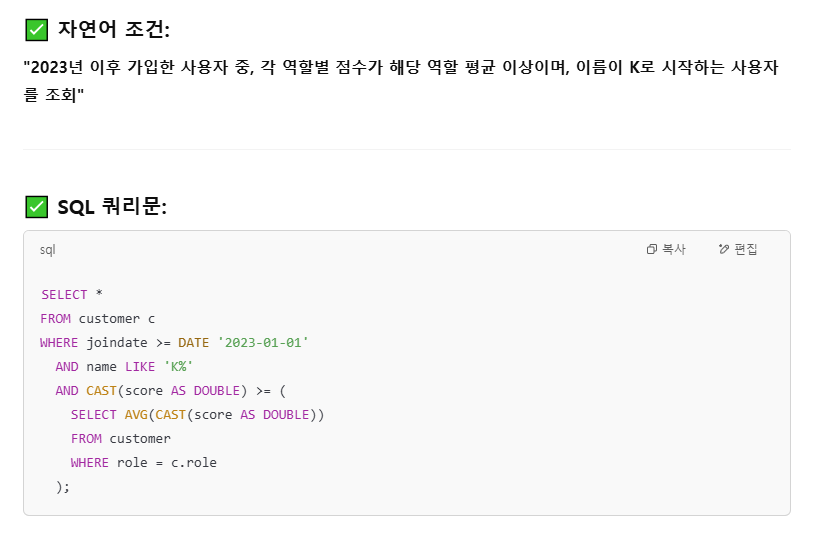
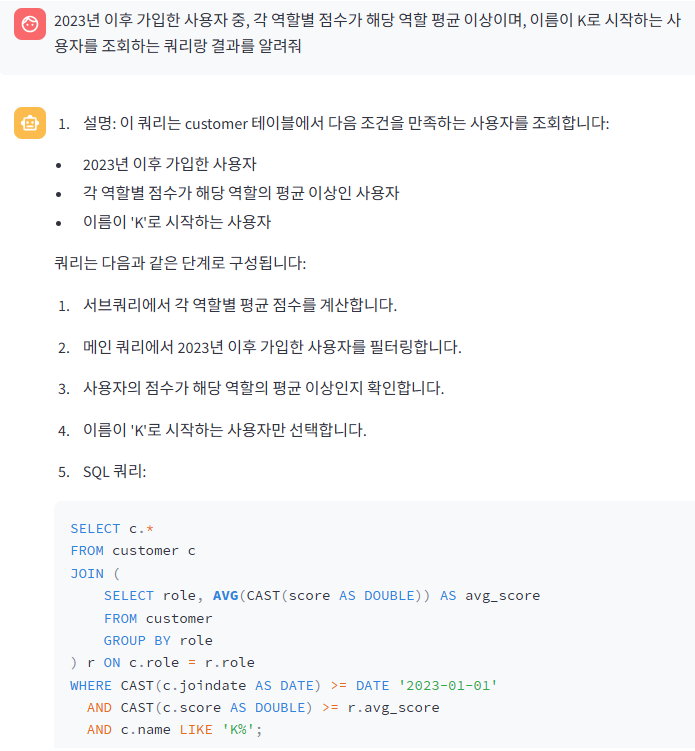
Chat GPT를 사용하여 "2023년 이후 가입한 사용자 중, 각 역할별 점수가 해당 역할 평균 이상이며, 이름이 K로 시작하는 사용자를 조회하는 쿼리랑 결과를 알려주는 SQL문을 작성해줘" 라는 입력을 하였다.
먼저 위 쿼리에서는 joindate 컬럼의 데이터 타입이 varchar인 반면, 비교 대상은 DATE '2023-01-01'로 DATE 타입이기 때문에 쿼리가 실패할 것이다. 즉, varchar 타입과 date 타입 간 비교는 허용되지 않는다.
그렇기에 아래와 같은 쿼리로 수정하여 Athena 에서 직접 쿼리를 수행한 결과를 보겠다.
SELECT *
FROM customer c
WHERE CAST(joindate AS DATE) >= DATE '2023-01-01'
AND name LIKE 'K%'
AND CAST(score AS DOUBLE) >= (
SELECT AVG(CAST(score AS DOUBLE))
FROM customer
WHERE role = c.role
);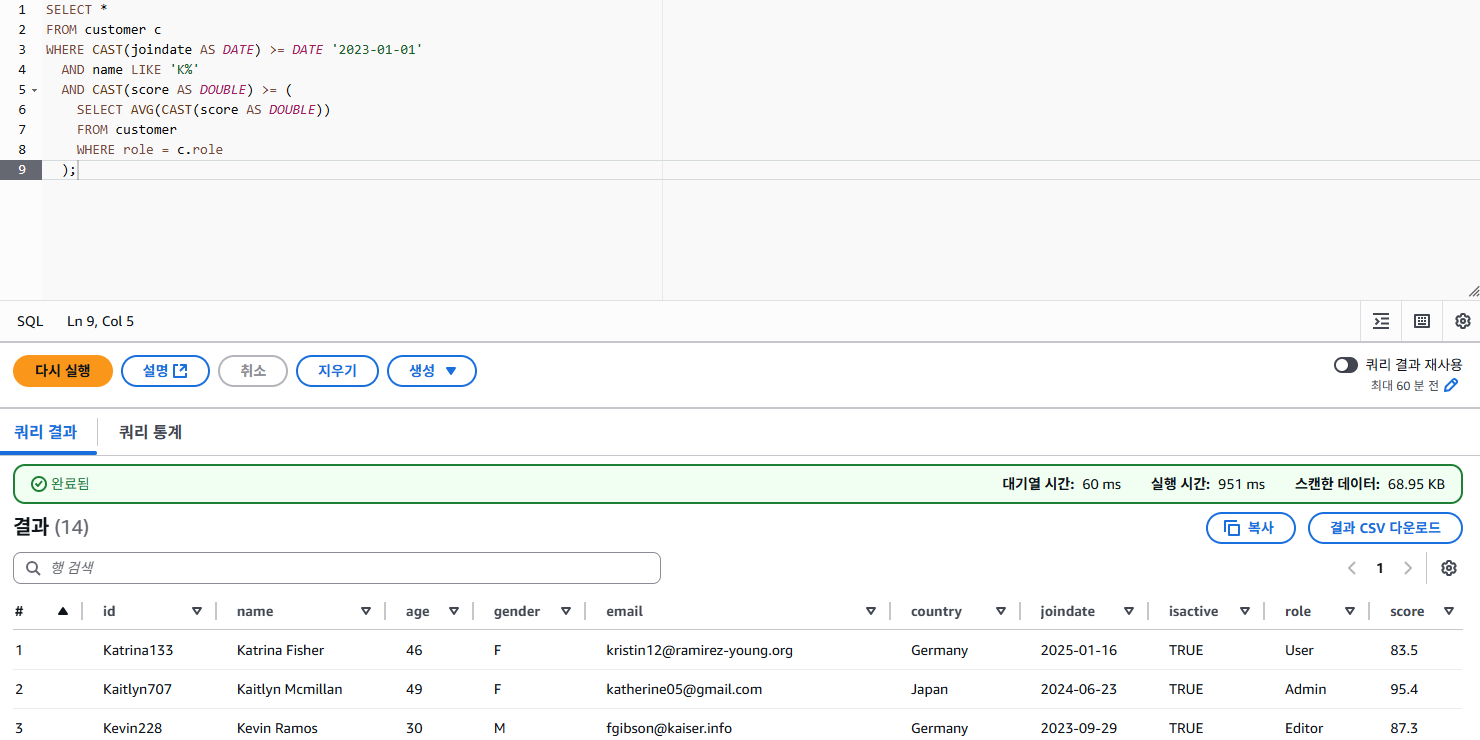
수정된 쿼리 사용 시 총 14개의 데이터가 나온 것을 확인할 수 있었다.
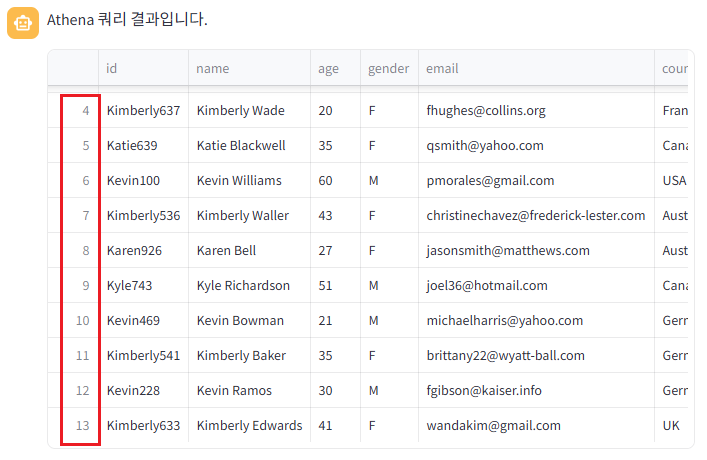
"2023년 이후 가입한 사용자 중, 각 역할별 점수가 해당 역할 평균 이상이며, 이름이 K로 시작하는 사용자를 조회하는 쿼리랑 결과를 알려줘" 라는 질문을 하였고, GPT가 구현한 SQL과 Bedrock을 사용하여 나온 쿼리의 결과는 동일한 결과값을 보여준 것을 확인할 수 있었다. (쿼리 결과는 0번 row부터 시작하여 13번이 마지막)
결론적으로 GPT는 데이터에 대한 정보가 부족하여 joindate 컬럼의 데이터 타입을 알 수 없어, 쿼리문 수정을 했지만, Bedrock의 지식 기반 덕분에 테이블 스키마 정보를 이해하고, 정확한 쿼리를 한 번에 생성할 수 있었다.
마무리
요즘 GenAI가 뜨거운 주제인데, 이번 Text-to-SQL 시스템을 직접 만들어보면서 왜 많은 기업들이 이런 서비스를 도입하는지 실감할 수 있었다. 실제로 AI 서비스를 활용하니 반복 작업이 줄고, 분석 흐름도 훨씬 효율적으로 구성할 수 있어서 생산성이 눈에 띄게 향상된다는 걸 느꼈다.
처음 다뤄보는 서비스들이 많아 어려움도 있었지만, 하나씩 정리하고 개념을 익히며 직접 써보는 과정을 통해 점점 익숙해졌고, 결국 나만의 AI 기반 분석 시스템을 완성할 수 있었다는 점에서 큰 보람을 느꼈다.
특히, S3 기반의 데이터 수집부터 Glue ETL, Athena 분석, 그리고 Bedrock + OpenSearch를 활용한 자연어 질의 응답까지 전체 데이터 파이프라인을 직접 구성해보면서 AWS 생태계 내에서의 통합적 데이터 활용 방안을 몸소 체험할 수 있었다.
그 중에서도 Bedrock의 Agent와 Knowledge Base를 활용한 RAG 기반 아키텍처는 응답 정확도나 실무 적용 가능성 면에서 꽤 인상적이었고, 앞으로 AI 기반 분석 플랫폼을 구축할 때 강력한 무기가 될 수 있다고 생각했다.
무엇보다도, 처음에는 어렵게만 느껴졌던 생성형 AI 서비스들을 익히고 활용해보며 '나도 AI 서비스를 직접 만들 수 있구나' 하는 자신감을 얻은 것이 이번 경험에서 가장 큰 수확이었다.
