Cloudwatch Agent
Amazon CloudWatch Agent는 AWS에서 제공하는 모니터링 도구로, EC2 인스턴스나 온프레미스 서버에서 운영 체제 수준의 메트릭과 로그를 수집해 CloudWatch로 전송하는 역할을 한다. 기본적인 시스템 메트릭 외에도 사용자 지정 메트릭과 로그 수집도 가능하여, 인프라 모니터링을 보다 정밀하게 수행할 수 있다.
Architecture

설치 및 설정
- IAM Role 생성 및 IAM Policy 연결
- EC2 인스턴스의 IAM Role 연결
- CloudWatch Agent 설치
- CloudWatch Agent로 Memory 및 Disk 사용량 확인
- 알람 설정
IAM Role 생성 및 IAM Policy 연결
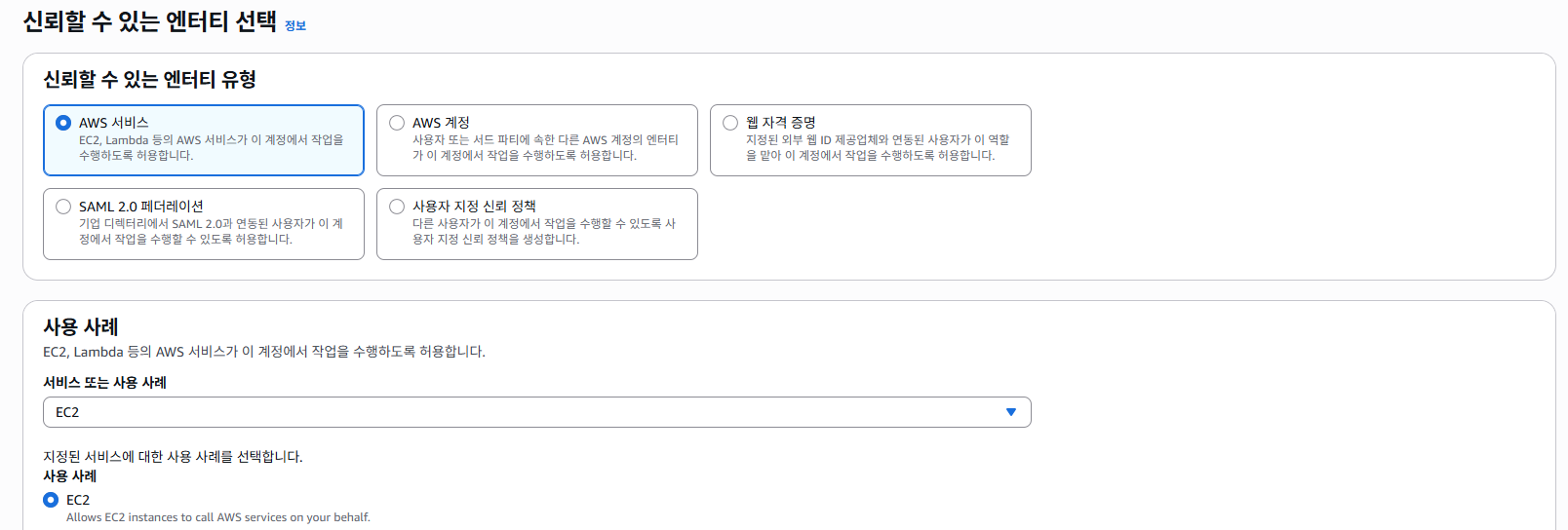
IAM > 역할 > 역할 만들기를 선택
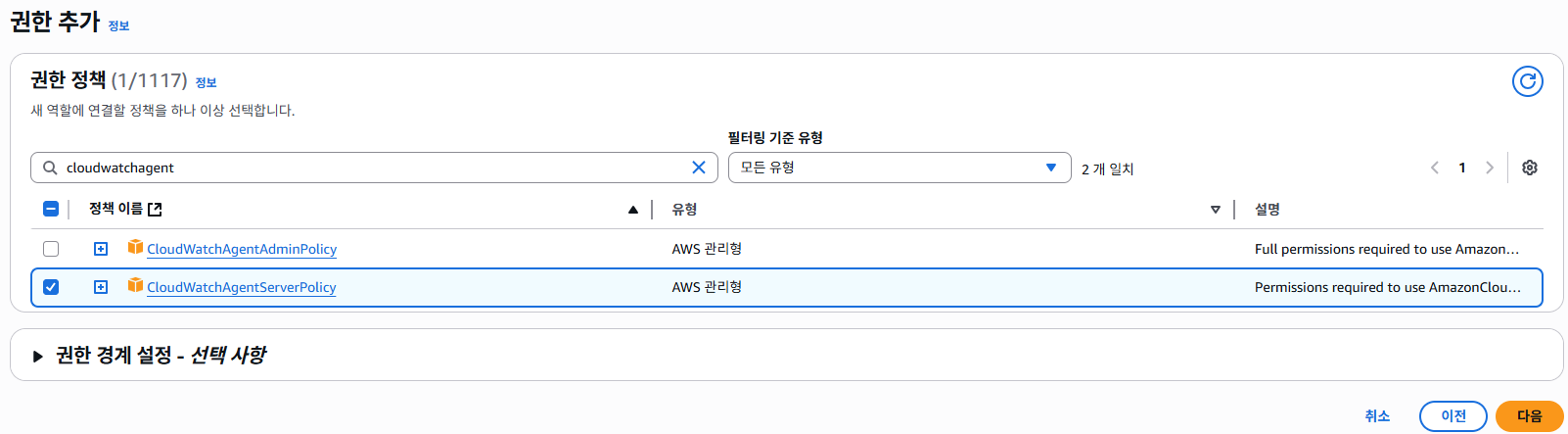
"CloudWatchAgentServerPolicy"를 검색해서 해당 정책을 추가
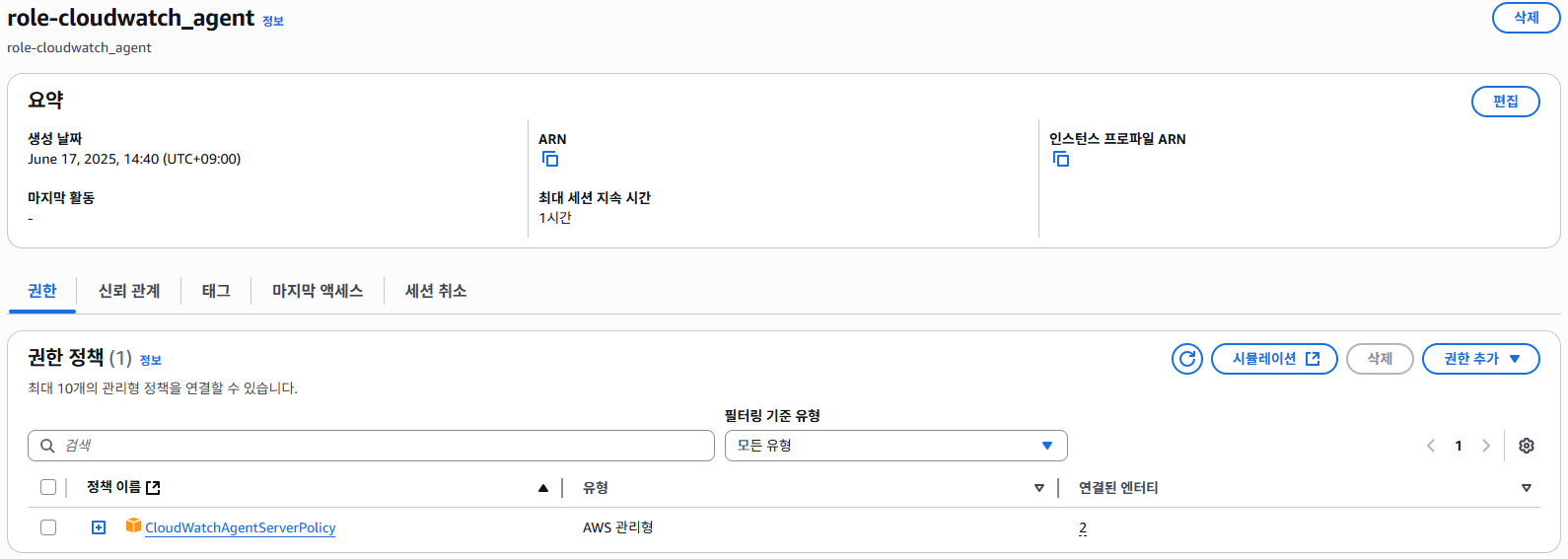
최종적으로 생성된 IAM Role과 연결된 정책 예시
EC2 인스턴스의 IAM Role 연결
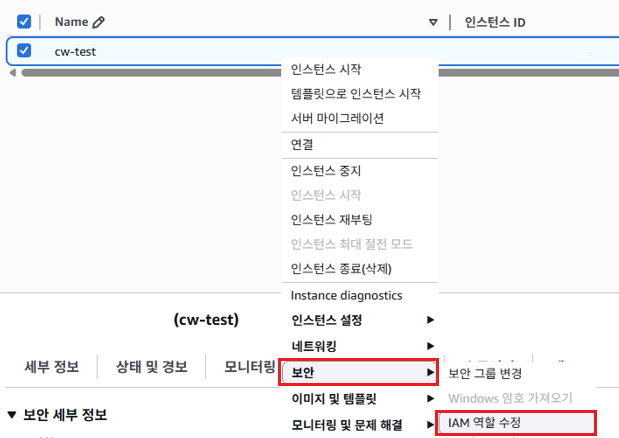
EC2 > EC2 선택 > 보안 > IAM 역할 수정을 선택

위에서 만들었던 역할을 선택하고 IAM 역할 업데이트를 선택
CloudWatch Agent 설치
# amazon-cloudwatch-agent 패키지 설치
$ yum install -y amazon-cloudwatch-agent
# 디렉토리 이동
$ cd /opt/aws/amazon-cloudwatch-agent/etc
# config 파일 생성
$ vi amazon-cloudwatch-agent.json
{
"agent": {
"metrics_collection_interval": 600
},
"metrics": {
"metrics_collected": {
"disk": {
"measurement": [
"used",
"used_percent"
],
"metrics_collection_interval": 600,
"resources": [
"/"
]
},
"mem": {
"measurement": [
"used",
"used_percent"
],
"metrics_collection_interval": 600,
"resources": [
"/"
]
}
}
}
}
# amazon-cloudwatch-agent 실행
$ systemctl start amazon-cloudwatch-agent
or
$ /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json
# process 확인
$ ps -ef | grep amazon-cloudwatch
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent -config /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml -envconfig /opt/aws/amazon-cloudwatch-agent/etc/env-config.json -otelconfig /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.yaml -pidfile /opt/aws/amazon-cloudwatch-agent/var/amazon-cloudwatch-agent.pid참고 사항
1. 각 설정 파일의 역할
- amazon-cloudwatch-agent.json
사용자가 직접 작성한 기본 입력 설정 파일 (human-friendly). AWS에서 제공하는 Wizard를 통해 생성할 수도 있다. - amazon-cloudwatch-agent.toml
CloudWatch Agent가 내부적으로 사용하는 메인 설정 파일입니다. .json 파일을 기반으로 변환되어 생성되며, 메트릭 수집 등 다양한 설정을 포함한다. Agent는 이 파일을 직접 사용하여 동작한한다. - amazon-cloudwatch-agent.yaml
CloudWatch Agent가 OpenTelemetry 구성을 지원하기 위해 사용하는 YAML 형식의 설정 파일이다. 로그 수집 또는 OpenTelemetry Collector 구성이 여기에 포함될 수 있다. - env-config.json
에이전트가 실행될 때 필요한 환경 변수 또는 실행 조건들이 정리된 JSON 파일이다. 예: region, credentials, logs 관련 등. - common-config.toml
여러 구성에서 공통으로 사용하는 설정 파일로, 주로 metrics_collection_interval, logfile, force_flush_interval 등의 공통 속성이 담긴다.
2. 왜 ps 명령어에서는 .toml, .yaml이 사용되는가?
CloudWatch Agent는 실제로 실행 시 다음과 같은 명령어와 함께 실행된다:
/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent \ -config /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml \ -envconfig /opt/aws/amazon-cloudwatch-agent/etc/env-config.json \ -otelconfig /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.yaml에이전트는 직접 .json 파일을 사용하지 않고, .json을 파싱해 변환된 내부 포맷(.toml, .yaml)을 통해 실행된다. 이건 다음과 같은 장점이 있기 때문이다:
- 성능: TOML/YAML이 파싱 및 내부 처리에 더 효율적
- 표준화된 구성 관리: 다양한 설정 소스를 통합하여 일관되게 관리 가능
- OpenTelemetry 등과 통합 가능성 고려
메트릭 설정 참고
CloudWatch 에이전트 구성 파일
CloudWatch 에이전트가 수집하는 지표
CloudWatch Agent로 Memory 및 Disk 사용량 확인
Cloudwatch > 지표 > 모든 지표 > 찾아보기 > 사용자 지정 네임스페이스 > CWAgent 선택
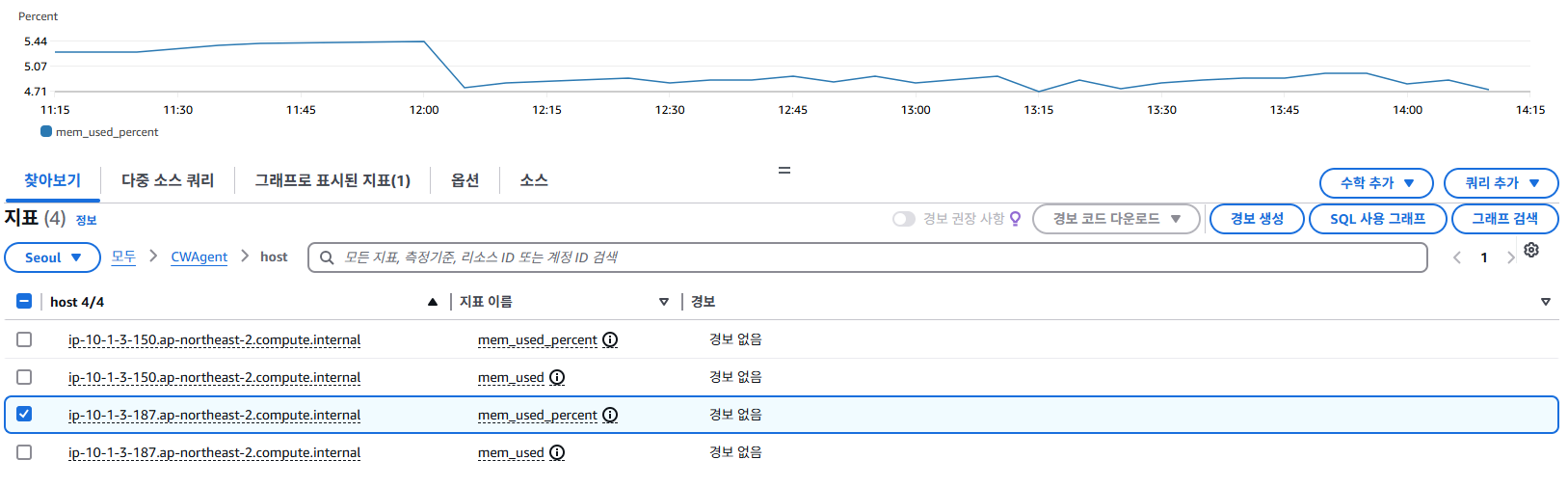
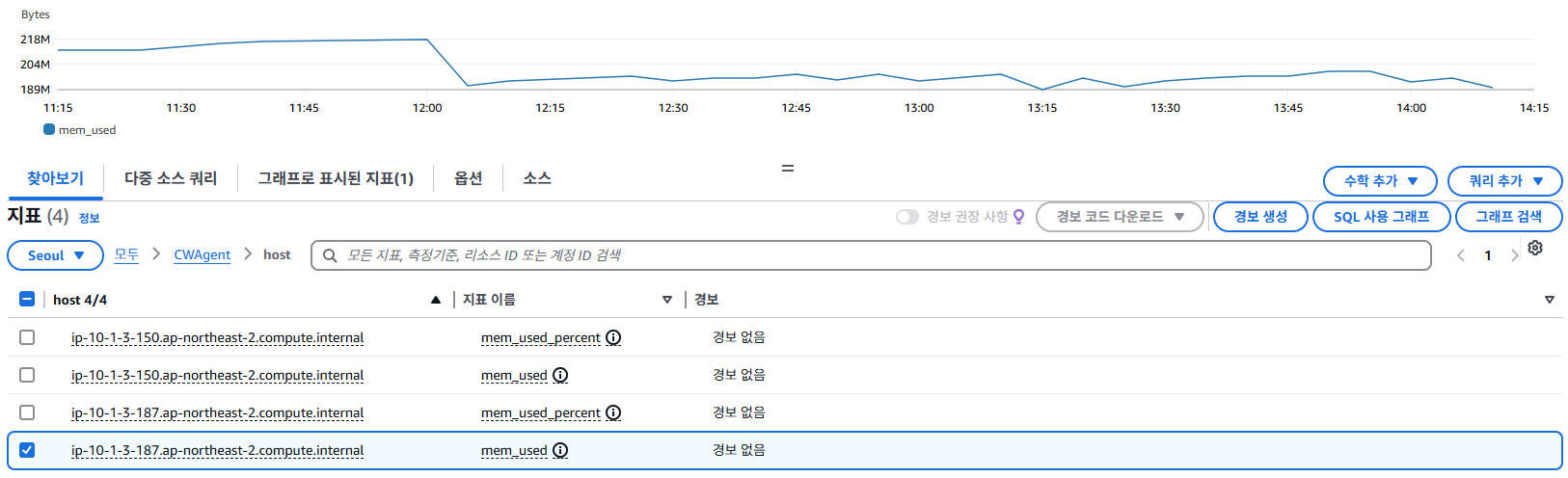
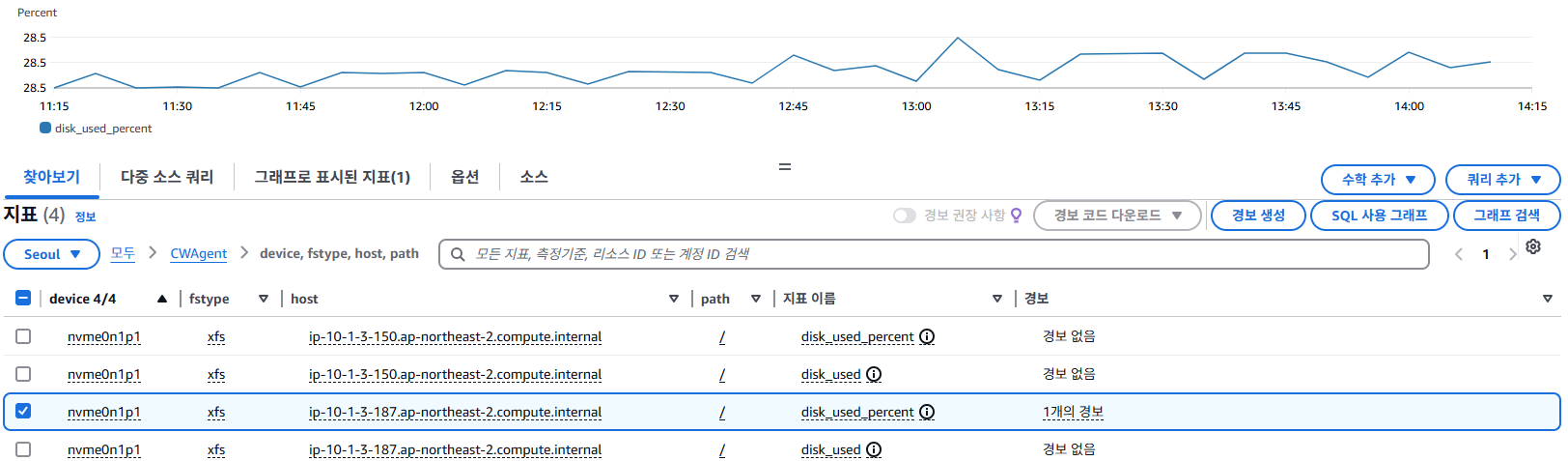
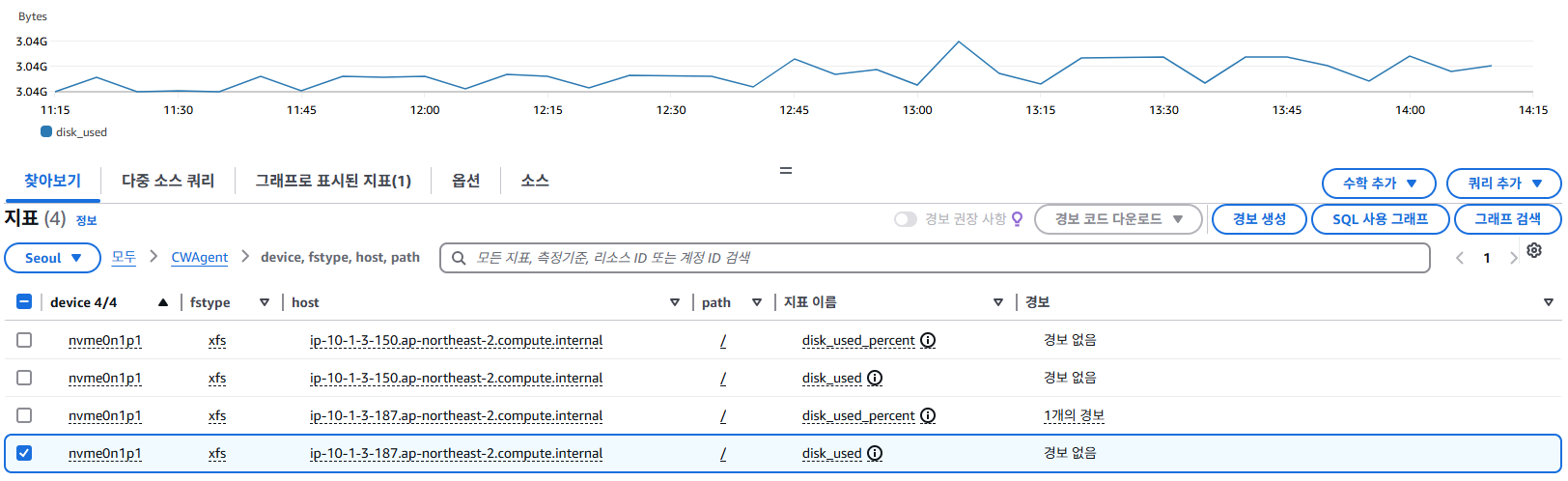
지정한 서버의 Memory, Disk의 사용량(%) 또는 크기(GB, Byte) 단위로 확인 할 수 있다.
알람 설정
SNS
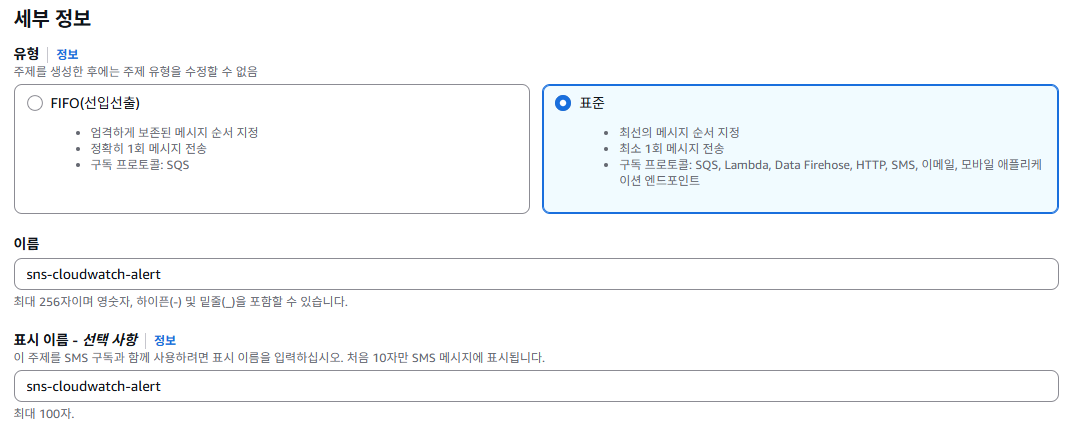
SNS > 주제 > 주제 생성을 클릭
위와 같이 유형은 표준으로 SNS 주제를 생성한한다.
Cloudwatch
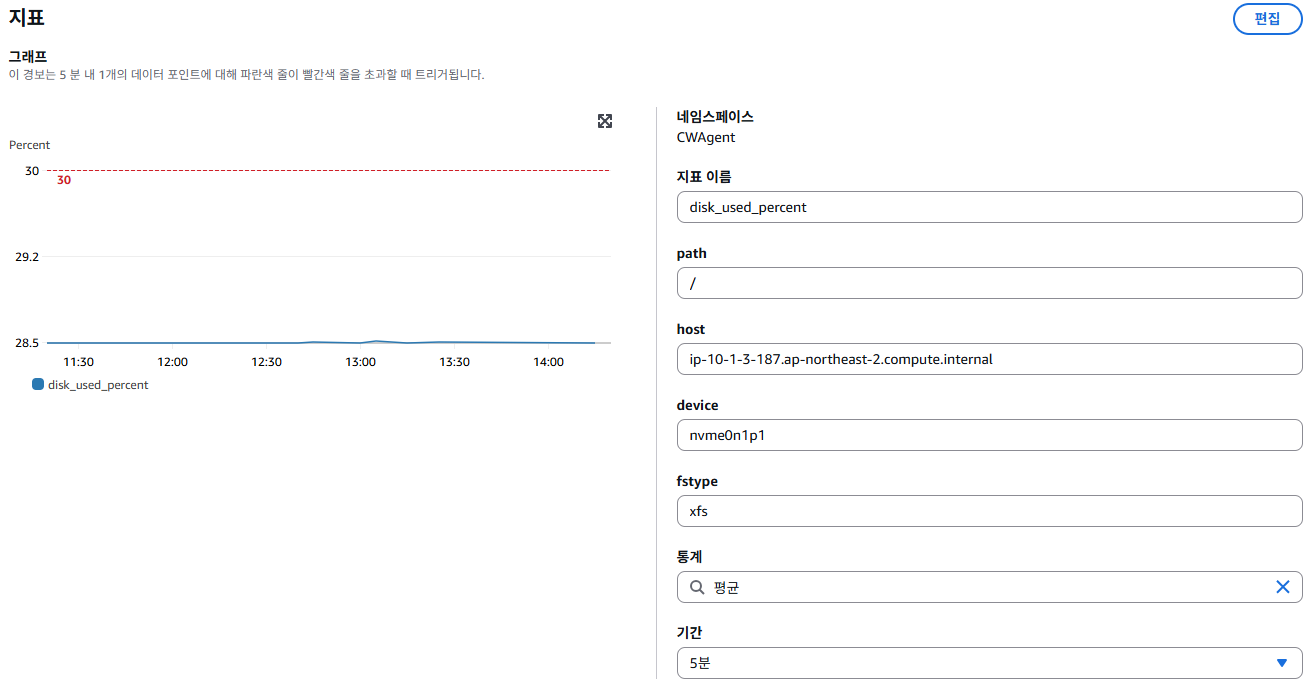
Cloudwatch > 경보 > 모든 경보 > 경보 생성을 클릭
주의
만약 여러 개 서버의 알람을 하나의 경보로 설정은 불가능히지만, 개별 알람들을 묶어서 하나의 복합 알람으로 관리할 수 있다.
예:
서버 A 디스크 알람,서버 B 디스크 알람,서버 C 디스크 알람을 만들고, 이들을 하나로 묶어 "디스크 이상 통합 알람"이라는 복합 알람 구성 가능
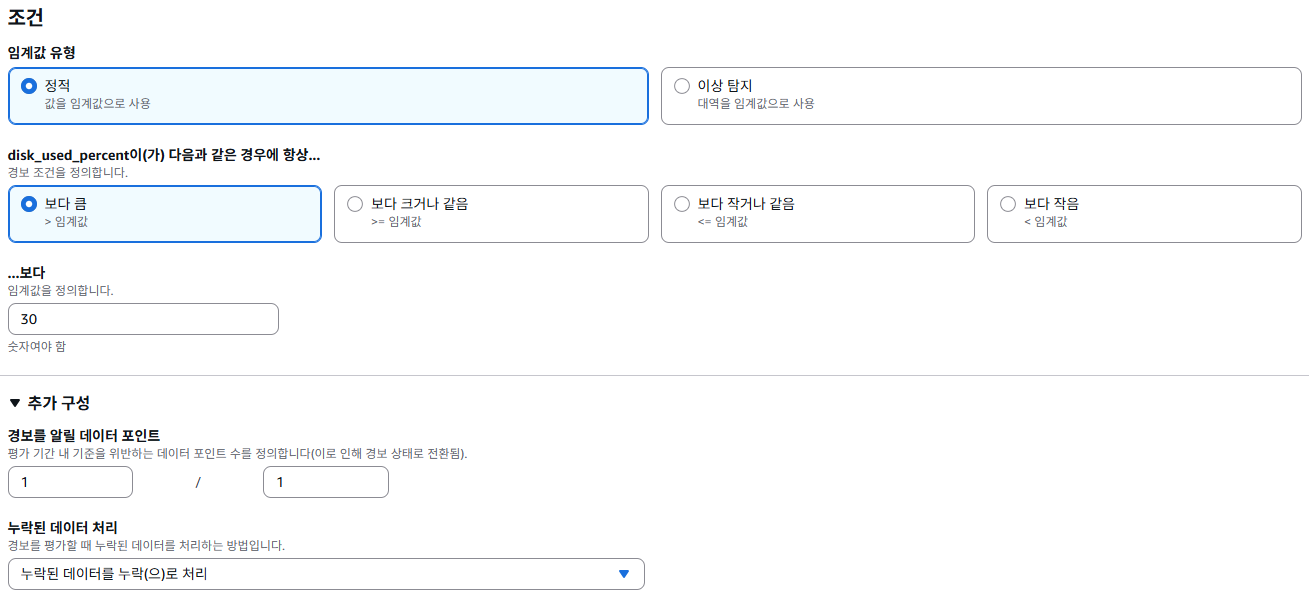
위 설정은 특정 서버(예: ip-10-1-3-187...)의 디스크 사용률이 5분 동안 평균적으로 30%를 초과하면, CloudWatch가 즉시 알람을 발생시키는 조건이다.
디스크는 루트 디렉토리(/)의 특정 장치(nvme0n1p1)와 파일 시스템(xfs)을 모니터링하고 있고, 이 지표는 CloudWatch Agent를 통해 수집중이다.
알람은 단 한 번이라도 5분 평균 디스크 사용률이 30%를 넘으면 바로 작동하게 되어 있다.
데이터 평가 기준은 5분 간격으로 수집되는 데이터 포인트 1개 중 1개 이상이 조건을 만족하면 경보가 울리게 된다.
만약, 수집 주기에 데이터가 없더라도, 해당 데이터는 판단에서 제외(무시)되도록 설정돼 있어서
누락된 데이터 때문에 오탐이나 경보 누락이 발생하지 않도록 구성이 되어 있다.
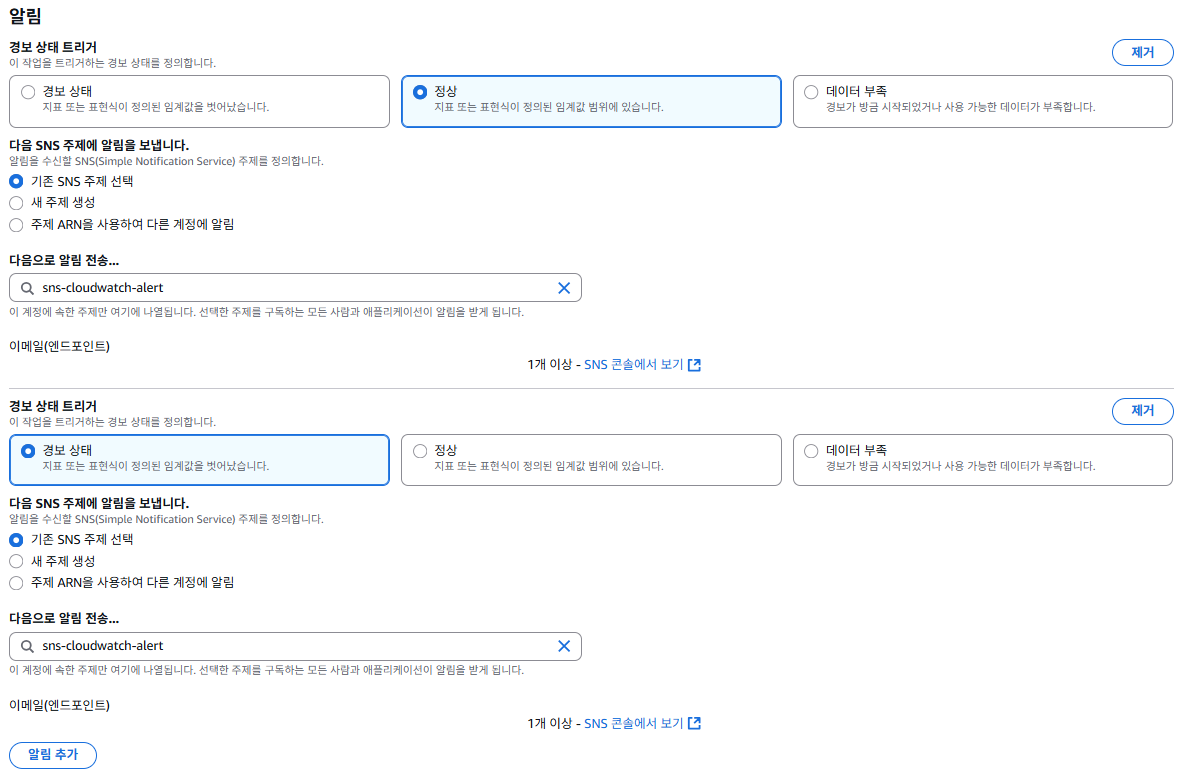
Metric에서 경보의 조건을 만족할 경우 SNS로 전달 할 수 있도록 설정을 진행한다.
경보가 정상인 것을 받기 위해서는 경보 상태 트리거를 "정상", "경보 상태" 두 가지를 추가해야 한다.
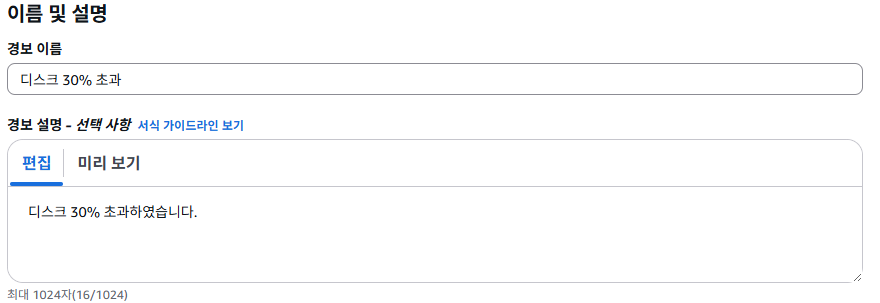
경보에 대한 이름과 주석 등 추가할 수 있으며, 간단하게 "디스크 30% 초과"라는 경보를 생성한한다. (메모리 설정도 동일)
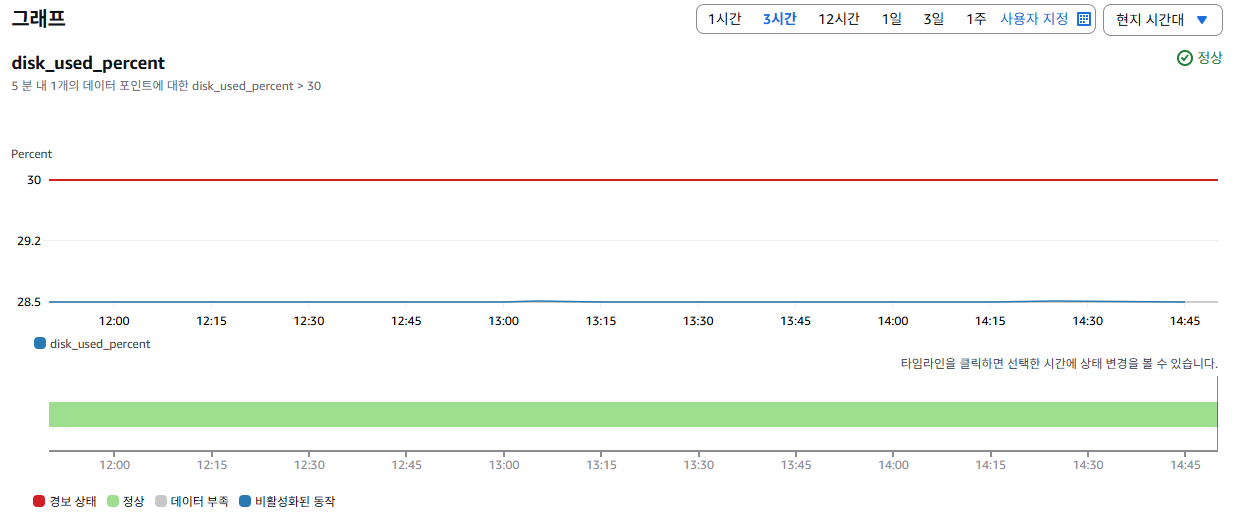
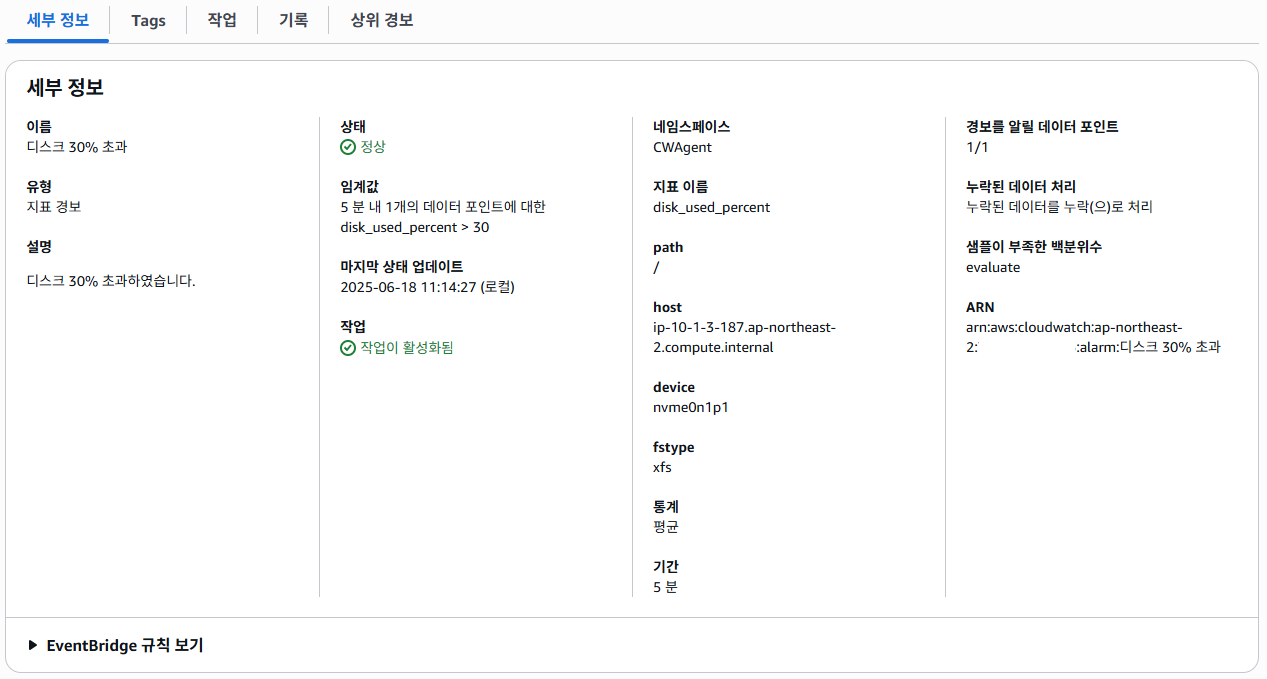
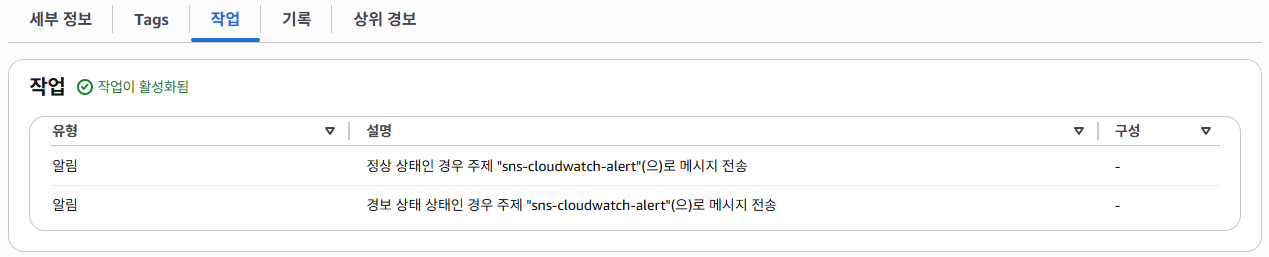
설정이 끝났다면 지정한 서버의 메트릭과 상세 정보 등 확인 할 수 있다.
작업 탭에서는 임계치에 도달 후 알람을 발생시키고, 경보가 정상으로 돌아왔을 시에도 SNS로 이벤트를 전달하도록 되어 있다.
Lambda
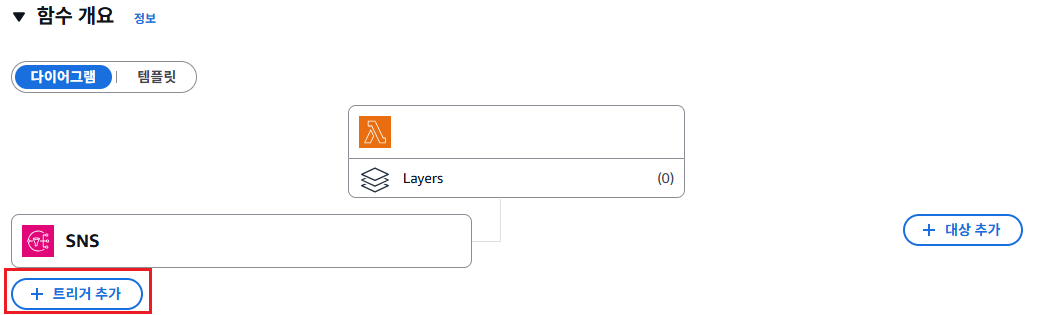
생성한 Lambda에서는 트리거를 이전 위에서 생성했던 SNS를 추가해야 이벤트를 Lambda가 받아서 처리할 수 있다.
# lambda 이벤트 처리 함수
import json
import urllib.request
import datetime
SLACK_WEBHOOK_URL = <your-slack-webhookURL> # slack webhook url
def lambda_handler(event, context):
# SNS 메시지 추출
sns_message = json.loads(event['Records'][0]['Sns']['Message'])
# 기본 값들 추출
alarm_name = sns_message['AlarmName']
description = sns_message.get('AlarmDescription', '-')
state = sns_message['NewStateValue']
state_time_utc = sns_message['StateChangeTime']
aws_account_id = sns_message['AWSAccountId']
trigger = sns_message['Trigger']
# Memory, Disk 등 trigger 정보
metric_name = trigger['MetricName']
namespace = trigger['Namespace']
threshold = trigger['Threshold']
comparison = trigger['ComparisonOperator']
dimensions = {d['name']: d['value'] for d in trigger['Dimensions']}
current_value = float(sns_message['NewStateReason'].split('[')[1].split()[0])
# 시간 포맷 변환
utc_dt = datetime.datetime.strptime(state_time_utc, "%Y-%m-%dT%H:%M:%S.%f%z")
kst_dt = utc_dt + datetime.timedelta(hours=9)
kst_time_str = kst_dt.strftime("%Y-%m-%d %H:%M:%S")
# 대상 구분
metric_display = {
**{k: "Disk" for k in ["disk_used", "disk_used_percent"]},
**{k: "Memory" for k in ["mem_used", "mem_used_percent"]},
**{k: "CPU" for k in ["CPUUtilization"]}
}
target = metric_display.get(metric_name, metric_name)
# Slack 메시지 구성
text = f"""
*AWS 계정:* {aws_account_id}
*이벤트:* {alarm_name}
*설명:* {description}
*현재 상태:* {"🚨" if state == "ALARM" else "✅"}
*발생시간:* {kst_time_str}
*해당 서버:* {dimensions.get("host", "-")}
*대상:* {target}
*지표:* {metric_name}
*기준:* {threshold} %
*현재:* {current_value:.2f} %
""".strip()
# Slack 전송
payload = {
"text": text
}
req = urllib.request.Request(
SLACK_WEBHOOK_URL,
data=json.dumps(payload).encode("utf-8"),
headers={"Content-Type": "application/json"}
)
try:
with urllib.request.urlopen(req) as response:
print("Slack 응답:", response.read().decode())
except Exception as e:
print("Slack 전송 실패:", str(e))
return {
"statusCode": 200,
"body": "OK"
}Lambda 함수에서 이벤트를 처리하여 Slack 채널로 보내는 함수이며, SNS에서 받아온 이벤트의 예시를 참고하였였다.
Slack
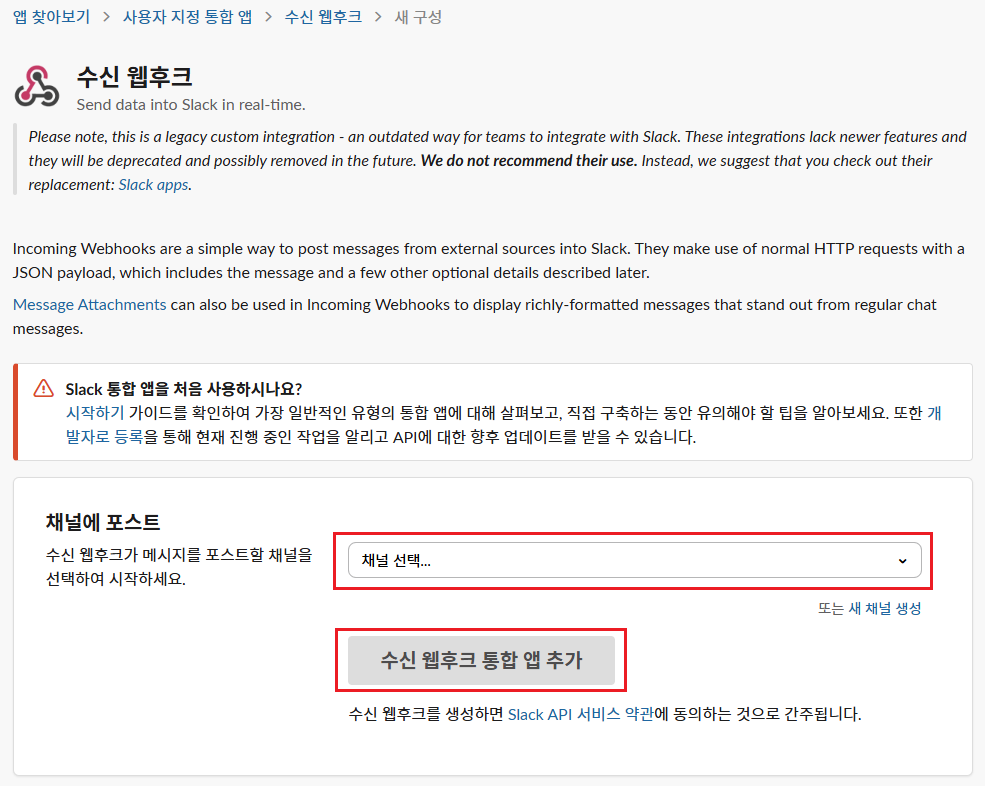
Slack에서 웹훅 앱을 추가하고 채널을 설정할 때 생성되는 URL은 Lambda 함수의 SLACK_WEBHOOK_URL 변수 값으로 설정한다.
결과
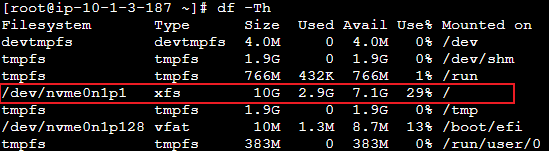
현재 모니터링 중인 서버의 디스크 볼륨 사용률은 29% 로, 임계치 이전의 정상적인 상태이다.
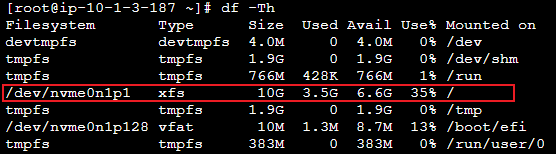
임의로 디스크 볼륨 사용률을 35% 까지 상승시켰다.
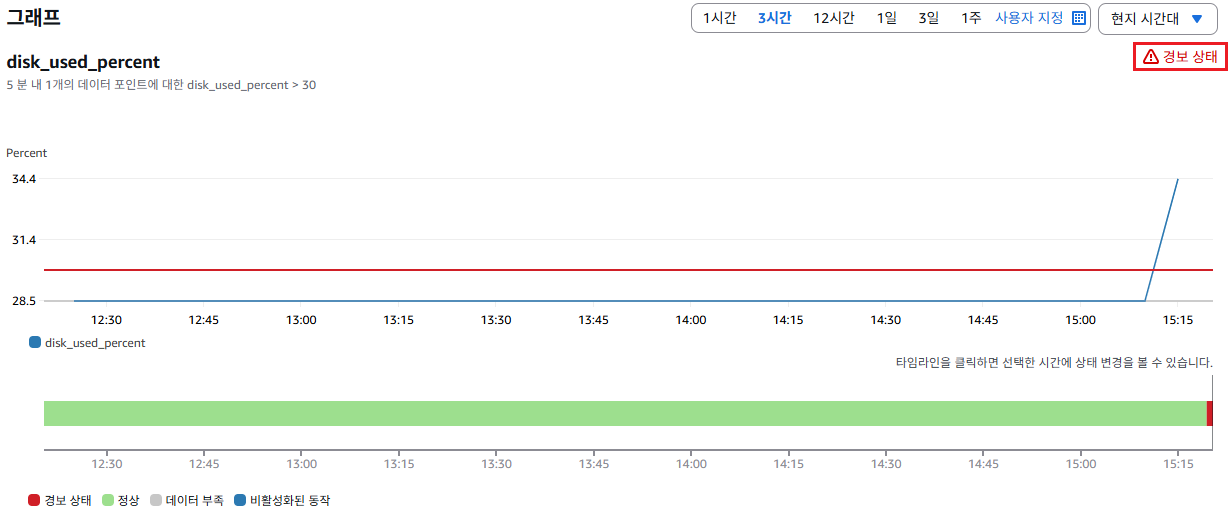
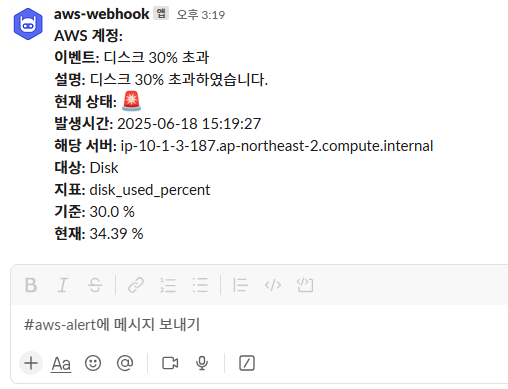
CloudWatch에서도 경보 상태로 전환되었으며, Webhook을 통해 Slack 채널에 알림이 전송된 것을 확인할 수 있다.
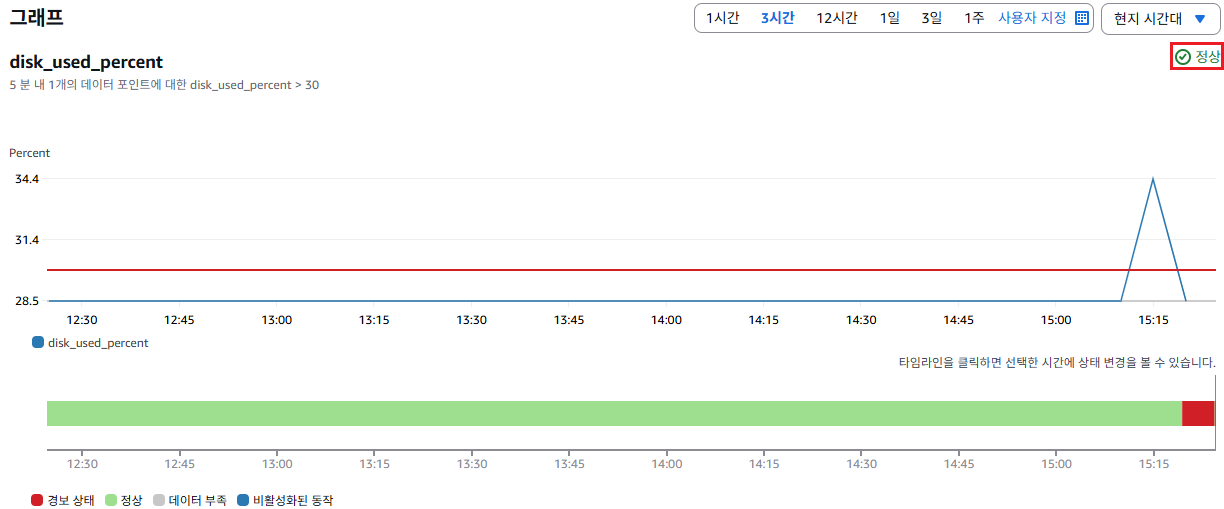
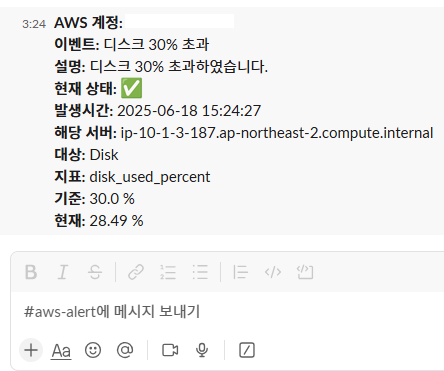
또한, 디스크의 임계치 아래로 도달 시 정상으로 돌아온 알람을 확인할 수 있다.
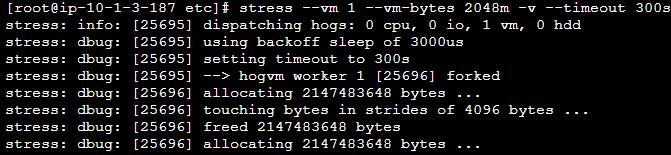
서버에서 stress 명령어를 통해 메모리 부하 테스트를 수행한다.
2GB 메모리를 사용하는 VM 부하 워커 1개를 실행하여 시스템에 메모리 스트레스를 주고, 이 상태를 5분 동안 유지하며 실행 중 상태를 자세히 출력하도록 하였다.

vmstat를 통해 현재 유휴한 메모리를 확인한 결과, 실행 전에는 약 3.7GiB였고, 실행 중에는 약 1.1GiB에서 2.7GiB 사이로 유휴 메모리 남아 있는 것을 확인할 수 있었다.
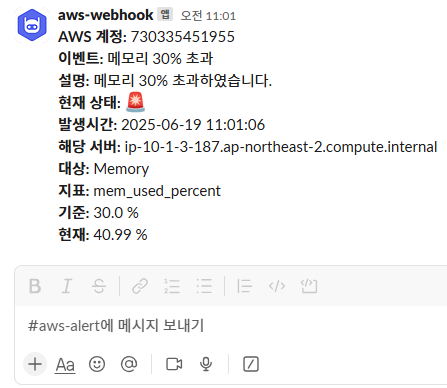
이전 설정해둔 Lambda 코드를 통해, 메모리 사용량 초과 시 Slack 채널에도 동일하게 알림이 전송되었다.
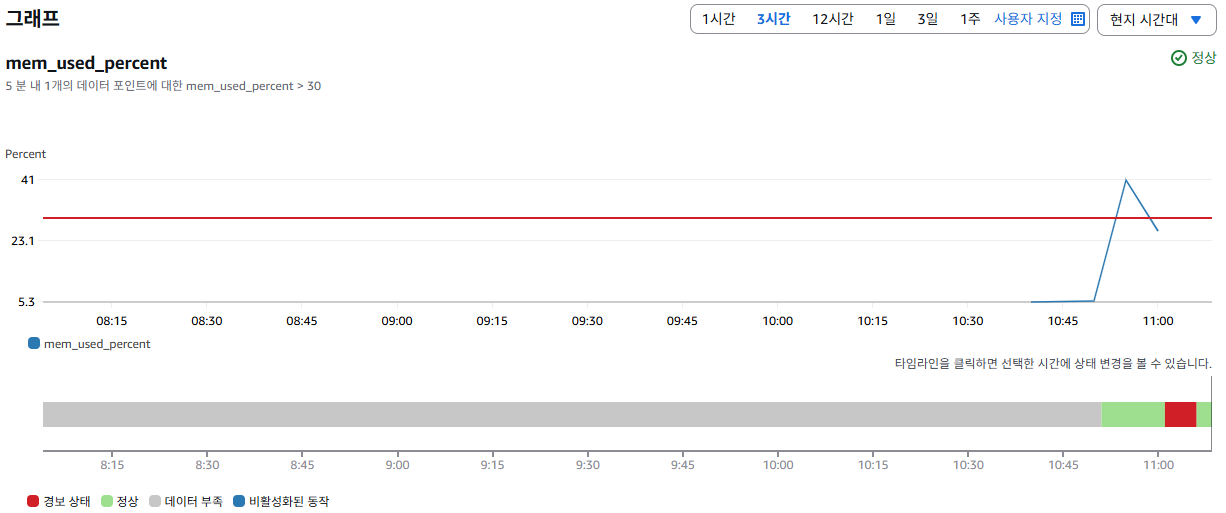
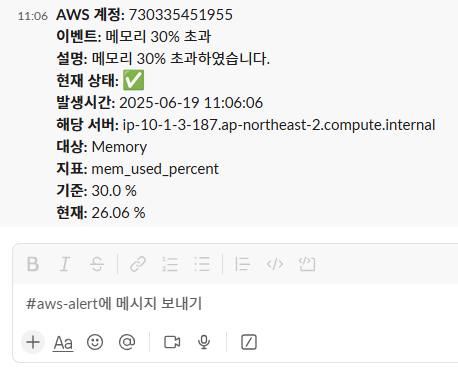
5분 후 부하 테스트가 종료되고, 정상 복구 알림도 Slack 채널을 통해 정상적으로 수신되었다.
