개요
- SRE(사이트 신뢰성 엔지니어링) Engineer 직무가 많이 보이고 있고, 이전 회사에서 고객사의 클라우드 인프라를 운영하면서 SLA 라는 단어를 들으며 정확한 내용을 잘 몰라 정리를 위해 포스팅을 하였다.
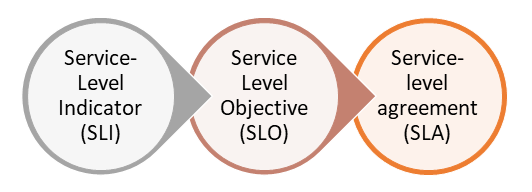
SLI (서비스 수준 척도, Service Level Indicator)
- 서비스 수준을 판단할 수 있는 몇가지를 정량적으로 측정한 값 또는 지표이다.
- SLI 는 회사가 정의하기 나름이다.
예시
- 응답속도 : 요청에 대한 응답이 리턴되기까지의 시간
- 에러율 : 전체 요청 수 대비
- 처리량(throughput) : 초당 처리할 수 있는 요청 수
- 가용성 : 서비스가 사용 가능한 상태로 존재하는 시간의 비율
- 내구성 : 데이터 저장이 중요한 목적인 서비스의 경우 특히 중요
예를 들어 하루 100만 건의 요청 중 99만9천 건이 정상 응답했다면, '요청 성공률'이라는 SLI의 현재 측정값은 99.9%가 된다.
SLO (서비스 수준 목표, Service Level Object)
- SLO = SLI + 목표값(Goal)
- SLI에 의해 측정된 서비스 수준의 목표 값, 또는 일정 범위의 값을 의미한다.
- SLO 는 우리가 달성하고자 하는 수준
예를 들어 "요청 성공률을 98% 이상으로 유지한다"는 것이 SLO입니다. 또한, 에러 버짓을 산정하고 2%의 버짓이 남아 있다면 새로운 기능을 빠르게 배포하고, 없다면 안정성에 집중합니다.
SLA (서비스 수준 협약, Service Level Agreements)
- SLO 를 달성하지 못하면 어떻게 되는지를 적어놓은 약속
- SLA 는 꼭 지켜야만 하는 수준 - SRE가 직접 관여하지는 않음
예시
- 매일 99% 이상의 요청이 200ms 이내의 응답시간으로 응답되어야 하며, 이 때 응답 Body 크기는 1MB 이하여야 합니다. 이보다 큰 Body를 응답하는 경우 응답시간을 보장할 수 없습니다.
SRE

일반적으로 위의 SLI, SLO 지표를 정의하고 측정하고 유지보수하는 것은 SRE 직무의 사람이 하는 경우가 많다.
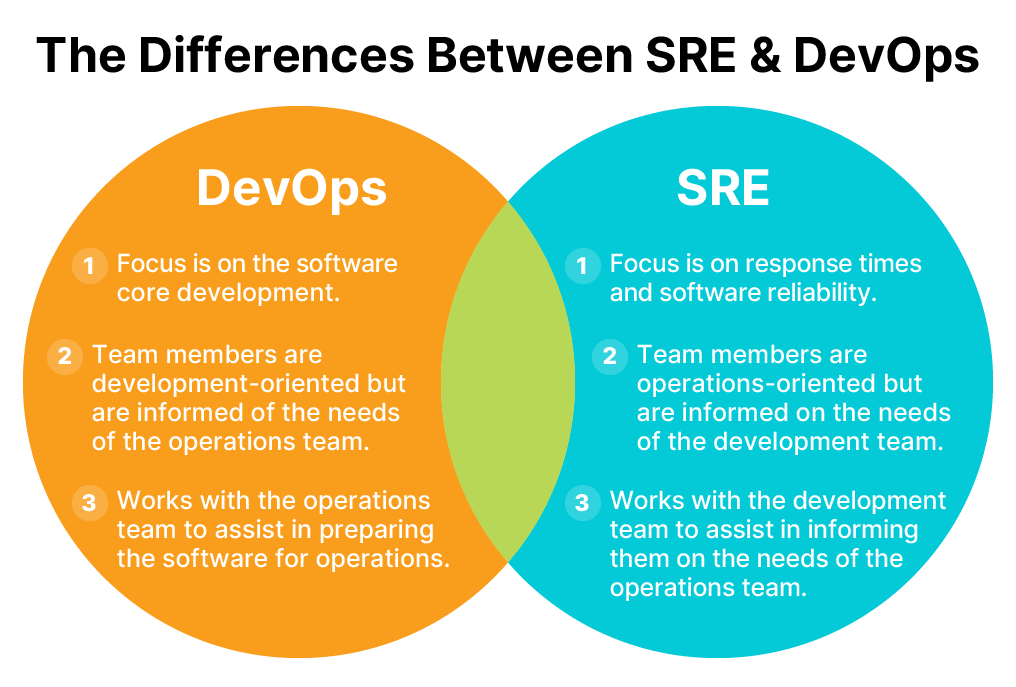
게시물을 읽다가 Devops 와 SRE에 대한 차이점을 나타내는 아래의 그림을 보았다.
아직 회사마다 Devops, SRE를 정의하는 기준이 명확하지 않고, 회사마다 차이가 있다. 그래서 SLI, SLO를 정의하는것이 SRE만의 업무라고 보기보다는 Devops에서 진행하는 한 카테고리의 업무로 봐도 될것 같다.
간단히 정리를 하고자 한다.
DevOps 는 CI/CD 구성하고 자동화에 특화되어 배포나 프로세스를 Agile 하게 적용할 수 있도록 하는 직무라고 생각한다.
SRE 는 운영적인 측면에서 모니터링, 지표와 같은 내용을 정의하고 안정적인 운영에 포커스가 맞춰진 직무라고 생각된다.
+추가 RPO, RTO

RPO(Recovery Point Objective - 복구 시점 목표)
RPO는 재해 상황에서 복구되어야 하는 데이터의 시점을 나타낸다
RPO는 데이터 손실을 어느 정도 허용할 수 있는지를 정의하며, 이전의 데이터까지만 복구 가능하다.
RPO는 주로 데이터 복구 및 백업 정책에서 사용되며, 데이터 복구 포인트를 결정한다.
RTO(Recovery Time Objective - 복구 시간 목표)
RTO는 재해 상황에서 시스템 또는 서비스를 복구하는 데 걸리는 최대 시간을 나타낸다
RTO는 시스템 또는 서비스가 다운된 시점부터 얼마나 빨리 다시 가동되어야 하는지를 정의한다.
RTO는 주로 비즈니스 연속성 계획에서 사용되며, 다운타임을 최소화하여 업무 연속성을 보장한다.
RPO와 RTO의 차이점
목적
RPO는 데이터 손실의 허용 가능한 한계를 정의한다
RTO는 시스템 또는 서비스의 복구 시간 한계를 정의한다.
시간 관점
RPO는 데이터 백업 시점과 장애 발생 시점 사이의 시간 간격을 나타낸다.
RTO는 장애 발생 후 시스템을 복구하고 가동할 때까지 소요되는 시간을 나타낸다.
