
Python답게 짜는 법
파이썬 특유의 문법이나 스타일로 코딩을 하는 경우가 있는데 다양한 레퍼런스 코드들을 보다보니 이해안되는 부분도 있고 해서 정리해봤다. 그리고, 실제로 for loop으로 append 하는 것보다 list가 조금 더 빠르다. 효율적인 면도 있고 아무래도 다른 파이썬 개발자와 소통이 되어야하니...정리했다.
split & join
split
string type 값을 기준값으로 나눠서 list 형태로 변환하는 함수다.
>> text="hello world".split() # default : 빈칸 기준
>> print(text)
['hello','world']
>> text="hello,world".split(",") # 쉽표 , 기준
>> print(text)
['hello','world']
>> A,B="hello,world".split(",") # split 하면서 바로 unpacking도 가능함.
>> print(A)
hellosplit함수의 인자로 구분자를 정해준 후, list로 변환한다. 이때, 반환값을 unpacking 하는 것도 가능하다.
join
>> colors=['red','blue']
>> result=''.join(colors) # string으로 구성된 list 인자로 받아 하나의 string으로 변환
>> print(result)
redblue
>> colors=['red','blue']
>> result='-'.join(colors) # join앞의 문자열로 연결을 어떤 문자로 할 것인지 선택 가능
>> print(result)
red-blue
split함수와 다르게 join함수는 string으로 구성된 list를 특정 문자를 사용하여 연결하는 역할을 한다.
List Comprehension
기존의 list를 사용해서 다른 list를 보다 간단하게 만드는 기법이다. 포괄적인 list라는 의미로 파이썬에서 가장 많이 사용되는 기법 중 하나이다. for+append기법보다 빠르다
>> result=[]
>> for i in range(5):
>> result.append(i)
>> print(result)
[0,1,2,3,4]
>> result=[i for i in range(5)] # for loop을 돌며 append하는 것과 동일한 결과를 가짐.
>> print(result)
[0,1,2,3,4]
>> result=[i for i in range(5) if i%2==0] # if문을 사용해서 반복문 수행중 저장할 값 필터링 가능.
>> print(result)
[0,2,4]
위 처럼 한개의 for문을 가지고 append 대신 바로 list에 입력하는 방법으로 코드를 간소화할 수 있다. 또한, 2중 반복문도 아래와 같이 구현이 가능하다.
>> word_1="hello"
>> word_2="world"
>> result=[]
>> for i in word_1:
>> for j in word_2:
>> result.append(i+j)
>> print(result)
['hw','ho','hr','hl','hd','ew','eo','er','el','ed',
'lw','lo','lr','ll','ld','lw','lo','lr','ll','ld',
'ow','oo','or','ol','od']
# Nested for loop
>> result=[i+j for i in word_1 for j in word_2]
>> print(result)
['hw','ho','hr','hl','hd','ew','eo','er','el','ed',
'lw','lo','lr','ll','ld','lw','lo','lr','ll','ld',
'ow','oo','or','ol','od']
nested for loop라고 해서 위처럼 2중 for문도 list comprehension 가능하다. 조건문을 추가해서 아래와 같이 구현 가능하다.
>> case_1=['A','B']
>> case_2=['B','D']
>> result=[i+j if not(i==j) else i for i in case_1 for j in case_2]
>> print(result)
['AB','AD','B','BD']else문까지 포함한 3항연산자로 구현할 때는 "리스트에 저장할 값/if문/else문/반복문" 순으로 작성한다.
two dimensional array도 구현이 가능하다.
>> words ="The quick brown fox jumps over the lazy dog".split()
>> print(words)
["The","quick","brown","fox","jumps","over","the","lazy","dog"]
>> result=[[w.upper(),w.lower(),len(w)]for w in words]
>> for i in result:
>> print(i)
[["THE","the",3],
["QUICK","quick",5],
...
["DOG","dog",3]]위와 같이 words라는 리스트의 각 element의 대문자, 소문자,글자의 길이 순서대로 이루어진 2차원 행렬을 구현 가능하다.
2차원과 1차원에서의 차이가 어느정도 존재한다 아래의 코드르 보자
>> case_1=['A','B']
>> case_2=['B','D']
>> result=[i+j for i in case_1 for j in case_2]
>> print(result)
['AB','AD','BB','BD']
>> result=[[i+j for i in case_1]for j in case_2]
>> print(result)
[['AB','BB'],['AD','BD']]2차원 행렬로 저장하는 과정에서 i가 먼저 순회하고 j가 순회하는 것을 확인할 수 있다.
>> for i in case_1:
>> for j in case_2:
>> for j in case_2:
>> for i in case_1:
이 코드가 실행되는 것과 같다. 위의 예시는 j가 먼저 밑의 예시는 i가 먼저 순회한다.
enumerate & zip
enumerate
>> for i,v in enumerate(['hello','world']):
>> print(i,v)
0 hello
1 world
>> text="The quick brown fox jumps over the lazy dog"
>> set_text=list(set(text.split())) # set로 text를 묶어 중복되는 값 삭제 후 list로 형변환
>> word_idx={v.lower():i for i,v in enumerate(set_text)} # enumerate로 각 단어의 인덱스 딕셔너리 생성
>> print(word_idx)
{"the":0 , "quick":1 , "brown":2 , ,,,"dog":7}list의 element에 index를 붙여서 추출할때 사용한다. 문장내에서 각 단어에 index를 부여하는 등 응용이 가능하다.
zip
>> math=[100,30,40]
>> english=[80,20,50]
>> for a,b in zip(math,english): # zip을 통해 묶은 값은 tuple형 , 묶음과 동시에 unpacking 가능
>> print(a,b)
100 80
30 20
40 50
>> print([sum(x) for x in zip(math,english)])
[180,50,90]두개의 list의 값을 병렬적으로 추출한다. 각 리스트의 같은 index끼리 묶어서 묶은 값을 tuple형으로 반환해서 sum과 같은 함수랑 응용하여 사용도 가능하다. zip과 enumerate를 묶어서 사용도 가능하다
>> a=['a1','a2']
>> b=['b1','b2']
>> for i,(a,b) in enumerate(zip(a,b)):
>> print(i,a,b)
0 a1 b1
1 a2 b2lambda & map & reduce
lambda
python3 부터 권장하지 않는다고는 하지만 자주 보이는 함수이다. 이름이 없는 함수라고 생각하면 된다. 예시가 더 이해하기 편할 것이다
>> f=lambda x:x+1
>> print(f(2))
3
>> print((lambda x : x+1)(2))
3위처럼 따로 def 를 사용하지 않고, "lambda 파라미터 : 반환되는 값" 순으로 선언한다. 함수의 이름을 따로 정해도 되고 정하지 않아도 사용이 가능하다. map함수와 연결해서 사용이 가능하다.
map
map함수는 첫번째 인자 값을 후의 인자들에 적용한다고 생각하면 편하다. python 3에서는 map함수의 결과물이 iteration을 생성하기 때문에 list를 붙여줘야 list로 사용가능하다.
아래의 예시를 살펴보면,lambda로 생성한 함수에 x,y를 입력하고, map을 통해서 적용한 것을 알 수 있다. 두개 이상의 int형을 입력받을 때도 map함수를 사용하곤 한다.
>> ex[1,2,3]
>> f=lambda x,y : x+y
>> print(list(map(f,ex,ex)))
[2,4,6]
>> a,b=map(int,input().split())
5 10 으로 입력하면 a=5 b=10 할당됨.reduce
map function과 다르게 list에 똑같은 함수를 적용해서 통합한다.
>>from functools import reduce
>>print(reduce(lambda x, y: x+y, [1,2,3,4,5]))
15위의 계산 과정은 (((1+2)+3)+4)+5 을 1+2부터 차례대로 수행한다.
lambda, map, reduce 모두 간단한 코드로 다양한 기능을 제공하지만 직관성이 떨어진다고 하여, lambda나 reduce는 python 3에서 사용을 권장하지 않는다. 물론, 아직 많이 사용된다
generator (iterable Object)
iterable object
sequence형 자료형에서 데이터를 순서대로 추출하는 object이다.
>> cities=["seoul","busan"]
>> iter_obj=iter(cities)
>> print(next(iter_obj))
seoul
>> print(next(iter_obj))
busan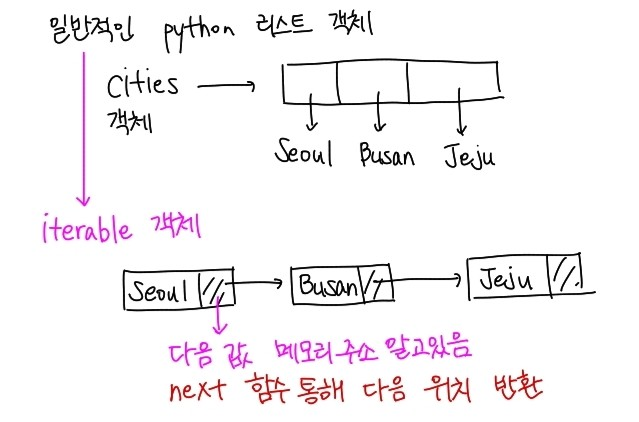
iter()와 next()함수로 iterable 객체를 iterator object로 사용한다 위의 그림과 같은 차이가 있다. 사실 list로 선언했을때 각 id가 어떤 주소를 가리키는 거였다면 iterable객체로 변환한다면, 각 값들이 다음 메모리 주소를 가리키고 있는 형태로 변환되는 것이다.
generator
iterable object를 특수한 형태로 사용해주는 함수다. element가 사용되는 시점에 값을 메모리에 반환하기 때문에 기존의 list와 같은 변수보다 메모리 효율이 훨씬 좋다. yield를 통해 값을 전달할때만 메모리가 사용된다.
def generator_list(value):
result=[]
for i in range(value):
yield i
def general_list(value):
result=[]
for i in range(value):
result.append(i)
return ilist comprehension과 유사한 형태로 generator형태의 list를 생성할 수도 있다.
gen_ex=(n*n for n in range(500))
list_ex=[n*n for n in range(500)]list 타입의 데이터를 반환해주는 함수를 generator로 만들어서 큰 데이터를 처리할때 효율적으로 관리할 수 있다.
arguments
keyword argument
함수에 입력되는 parameter의 변수명을 사용해서 arguement를 넘겨주는 방식이다.
>> def my_print(a,b):
>> print(a,b)
>> my_print("hello","world")
hello world
>> my_print(b="hello",a="world")
world hello차례대로 변수를 지정할 수 있지만, 변수명을 언급해줘서 선택해서 변수를 전달해줄 수 있다.
Default argument
>> def my_print(a,b="hello")
>> print(a,b)
>> my_print("hello","world")
hello world
>> my_print("hello")
hello hello함수의 선언시 parameter에 기본 값을 적용하여 입력하지 않을경우 기본값을 출력하게 할 수 있다. 하지만, 함수의 parameter가 정해지지 않을 수 있다. 이때 variable length asterisk를 사용한다.
variable-length
개수가 정해지지 않은 변수를 함수의 prameter로 사용하는 방법이다. keyword arguments와 argument 추가가 가능하다. Asterisk(*) 기호를 사용한다. 입력된 값은 tuple type으로 사용된다. 오직 한개, 맨 마지막 위치에 사용가능하다.
>> def asterisk_test(a,b,*args):
>> return a+b+sum(args)
>> print(asterisk_test(1,2,3,4,5))
15위의 함수에서 3,4,5 값이 *args에 입력되고, tuple 형태로 전달된다.
keyword variable-length
parameter 이름을 따로 저장하지 않고 입력하는 방법이다. Asterisk(*)를 두개 사용한다. 입력된 값은 dictionary type으로 사용된다.
함수의 인자엔 keyword가 없는 것부터 순서대로 인자로 입력할 수 있다.
>> def test(one,two,*args,**kwargs):
>> print(one+two+sum(args))
>> print(kwargs)
>> test(3,4,5,6,7,8,9,first=3,second=4,third=5)
42
{'first': 3, 'second': 4, 'third': 5}
만약에 변수를 전달할 때, one=3,two=4,5,6,7,8,9,first=3,second=4,third=5 로 전달해주면 오류가 발생한다.
Asterisk
곱하기와 제곱외에도 unpacking하는 역할도 수행한다.
>> def asterisk_test(a,*args):
>> print(a,args)
>> print(type(args))
>> astersik_test(1,*(2,3,4,5,6))
1 (2, 3, 4, 5, 6)
<class 'tuple'>
>> astersik_test(1,(2,3,4,5,6))
1 ((2, 3, 4, 5, 6),)
<class 'tuple'>(2,3,4,5,6)의 tuple을 Asterisk(*)을 사용해서 unpacking한 후 전달해주고, args 자체를 출력했을때, tuple형으로 출력되는 것을 알 수 있다. 두번째 예시처럼 unpacking을 수행하지 않으면, tuple형태로 즉 한개로 처리하고 전달되는 것이고, 따라서 args를 출력했을 때, ((2, 3, 4, 5, 6),) 로 출력되는 것을 알 수 있다.
