
Text preprocessing
Natural Language Processing (NLP)
Natural Language Processing (NLP)는 컴퓨터가 인간의 언어를 이해하고 처리할 수 있도록 하는 기술을 연구하는 학문이다. AI의 한 분야로 텍스트 및 음성 데이터에서 의미를 추출하고, 분석,이해,생성하는 다양한 방향으로 개발한다. NLP의 최종적인 목표는 컴퓨터가 인간의 언어를 이해하고 사용할 수 있도록 하는 것이다.
Text preprocessing
다양한 방향으로 개발하기에 앞서, 주어진 텍스트를 용도에 맞게 처리하는 작업을 Text preprocessing이라 한다. 텍스트 정규화, 토큰화, 불용어 제거, 어근 추출 및 형태소 분석 등이 포함된다.
Tokenization
텍스트를 단어,문장,문자 등의 작은 단위로 나누는 과정이다. 텍스트를 구조적으로 분석할 때 필수적인 단계이다.
토큰화 과정에서 고려해야하는 사항
언어적 특성: 각 언어마다 토큰화 과정에서 다르게 처리해야 할 특성이 있다. 영어는 공백을 기준으로 단어를 분리할 수 있지만, 한국어는 조사나 어미와 같은 언어적 특성 때문에 더 정교한 처리가 필요하다.
구두점 처리: 문장 부호나 특수 문자를 어떻게 처리할지 결정해야 한다. 이를 별도의 토큰으로 취급할지, 아니면 무시할지 등에 대한 정책이 필요하다.
어근 추출(Lemmatization) 및 형태소 분석(Morphological Analysis): 토큰화 이후에는 단어의 기본형을 추출하거나 단어의 형태를 분석하여 더 정교한 처리가 가능하다.
한글 tokenization
한글 자연어처리의 어려운 점.
1) 교착어의 특성
한글을 토큰화 하는 과정에선, 한글의 주요한 특성인 교착어에 대해 알고 넘어가야 한다. 교착어란 실질적인 의미를 가진 단어, 어간에 문법적인 기능을 가진 요소가 차례로 결합함으로써 문장 속에서 문법적인 역할이나 관계의 차이를 나타내는 언어이다.
한글은 영어와 다르게 띄어쓰기만으로 토큰화 하기 부족하다. 띄어쓰기 단위로 진행한 어절 토큰화가 단어 토큰화와 같지 않다. 한글에선 어절이 독립적인 단어로 구성된 것이 아니라 조사 등 무언가에 붙어있는 경우가 많기 때문에 이를 분리해줘야한다. 따라서, 한글을 토큰화할 때 형태소 단위(의미를 가지는 가장 작은 말의 단위)로 토큰화를 수행한다.
형태소 종류
- 자립 형태소 : 접사,어미,조사와 상관없이 자립해서 사용되는 형태소 체언(명사,대명사,수사),수식언(관형사,부사),감탄사 등
- 의존 형태소 : 다른 형태소와 결합하여 사용되는 형태소 접사,어미,조사,동사 형용사의 어간 등
2) 모아쓰기 방식(한글), 풀어쓰기 방식(영어)
한국어는 영어에 비해 띄어쓰기가 잘 지켜지지 않는 편이기 때문에 형태소 단위 분석이 필요하다. 띄어쓰기가 지켜지지 않아도 이해하기 쉬운 언어이기 때문에 그렇다. 뉴스 기사와 같이 띄어쓰기를 지킨 글이 코퍼스로 사용되면 좋지만, 많은 코퍼스가 띄어쓰기 부분에서 틀린 부분이 있다. 따라서, 한글에서 띄어쓰기가 무시되는 경우가 많아 자연어 처리가 어려운 경향이 있다.
형태소(morpheme) 단위 토큰화
위의 여러 어려운 점을 최대한 해소하기 위해서 문장에서 의미를 가진 단위로 토큰화한다. 아래는 영어식 토큰화인 어절 토큰화와 한글에서의 형태소 단위 토큰화를 비교한 예시이다.
철수가 책을 읽었다
→(어절 토큰화) ['철수가' , '책을' , '읽었다']
→(형태소 토큰화) ['철수' , '-가' , '책', '-을' , '읽' , '-었' , '-다']
형태소 단위로 토큰화를 진행하면, '철수', '책'과 같이 명사를 얻어낼 수 있다. 어절 토큰화가 아닌 형태소 토큰화를 수행해야한다는 것을 알 수 있다.
POS(Part Of Speech) tagging
표기는 같지만, 단어가 문장에서 어떤 품사로 쓰이냐에 따라 다른 의미로 해석될 수 있다.
1) 그는 못 뛴다.
2) 그는 못을 벽에 박았다.
위의 두 문장에서 같은 '못'이라는 표기의 단어를 사용했지만, 부사일 경우 동사에 부정의 의미를 가지고, 명사일 경우 망치를 사용해 무언갈 고정할 때 사용하는 물건의 의미를 가진다.
결국, 단어의 의미를 제대로 파악하려면, 문장내에서 어떤 품사로 사용됐는지도 토큰화 과정에서 중요하다.
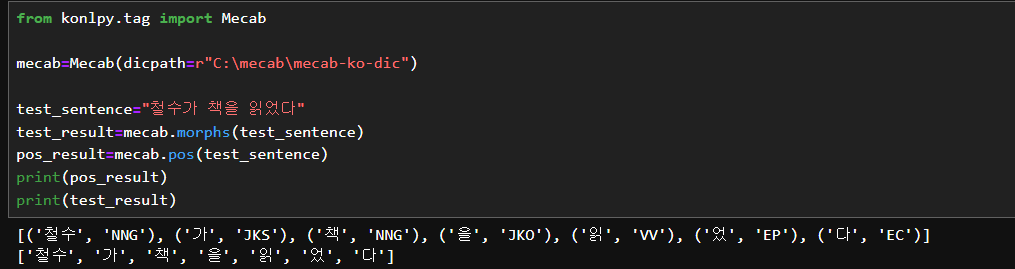
Mecab tokenizer로 문장을 형태소 단위로 token화 해봤다. Okt,Kkma
https://happygrammer.github.io/nlp/postag-set/
위의 링크에서 pos tag 표를 확인할 수 있다.
철수 - NNG(일반명사)
가 - JKS(주격조사)
책 - NNG(일반명사)
을 - JKO(목적격조사)
읽 - VV(동사)
었 - EP(선어말 어미)
다 - EC(연결 어미)
다음 글에선, 희귀 단어, 신조어와 같은 문제를 완화시킬 수 있는, subword segmentation 작업에 대해 다뤄보려 한다.
Reference
