프론트엔드 개발자로 일하면서 `SQL`이 필요할까? 고민하던 때가 있었어요.
실제 개발을 하며 DB를 보고 원하는 걸 뽑아서 확인하고 싶을 때,
이미 작성된 SQL문을 보고 이해하고 수정하고 싶을 때,
SQL을 모르니 이게 뭐지.....하는 생각을 하곤 했어요.
매우 간단한 SQL은 직감으로 이거겠지? 하고 예측하지만
쿼리문이 복잡해지고 길어지면 점점 시야가 흐려지는 경험을 다들 해보셨을거라고 생각해요.

복잡한 쿼리는 무슨뜻인지 검색하기도 애매하구요.
저와 같은 주니어 FE개발자 분들이 분명 있을거라고 생각하고
블로그를 작성하자 결정했습니다.
이 블로그를 보고 이제부터 SQL을 두려워하지 않는,
피하지 않는 FE개발자 되어봅시다.
데이터베이스(Database)
정의: 여러 사람이 공유해서 사용할 목적으로 쳬계화해 통합, 관리하는 데이터의 집합
종류: 계층형, 네트워크형, 관계형, NoSQL 등...
현업에서 많이 사용되고 우리가 공부할 데이터베이스는 관계형 데이터베이스 입니다.
관계형 데이터베이스(Relational Database)
데이터를 아래와 같은 형태의 테이블로 관리해요.
아래 학번, 이름, 학년, 생일을 열(Column)이라고 하고
20230001(학번) 홍길동(이름) 1(학년) 920101(생일)을 열(Row)이라고 해요.
학번 이름 학년 생일 20230001 홍길동 1 920101 20220002 이순신 2 910101 20210003 임꺽정 3 900101 20200004 장보고 4 890101
데이터베이스 관리시스템(Database Management System)
DB는 정보이므로 정보를 다루기 위한 시스템이 필요한데
이것이 DBMS(데이터베이스 관리시스템)이에요.
우리가 관계형 데이터베이스를 다뤄야 한다면 RDBMS(관계형 데이터베이스 관리시스템)를 이용해 RDB의 정보를 다룰 수 있어요.
어떤 RDBMS가 많이 사용되는지는 링크를 통해 확인 할 수 있어요.
관계형 데이터베이스는 보통 많은 테이블로 구성되는데요.
이미지에서 보이는 PrimaryKey(기본 키), ForeignKey(외래 키)를 이용해서 테이블을 조합할 수 있어요.
PrimaryKey: 가장 중요한 키로써 하나의 테이블에서 중복되지 않는 값을 가지며, NULL값을 가질 수 없어요.
ForeignKey: 테이블에 컬럼으로 존재하며 다른 테이블의 PrimaryKey이에요.
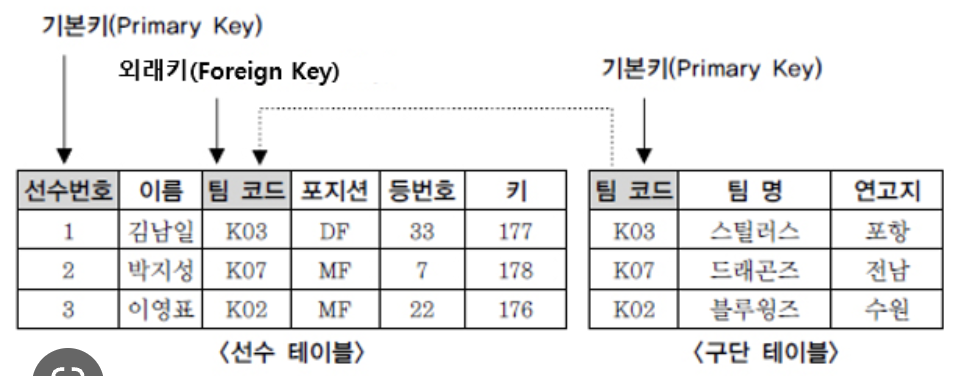
이미지 출처: https://m.blog.naver.com/devks0228/221626517254
데이터 타입(Data Type)
참고링크
자세한 타입은 위에 참고링크를 확인 해주세요.
지금은 데이터 타입에 집중하지 않고 진행하도록 할게요.
데이터 타입은 크게 문자, 숫자, 날짜&시간으로 나눌 수 있어요.
| 문자 | 숫자 | 날짜 & 시간 |
| CHAR(최대 255byte) | INT(정수) | DATE(날짜: 년도, 월, 일) |
| VARCHAR(최대 65535byte) | FLOAT(소수) | TIME(시간: 시, 분, 초) |
| - | - | DATETIME(날짜, 시간 형태의 표현: time_zone 반영이 되지 않아요) |
| - | - | TIMESTAMP(날짜, 시간 형태의 표현: UTC 지원이 가능해 time_zone 반영을 할 수 있어요.) |
지금까지 아주 기본적인 개념을 살펴봤는데요. 이제부터 SQL 쿼리문을 알아보도록 합시다 : )
SELECT, FROM, LIMIT
SELECT <Column>
FROM <Table>
LIMIT <Count>
-- 위에있는 선수 테이블을 예로 들어보겠습니다.
-- 쿼리문의 종료에는 ;가 필요한 SQL도 있고 아닌 SQL도 있어요.
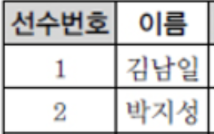
SELECT 선수번호, 이름
FROM 선수테이블
LIMIT 2; 결과는 아래와 같아요.
SELECT로 선택한 선수번호, 이름
FROM으로 선택한 선수테이블
LIMIT 2를 했기 때문에 2개만 반환해요.
만약 SELECT에 * 한다면 모든 Column을 가져옵니다.
LIMIT를 사용하지 않으면 모든 Row를 가져오구요.
AS, WHERE
-- AS: 별명을 지정
-- WHERE: 원하는 조건으로 데이터를 필터링
-- AND: WHERE의 조건외에 추가하고 싶은 조건을 붙일때 사용 (Javascript && 연산자처럼 생각하면 이해하기 쉬워요)
-- BETWEEN A AND B: A 이상 B 이하로 조건을 걸고 싶을 때 사용해요.
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_height >= 177
-- AND player_height BETWEEN 177 AND 178 위의 WHERE와 같은 조건이에요.| player_number | player_name | player_height |
| 1 | 김남일 | 177 |
| 2 | 박지성 | 178 |
-- OR: Javascript의 || 연산자라고 이해하면 쉬워요.
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_height > 175
AND (player_name = '박지성' OR player_name = '이영표');
-- IN: Javascript의 includes() 라고 이해하면 쉬워요.
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_height > 175
AND player_name IN ('박지성', '이영표');
-- NOT IN: Javascript의 !includes() 라고 이해하면 쉬워요.
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_height > 175
AND player_name NOT IN ('김남일');
-- LIKE: 부분적으로 일치하는 Column을 찾을때 사용해요.
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_height > 175| player_number | player_name | player_height |
| 2 | 박지성 | 178 |
| 3 | 이영표 | 176 |
-- LIKE: 부분적으로 일치하는 Column을 찾을때 사용해요.
-- NOT LIKE: 당연히 일치하지 않는 Column을 찾을때 사용합니다.
-- '%A%': A를 포함하는 경우
-- 'A%': A로 시작하는 경우
-- '%A': A로 끝나는 경우
-- 'A_': A로 시작하는 두글자 문자 찾는 경우
-- '[^A]': 첫번째 문자가 A가 아닌 모든 문자열을 찾는 경우
-- '[ABC]', '[A-C]': 첫번째 문자가 A || B || C 인 경우
SELECT 선수번호 AS player_number, 이름 AS player_name, 키 AS player_height
FROM 선수테이블
WHERE player_name LIKE '%지성%'| player_number | player_name | player_height |
| 2 | 박지성 | 178 |
-- AS 생략가능: 포지션 AS player_position = 포지션 player_position
-- UPPER(Column), LOWER(Column): Javascript의 toUpperCase(), toLowerCase()로 이해하시면 쉬워요.
SELECT LOWER(포지션) player_position, 이름 player_name
FROM 선수테이블| player_position | player_name |
| df | 김남일 |
| mf | 박지성 |
| mf | 이영표 |
GroupBy, Having을 학습하기 위해 새로운 Table을 사용할게요
| index | name | team |
| 1 | 안중근 | 1 |
| 2 | 강감찬 | 1 |
| 3 | 세종대왕 | 2 |
| 4 | 이순신 | 2 |
| 5 | 서희 | 3 |
| 6 | 을지문덕 | 3 |
| 7 | 궁예 | 4 |
team_info
GROUP BY, HAVING
-- GROUP BY: 특정 컬럼의 데이터를 그룹화 하기위해 사용해요.
-- COUNT(Column): Column에 값이 존재하는 데이터를 카운트 해요. (비워진 데이터는 카운트하지 않아요)
-- MAX(Column) / MIN(Column): Column의 값에서 최대 값(MAX), 최소 값(MIN)을 구해요.
-- SUM(Column): Column에 있는 값의 합계를 구하기 위해 사용해요.
-- AVG(Column): Column의 평균 값을 구하기 위해 사용해요.
-- ORDER BY <Column> ASC: ASC(오름차순)이 default이고 DESC(내림차순)이에요.
-- ASC는 따로 적지 않아도 기본 값으로 적용이 돼요.
--내림차 순으로 하고 싶다면 Column뒤에 한칸 공백을 하고 DESC를 붙여주세요.
SELECT team, COUNT(name) AS count_name
FROM team_info
GROUP BY team
ORDER BY team DESC;| team | count_name |
| 4 | 1 |
| 3 | 2 |
| 2 | 2 |
| 1 | 2 |
-- HAVING: 그룹화 결과에 조건을 적용해요. 그렇기 때문에 GROUP BY 뒤에 작성해요.
-- WHERE: 그룹화 전에 각 Row에 적용해요. 그렇기 때문에 GROUP BY 전에 작성해요.
SELECT team, COUNT(name) AS count_name
FROM team_info
GROUP BY team
HAVING count_name >= 2;| team | count_name |
| 1 | 2 |
| 2 | 2 |
| 3 | 2 |
지금까지 하나의 테이블을 대상으로 SQL의 기본적인 문법을 살펴보았는데요.
다음 포스팅에서 2개 이상의 테이블을 대상으로 SQL 쿼리문을 작성해 보도록 할게요.
부족한 글 읽어주셔서 감사해요 :)
