2024년 5월 16(목) ~ 17(일) 이틀간 코엑스 컨벤션 센터에서 열린 AWS Summit Seoul 2024에 참석하였고, 인상깊었던 내용들을 공유하고자 작성하는 후기입니다.
1. 컨퍼런스 소개
AWS Summit Seoul은 국내 최대 규모의 IT 컨퍼런스로, 이번 2024년에 10주년을 맞이했습니다.
이 컨퍼런스는 다양한 분야의 리더들의 기조연설을 통해 최신 IT 시장 트렌드를 파악할 수 있으며,
파트너사들의 클라우드 도입 노하우와 신기술을 공유하는 기술 강연으로 이루어져 있습니다.

1-1. 행사장 사진
국내 최대 규모 IT 컨퍼런스답게 입장하는 곳부터 웅장함을 느낄 수 있었습니다. 😄

2. 강연 목록
아래는 제가 선택했던 1일차 및 2일차 희망 강연들입니다.
전체 강연 목록은 AWS Summit Seoul 2024 Agenda_v16 에서 확인하실 수 있습니다.
2-1. 희망 강연 목록
1일차 (5/16)
- 11:10 ~11:50 : 데이터 주도 기업의 디지털 혁신 전략과 사례
- 1:10 ~ 1:50 : 채널톡 스타트업 기술 성장기 : RDBMS에서 NoSQL로의 전환
- 2:20 ~ 2:50 : 어떤 의도든 똑똑하게 이해하고 추론하는! Agents for Amazon Bedrock
- 3:20 ~ 4:00 : GS리테일 Amazon EKS의 모든 것 : 무중단 운영부터 배포 자동화까지
- 4:30 ~ 5:00 : AWS 최신기술을 활용한 클라우드 보안구성 방안
- 5:20 ~ 6:00 : 야놀자의 글로벌 신규 사업 진출 및 확장 노하우
2일차 (5/17)
- 11:10 ~11:50 : AWS로 구현하는 혁신적 애플리케이션 개발 전략
- 1:10 ~ 1:50 : 서비스를 현대화하기 위한 AWS 분산 디자인 패턴 구현하기
- 2:20 ~ 2:50 : 클라우드 보안의 새로운 패러다임
- 3:20 ~ 4:00 : 혁신을 가속화하는 AI : 개발자를 위한 새로운 AWS Gen AI 도구
- 4:30 ~ 5:00 : AI를 활용한 실시간 시대의 애플리케이션 강화 방법
- 5:20 ~ 6:00 : DevOps의 혁신 : Amazon EKS를 활용한. 플랫폼 엔지니어링 적용하기
2-2. 강연 사진들


3. 기억에 남는 강연
여러 강연들을 들었지만, 대부분이 배포 프로세스 혹은 클러스터 관리 및 생성형 AI 전략에 대한 내용이였습니다.
저에게 가장 재밌던 주제는 “채널톡 스타트업 기술 성장기: RDBMS에서 NoSQL로의 전환" 입니다.
채널톡에 대한 사전 설명
- *채널톡은 채널코퍼레이션이 제공하는 올인원 AI 채팅 서비스입니다.*
- 채팅상담, 챗봇, AI 전화 등의 기능을 가지고 있습니다.
3-1. 기존 서비스에서의 문제점
1. 스파이크 트래픽과 비용 비효율
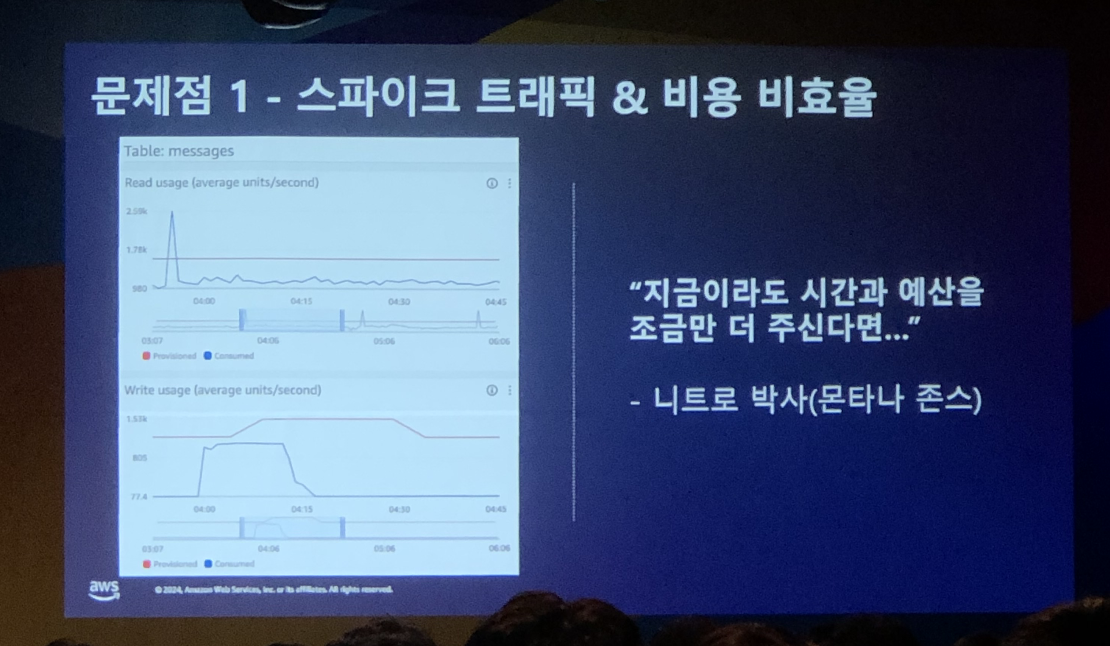
채널톡 서비스는 대부분 예측 가능한 트래픽 패턴을 가져, 오토스케일링만으로 충분한 대응이 가능합니다.
다만, 채널톡에서 제공하는 “일회성 메시지” 기능이 오토스케일링으로는 감당되지 않는 순간적인 대량의 트래픽을 야기하곤 합니다. (ex. 여러 회사에서 마케팅 메시지를 동일한 시간대에 예약 발송)
처음에는 스케일 업을 진행하려고 했으나 스파이크 트래픽이 발생하지 않는 시점에서는 낭비되는 리소스가 많기에 비용적으로 비효율적이라고 판단하였습니다.
2. 부하 전파
1번에서 스파이크 트래픽이 발생할 경우, 일회성 메시지를 저장하는 테이블에 부하가 걸립니다. (RDBS 특징)
이로 인해 DB 자체에 부하가 걸릴 경우 다른 테이블에도 부하가 전파되는 문제가 있습니다.
3. 오퍼레이션 호환성

채팅 목록 조회 화면에서는 채팅방 각각의 안 읽은 메시지 수와, 전체 채팅방의 읽지 않은 메시지 수를 보여줍니다.
이때 전체 채팅방의 읽지 않은 메시지 수는 각 채팅방의 안 읽은 메시지 수를 합산하여 계산합니다.
→ 이러한 오퍼레이션의 호환성으로 인해 신경써야 할 부분들이 존재합니다.
4. 마이그레이션

데이터베이스를 옮기는 작업은 매우 리스크가 큰 작업입니다. 기존 데이터를 안전히 옮겨야 하며, 동시에 실시간 데이터의 손실이 최대한 적도록 다운타임이 최대한 짧아야 합니다.
3-2. 해결 방법
Amazon DynamoDB를 이용하여 1번 & 2번 문제를 해결할 수 있었습니다.

1. DynamoDB의 온디맨드 혹은 프로비저닝 모드로 스파이크 트래픽 대처하기
온디맨드 모드와 테이블 사전 워밍 이용
- 온디맨드 모드
- 용량 계획 없이 초당 수천개의 요청을 처리 가능하며, 읽기 및 쓰기 요청에 대해 요청당 지불 가격을 제공
- 이는 사용하는 만큼 지불하면 되는 정책을 의미합니다.
- 애플리케이션 트래픽이 예측 불가능한 경우에 적합
- 테이블 사전 워밍
- 온디맨드 시에 이전 최대 트래픽의 2배까지 처리량을 늘릴 수 있지만, 그것보다 더 늘어날 경우 제한이 발생할 수 있음.
- → 이를 예상 피크 용량까지 사전 워밍하는 것을 통해 제한을 막을 수 있다.
프로비저닝된 모드와 오토 스케일링 이용
- 프로비저닝 모드
- 필요한 초당 읽기 및 쓰기 횟수를 지정하는 방식
- DynamoDB 사용을 정의된 요청 속도 이하로 유지하도록 관리하여 비용을 예측하는 데 도움이 됨
- 오토 스케일링
- DynamoDB Auto Scaling을 사용하면 테이블 또는 글로벌 보조 인덱스가 프로비저닝된 읽기 및 쓰기 용량을 늘려 요청 제한 없이 갑작스러운 트래픽 증가를 처리할 수 있음.
- 워크로드가 감소할 경우 DynamoDB Auto Scaling은 사용하지 않는 프로비저닝된 용량에 대한 요금을 지불하지 않도록 처리량을 줄일 수 있음.
2. DynamoDB의 설계로 인한 부하 전파 대처하기
- DynamoDB는 분산 아키텍처를 사용하여 데이터를 여러 파티션에 분산 저장하고 처리
- → 특정 테이블이나 파티션에 부하가 걸리더라도 전체 데이터베이스가 영향을 받지 않도록 설계되어 있음
3. 테이블을 분리함으로써, 연산을 분리하기

DynamoDB에는 COUNT 쿼리가 존재하지 않아, 아래와 같이 별도의 테이블로 설계
- 특정 채팅방의 안 읽은 메시지 수
- 전체 채팅방의 안 읽은 메시지 수
따라서, 새로운 채팅 메시지를 받았을 때 채팅방 목록 조회 화면에서는 아래와 같은 쿼리가 발생한다.
- 특정 채팅방의 안 읽은 메시지 수 조회
- 전체 채팅방의 안 읽은 메시지 수 조회
→ 특정 채팅방의 안 읽은 메시지 수들을 합하는 연산이 필요하지 않아 시간 복잡도가 1로 줄어들었다.
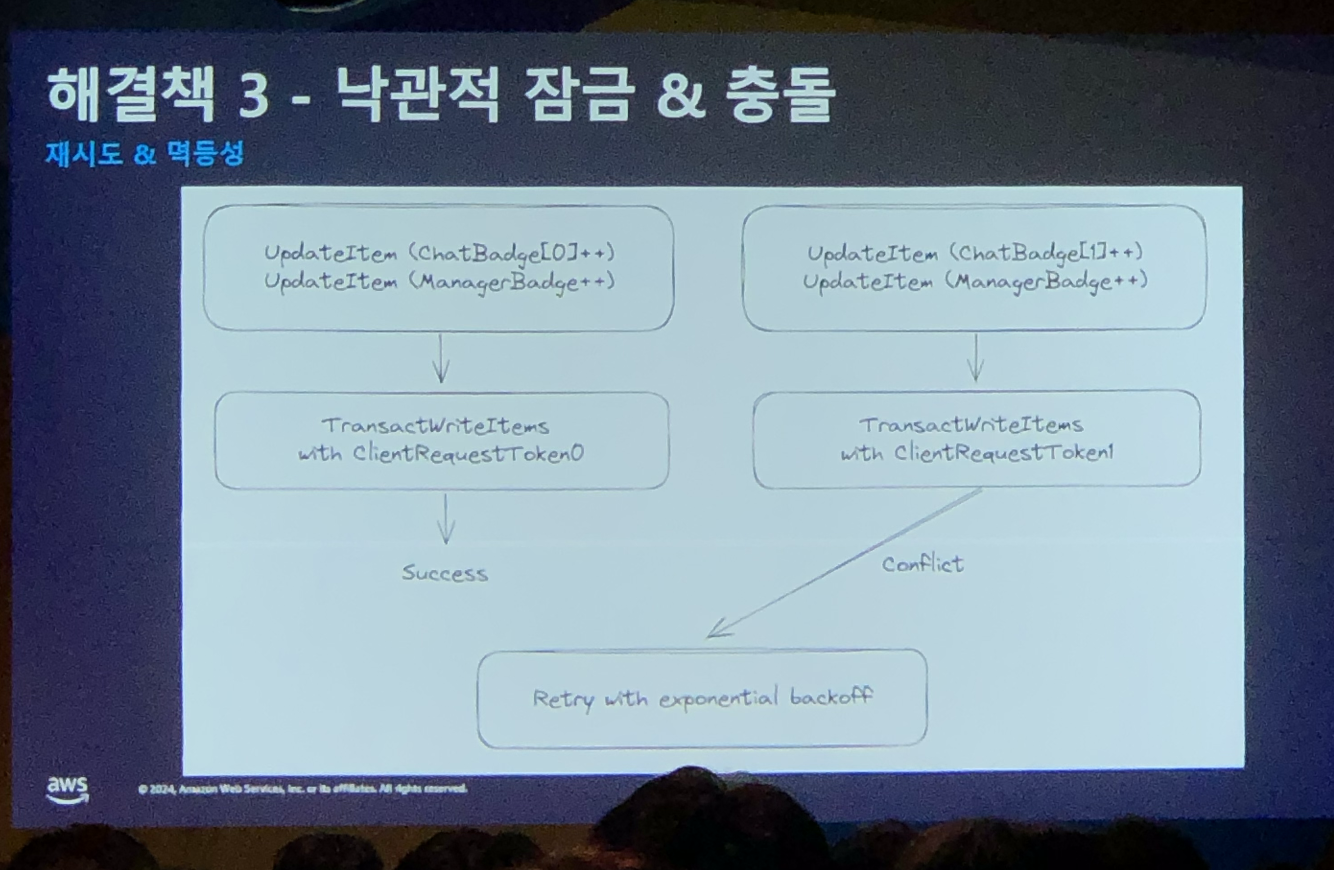
새로운 채팅 메시지를 받았을 때, 안 읽은 메시지 수를 증가시키다가 충돌이 발생할 수 있다.
이를 피하기 위해 두 작업을 DynamoDB 트랜잭션으로 묶어 하나의 작업처럼 동작하도록 하였다.
또한 낙관적 락을 걸고, 충돌이 날 경우에 백오프 전략으로 재시도하도록 설정하였다.
4. 병렬 스캔 아이디어를 차용한 실시간 데이터베이스 마이그레이션
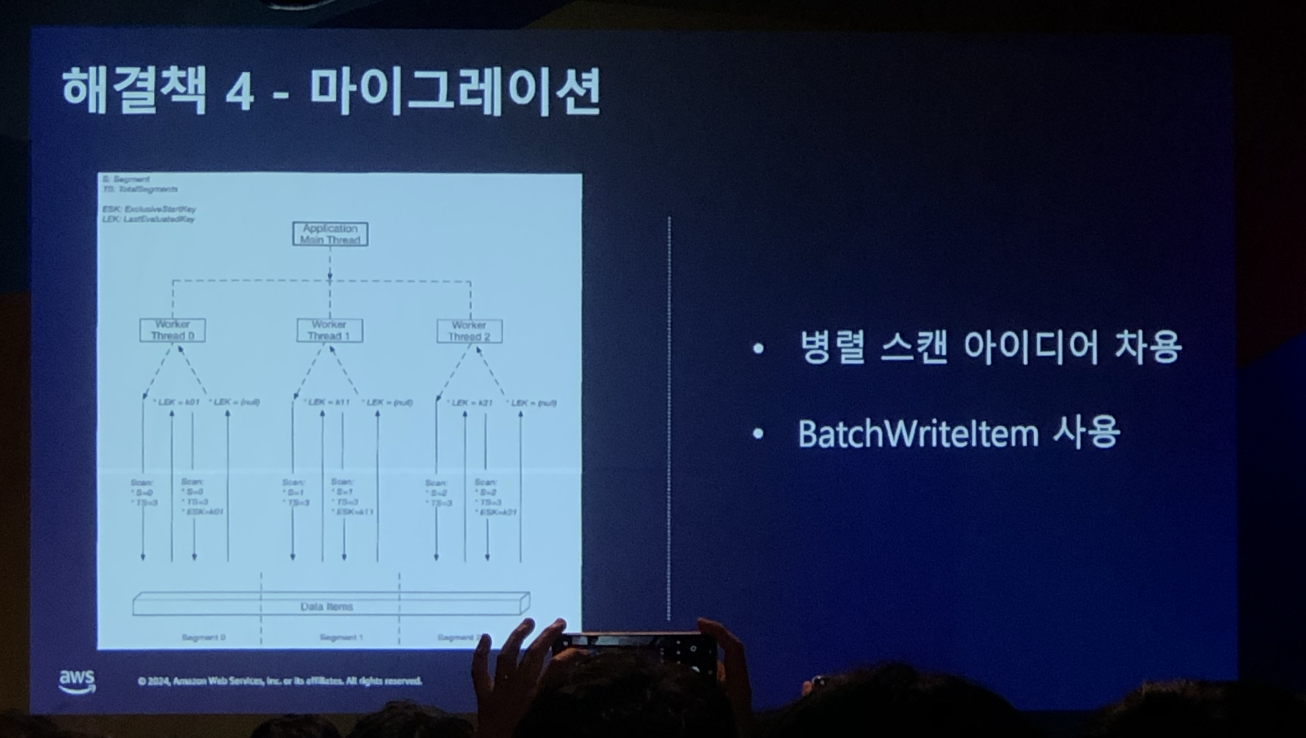
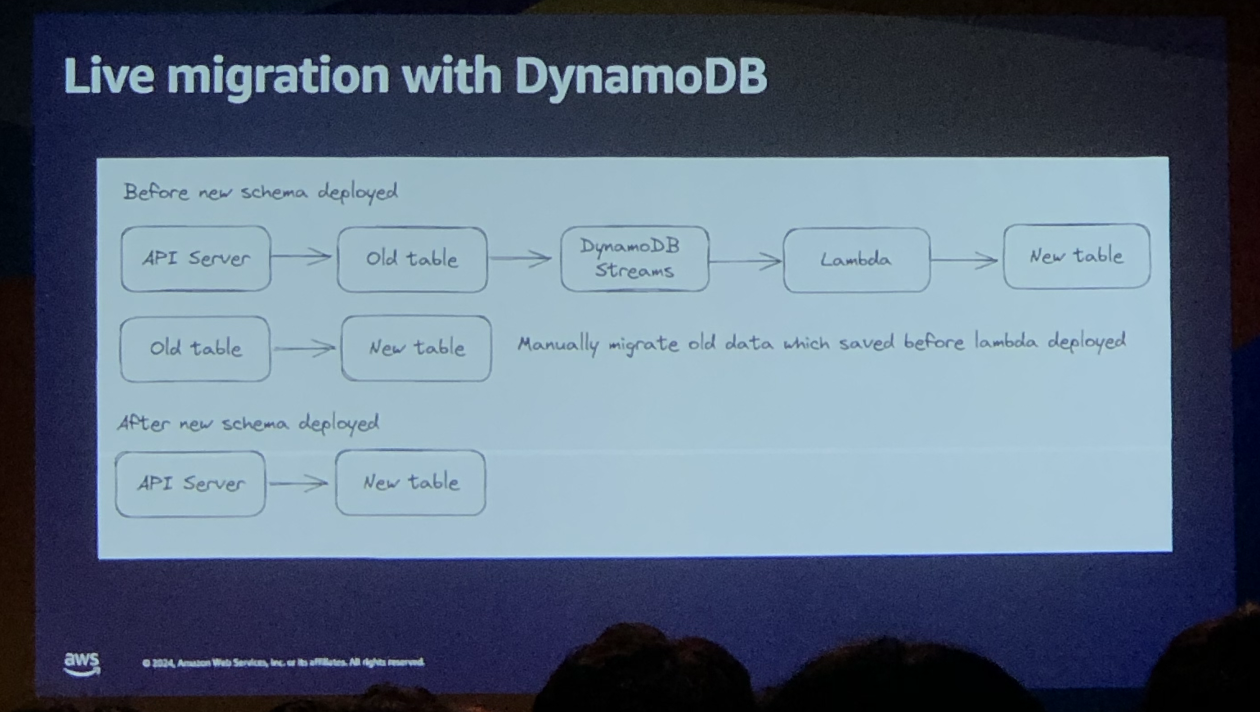
실시간 DynamoDB 마이그레이션은 아래와 같이 진행하였다.
- RDBMS의 데이터를 NoSQL로 이동하는 작업을 진행
- 동시에 실시간으로 서버에 요청이 들어오는 건들은 RDBMS에 저장
- DynamoDB Streams를 이용해 RDBMS에 데이터가 들어오는 것을 감지
- 람다를 실행시켜 RDBMS에 새로 들어온 데이터를 NoSQL로 이동
3-3. 연속해서 생긴 해결해야 할 점
프로비저닝 모드와 오토스케일링을 조합하여 사용하고 있지만, 여전히 들어오는 트래픽이 순간적으로 매우 클 경우에는 역부족하다. → 결국 먼저 트래픽을 받아 줄 외부 버퍼가 필요했고, Amazon SQS를 활용하기로 결정
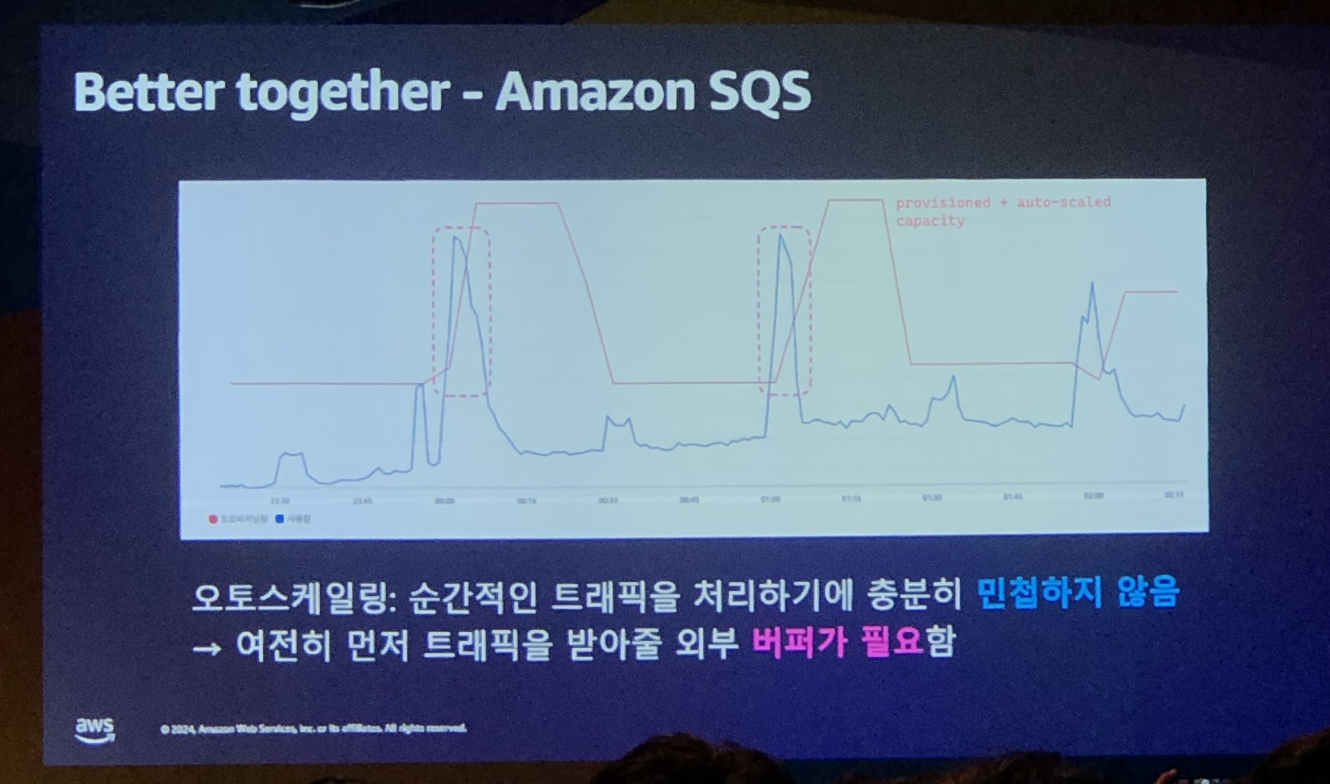
- 메시지를 queue에서 빼오는 것만으로는 SQS에서 메시지가 삭제되지 않는다.
- 메시지 각각에 대해 처리가 완료되었다(ACK)는 것을 SQS에 다시 요청해야 queue에서 메시지가 삭제된다. (kafka의 경우는 checkpoint로 “어디까지 처리했다~” 정도만 판단 가능)
1. Amazon SQS 컨슈머 구성하기
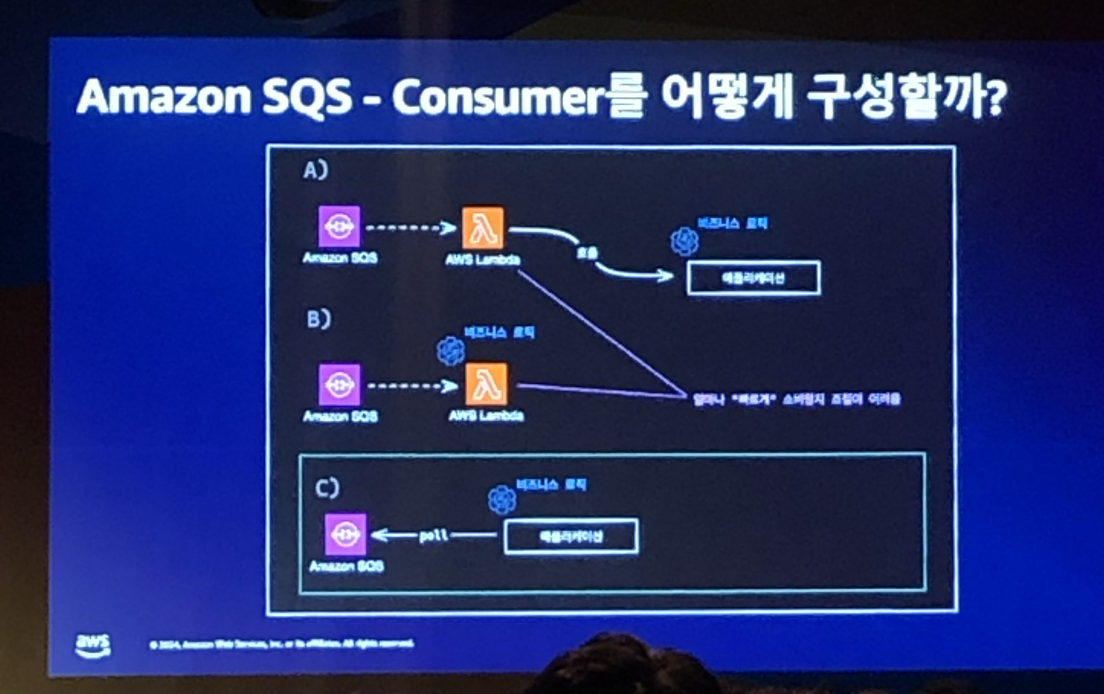
AWS SQS에 메시지가 전송되었을 때, 소비하는 컨슈머를 어떻게 구성할지에 대한 고민을 해야 했습니다.
고려했던 3가지 선택지는 아래와 같습니다.
- SQS에 메시지가 들어오면 Lambda가 동작하여 애플리케이션의 비즈니스 로직을 호출하기
- SQS에 메시지가 들어오면 Lambda에서 직접 비즈니스 로직 실행하기
- SQS에 메시지가 들어오면 애플리케이션에서 메시지를 꺼내가기
위 3가지 선택지 중 A와 B 선택지의 경우 “얼마나 빠르게 소비할지에 대한 조절이 어렵다”는 단점이 있었고, 이러한 이유로 C를 선택하게 되었습니다.
2. 컨슈머 스케일 업
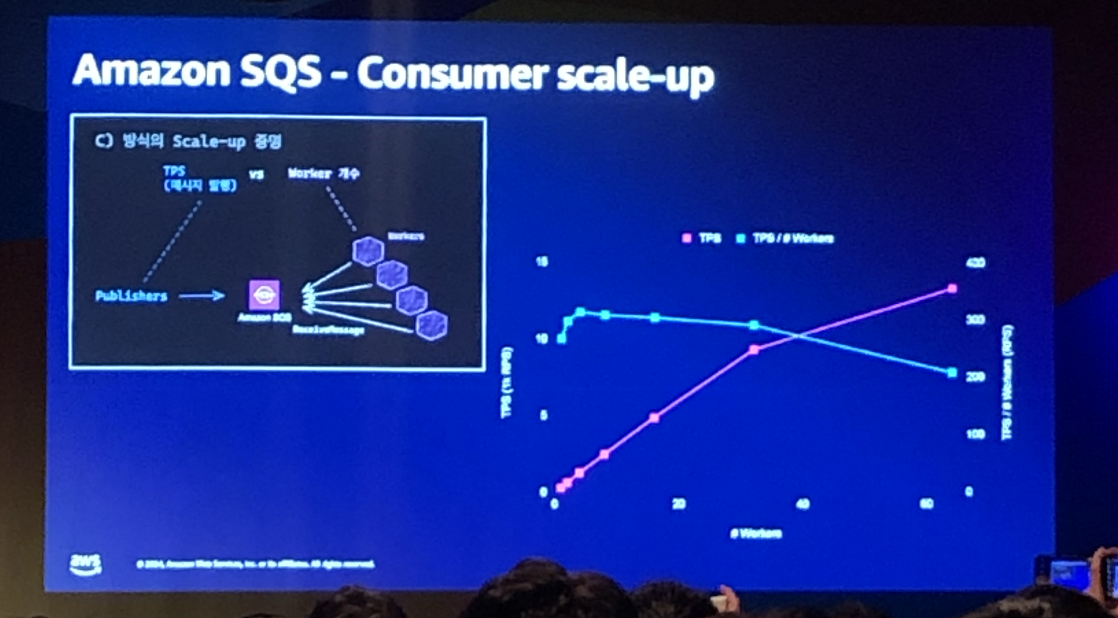
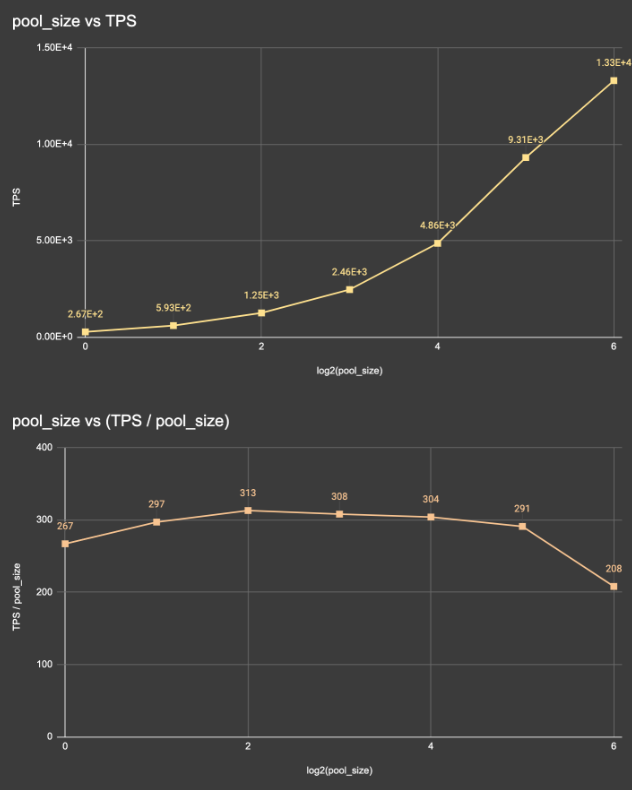
이후에는 성능 향상을 위해 컨슈머 스케일업을 진행하였습니다. (아래 사진 참고)
Consumer worker의 갯수를 늘려 나가며, TPS를 비교한 결과는 아래와 같습니다.
- Worker의 처리 속도는 갯수에 상관없이 300TPS 정도를 유지한다.
- Queue를 폴링하는 worker는 다른 worker와 독립적으로 작동하니,
worker 갯수가 n개가 되면처리 속도도 n배가 된다.
3-4. 비즈니스 성과 및 기술적 교훈

- Amazon SQS를 통해 작업 분산을 늘리고, 순간적인 트래픽에 취약했던 문제점을 보완
- 인메모리가 아닌 외부 큐를 이용하기 때문에 인스턴스가 죽더라도 새로운 인스턴스에서 큐를 소비 가능
- 메시지를 읽다가 어플리케이션이 죽어도 안전하게 재시도 가능
- Amazon CloudWatch Alarm 및 Metrics를 이용해 디버깅 편의성을 얻고 알림 설정 가능
- DynamoDB의 요금 정책을 이용해 고정 비용에서 가변 비용으로 변경
4. 느낀 점
RDBMS에서 NoSQL(DynamoDB)로 전환함으로써 생기는 이점들로 문제점을 극복한 경우들이 인상 깊었습니다.
아직 NoSQL 사용 경험이 없기에, 꾸준히 관심을 가져야 함을 느꼈습니다.
또한 메시지큐를 활용해 대규모 트래픽을 처리하는 방식에 대해 학습할 수가 있었고,
실제 운영 사례를 공유하는 자리를 참여할 수 있어서 동기부여가 되는 기회였습니다.
5. 참고자료
