Java에서 멀티스레드 환경을 지원하는 동시성 컬렉션에 대해 정리한 내용으로, 초반에는 기본적인 컬렉션에 대한 이론이 많이 나옵니다.
동시성 컬렉션이 궁금하신 분들은 8장으로 이동하시길 바랍니다.
8장에서 다룬 동시성 컬렉션 목록
- ConcurrencyMap
- CopyOnWriteList
- ConcurrentSkipListMap
- ConcurrentSkipListSet
- BlockingQueue
- ConcurrentLinkedQueue
- ConcurrentLinkedDeque
이외에 8장에서 소개하는 예제 코드들은 Github에서 확인하실 수 있습니다.
1. 컬렉션
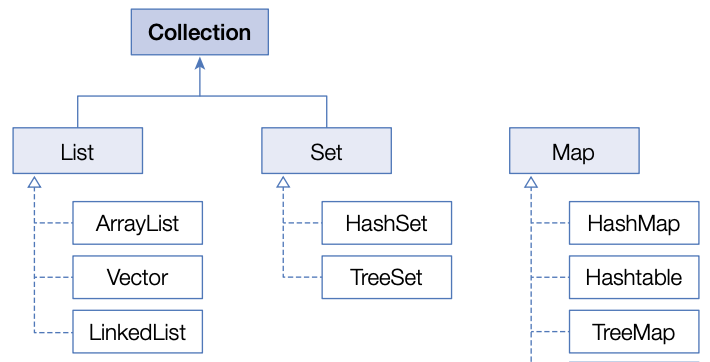
Java는 java.util 패키지에 객체들을 효율적으로 보관하는 인터페이스를 컬렉션이라는 이름으로 총칭한다.
List와 Set은 객체를 추가, 삭제, 검색하는 방법에 있어 공통점이 있기 때문에 공통점을 Collection 인터페이스로 정의해두고 상속한다.

2. List
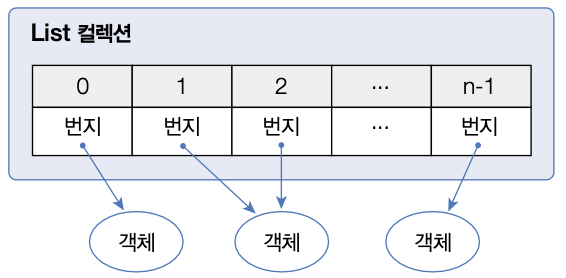
List 컬렉션은 객체를 인덱스로 관리하기 때문에 객체를 저장하면 인덱스가 부여되고 인덱스로 객체 를 검색, 삭제할 수 있는 기능을 제공한다.
List 컬렉션에는 ArrayList, LinkedList, Vector가 존재한다.
2-1. ArrayList
ArrayList에 객체를 추가하면 내부 배열에 객체가 저장된다.
일반 Array(배열)과 차이점은 용량 제한 없이 추가할 수 있다는 것이다.
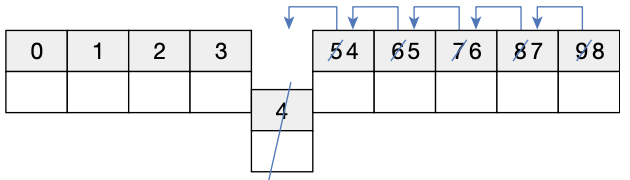
아래의 이유로, 빈번하게 객체의 삽입과 삭제가 일어날 경우에는 ArrayList가 바람직하지 않다.
특정 인덱스의 객체를 제거할 경우, 바로 뒤 인덱스부터 마지막 인덱스까지 모두 앞으로 1씩 당겨진다.
마찬가지로 특정 인덱스에 객체를 삽입하는 해당 인덱스부터 마지막 인덱스까지 모두 1씩 밀려난다.
2-2. Vector
Vector는 ArrayList와 동일한 내부 구조를 가지고 있다.
차이점은 Vector는 동기화된 synchronized 메소드로 구성되어 있어, 멀티 스레드 환경에서는 안전하게 객체를 추가 또는 삭제할 수 있다.
2-3. LinkedList
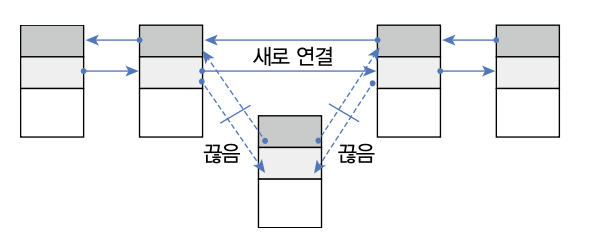
- ArrayList와 사용 방법은 동일하지만 내부 구조는 완전히 다르다.
- ArrayList는 내부 배열에 객체를 저장하지만, LinkedList는 인접 객체를 체인처럼 연결해서 관리한다.
LinkedList는 빈번한 객체 삭제와 삽입이 일어나는 곳에서는 ArrayList보다 좋은 성능을 발휘한다.
LinkedList는 특정 위치에서 객체를 삽입하거나 삭제하면 바로 앞뒤 링크만 변경하면 된다.
3. Set
Set은 List와 다르게 저장 순서가 유지되지 않는다. 또한 객체를 중복 저장할 수 없다.
3-1. HashSet
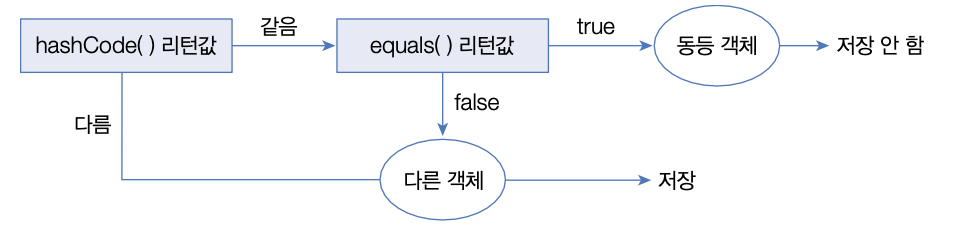
HashSet은 동일한 객체는 중복 저장하지 않는다. 여기서 동일한 객체란 동등 객체를 말한다.
다른 객체라도 hashCode () 메소드의 리턴값이 같고, equals () 메소드가 true를 리턴하면 동일한 객체라고 판단하고 중복 저장하지 않는다.
4. Map
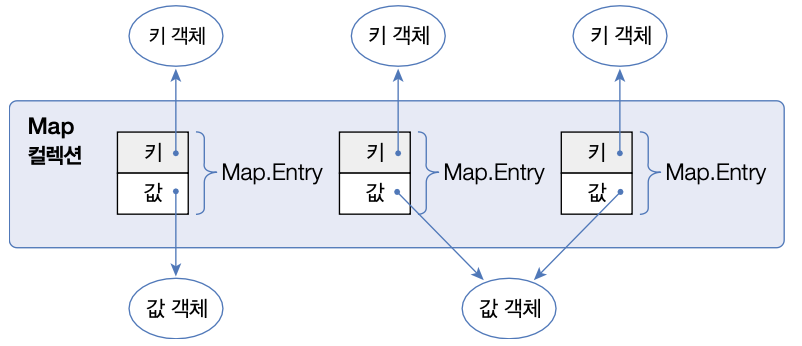
Map 컬렉션은 키key와 값value으로 구성된 엔트리(Entry) 객체를 저장한다.
키는 중복 저장할 수 없지만 값은 중복 저장할 수 있다.
기존에 저장된 키와 동일한 키로 값을 저장하면 기존의 값은 없어지고 새로운 값으로 대치된다.
4-1. HashMap
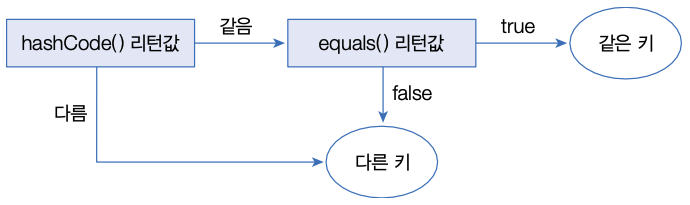
HashMap은 키로 사용할 객체가 hashCode() 메소드의 리턴값이 같고 equals() 메소드가 true 를 리턴할 경우, 동일 키로 보고 중복 저장을 허용하지 않는다.
4-2. HashTable
Hashtable은 HashMap과 동일한 내부 구조를 가지고 있다.
차이점은 Hashtable은 동기화된 (synchronized) 메소드로 구성되어 있기 때문에 멀티 스레드가 동시에 Hashtable의 메소드들을 실행할 수 없다다.
따라서 멀티 스레드 환경에서도 안전하게 객체를 추가, 삭제할 수 있다.

사용 예제
아래 예제를 HashTable이 아닌 HashMap으로 변경할 경우, 에러가 발생하거나 총합이 2000개가 아니게 된다.
public class HashtableExample {
public static void main(String[] args) {
//Hashtable 컬렉션 생성
Map<String, Integer> map = new Hashtable<>();
//작업 스레드 객체 생성
Thread threadA = new Thread(() -> {
//엔트리 1000개 추가
for (int i = 1; i <= 1000; i++) {
map.put(String.valueOf(i), i);
}
});
//작업 스레드 객체 생성
Thread threadB = new Thread(() -> {
//엔트리 1000개 추가
for (int i = 1001; i <= 2000; i++) {
map.put(String.valueOf(i), i);
}
});
//작업 스레드 실행
threadA.start();
threadB.start();
//작업 스레드들이 모두 종료될 때까지 메인 스레드를 기다리게 함
try {
threadA.join();
threadB.join();
} catch (Exception e) {
}
//저장된 총 엔트리 수 얻기
int size = map.size();
System.out.println("총 엔트리 수: " + size); // 2000
}
}5. 검색 기능을 강화시킨 컬렉션
5-1. TreeSet
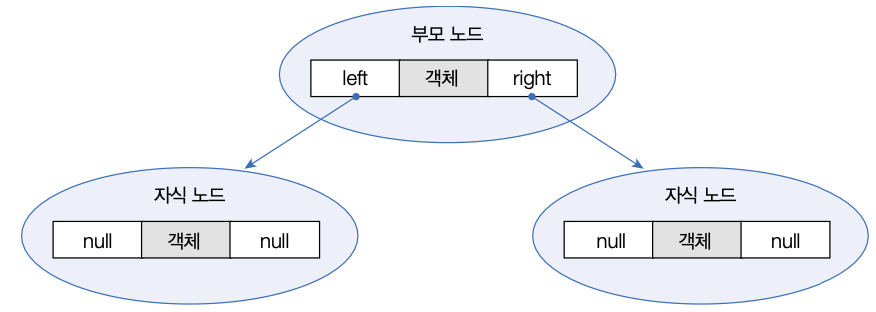
TreeSet은 이진 트리를 기반으로 한 Set 컬렉션이다.
이진 트리는 여러 개의 노드가 트리 형태로 연결된 구조로, 루트 노드라고 불리는 하나의 노드에서 시작해 각 노드에 최대 2개의 노드를 연결할 수 있는 구조를 가지고 있다.
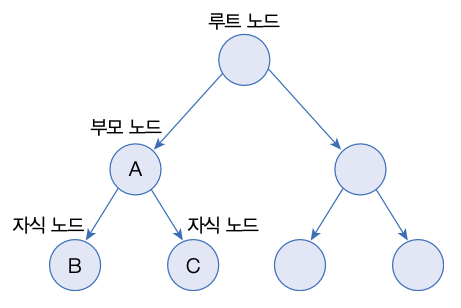
TreeSet에 객체를 저장하면 다음과 같이 자동으로 정렬된다.
부모 노드의 객체와 비교해서 낮은 것 은 왼쪽 자식 노드에, 높은 것은 오른쪽 자식 노드에 저장한다.
TreeSet의 검색 관련 메서드
| 리턴 타입 | 메소드 | 설명 |
|---|---|---|
| E | first( ) | 제일 낮은 객체를 리턴 |
| E | last( ) | 제일 높은 객체를 리턴 |
| E | lower(E e) | 주어진 객체보다 바로 아래 객체를 리턴 |
| E | higher(E e) | 주어진 객체보다 바로 위 객체를 리턴 |
| E | floor(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 없다면 바로 아래 객체를 리턴 |
| E | ceiling(E e) | 주어진 객체와 동등한 객체가 있으면 리턴, 없다면 바로 위 객체를 리턴 |
| E | pollFirst( ) | 제일 낮은 객체를 꺼내오고 컬렉션에서 제거함 |
| E | pollLast( ) | 제일 높은 객체를 꺼내오고 컬렉션에서 제거함 |
5-2. TreeMap
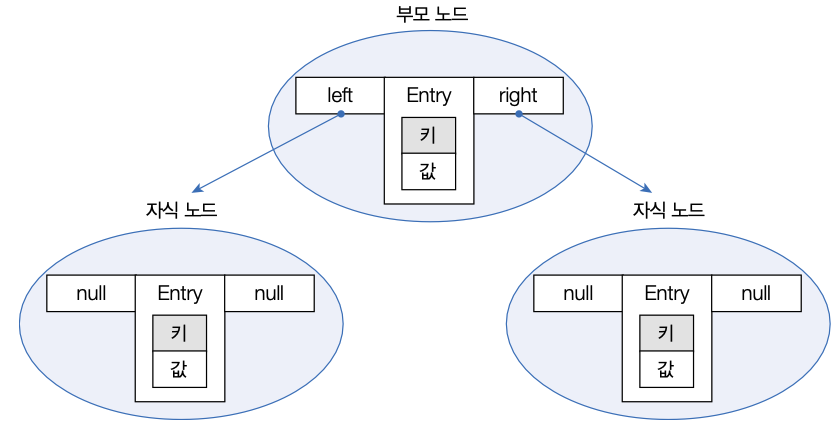
TreeMap은 이진 트리를 기반으로 한 Map 컬렉션이다.
TreeSet과의 차이점은 키와 값이 저장된 Entry를 저장한다는 점이다.
TreeMap에 엔트리를 저장하면 키를 기준으로 자동 정렬되는데, 부모 키 값과 비교해서 낮은 것은 왼쪽, 높은 것은 오른쪽 자식 노드에 Entry 객체를 저장한다.
TreeMap의 검색 관련 메서드
| 리턴 타입 | 메소드 | 설명 |
|---|---|---|
| Map.Entry\<K,V> | firstEntry( ) | 제일 낮은 Map.Entry를 리턴 |
| Map.Entry\<K,V> | lastEntry( ) | 제일 높은 Map.Entry를 리턴 |
| Map.Entry\<K,V> | lowerEntry(K key) | 주어진 키보다 바로 아래 Map.Entry를 리턴 |
| Map.Entry\<K,V> | higherEntry(K key) | 주어진 키보다 바로 위 Map.Entry를 리턴 |
| Map.Entry\<K,V> | floorEntry(K key) | 주어진 키와 동등한 키가 있으면 해당 Map.Entry를 리턴, 없다면 주어진 키 바로 아래의 Map.Entry를 리턴 |
| Map.Entry\<K,V> | ceilingEntry(K key) | 주어진 키와 동등한 키가 있으면 해당 Map.Entry를 리턴, 없다면 주어진 키 바로 위의 Map.Entry를 리턴 |
| Map.Entry\<K,V> | pollFirstEntry( ) | 제일 낮은 Map.Entry를 꺼내오고 컬렉션에서 제거함 |
| Map.Entry\<K,V> | pollLastEntry( ) | 제일 높은 Map.Entry를 꺼내오고 컬렉션에서 제거함 |
| NavigableSet\<K> | descendingKeySet( ) | 내림차순으로 정렬된 키의 NavigableSet을 리턴 |
| NavigableMap\<K,V> | descendingMap( ) | 내림차순으로 정렬된 Map.Entry의 NavigableMap을 리턴 |
| NavigableMap\<K,V> | headMap(K toKey, boolean inclusive) | 주어진 키보다 낮은 Map.Entry들을 NavigableMap으로 리턴. 주어진 키의 Map.Entry 포함 여부는 두 번째 매개값에 따라 달라짐 |
| NavigableMap\<K,V> | tailMap(K fromKey, boolean inclusive) | 주어진 객체보다 높은 Map.Entry들을 NavigableSet으로 리턴. 주어진 객체 포함 여부는 두 번째 매개값에 따라 달라짐 |
| NavigableMap\<K,V> | subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) | 시작과 끝으로 주어진 키 사이의 Map.Entry들을 NavigableMap 컬렉션으로 반환. 시작과 끝 키의 Map.Entry 포함 여부 |
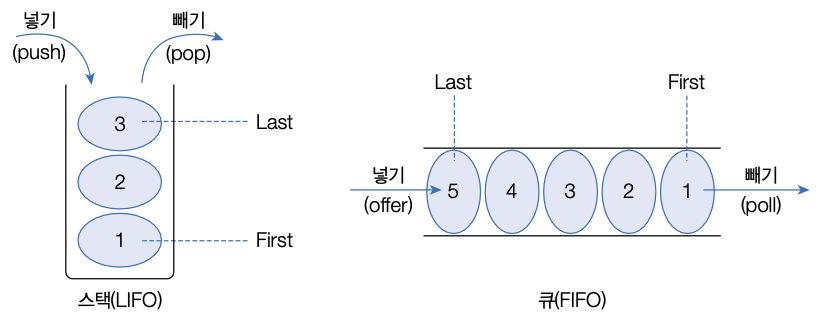
6. LIFO & FIFO 컬렉션
Java의 컬렉션은 LIFO 자료구조의 Stack 클래스와 FIFO 자료구조의 Queue 인터페이스를 제공한다.
- 스택을 응용한 대표적인 예시 : JVM 스택 메모리
- 큐를 응용한 대표적인 예시 : 스레드풀(ExecutorService)의 작업 큐
7. 동기화된 컬렉션
ArrayList, HashSet, HashMap을 멀티 스레드 환경에서 사용하고 싶을 때가 있을 것이다.
이를 대비해서 비동기화된 메소드를 동기화된 메소드로 래핑하는 synchronizedXXX() 메소드를 제공한다.
메서드 예시
| 리턴 타입 | 메소드(매개변수) | 설명 |
|---|---|---|
| List\<T> | synchronizedList(List\<T> list) | List를 동기화된 List로 리턴 |
| Map\<K,V> | synchronizedMap(Map\<K,V> m) | Map을 동기화된 Map으로 리턴 |
| Set\<T> | synchronizedSet(Set\<T> s) | Set을 동기화된 Set으로 리턴 |
사용 예시
List<T> list = Collections.synchronizedList(new ArrayList<T>());
Set<T> set = Collections.synchronizedSet(new HashSet<T>());
Map<K, V> map = Collections.synchronizedMap(new HashMap<K, V>());8. 동시성에 안전한 컬렉션
8-1. ConcurrencyMap
ConcurrentMap은 동시성 문제를 해결하기 위해 특별히 설계된 맵 인터페이스입니다.
Java에서는 ConcurrentHashMap 클래스가 이 인터페이스를 구현합니다.
주요 특징
- 동시성 제어:
- 여러 스레드가 동시에 데이터를 삽입하거나 삭제하는 경우에도 안전하게 동작
- 락 분할(Lock Striping):
- 전체 맵을 하나의 락으로 제어하는 것이 아니라, 여러 개의 락으로 나누어 동시성을 높인다.
- → 이를 통해 성능이 향상
- 원자적 연산:
putIfAbsent,remove,replace와 같은 메서드를 통해 여러 스레드가 동시에 작업해도 데이터의 일관성을 유지할 수 있다.
크기 제어 여부
- 확장 방식: 필요에 따라 버킷 수를 두 배로 늘리며 확장
- 축소 여부: 자동으로 크기를 줄이지는 않는다.
예시 코드
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class ConcurrentMapExample {
private static final int NUM_THREADS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentMap<String, Integer> map = new ConcurrentHashMap<>();
// 쓰레드 배열
Thread[] threads = new Thread[NUM_THREADS];
// 쓰레드를 생성하여 ConcurrentMap에 데이터를 삽입
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
final String threadName = Thread.currentThread().getName() + "-" + j;
System.out.println("threadName = " + threadName);
map.put(threadName, j);
}
});
}
// 모든 쓰레드 시작
for (Thread thread : threads) {
thread.start();
}
// 모든 쓰레드가 작업을 마칠 때까지 대기
for (Thread thread : threads) {
thread.join();
}
// 맵의 크기 확인
System.out.println("Map size: " + map.size());
// 맵의 데이터 검증
for (int i = 0; i < NUM_THREADS; i++) {
for (int j = 0; j < NUM_ENTRIES; j++) {
String key = "Thread-" + i + "-" + j;
Integer value = map.get(key);
if (value == null || value != j) {
System.out.println("Data inconsistency found: " + key + " -> " + value);
}
}
}
System.out.println("Data consistency check complete.");
}
}
====================================
Map size: 10000
Data consistency check complete.8-2. CopyOnWriteList
CopyOnWriteArrayList는 쓰기 작업이 발생할 때마다 내부 배열을 복사하는 리스트입니다.
주로 읽기 작업이 빈번하고 쓰기 작업이 드물 때 사용됩니다.
주요 특징
- 읽기-쓰기 분리:
- 읽기 작업은 락 없이 수행되고,
- 쓰기 작업은 내부 배열을 복사하여 새로운 배열을 만들어 수행
- 따라서 읽기 작업이 매우 빠르다.
- 불변성:
- 쓰기 작업이 발생할 때마다 새로운 배열을 생성
- 읽기 작업 중에 데이터의 불변성을 유지할 수 있다.
- 성능 특성:
- 읽기 작업이 빈번하고 쓰기 작업이 적은 경우에 매우 효율적
크기 제어 여부
- 확장 방식: 배열이 가득 차면 새로운 배열을 생성하고 현재 크기의 약 1.5배로 확장
- 축소 여부: 자동으로 크기를 줄이지는 않습니다. 배열의 크기는 그대로 유지된다.
예시 코드
public class CopyOnWriteArrayListExample {
private static final int NUM_THREADS = 10;
private static final int NUM_ENTRIES = 100;
public static void main(String[] args) throws InterruptedException {
List<String> list = new CopyOnWriteArrayList<>();
// 쓰레드 배열
Thread[] threads = new Thread[NUM_THREADS];
// 쓰레드를 생성하여 CopyOnWriteArrayList에 데이터를 삽입
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
String threadName = Thread.currentThread().getName();
String value = threadName + "-" + j;
list.add(value);
}
});
}
// 모든 쓰레드 시작
for (Thread thread : threads) {
thread.start();
}
// 모든 쓰레드가 작업을 마칠 때까지 대기
for (Thread thread : threads) {
thread.join();
}
// 리스트의 크기 확인
System.out.println("List size: " + list.size());
// 리스트의 데이터 검증
int expectedSize = NUM_THREADS * NUM_ENTRIES;
if (list.size() != expectedSize) {
System.out.println("Data inconsistency found. Expected size: " + expectedSize + ", Actual size: " + list.size());
} else {
System.out.println("Data consistency check complete. All entries are present.");
}
}8-3. ConcurrentSkipListMap
ConcurrentSkipListMap은 동시성 문제를 해결하면서 정렬된 맵을 제공한다.
이 맵은 스킵 리스트를 사용하여 내부적으로 구현되어 있다.
주요 특징
- 정렬된 맵:
- 항목이 삽입된 순서에 따라 정렬된 상태로 유지된다.
- 높은 동시성:
- 여러 스레드가 동시에 읽기 및 쓰기 작업을 수행할 수 있다.
크기 제어 여부
- 확장 방식: 트리 기반 구조로 필요에 따라 노드를 추가하여 확장
- 축소 여부: 항목을 제거할 때 노드를 해제하여 메모리를 반환
사용 예제
public class ConcurrentSkipListMapExample {
private static final int NUM_THREADS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentMap<String, Integer> map = new ConcurrentSkipListMap<>();
// 쓰레드 배열
Thread[] threads = new Thread[NUM_THREADS];
// 쓰레드를 생성하여 ConcurrentSkipListMap에 데이터를 삽입
for (int i = 0; i < NUM_THREADS; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
String threadName = Thread.currentThread().getName() + "-" + j;
map.put(threadName, j);
}
});
}
// 모든 쓰레드 시작
for (Thread thread : threads) {
thread.start();
}
// 모든 쓰레드가 작업을 마칠 때까지 대기
for (Thread thread : threads) {
thread.join();
}
// 맵의 정렬 상태 확인
map.forEach((key, value) -> System.out.println(key + ": " + value));
// 맵의 크기 확인
System.out.println("Map size: " + map.size());
// 맵의 데이터 검증
for (int i = 0; i < NUM_THREADS; i++) {
for (int j = 0; j < NUM_ENTRIES; j++) {
String key = "Thread-" + i + "-" + j;
Integer value = map.get(key);
if (value == null || value != j) {
System.out.println("Data inconsistency found: " + key + " -> " + value);
}
}
}
System.out.println("Data consistency check complete.");
}
}
=======================================================
...
Thread-9-997: 997
Thread-9-998: 998
Thread-9-999: 999
Map size: 10000
Data consistency check complete.8-4. ConcurrentSkipListSet
이는 동시성 문제를 해결하면서 정렬된 집합을 제공하며, ConcurrentSkipListMap 를 기반으로 구현됐다.
주요 특징
- 정렬된 집합:
- 항목이 삽입된 순서에 따라 정렬된 상태로 유지된다.
- 높은 동시성:
- 여러 스레드가 동시에 읽기 및 쓰기 작업을 수행할 수 있다.
크기 제어 여부
- 확장 방식: 내부적으로
ConcurrentSkipListMap을 사용하므로 트리 기반 구조로 필요에 따라 노드를 추가하여 확장 - 축소 여부: 항목을 제거할 때 노드를 해제하여 메모리를 반환
사용 예제
import java.util.concurrent.ConcurrentSkipListSet;
public class ConcurrentSkipListSetExample {
private static final int NUM_THREADS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentSkipListSet<String> set = new ConcurrentSkipListSet<>();
// 쓰레드 배열
Thread[] threads = new Thread[NUM_THREADS];
// 쓰레드를 생성하여 ConcurrentSkipListSet에 데이터를 삽입
for (int i = 0; i < NUM_THREADS; i++) {
final int threadIndex = i;
threads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
set.add("Thread-" + threadIndex + "-" + j);
}
});
}
// 모든 쓰레드 시작
for (Thread thread : threads) {
thread.start();
}
// 모든 쓰레드가 작업을 마칠 때까지 대기
for (Thread thread : threads) {
thread.join();
}
// 집합의 크기 확인
System.out.println("Set size: " + set.size());
// 집합의 데이터 검증
for (int i = 0; i < NUM_THREADS; i++) {
for (int j = 0; j < NUM_ENTRIES; j++) {
String key = "Thread-" + i + "-" + j;
if (!set.contains(key)) {
System.out.println("Data inconsistency found: " + key);
}
}
}
System.out.println("Data consistency check complete.");
}
}
========================================================
List size: 1000
Data consistency check complete. All entries are present.8-5. BlockingQueue
동시성 문제를 해결하기 위해 추가적인 기능을 제공하는 인터페이스이다.
구현체는 대표적으로 ArrayBlockingQueue, LinkedBlockingQueue, PriorityBlockingQueue, DelayQueue 등이 있다.
주요 특징
- 쓰레드 간 통신:
- 생산자-소비자 패턴에서 주로 사용된다.
- 생산자는 큐에 아이템을 추가하고, 소비자는 큐에서 아이템을 가져간다.
- 블로킹 연산:
- 큐가 가득 차면 생산자는 큐에 아이템을 추가하려고 할 때 블록되고, 큐가 비어 있으면 소비자는 큐에서 아이템을 가져오려고 할 때 블록됩니다.
크기 제어 여부
- 구현체마다 크기 확장과 축소 방식이 다름
ArrayBlockingQueue- 확장 방식: 고정된 크기를 가지며 확장되지 않는다.
- 축소 여부: 고정된 크기이므로 축소되지 않는다.
LinkedBlockingQueue- 확장 방식: 큐에 항목을 추가할 때 노드를 추가하는 방식으로 확장
- 축소 여부: 항목을 제거할 때 노드를 해제하여 메모리를 반환 (=즉, 필요에 따라 크기가 축소)
PriorityBlockingQueue- 확장 방식: 내부적으로
PriorityQueue와 유사하게 동작하며, 필요에 따라 두 배로 크기를 확장 - 축소 여부: 자동으로 크기를 줄이지는 않는다.
- 확장 방식: 내부적으로
DelayQueue- 확장 방식: 내부적으로
PriorityQueue와 유사하게 동작하며, 필요에 따라 두 배로 크기를 확장 - 축소 여부: 자동으로 크기를 줄이지는 않는다.
- 확장 방식: 내부적으로
예시 코드
public class BlockingQueueExample {
private static final int NUM_PRODUCERS = 10;
private static final int NUM_CONSUMERS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(NUM_PRODUCERS * NUM_ENTRIES);
// 프로듀서 스레드 배열
Thread[] producerThreads = new Thread[NUM_PRODUCERS];
// 컨슈머 스레드 배열
Thread[] consumerThreads = new Thread[NUM_CONSUMERS];
// 프로듀서 스레드를 생성하여 BlockingQueue에 데이터를 삽입
for (int i = 0; i < NUM_PRODUCERS; i++) {
final int threadIndex = i;
producerThreads[i] = new Thread(() -> {
try {
for (int j = 0; j < NUM_ENTRIES; j++) {
String item = "Producer-" + threadIndex + "-" + j;
queue.put(item);
System.out.println("Produced: " + item);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 컨슈머 스레드를 생성하여 BlockingQueue에서 데이터를 소비
for (int i = 0; i < NUM_CONSUMERS; i++) {
consumerThreads[i] = new Thread(() -> {
try {
while (true) {
String item = queue.take();
System.out.println("Consumed: " + item);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
// 모든 프로듀서 스레드 시작
for (Thread thread : producerThreads) {
thread.start();
}
// 모든 컨슈머 스레드 시작
for (Thread thread : consumerThreads) {
thread.start();
}
// 모든 프로듀서 스레드가 작업을 마칠 때까지 대기
for (Thread thread : producerThreads) {
thread.join();
}
// 모든 컨슈머 스레드를 인터럽트하여 종료
for (Thread thread : consumerThreads) {
thread.interrupt();
}
System.out.println("All producers have finished producing. Consumers have been interrupted.");
}
}
================================================================
Consumed: Producer-7-933
Consumed: Producer-7-928
Produced: Producer-0-923
Consumed: Producer-0-924
Consumed: Producer-0-923
Produced: Producer-0-924
Consumed: Producer-0-925
Produced: Producer-0-925
All producers have finished producing. Consumers have been interrupted.8-6. ConcurrentLinkedQueue
비차단(non-blocking) FIFO(First-In-First-Out) 큐로, LinkedList를 기반으로 구현되었다.
주요 특징
- 논블로킹 큐:
- 락을 사용하지 않고 동시성을 처리한다.
- FIFO 순서:
- 삽입된 순서대로 항목을 처리한다.
예시 코드
import java.util.concurrent.ConcurrentLinkedQueue;
public class ConcurrentLinkedQueueExample {
private static final int NUM_PRODUCERS = 10;
private static final int NUM_CONSUMERS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
// 프로듀서 스레드 배열
Thread[] producerThreads = new Thread[NUM_PRODUCERS];
// 컨슈머 스레드 배열
Thread[] consumerThreads = new Thread[NUM_CONSUMERS];
// 프로듀서 스레드를 생성하여 ConcurrentLinkedQueue에 데이터를 삽입
for (int i = 0; i < NUM_PRODUCERS; i++) {
final int threadIndex = i;
producerThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
String item = "Producer-" + threadIndex + "-" + j;
queue.offer(item);
System.out.println("Produced: " + item);
}
});
}
// 컨슈머 스레드를 생성하여 ConcurrentLinkedQueue에서 데이터를 소비
for (int i = 0; i < NUM_CONSUMERS; i++) {
consumerThreads[i] = new Thread(() -> {
while (true) {
String item = queue.poll();
if (item != null) {
System.out.println("Consumed: " + item);
} else {
// 큐가 비어있으면 잠시 대기
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
});
}
// 모든 프로듀서 스레드 시작
for (Thread thread : producerThreads) {
thread.start();
}
// 모든 컨슈머 스레드 시작
for (Thread thread : consumerThreads) {
thread.start();
}
// 모든 프로듀서 스레드가 작업을 마칠 때까지 대기
for (Thread thread : producerThreads) {
thread.join();
}
// 잠시 대기하여 컨슈머가 남은 아이템을 소비하도록 함
Thread.sleep(1000);
// 모든 컨슈머 스레드를 인터럽트하여 종료
for (Thread thread : consumerThreads) {
thread.interrupt();
}
// 모든 컨슈머 스레드가 종료될 때까지 대기
for (Thread thread : consumerThreads) {
thread.join();
}
System.out.println("All producers have finished producing. All consumers have finished consuming.");
}
}
============================================================
Consumed: Producer-9-998
Consumed: Producer-9-999
All producers have finished producing. All consumers have finished consuming.8-7. ConcurrentLinkedDeque
비차단(non-blocking) 양방향 큐(Deque)로, 큐의 양쪽 끝에서 삽입과 삭제가 가능하며 LinkedList를 기반으로 구현되었다.
주요 특징
- 비차단 양방향 큐:
- 락을 사용하지 않고 동시성을 처리한다.
- 양쪽 끝에서 삽입/삭제 가능:
- 큐의 양쪽 끝에서 데이터를 삽입하거나 삭제할 수 있습다.
사용 예제
public class ConcurrentLinkedDequeExample {
private static final int NUM_PRODUCERS = 10;
private static final int NUM_CONSUMERS = 10;
private static final int NUM_ENTRIES = 1000;
public static void main(String[] args) throws InterruptedException {
ConcurrentLinkedDeque<String> deque = new ConcurrentLinkedDeque<>();
// 프로듀서 스레드 배열
Thread[] producerThreads = new Thread[NUM_PRODUCERS];
// 컨슈머 스레드 배열
Thread[] consumerThreads = new Thread[NUM_CONSUMERS];
// 프로듀서 스레드를 생성하여 ConcurrentLinkedDeque에 데이터를 삽입
for (int i = 0; i < NUM_PRODUCERS; i++) {
final int threadIndex = i;
producerThreads[i] = new Thread(() -> {
for (int j = 0; j < NUM_ENTRIES; j++) {
String item = "Producer-" + threadIndex + "-" + j;
deque.addFirst(item); // 덱의 앞에 삽입
System.out.println("Produced: " + item);
}
});
}
// 컨슈머 스레드를 생성하여 ConcurrentLinkedDeque에서 데이터를 소비
for (int i = 0; i < NUM_CONSUMERS; i++) {
consumerThreads[i] = new Thread(() -> {
while (true) {
String item = deque.pollLast(); // 덱의 뒤에서 소비
if (item != null) {
System.out.println("Consumed: " + item);
} else {
// 덱이 비어있으면 잠시 대기
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
});
}
// 모든 프로듀서 스레드 시작
for (Thread thread : producerThreads) {
thread.start();
}
// 모든 컨슈머 스레드 시작
for (Thread thread : consumerThreads) {
thread.start();
}
// 모든 프로듀서 스레드가 작업을 마칠 때까지 대기
for (Thread thread : producerThreads) {
thread.join();
}
// 잠시 대기하여 컨슈머가 남은 아이템을 소비하도록 함
Thread.sleep(1000);
// 모든 컨슈머 스레드를 인터럽트하여 종료
for (Thread thread : consumerThreads) {
thread.interrupt();
}
// 모든 컨슈머 스레드가 종료될 때까지 대기
for (Thread thread : consumerThreads) {
thread.join();
}
System.out.println("All producers have finished producing. All consumers have finished consuming.");
}
}
===============================================================
Consumed: Producer-5-844
Consumed: Producer-5-809
Consumed: Producer-5-800
All producers have finished producing. All consumers have finished consuming.9. 마무리
컬렉션을 사용할 때 동시성을 지원하는지도 확인해야 하지만, 평소에 간과하고 있던 컬렉션 크기의 확장/축소 여부에 대해서도 알게 되었다. 크기가 커지기는 했지만, 필요시 다시 축소되지 않는다면 조금 더 고려해봐야 할 것 같다.
