복습하기 위해 작성한 글 주의 (읽기 힘듦)
0. 자료구조를 배워야 하는 이유
자료구조란 일련의 동일한 타입의 데이터를 정돈하여 저장한 구성체이다. 데이터를 정돈하는 목적이 무엇일까? 프로그래밍의 가장 중요한 작업 중 하나는 '데이터'를 다루는 것이다. 프로그래밍은 저장되어 있는 데이터를 다루어(탐색, 삽입, 삭제 등의 연산) 유의미한 정보를 생산해낼 수 있다.
이처럼 자료구조에서는 프로그래밍에서 가장 중요시되는 연산을 효율적으로 수행하기 위해 데이터를 정돈하는 여러 가지 방법을 배운다. 데이터의 구조를 효율적으로 설계하는 것은 데이터 관련 작업의 효율을 극대화시켜줄 것이니까. 따라서 자료구조를 배울 때 다양한 것들을 배우게 되는데, 아래 순으로 공부할 것이다.
배울 것
- 리스트
- 스택과 큐
- 트리
- 테이블
- 우선순위 큐
- 그래프
- 고급 탐색 트리
- 그 외 (빅오 분석, 정렬 알고리즘)
배워야할 것들이 상당히 많다. 이처럼 많은 자료구조를 배우는 이유를 지금 필자가 설명할 건데, 이는 우리가 자료구조를 어떻게 공부해야 하는지와 상당히 관련되어 있다. 다시 말하자면 자료구조란 데이터를 정돈한 구성체이다. 이처럼 다양한 자료구조가 있는 이유는 데이터를 정돈하는 목적이 다양하기 때문이다. 우리가 가장 애용하는 배열의 장점을 하나 말해보겠다.
왜 배우죠
배열의 장점
배열은 배열 인덱스를 이용하여 특정 위치의 원소에 빠르게 접근할 수 있다.
'특정 위치의 원소에 빠르게 접근해야 하는 프로그램'에서 배열을 사용하면 되겠다.
자 그럼, 배열의 단점을 하나 말해보겠다.
배열의 단점
배열은 원소들이 연속적인 메모리 공간에 할당되어 있으므로 배열의 중간 위치에 원소가 하나 삽입되거나 삭제되면 뒤따르는 모든 원소들을 한 칸씩 뒤로 또는 앞으로 이동시켜야 한다.
쉽게 설명해보겠다. '1억1'짜리 길이의 배열에 1억개의 원소가 꽉 차있다고 생각해보자. 자그마치 1억개의 원소다. 이 상황에서, 갑자기 가장 첫 원소를 삭제해야 하는 상황이 발생했다. 이 때 원소 하나를 삭제하면, 뒤따르는 9999만9999개의 원소를 앞당겨주는 이동 연산을 해야 한다. 매우 비효율적이다. 세상에 자료구조가 배열 하나 밖에 없다면 데이터 삽입/삭제가 많은 프로그램에도 울며겨자먹기로 배열을 써야 한다. 그렇다면 이 상황에서 이 질문이 나올 것이다.
'배열 말고 다른 건 없어요?'
데이터 삽입/삭제 연산 시 효율적인 다른 자료구조 달라구요!
당연히 있다! 여기서 우리는 왜 다양한 종류의 자료구조를 배워야 하는지 알 수 있다. 각각의 프로그램은 저마다 다른 데이터 작업들을 수행하기에, 저마다 적용했을 때 효율적인 자료구조가 각각 다르다. 우리는 모두 효율적이고 쾌적한 프로그램을 만드는 개발자가 되고 싶지 않은가?
그렇다면
1. 다양한 종류의 자료구조가 각각 왜 존재하는지(장단점)을 알아두고
2. 상황마다 효율적인 자료구조를 선택할 줄 알아야 한다.그러니 각 자료구조의 존재 이유와 장단점에 초점을 두고 공부하자!
만일 배열의 특성을 몰랐다면 어떻게 됐을까? 위의 안 좋은 상황(배열)처럼, 비효율적인 프로그램을 만들 가능성이 높아진다. 이러한 이유로 비전공자와 전공자의 차이가 있다고 하는 것이다. 하지만 요즘은 하드웨어 성능이 워낙 좋아지면서 효율의 가치가 저평가 되고 있다. 하지만 자료구조를 아는 개발자와 그렇지 않은 개발자가 같은 프로그램을 만들었을 때, 어떤 프로그램이 더 쾌적한 환경을 제공할지는 쉽게 알 수 있을 것이다.
1. 빅오 표기법
각 자료구조들을 살펴보기 전에 빅오 분석이라는 개념을 공부해야 한다. 자, 자료구조는 데이터를 저장 및 정돈하는 구성체라고 했다. 프로그래밍 중 자료구조를 사용해야 할 때가 왔다고 가정해보자. 배열과 리스트 두 가지 자료구조를 비교해서 하나를 선택하려고 하는데, 이 두 가지 자료구조 중 특정 원소 삭제 연산은 누가 더 빠를까? 이 때 우리는 빅오분석을 사용한다. 빅오분석은 특정 코드 실행의 효율성을 따지기 위해 가장 흔하게 사용되는 정량적 평가 기준이다. 즉 코드 성능평가의 지표로 가장 쉽게, 또 흔하게 사용되는 평가 기준이라고 보면 되겠다.
빅오(Big-Oh) 분석 : 시간복잡도 계산
빅오 분석 : 특정 코드 실행의 효율성을 따지기 위해 가장 흔하게 사용되는 정량적 평가 기준
그럼 빅오 분석은 어떤 구체적 기준을 사용하여 코드의 효율성을 따질까? 바로 시간 복잡도라는 것을 따진다. 시간복잡도는 프로그램을 실행시켜 완료하는데 소요되는 총 시간의 추산량이다. 똑같은 작업을 할 때 이 추산량(시간복잡도)가 적은 쪽이 더 효율적이라고 할 수 있겠다. 이 시간복잡도는 기본적인 연산의 횟수를 입력 크기의 함수로 표현한다. 이 기본 연산은 탐색, 삽입, 삭제와 같은 연산이 아닌 데이터 간 크기 비교, 데이터 읽기 및 갱신, 숫자 계산 등과 같은 단순한 연산을 의미한다.
시간복잡도 : 프로그램을 실행시켜 완료하는데 소요되는 총 시간의 추산량, 기본 연산의 횟수를 입력 크기의 함수로 표현한다.
기본 연산 : 탐색, 삽입, 삭제와 같은 연산이 아닌 데이터 간 크기 비교, 데이터 읽기 및 갱신, 숫자 계산 등과 같은 단순한 연산
설명이 어려운데 쉽게 설명해보겠다. 필자는 빅오분석을 설명하기 위해, 기본 연산 중 하나인 데이터 갱신을 하는 프로그램을 만들고 있다고 생각해보자. 초기에 0으로 초기화한 변수 num의 값을 1로 바꾸는 프로그램을 작성할 것이다. 시간 복잡도는 기본 연산의 횟수를 기준으로 사용한다고 했던 것을 기억하고 아래를 보자.
<program 1>
int num = 0; //-> 기본 연산(데이터 갱신) 1회 발생
num = 1; //-> 기본 연산(데이터 갱신) 1회 발생
데이터 갱신 두번 발생 -> 빅오분석 결과(함수로 표현) : O(2)<program 2>
int num = 0; //-> 기본 연산(데이터 갱신) 1회 발생
for(int i = 0; i < N; i++){
num = 1;
} //-> 기본 연산(데이터 갱신) N회 발생
데이터 갱신 (N + 1) 번 발생 -> 빅오분석 결과(함수로 표현) : O(N + 1)<program 3>
int num = 0; //-> 기본 연산(데이터 갱신) 1회 발생
for(int i = 0; i < N; i++){
for(int j = 0; j < N; j++){
num = 1;
}
} //-> 기본 연산(데이터 갱신) N^2회 발생
데이터 갱신 (N^2 + 1) 번 발생 -> 빅오분석 결과(함수로 표현) : O(N^2 + 1)프로그램 2, 3의 코드가 너무 비효율적인데요.
라는 말이 나왔다면 이미 빅오 분석을 이해할 준비가 끝난 것이다. 프로그램의 비효율성은 뒤로 미뤄두고, 각 프로그램의 기본 연산의 횟수에 집중해보자. 빅오분석 결과가 순서대로 O(2), O(N+1), O(N^2+1)가 나왔다. 우리는 이 빅오 분석 결과값을 통해 프로그램 1, 2, 3의 효율성을 판단할 수 있게 됐다. 프로그램의 결과가 모두 같기 때문이다. 세 프로그램 모두 목적(변수 num에 1 할당)을 달성한 것은 같지만, 기본 연산(데이터 갱신)은 각각 2번, (N+1)번, (N^2+1)번 발생했기 때문에 프로그램 1이 가장 효율적인 프로그램이라고 객관적으로 말할 수 있게 된 것이다.
누군가 나에게 위 프로그램 1, 2, 3의 효율성에 대해 질문했다.
1. 빅오 분석법을 안다면
A : '빅오 분석을 해보니 프로그램 1이 O(2)의 시간 복잡도로 가장 효율적이네요.'
2. 빅오 분석법을 모른다면
A : '음.. 딱 봐도 <프로그램 1>이 가장 효율적이네요.'어떤 답변이 더 객관적인 평가인가?
수행 시간의 점근표기법
앞서 빅오 분석을 위해 시간복잡도를 계산해봤다. 하지만 실제 빅오 분석은 결과값을 점근적으로 표기하여 '빅오 표기법'이라는 표기법으로 사용한다. 쉽다. 프로그램 2의 빅오 분석(시간 복잡도)값이 O(N+1)이었는데, 이를 점근적으로 O(N)으로 간단하게 표현한다는 것이다. 좀 더 다양한 예시를 보면 아래와 같다.
빅오 표기법(시간복잡도의 점근표기법)
| 특정 코드의 시간복잡도 | 빅오 표기(시간 복잡도의 점근 표기법) | |
|---|---|---|
| O(N+1) | -> | O(N) |
| O(3N^3+2) | -> | O(N^3) |
| O(3N^4+2N^2+12N+124) | -> | O(N^4) |
이런 식으로 말이다. 아니 그렇다면 시간 복잡도가 O(1000000N^3)인 코드와 O(N^3)인 코드의 시간 복잡도 값을 같다고 표시하는 건가? 그렇다. 물론 두 번째 코드의 실제 시간 복잡도가 훨씬 적을 것이다. 하지만 이렇게 표기할 수 있는 이유가 있다. 아래는 각 시간복잡도에 따른 수행 시간 그래프이다. 실제 수행 시간에 영향을 주는 것은 차수이지, 계수가 아니기 때문이다.
즉 O(1000000N)과 O(N)의 수행 시간 차이는
O(NlogN)과 O(N)의 수행 시간 차이에 비하면 "한없이 작기" 때문에
둘 다 점근적으로 O(N)이라는 값으로 표현하는 것이다.
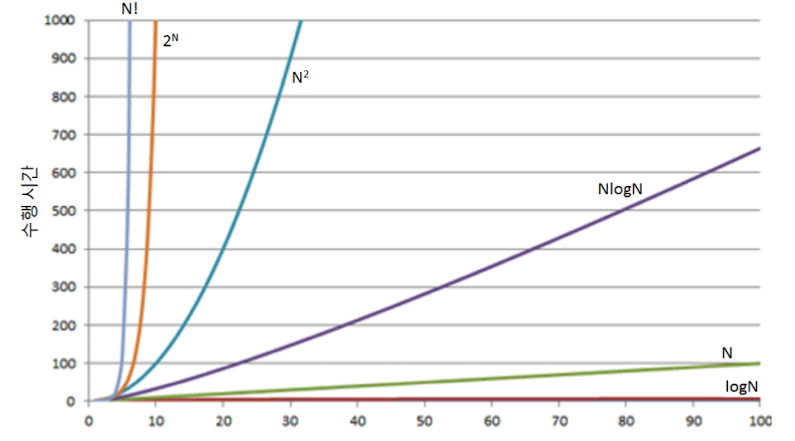
O(빅오)표기법을 사용하는 이유
O(빅오)표기법 뿐 아니라 Ω(빅오메가)표기법도 존재한다. 둘의 차이는
- O(빅오)표기 : 최악의 시간복잡도를 계산하여 표기한다.
- Ω(빅오메가)표기 : 최선의 시간복잡도를 계산하여 표기한다.
그러니까, 어떤 코드의 시간복잡도가 최악의 경우 O(N^2)이고, 최선의 경우 O(N)이라고 가정해보자. 아니 그렇다면 제일 빠른 케이스를 나타내는 Ω(빅오메가)표기법을 사용하면 되는거 아닌가? 절대 그렇지 않다. 프로그래머는 빅오 분석을 사용해야 하는 이유가 있는데, 그것은.
프로그래머는 최악의 경우를 최우선적으로 생각한다.
개발자는 if-else의 직업이라 해도 과언이 아니다. 어떤 코드가 100번 중에 99번 성공적으로 실행되고, 1번 실패한다고 생각해보자. 당신이 개발자라면 이 코드를 그냥 두겠는가? 개발자라는 직군은, 최악의 경우를 항상 생각해야 한다. 따라서 빅오메가 표기법으로 효율적인 시간복잡도가 나와도, 빅오 표기법으로 매우 비효율적인 코드가 나온다면 그것은 효율적인 코드가 아닐 가능성이 높다. 따라서 빅오 표기법을 중점으로 시간복잡도를 계산하고, 코드의 효율성을 계산하는 것이다.
본격적으로
각 자료구조들을 배워 보기에 앞서, 필자가 자료구조 공부한 핵심적 포인트를 글에도 똑같이 적용시킬 예정이다. 해당 자료구조를 사용하는 이유를 최우선적으로 알면 된다. 이유를 알면, 장단점도 추론이 가능하다. 또한 학부 수업에선 각 자료구조의 구현 사항도 배우지만, 복습 목적의 글에서 너무 구현사항까지 나오기엔 너무 복잡해질 것 같다. 아무튼 왜 이 자료구조가 등장했는지에 대해 중점적으로 글을 풀어나갈 생각이다.
2. 리스트
목차
(0) 배열
(1) 리스트
(2) 배열리스트
(3) 연결리스트
(4) 이중연결리스트
(5) 원형리스트
(0) 배열
배열은 동일한 타입의 원소들이 연속적인 메모리 공간에 할당되어 각 항목이 하나의 원소에 저장되는 기본적인 자료구조이다.
프로그래밍에 조금이라도 익숙해졌다면 배열의 존재를 알고 있을 것이다. 리스트에 들어가기 앞서, 우리는 배열의 특징을 몇 가지 알고 넘어가야 한다. 뒤의 내용과 이어진다.
왜 사용할까.
프로그래밍에서 가장 기본적인 형태의 자료구조이다.
1. Random Access
배열은 연속적인 메모리 공간에 할당되어 있기 때문에, 특정 위치의 원소에 접근할 때는 배열 인덱스를 이용하여 O(1) 시간에 접근할 수 있다. 차근차근 이해해보자. O(1)은 앞서 배웠던 빅오 표기법이다. 100짜리 길이의 arr 배열이 있다고 하자. 그리고 중간에 있을 55번째 원소의 값이 무엇인지 알고 싶다면 '데이터 접근'을 해야 하는데 이 때 우리는 어떻게 하는가? arr[54]를 사용하여 값을 받아왔지 않은가. 이 과정에 대한 얘기다. arr[54]에 접근하기 위해 0, 1, 2, ... , 53의 인덱스 값을 탐색하지 않아도 된다는 것이다. 연속적인 메모리 공간에 할당되어 있기 때문에, O(1), 즉 단 한 번의 기본 연산으로 arr[0]에 접근할 수 있다. 이는 배열의 가장 큰 장점이 된다. Random Access를 통한 빠른 데이터 접근으로 이해하자.
2. Java의 배열, 그리고 C의 배열
이건 메모리에 관한 이야기이고, 배열이 어떤 방법으로 구현되고 사용되는지에 대해 이해도가 올라갈 수 있을 것 같아 추가한 내용이다. Java로 arr이라는 배열을 초기화해보자. 그리고 배열을 인자로 넘기는 함수가 하나 있다고 해보자. 그렇다면 우리는 인자가배열인함수(arr) 방식으로 함수를 사용하지 않는가. 이 과정에서 과연 arr 배열 하나가 통째로 넘어가는 것일까? 결과적으론 그렇지 않다. 실제로는 arr[0]의 주솟값이 넘어가는 것이다. 왜냐하면 java에서 생성한 배열 arr은, arr이라는 변수 그자체는, 'arr의 첫 번째 원소의 레퍼런스'를 저장하고 있기 때문이다. 그렇다면 C언어로 넘어와서, 똑같은 함수를 작성한다고 해보자. 인자로 들어갈 arr의 타입을 int[]라는 식으로 설정하는 것이 가능할까? 불가능하다. 앞에서 실제론 배열 첫 번째 원소의 주솟값이 넘어간다고 했었다. 이처럼 C언어에서 배열을 인자로 넘기고 싶다면, arr[0]의 주솟값을 넘겨야 한다. 따라서 넘기고 싶은 배열 인자의 타입은 int[]가 아닌 *int가 되어야 한다. 포인터를 사용해서 말이다. 그리고 넘어간 배열 첫번째 원소 주솟값으로 arr을 인자로 넘겼다고 하자. 그리고 함수 내에서 arr[5]을 사용하게되면, arr[0]에서 5번 째 칸 뒤의 원소에 접근할 수 있게 되는 것이다.
3. Shift 연산
앞에서 배열은 연속적인 메모리 공간에 할당되어 있는 자료구조라서 데이터 접근 연산이 빠르다고 했다. 하지만, 데이터 삽입, 삭제 연산에서 불리하다. 왜 일까? 연속적인 메모리 공간에 할당이라는 배열의 장점 때문이다. 장점이 단점이기도 하다. 먼저 데이터 삽입의 경우를 생각해보자. 어떤 배열의 5번째 인덱스에 값을 할당하고 싶다. 그렇다면 기존의 5번째 인덱스 값은 덮어씌워 지면 안 된다. 그렇기에 6번째 인덱스부터 마지막 인덱스까지의 원소를 한 칸씩 뒤로 밀어주는 연산이 필요하다. 이를 한 칸씩 밀어주는, shift 연산이라고 한다. 삭제의 경우도 같다. 연속적으로 할당되어 있는 배열에서 7번째 인덱스 값을 삭제했다. 삭제까지는 괜찮다. 하지만 삽입 연산의 경우처럼, 8번째 인덱스부터 마지막 인덱스의 원소들을 모두 앞으로 당겨줘야 한다. 해당 연산도 한 칸씩 밀어주는, 이 또한 shift 연산이라고 한다. 이처럼 배열은 데이터 접근 연산 면에서 O(1)이라는 우월한 시간복잡도를 자랑하지만, 데이터 삽입이나 삭제 연산 시 O(N)이라는 비효율적인 시간복잡도 또한 자랑하고 있는 것이다. 그리고 당연히, shift라는 비효율적인 연산을 해결하는 자료구조가 나올 것이다. 곧.
4. overflow
배열은 메모리에 연속적인 공간을 할당한다고 했다. 만약에 내가 처음에 10짜리 공간의 arr 배열을 할당받았다. 그리고 배열을 사용하다보니 배열 공간이 부족해졌다. 길이가 10이므로 arr[9]까지 접근이 가능한데, 만약 공간이 더 필요하다고 해서 arr[10]에 값을 새로 할당했다고 하자. 음 잘됐다. 근데 만약, arr[9]의 바로 다음 인덱스(메모리 공간)에 다른 변수의 값이 저장되어 있었다면? 그리고 그것이 프로그램 실행에 있어 가장 중요한 변수였다면? 상상만 해도 끔찍하다. 따라서 배열의 범위를 벗어난 배열의 인덱스 주소에 접근하면 exception, 에러를 띄우는 것이다. 이처럼 더 이상 빈 자리가 없어 새 항목을 삽입할 수 없는 상황을 overflow라고 한다. overflow를 해결하기 위한 방법으로, overflow가 발생하면 기존 배열 두 배 길이의 새로운 배열을 만들어, 그 배열로 값을 복사한다. 이사하는 것이다. 이를 resize 연산이라 한다. 하지만, 만약 원소의 갯수가 50만개라고 해보자. overflow가 발생하면 50만 개의 데이터가 이동해야 한다. 따라서 초기에 배열의 사이즈를 잘 잡는 것이 중요하다. 하지만 미래는 알 수 없다. 따라서 이러한 배열의 특징도, 다른 자료구조에서 해결해 줄 것이라는 생각이 든다.
5. 배열 왜이렇게 길게 얘기해요? 설명도 잘 못하면서
배열에 대한 얘기가 길어지고 있다. 그도 어쩔 수 없는 것이, 배열이 가장 기본적인 자료구조기 때문이다. 기본적인 자료구조의 문제점들을 해결하고, 또 해결하고, 해결해 나가면서 여러 가지 자료구조들이 생겨난 것이기 때문이다. 따라서 배열의 특징들을 잘 알아 놓는 것이 앞으로 설명할 자료구조의 존재 이유를 이해하는데 많은 도움이 된다.
배열
- 연속된 메모리 공간에 할당
- Random Access. O(1)의 시간으로 특정 인덱스 원소에 접근 가능
- 중간 데이터 삽입, 삭제 시 shift 연산 필요
- 배열의 길이를 넘어서 값을 추가하려면 overflow 발생
(1) 리스트란?
일련의 동일한 타입의 항목(item)들이다. 항목들을 일렬로 세워둔 형태의 자료구조로 이해하자. 배열로 리스트를 구현하면 ArrayList, Node로 리스트를 구현하면 LinkedList라고 한다. 하지만 LinkedList는 메모리의 연속된 공간에 할당되지 않는 자료구조이다. 즉, 리스트는 일렬로 원소들이 존재하는 형태만 가질 뿐이지, 원소들이 메모리 공간에서 연속적으로 존재하는 자료구조를 지칭하는 것이 아닐 뿐이다. 음 그리고 연산에 대한 얘기를 해보자. Java로 예를 들면 자료구조는 클래스로 구현이 된다. 그리고 클래스에는 필드와 메서드가 있다. 각 자료구조 클래스도 동일하다. 해당 자료구조를 구현하는데 있어 필요한 필드와, 각 데이터 연산에 해당하는 작업을 메서드로 미리 구현해놓고 간편하게 사용할 수 있다. 따라서 각 자료구조 클래스의 필드와 메서드를 알고 있으면 어떤 자료구조인지 이해하기 쉬워진다.
(2) 배열리스트
1. 등장 이유
가장 기본적인 자료구조인 배열을 리스트로써 사용하기 위해 사용된다.
2. 무엇인가
말 그대로 배열로 구현한 리스트이다. 배열과 동작하는 방식은 거의 같지만, 필드, 메서드를 가지고 배열을 좀 더 편리하게 사용할 수 있다. Java에선 ArrayList<>()의 생성자로 사용 가능하다.
3. 멤버
-
필드
E arr[]
int size -
메서드
생성자
E peek(int k)
void insertLast(E newItem)
void insert(E newItem, int k)
void resize(int newSize)
E delete(int k)
4. 특징
peek(int K)의 경우 특정 인덱스의 데이터에 접근하는 메서드이다. 연속된 메모리 공간에 할당돼있는 배열로 구현되어 있기 때문에, 해당 연산의 시간복잡도는 O(1)에 달한다. 하지만 배열의 중간에 항목 추가 및 항목 삭제가 발생 시, shift 연산이 필요하게 되어 시간복잡도는 O(N)이다. 음 그런데, arrayList.delete(arr.length()-2)를 하면 shift 연산이 1번밖에 발생하지 않는다. 근데 왜 시간복잡도는 O(N)일까? 빅오표기법은 최악의 시간복잡도를 계산한다. 따라서 배열리스트의 첫 원소를 삭제했을 때가 최악의 경우임을 알 수 있다. 일단 배열리스트에서 우리가 발견한 단점은, 중간 위치에 데이터 삽입/삭제 시 O(N)의 시간이 소요됨을 알고 넘어 가자.
(3) 단일연결리스트
1. 등장 이유
배열과 배열로 구현된 배열리스트의 단점을 떠올려보자. 중간 데이터 삽입/삭제 시 O(N) shift 연산 필요, overflow 발생 시 O(N)의 resize 연산 필요의 단점이 존재했다. 리스트는 이를 해결하기 위한 자료구조이다.
2. 무엇인가
연속된 메모리 공간에 할당된 메모리가 아니다. 동적 메모리 공간(Heap)을 사용하는 리스트이며, 노드라는 단위로 구성이 되어있다. 배열의 경우 하나의 항목엔 데이터만 들어있고, 각각이 인덱스라는 순서로 표현이 되어 있다. 하지만 연결리스트는 노드에 데이터와 다음 노드의 주솟값을 저장한다. 체인의 형태로 봐도 될 것 같다. 연속된 공간이 아니라는 것은, shift 연산이나 resize 연산이 필요없어짐을 의미한다. 중간 위치에 데이터를 삭제한다고 하면, 해당 데이터를 삭제하고 바로 이전 노드의 다음 노드 주솟값을 삭제된 노드의 다음 노드의 주솟값으로 설정해주는 O(1)의 연산을 수행하면 되기 때문이다.
3. 멤버
-
노드의 필드
E element
E Node<E> next -
노드의 메서드
생성자
element와 next에 대한 getter, setter -
연결리스트의 필드
Node<E> head
Node<E> tail
int size -
연결 리스트의 메서드
생성자
int size()
boolean isEmpty()
E first()
E last()
void addFirst(E e)
void addLast(E e)
void addAfter(E newElement, Node<E> prevNode)
E removeFirst()
E deleteAfter(Node<E> prevNode)
4. 특징
deleteAfter(Node<E> prevNode>) 메서드의 구현 사항을 살펴보자.
public void deleteAfter(Node<E> prevNode){
//prevNode : 삭제하고자하는 노드의 바로 이전 노드
if(prevNode == null) return;
Node tmp = prevNode.getNext(); //1
prevNode.setNext(tmp.getNext()); //2
tmp.setNext(null); //3
size--;
}해당 연산을 살펴보게되면 삭제 노드(prevNode 다음 노드)의 다음 노드 주소를 prevNode의 다음 주소로 설정하고, 삭제 노드의 다음 노드 주소값을 null로 설정한다. 그렇다면 삭제 노드는 더 이상 참조를 하지도, 참조를 받지도 않기 때문에 JVM의 GC에 의해 자동으로 정리되게 된다. 하지만 만약, 마지막 노드를 삭제했다고 생각해보자. 마지막 노드는 tail이라는 필드로 참조되어 있다. 하지만 마지막 노드를 삭제하기 위해 필요한 끝에서 두 번째 노드를 가져오려면 해당 연결리스트의 첫 번째 노드로부터 탐색을 해와야하는 O(N)의 연산이 발생하게 된다. 이것이 연결리스트의 단점이다. 중간 위치의 데이터 삽입/삭제 연산은 O(1)로 가능하지만 데이터 탐색이 O(N)의 시간이 소요되는. 이렇기에 배열리스트와 연결리스트는 상반되는 특징을 가지고 있다고 보면된다. 연결리스트는 인덱스로 특정 위치를 바로 찝어낼 수 없기 때문에, 데이터 탐색 시간은 O(N)이다. 하지만 연결리스트의 후반부에 위치한 노드를 삭제할 때 발생하는 비효율은 개선할 수가 있다. 바로 이중연결리스트로 말이다.
(4) 이중연결리스트
1. 등장 이유
이중연결리스트는 단일연결리스트의 후반 데이터 탐색의 비효율성을 개선한 자료구조이다. 기존 단일연결리스트에서 변수 tail은 가장 마지막 노드를 참조하고 있지만, 마지막에 근접하는 노드들에 접근하기 위해선 O(N)의 시간에 육박하는 데이터 탐색 연산을 수행해야 한다. 왜냐하면 단일연결리스트의 노드는 다음 노드 주솟값만 참조하고 있기 때문이다.
2. 무엇인가
그렇다면 이중연결리스트는 말 그대로 노드가 이중으로 이전과 다음 노드를 모두 참조하고 있는 연결리스트이다. 단일연결리스트는 다음 노드만 참조하지만, 이중연결리스트는 이전의 노드도 참조하기 때문에, 후반부에 위치한 노드를 탐색할 시엔 tail로 부터 이전 노드들을 참조하면서 탐색하면, O(N)의 시간에 육박하진 않게 된다. 물론 노드에 하나의 필드가 추가되면서 메모리 공간을 더 사용하지만, 단일연결리스트 대신 이중연결리스트를 사용했을 때 더 효율적인 상황은 존재하기 마련이다.
3. 멤버
단일연결리스트와 유사한 필드와 메서드를 가진다. 다만 사용하는 노드에 이전 노드의 주솟값 prevNode 필드를 가지는 것이 가장 큰 차이이다.
4. 특징
단일연결리스트와 유사하지만, 후반부에 위치한 노드를 탐색할 때 더 효율적인 연산이 가능하단 것이 가장 큰 특징이다.
(5) 원형리스트
1. 등장 이유
마지막 노드를 하고 첫 노드를 다음 노드로 방문해야 할 때, 바로 방문할 수 없을까? 라는 아이디어로 시작됐다. 따라서 마지막 노드가 head를 참조하고 있는 형태이다.
2. 무엇인가
마지막 노드가 첫 노드와 연결된 단순연결리스트이다. tail이라는 필드는 필요없어지고, 마지막 노드는 head가 참조하는 노드를 참조하고 있다.
3. 특징
많은 사용자들이 동시에 사용하는 컴퓨터에서 CPU 시간을 분할하여 작업을 할당하는 운영체제에 사용된다고 한다. 리스트가 empty가 아니면 어떤 노드도 null 레퍼런스를 가지고 있지않으므로 null 조건을 검사하지 않아도 된다. 하지만 반대로 무한루프가 발생할 수 있기 때문에 유의해야 하기도 한다.
스택과 큐
목차
0. 스택과 큐의 등장 이유
1. 스택(배열 구현, 링크드리스트 구현)
2. 큐(원형 배열 구현, 링크드리스트 구현)
3. 데크
트리
목차
트리
0. 트리의 등장 이유
1. 트리란
2. 이진 트리
3. 이진 트리의 순회 방식
4. 트리의 높이
5. Union 연산
탐색 트리
0. 탐색 트리란
1. 이진 탐색 트리
2. AVL 트리
3. 2-3 트리
4. 레드블랙 트리
테이블
목차
0. 테이블의 등장 이유
1. 테이블이란
우선순위큐
목차
0. 우선 순위 큐의 등장 이유
1. 이진힙
2. 허프만 코딩
3. 좌편향 힙
4. 양쪽 끝 우선순위 큐
5. 대칭 최소-최대 힙
6. 구간 힙
정렬
목차
0. 정렬을 하는 이유
1. 선택정렬
2. 삽입정렬
3. 힙정렬
4. 합병정렬
5. 퀵정렬
6. 기수정렬
7. 외부정렬
그래프
목차
0. 그래프의 등장 이유
1. 그래프란
2. DFS, BFS
3. 위상정렬
4. 최소 신장 트리(MST)
- kruskal
- Prim
- Sollin
5. 최단경로
- Dijkstra
- Bellman-Ford
- Floyd-Warshall
6. 이중연결성분
7. 강연결성분
