
오늘은 OS만의 CPU를 잘 사용하기 위한 프로세스 배정 방법에 대해 포스팅하겠습니다. 이 말은 즉, CPU 스케줄링이라고 하는데요. 프로세스를 배정할 때, 가능한 많은 일을 가능한 시간내 처리할 수 있게 하는 것이 목표입니다.
실제로 터미널에 ps aux 를 입력해보면 현재 실행중인 프로세스 수를 확인할 수 있습니다. 컴퓨터 내 CPU는 많아봐야 4~8개 정도인데 어떻게 이렇게 많은 프로세스를 관리할까요? 심지어 CPU는 하나의 프로세스만 관리할 수 있습니다.
ps aux | wc -l
# wc는 라인수를 의미합니다.간략하게 설명해드리자면 현대 컴퓨터는 멀티태스킹이 가능하기 때문이죠. 하나의 CPU가 여러개의 프로세스를 관리한다는 게 아니라 동시에 실행되는 것 처럼 관리하는 한다는 것입니다. 그것도 빠른 시간내에 순차적으로요.
그럼, 이 빠른 시간내 순차적으로 프로세스를 실행한다는 건 어떻게 이루어지는 걸까요?
먼저 우리는 프로세스에 대해 자세히 알고 넘어가봅시다.
💡 프로세스, 프로그램, 프로세서
- 프로세스 : 프로그램이 CPU 소유권을 갖고 실행중인 상태
- 프로그램 : 프로그램
- 프로세서 : CPU
📌 프로세스는 누군가요?
프로세스는 컴퓨터에서 실행되는 하나의 프로그램(task, job) 을 말합니다. 프로그램은 실행이 되기 전에 명령어들의 묶음을 말하는데 이들이 실행 중에 있을 때를 프로세스라고 합니다.
💡 멀티 프로세싱과 멀티 태스킹
- 멀티 프로세싱 : 여러 개의 프로세서를 사용하는 것
- 멀티 태스킹 : 같은시간에 여러개의 프로그램을 시분할 방식으로 처리하는 것
이러한 프로그램을 관리하는 녀석을 CPU라고 하는데 이 CPU는 프로세스 A를 관리하다가 프로세스 할당 시간이 종료되면 프로세스 A의 정보를 PCB(프로세스 제어 블록)에 저장하고 문맥 교환(Context Switch)을 통해 다른 프로세스를 실행하게 됩니다.
그렇다면 문맥 전환이라는 건 왜 일어나고 프로세스 제어블록은 무엇일까요?
문맥 교환(Context Switch)
문맥 교환이라는 것은 말그대로 프로세스가 할당 시간이 종료되면 인터럽트가 발생하여 다른 PCB를 불러와 다른 프로세스를 실행하는 것을 말합니다. 다양한 인터럽트를 통해서 문맥 교환이 일어나는데 대기명령을 통해 문맥전환이 일어나는 경우 타임 아웃을 통해 문맥 전환이 일어난 경우가 있습니다.
문맥교환이 발생하면 CPU는 아무것도 하지 못합니다. 왜냐하면 문맥교환이 발생하면서 PCB를 저장하고 다른 프로세스의 PCB를 가져와야하는 시간이 있기 때문입니다. 이 사간을 유휴시간(idle time)이라고 합니다.
이러한 유휴시간 뿐만아니라 주소를 변환으로 인해 비용도 들게됩니다. 만약 메모리 주소를 그대로 가지고 있으면 캐시 메모리 초기화같은 무거운 작업일 때 오버헤드가 발생하는데 스레드를 이용해 문맥 교환 부하를 줄이는 방법을 택해야 합니다.
💡 스레드로 문맥 교환을 줄인다고?
이유는 스레드와 프로세스내 메모리 구조가 다르기 때문입니다. 스레드는 프로세스와 달리 스택 영역을 제외한 모든 메모리를 공유하고 커널모드 전환이 없기 때문에 비용이나 시간이 더 적게 걸리기 때문입니다.

음,,, 약간 학원 선생님(CPU)가 학생들의 교재(PCB)로 학생들(Process)를 관리한다고 생각했어요.. 그리고 학원 선생님에게 시키는 건 학원장(OS)
인터럽트는 언제 발생하는가?
프로세스의 상태 전이를 보게 되면, 입출력 장치를 사용할 필요가 있을 때, 잠깐 프로세스가 중단된 상태가 되며 다음 프로세스가 실행됩니다. 이 경우에 인터럽트가 발생하게 됩니다. 예를 들면, 노트를 작성하지 않다가 갑자기 작성하게 되면 입출력이 발생되는 것이죠. 그리고 입출력이 끝나면 다시 준비 상태로 가게됩니다.
이뿐만 아니라 실행상태에서 일정한 시간이 지나면 다시 준비 상태로 돌아가게 되는데 이때도 인터럽트가 발생됩니다.
프로세스의 상태전이로는 크게 접수, 준비, 대기, 실행, 종료로 이루어져 있습니다.
- 접수 : 프로세스가 생성이 되었지만 아직 메인 메모리에 할당이 되지 않은 상태입니다.
fork()나exec()함수에 의해 프로세스가 생성됩니다. - 준비 : 프로세스가 실제로 메모리에 적재되고 CPU 소유권에 대한 할당을 기다리는 단계입니다.
- 실행 : CPU와 메모리가 할당받고 CPU가 해당 프로세스를 실행하는 상태입니다.
- 대기 : 갑작스런 입출력의 인터럽트로 인해 잠깐 일시정지한 상태입니다.
- 종료 : 프로세스의 실행이 완전이 종료된 상태입니다. 자연스럽게 종료되거나
process.kill로 인해 종료될 수도 있어요.
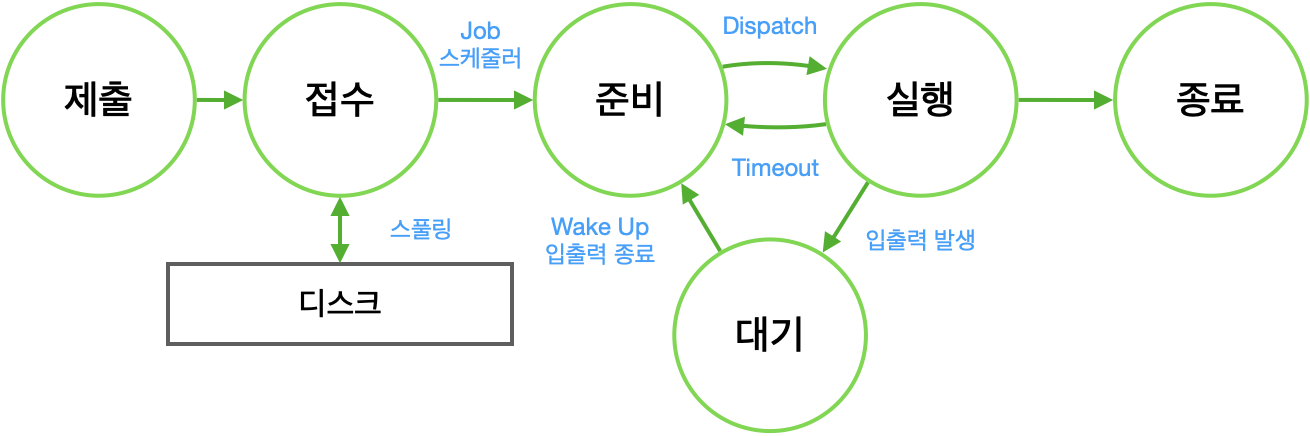
PCB를 저장하고 다시 가져온다고?
네 맞아요. 프로세스 제어블록을 가져오고 프로세스를 실행시키는 구조입니다. 프로세스 제어블록(PCB)는 프로세스에 있는 정보를 담고 있습니다. 프로세스가 CPU 제어권을 받게되면 PCB에 있던 정보를 불러와 다시 프로세스가 실행됩니다.** 그래서 PCB에는 프로세스의 관한 정보가 있고 이전에 나왔던 현재 상태도 나와 있습니다.
- 프로세스 식별자(PID)
- 프로세스 스케줄링 상태
- 프로그램 카운터(PC): 다음 실행 명령어 주소에 대한 포인터
- 프로세스 우선순위, 권한을 비롯한 CPU 레지스터 값, 점유시간, 정보들이 있습니다.
📌 프로세스와 스레드의 차이
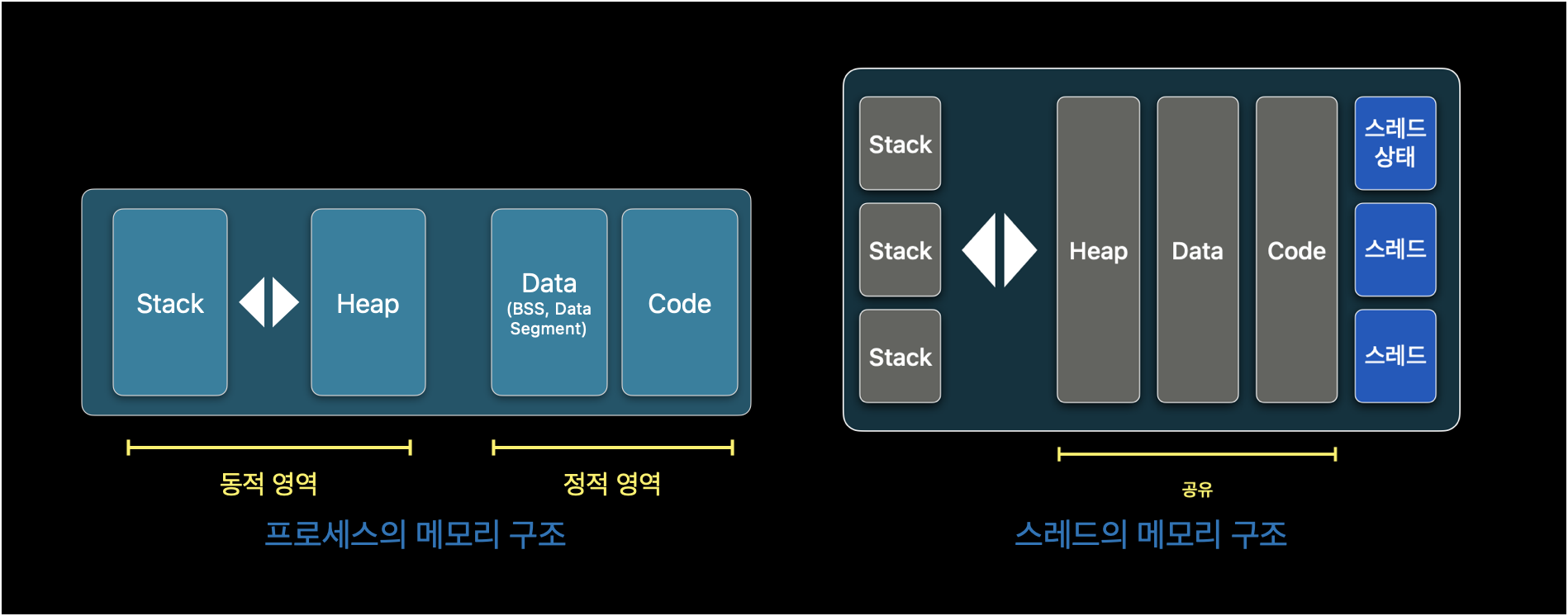
앞서, 문맥교환으로 인해 유휴시간과 캐시미스가 발생한다고 하였습니다. 문맥교환의 부하를 줄이기 위해 스레드를 사용한다고 했습니다. 그렇다면 스레드와 프로세스는 무슨 차이가 있길래 그런걸까요? 프로세스와 스레드의 메모리 구조를 자세히 보면 알 수 있습니다.
프로세스와 스레드의 메모리 구조 차이
프로세스의 메모리 구조를 보면 네가지의 구조로 나타납니다.
- 스택 : 지역 매개 변수나 함수, 리턴값에 의해 메모리가 늘어나거나 줄어드는 임시 메모리 영역
- 힙 : 동적으로 할당된 변수 영데
new(),malloc()) - 데이터 : 컴파일 단계에서 정적으로 메모리를 할당되는 영역(전역변수, 정적변수, 배열 등)
- 코드 : 코드 구성 자체의 메모리 영역
스레드는 프로세스 내에 실행되는 하나의 작업 단위를 의미합니다. 일반적으로 프로세스는 하나 이상의 스레드를 가지고 있고 둘 이상의 스레드를 실행할 수도 있습니다. 스레드는 프로세스가 생성되는 시작부터 데이터를 공유한다면으로 시작하게 되었습니다. 실제로 멀티 스레드의 메모리 구조를 봐도 스택 영역을 제외한 나머지 영역에는 스레드끼리 공유하고 있습니다. 즉, 프로세스 처럼 메모리나 데이터를 할당받아 차지하는 것보다 효율적으로 메모리를 사용할 수 있게 됩니다. 그리고 전환 속도도 빠릅니다. 그러나 스레드는 데이터를 전역 변수로 이용하기 때문에 오버헤드가 늘어날 수 있습니다.
멀티 프로세싱과 멀티 스레딩
사전 개념
먼저 개념적으로 3가지 용어에 대해 다시한번 짚고 넘어가봅시다.
- 프로세서(CPU) : 프로세스는 CPU나 마이크로프로세서라는 하드웨어를 의미합니다.
- 프로세스(Process): 실제 메모리에 적재되어 프로세서(CPU)에 의해 실행되는 프로그램을 말합니다.
- 스레드(Thread) : 프로세스 내에서 실행되는 흐름 단위를 말하며 한 프로그램에 둘 이상의 스레드를 동시에실행할 수 있습니다.
멀티 태스킹(Multi Tasking)
프로세스보다 좀 더 확장된 개념으로 다수의 Task를 번갈아가면서 처리하는 것을 말합니다. 이렇게 번갈아 가며서 처리하는 것은 동시에 처리하는 것처럼 보이게 됩니다.
멀티 프로그래밍(Multi Programming)
- 멀티 프로그래밍 : 프로세서(CPU)가 A 작업을 처리하는 중에 다른 작업을 접근하는 방식인데요. 대표적으로, 응용 프로그램을 실행하다가 파일을 접근할 때를 말합니다.

이러한 멀티 프로그래밍, 멀티 프로세싱 환경에서 생길 수 있는 문제는 교착상태(Deadlock) 입니다.
교착상태(Dead Lock)?
우선, 교착 상태는 서로 자원을 가지고 있음에도 자원을 얻지 못해 처리할 수 없는 상태를 말합니다. 상호 배제, 점유대기, 비선점, 환형 대기로 인해 생기게 되죠.
그렇다면, 어떻게 해결할 수 있을까요?
- 예방(Prevention) : 위 네가지 발생 조건 중 하나를 부정하는 방법
- 회복(Recovery) : 교착 상태를 일으킨 프로세스를 종료한다.
- 무시(Ingnore) :
응답없음처럼 그냥 작업을 종료 - 회피(Avoidance) : 교착 상태가 발생할 가능성이 적을 때 자원을 할당하여 은행원 알고리즘을 통해 할당 가능여부를 판단합니다.
💡 은행원 알고리즘(Banker's Algorithm)
안정 상태(Safe State)를 유지하면서 총 자원양과 현재 할당 자원양을 기준으로 안정적으로 자원을 할당하는 알고리즘입니다.
멀티 프로세싱(Multi Processing)
여기서 중요한 것은 동시에 처리하는 역할이 프로세스가 아니라 프로세서(CPU)입니다. 즉, 다수의 프로세서(CPU)가 다수의 작업을 함께 처리하는 것을 말합니다.
- 안정성 : 하나의 프로세서가 고장나도 다른 프로세서가 대체할 수 있기 때문에 신뢰도가 높습니다.
- 프로세스 공유 : 프로세스를 공유하여 사용하기 때문에 비용을 절약할 수 있습니다.
- 잦은 문맥교환 : 각각 독립된 메모리 영역을 갖고 있기 때문에 오버헤드가 발생할 수 있습니다.
💡 IPC
inter-Process-Communication 이라고 하는 IPC는 독립적인 구조를 가진 프로세스들 간 통신하도록 관리하는 방법을 말합니다. 프로세스는 커널의 IPC 설비를 통해 통신할 수 있는데 다양한 설비 종류가 존재합니다.
- 공유 메모리 : 파이프, 메세지큐와 다르게 메모리 자체를 공유해 사용할 수 있어 오버헤드가 발생하지 않고 빠름.
- 파일이나 소켓 : FTP나 NIC(네트워크 인터페이스)를 사용해 데이터 전송
- 파이프
- 익명 파이프 : 프로세스끼리 단방향으로 통신이 가능한 방식 (한쪽에서는 쓰고 한쪽에서는 읽고)
- 명명 파이프 : 익명 파이프와 다르게 전혀 모르는 프로세스와 통신이 가능한 방식, 역시나 동시 읽기쓰기는 안되고 전이중으로 통신하려면 2개를 만들어야 함.
- 메세지 큐 : 메시지 단위로 공유해 동기화를 구현
만약에 프로세스 간 공유를 한다고 생각하면, 자원을 접근하는데 동시에 들어갈 수 있는 문제도 있지 않을까?
이러한 문제를 방지하기 위해 자원에 대한 접근을 제어하는 세마포어(Semaphore)가 존재합니다. 이 이야기는 멀티 스레딩과 멀티 프로세싱 차이가 끝나고 얘기해봅시다.
멀티 스레딩(Multi Threading)
프로세스 내부에 쓰레드가 2개이상 존재해 다수의 스레드가 자원을 공유해 하나의 프로세스를 실행시키는 방식을 의미합니다. 멀티 쓰레딩은 프로세스와 달리 거의 모든 영역이 서로 공유하고 있기 때문에 효율적일 뿐만 아니라 생성 비용도 더 저렴하기 때문에 수행 능력을 향상시켜 줍니다. 다만, 서로 공유하는 메모리이기 때문에 하나의 스레드가 망가지면 모든 스레드에도 영향을 줍니다.
이 공유 메모리로 인한 안정성 문제는 프로세스 동기화(Process Synchronization)를 통해 대비할 수 있습니다. 두 개 이상의 프로세스가 공유자원에 동시 접근하면 data inconsistency가 발생할 수 있기 때문에 이를 방지하기 위한 방법이 프로세스 동기화입니다. 프로세스 동기화의 종류로 뮤텍스, 세마포어, 모니터등이 있습니다.
공유 자원(Shared Resource)와 프로세스 동기화(Process Synchronization)
다음과 같이 프로세스나 스레드가 공유할 수 있는 자원을 공유 자원이라하는데 이 프로세스나 스레드가 동시에 접근을 하는 상황은 경쟁상태(race condition)이라고 합니다. 그런데 이렇게 동시에 자원을 접근 함으로써 달라지는 코드의 일부를 임계구역(Critical Section)이라고 합니다.
아래 그림을 보면, 두 스레드가 각 전역 변수의 값을 1을 증가시켰을 때, 어떤 순서나 타이밍으로 인해 예상치 못한 결과가 발생하게 되었습니다. 이러한 경쟁 상태를 상호 배제, 한정 대기 등의 조건들을 통해 뮤텍스나 세마포어등으로 방지할 수 있습니다.
뮤텍스(Mutex)
실행시간이 서로 겹치지 않게 서로 단독으로 실행되게하는 기술입니다. 각각 lock , unlock으로 상호 배제하는 기술입니다.
- 뮤텍스 알고리즘으로 데커 알고리즘, 피터슨 알고리즘, 제과점 알고리즘이 있습니다.

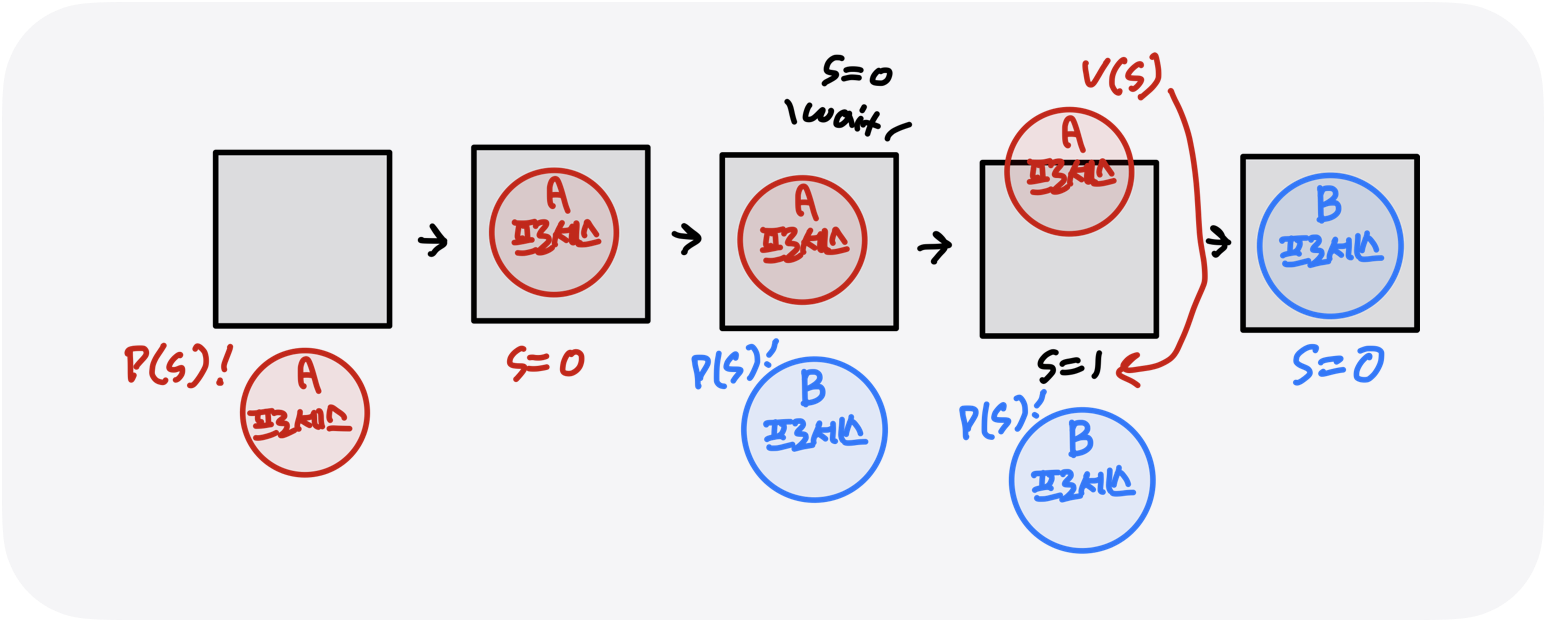
세마포어(Semaphore)
wait(P)와 signal(V) 연산을 통해 함수로 자원에 대한 접근을 처리합니다. P나 V를 수행하는 동안에는 프로세스가 인터럽트 하지 않습니다.
- 배경 : 상호 배제
모니터
둘 이상의 스레드나 프로세스가 공유자원을 안전하게 접근할 수 있도록 모니터 큐를 이용해 인터페이스만 제공하는 방법이다. 세마포어와 다르게 자동적으로 상호배제가 구현됩니다.
💡 스레드 안전(Thread Safety)
동시에 스레드가 자원에 접근해도 프로그래밍 실행에 문제가 없는 것을 말합니다. 스레드 안전 방법으로 상호배제, 원자연산,쓰레드 지역 저장소, 재진입성이 있습니다. 그 중 상호배제는 일반적으로 많이 사용하나 파이썬에는 동시에 스레드를 사용할 수 없는 GIL 정책 때문에 Thread Safe를 보장할 수 있습니다.Python에서
threading.lock을 acqurie하면 해당 쓰레드만 공유 데이터에 접근할 수 있고 lock을 release해야만 다른 쓰레드에서 공유 데이터에 접근할 수 있다.
📌 CPU 스케줄링
운영체제는 가능한 효율적으로 처리하기 위해 프로세스에게 CPU 소유권을 배정합니다. 프로그램이 적당히 있으면 OS는 적당히 CPU 소유권을 줄 수 있으면 하지만 그 규모가 크다면 어떻게 소유권을 줄 수 있을까요? 이는 단계별로 나눌 수 있습니다.
스케줄링 규모별 단계
규모별로 장-중-단기(Long-Mid-Short Term)로 나눌 수 있습니다.
- 장기 스케줄링 : 시스템의 과부하를 막기 위해 전체적인 프로세스 개수를 결정합니다.
- 중기 스케줄링 : 장기 스케줄링에서 활성화된 프로세스 중에서 보류, 활성화로 나누어 분류합니다. 보류된 프로세스는 여유가 생기면 다시 활성화 됩니다.
- 단기 스케줄링 : 실제로 CPU의 할당여부에 따라 상태를 준비,대기냐? 실행이냐?로 결정 짓습니다.
스케줄링 알고리즘
OS는 앞서 설명드렸던 효율성에 따라 알고리즘을 평가해 선택하게 됩니다. 알고리즘 선택의 기준은 CPU 사용시간, 처리량, 대기시간, 응답시간, 반환시간에 따라 알고리즘을 선택하곤 합니다.
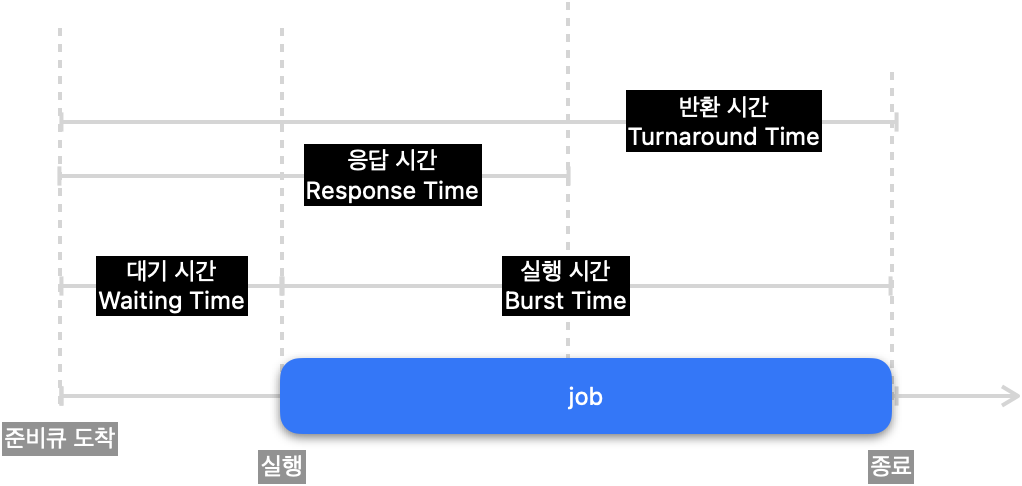
- Response Time : 작업이 처음 반응할 때까지 걸리는 시간
- Turnaround Time :실행 시간 + 대기 시간 = 작업이 완료될 때 까지 걸린 시간
그리고 알고리즘으로는 선점형과 비선점형 방식으로 나뉘게 됩니다.
- 선점형(Preemptive) : OS가 강제로 프로세스를 종료시키고 회수시킬 수 있는 방법
- 비선점형(Nonpreemptive) : 프로세스가 종료되거나 I/O 이벤트가 있을 때까지 실행하는 것
선점 스케줄링
선점 스케줄링은 빠르게 CPU를 강제회수하여 응답할 수 있는 장점이 있지만, 그만큼 많은 오버헤드가 있습니다.
Priority Scheduling
우선순위가 높은 대로 처리하는 알고리즘입니다. 물론 우선순위가 낮으면 무한 대기해야한다는 단점이 있습니다. Aging 방법으로 문제를 해결할 수 있습니다.
💡 에이징(Aging)
아무리 우선순위가 낮은 프로세스라 하더라도 오래 기다리면 우선순위가 높아지는 현상
Round Robin
각 프로세스마다 동일한 할당 시간(Time Quantum)이 주어지는데 이 시간안에 끝나지 않으면 다시 Ready 큐에 삽입되는 알고리즘입니다.
- 할당 시간이 너무 크면 FCFS 처럼 되어버리고, 너무 작으면 잦은 문맥교환으로 인해 오버헤드가 커집니다.
💡 문맥 교환(Context Switch)
앞 프로세스가 쫓겨나고 다음 프로세스가 CPU를 할당받게 되는데 프로세스가 바뀌면서 문맥전환이 일어납니다. 그리고 문맥전환이 이루어지는 동안 CPU는 아무것도 하지 않습니다. 즉, 문맥 전환이 잦으면 CPU 이용률도 감소하게 됩니다.
시간 할당량이 작으면 문맥 전환이 잦게 발생하는데, 반대로 시간 할당량이 크면 대기 시간이 증가하게 됩니다. 그래서 적절한 시간 할당량은 10ms ~ 100ms입니다.
SRF (Shortest Reamining Time First, SRTF)
SJF와 조금 다르게 중간에 더 짧은 작업이 들어오게 되면 더 짧은 작업 먼저 수행시키는 알고리즘입니다.
Multilevel-Queue(다단계 큐)
우선순위에 따라 여러 종류의 알고리즘 큐로 나누어 그 중에서 하나를 선점에 CPU를 할당하는 방법입니다.
- 우선순위가 낮은 큐들이 실행 못하는 것을 막기 위해 반비례로 Time Quantum을 할당합니다. (우선순위가 높다면 작은 Time QuanTum)
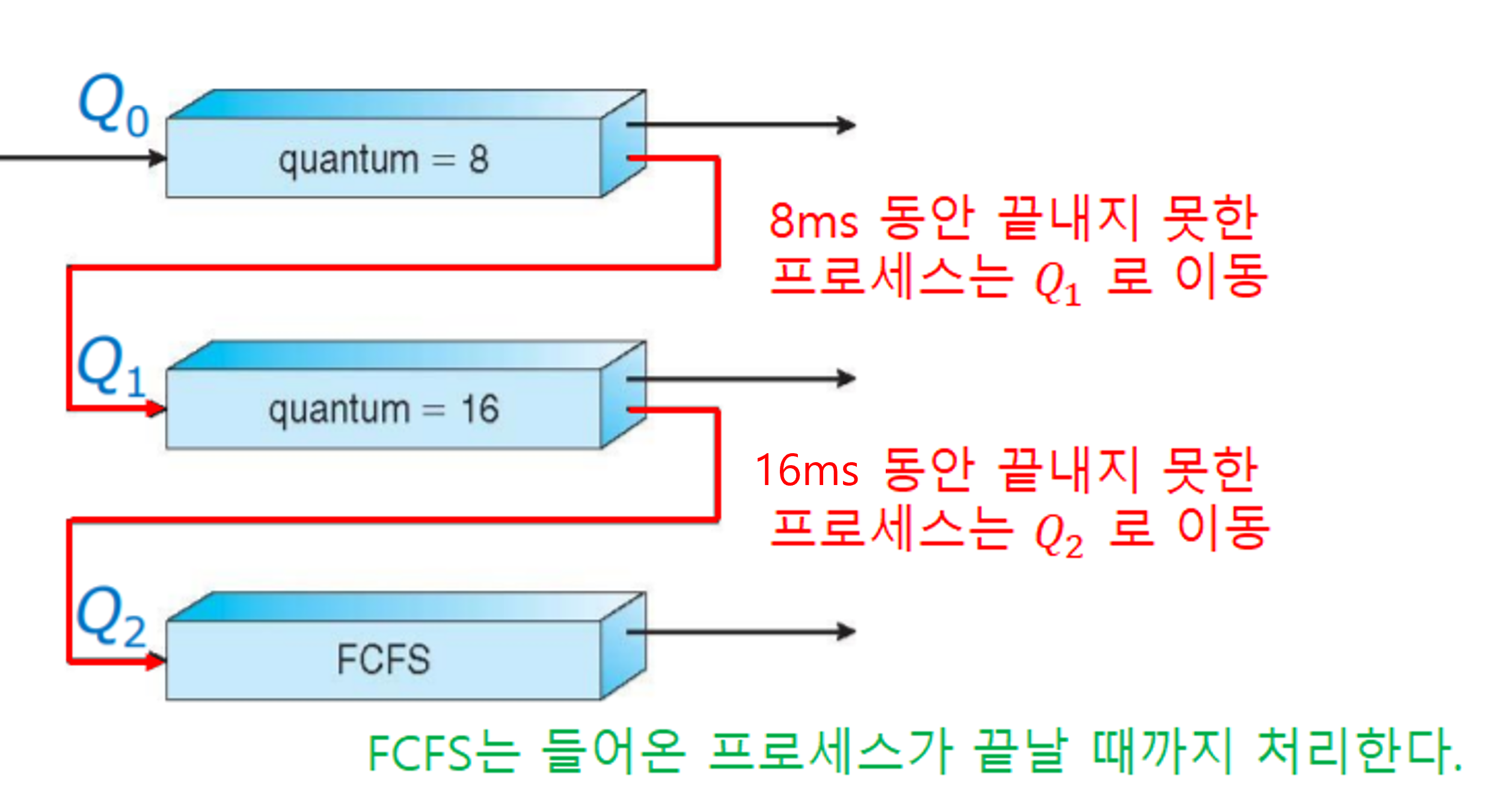
다단계 피드백 큐는 이전 다단계 큐와 다르게 프로세스들이 큐를 갈아탈 수 있는 방식입니다. Aging(오래된 작업일 수록 우선순위를 높이는 방법)을 통해 대기 시간이 긴 프로세스를 높은 우선순위 큐에 올려 기아 현상(Starvation)를 막을 수 있습니다.
비선점 스케줄링
문맥교환 오버헤드가 적다는 장점이 있으나 그 만큼 시간이 길기 때문에 처리률이 낮습니다.
1. FCFS(First Come First Served)
도착한 순서대로 처리하는 알고리즘입니다. 그러나 길게 수행되는 프로세스로 인해 오래 기다릴 수 밖에 없는 콘보이 현상가 발생합니다. 또, 그만큼 평균 대기시간도 길어질 수 밖에 없습니다.
💡 콘보이 현상(Convoy Effect)
긴 프로세스가 먼저 도달하여 모든 다른 프로세스들이 하나의 긴 프로세스가 CPU를 양도하기를 기다리는 효과입니다. 🚛🚙🚙
2. SJF(Shortest Job First)
수행시간이 가장 짧은 프로세스를 먼저 실행 시키는 알고리즘입니다. 평균 대기 시간이 짧지만 긴 프로세스가 뒤로 밀려나 기아 현상이 발생할 수도 있습니다. 계속 뒤로 밀려나가면 정확히 언제 끝나는지도 알 수 없어집니다.
💡 기아 현상(Starvation)
사용시간이 긴 프로세스는 영원히 CPU를 할당받지 못하는 현상입니다.
3. HRN(Hightest Response-ratio Next)
기존의 SJF 방식의 단점을 보완하여 오래된 작업일 수록 우선순위를 높이는 방법입니다.
- 우선순위 = (대기시간 + 처리시간)/처리시간
참고
https://doorbw.tistory.com/26
https://taegyunwoo.github.io/os/OS_MultiLayerQueue_MultiProcessor_RealtimeSystem
https://brunch.co.kr/@kd4/3
