안녕하십니까. 김동우입니다.
.png)
시작 전에 컴파일 과정 한 번 보고 시작하겠습니다.
이번 글에서는 조금 다양한 이야기를 해보고자 합니다.
따라서, 조금 중구난방식의 흐름으로 전개를 할테니 Ctrl+f 기능을 활용해서 필요한 정보를 찾아보시는 것을 추천드립니다.
keyword
1. Object - 객체
2. Variables - 변수
3. Left-values && Right-values
4. initialization && assignment
5. initialization의 필요성
-
Object
우선은 객체, Object라는 녀석에 대해 얘기해보겠습니다. 기존에 다른 언어를 사용하시던 분들에게는 상당히 익숙한 개념이지만, 초심자에게는 꽤나 모호한 개념으로 보입니다.
객체라는 것은 노트를 읽다 보면 차차 나올 개념이지만, 우선은 메모리를 차지하는 무언가 정도로 이해하고 넘기시는게 좋습니다.
그래도 그게 정 별로라고 생각이 드신다면, 수정, 대입, 치환, 등등의 모든 기본적인 작용 & 함수를 통한 변경 등의 동작이 가능한 무언가. 이렇게 생각하고 이후 노트를 보시면 됩니다.
이러한 기준에서 볼 경우, 메모리를 차지하는 무언가는 전부 작용과 동작의 대상이 되겠죠?
이러한 객체들은 공간을 차지한다는 것을 알아두시면 이후 내용 이해가 쉽습니다.대부분의 언어가 객체지향프로그래밍(OOP)인 이상 객체라는 개념은 더욱 중요하지만, 쉽게 이해할 수 없는데다가 공부하는 입장에서는 특히 매번 정의하기 어려운 개념인 것 같습니다.
그렇기에 몇몇 언어들은 우리 언어에서 사용하는 객체타입은 무엇이다! 하고 정의내린 기준이 존재할 만큼 친절하죠.
이후 객체에 대해서는 상당히 긴 글로 찾아뵙게 될 것 같습니다.
-
Variables
이제 메모리를 차지하고 있는 객체들을 활용해서 우린 프로그래밍을 하게 됩니다.
그렇다면, 이 메모리를 차지하고 있는 녀석들을 우린 어떻게 찾아가고, 불러낼 수 있을까요?
이를 위해서는 대부분의 Data structure 강의에서 가장 먼저 설명하는 메모리 구조를 조금 인용해야 합니다.
변수는 메모리에 할당된다. 이 때 메모리는 RAM 내의 메모리를 의미한다.
하드웨어를 갑자기 꺼내오니 답답해지는 느낌을 받으셨나요?
안타깝게도, 메모리 구조에 대한 이해를 하기 위해서는 또 다시 하드웨어 지식을 아주 일부 사용해야만 합니다.
RAM 공간은 기본적으로 쌓이는 구조로 표현됩니다. stack이라는 개념으로요.
이 공간들은 1 byte의 크기를 가지고 있습니다.
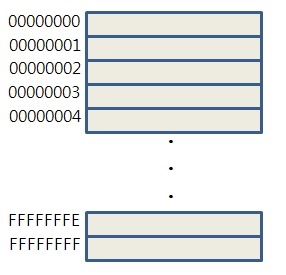
그리고 이렇게, 16진수 표기로 된 주소를 가지고 있죠.
만약, 객체가 4byte 크기를 가진다면 RAM에서는 4칸의 공간을 내어주어야 합니다.
그런데 RAM을 왜 가져와서 얘길 하느냐구요?
C++는 컴파일과 런타임에서 각각 다른 지정된 변수들과 함수를 RAM에 저장하게 됩니다. 이후에 나올 전역변수, 지역변수 등등이 그렇습니다.
이러한 변수들은 객체가 최소조건인 주소와 공간을 할당받아 실제 프로그래밍에 유효한 영향을 끼치는 상태가 된 것입니다.
변수는 사전에 부피(혹은 데이터량)만을 가지고 있던 데이터 쪼가리 객체에 명확한 메모리 주소가 할당되었고, 메모리 공간을 얼마나 잡아먹는지에 대한 정보까지 추가된 상태인 것이죠.
이해가 좀 되고 계신가요?
생각보다 모호한 개념인 객체에 비해 변수는 쉽게 이해하실 수 있을겁니다.
이러한 변수를 사용해서 나머지 개념을 적어보도록 하죠.
-
Left values & Right values
int x; x = 3;소스를 보시면 참 단촐하죠? 위 소스에서
int x;를 먼저 봐주시면 됩니다.변수 x 를 선언하는 단계에서 OS는 이미 크기와 주소를 모두 결정했습니다.
정말 놀랍죠? int 는 정수형 표현 범위를 가지고 있습니다. 그렇다면 이게 크기가 되는 것이죠. 자료형 이전 단계이니 여기까지만 잠깐 아셔도 괜찮습니다.
그리고 x를 적고, 세미콜론을 적은 순간 OS는 x라는 변수가 사용될 것이고, 또한 이 변수의 크기는 int의 범위만큼 표현할 수 있는 크기를 가지고 있다는 판단 하에 주소를 할당합니다.
즉, 우리도 모르는 새에 메모리를 사용하겠다고 선언한 것이죠.
그 다음 줄의 코드를 확인해보면,
여기서
x = 3;이라는 대입행이 나옵니다.프로그래밍에서 등호는 대부분 대입이라는 뜻입니다. 절대 같다는 말이 아닙니다.
등호를 기준으로 좌항을 Left values, 우항을 Right values 라고 표현합니다.
이 때, Left values는 변수 x이기 때문에 메모리 주소와 사용할 수 있는 공간정보를 내포하고 있습니다.
Right values는 메모리 크기를 가지는 임의의 정수값입니다.
즉, 대입이라는 뜻 자체로 미루어 좌항의 변수가 상주하고 있는 메모리 주소에 우항의 값을 일시적으로 밀어넣겠다! 라는 말이 됩니다.
변경할 수 있다는 의미에서 일시적이라는 표현을 했습니다.
그렇기에 만약 int 형이 표현할 수 있는 범위 이상의 정수값이 우항에 존재한다면, 당연히 들어갈 수 없으니 에러가 발생하겠죠? 이는 자료형에서 더 깊게 말씀드리겠습니다.
-
initialization & assignment &&
-
initialization의 필요성
이제 어느덧 초기화와 대입(또는 할당)입니다. 그리고 이번 글에서는 초기화의 필요성을 묶어 적고자 합니다.긴 글 읽으시느라 고생하셨고, 이제는 정말 빠르게 지나가겠습니다.
int x; std::cout << x << std::endl;이러한 코드를 실행시킬 수 있을까요?
아마도 warning 혹은 error가 발생할 코드의 예시입니다.
그 이유는 간단합니다.
주소를 알고 찾아갔더니 상주하고 있는 사람이 없는 경우인 것이죠.
즉, 컴파일러 입장에서 허탕쳤다! 이렇게 생각하시면 됩니다.
이러한 경우를 방지하기 위해 우리는 항상 공간을 차지하고 있는 특정 값을 처음 선언할 당시 임의로 지정해주고 있습니다.
int x = 3;이런 방식으로 진행되는데, 이를 우리는 initialization, 초기화라고 합니다.처음 선언할 때 값을 넣어주면 초기화, 이후에
x = 3;의 형태로 다시 값을 넣어주는 것을 우린 assignment, 대입이라 말합니다.만약 초기화된 값도 없고, 대입된 값이 없는 변수를 함수 혹은 표현식에서 사용할 경우 우린 어떤 문제를 겪게 될까요?
Debug 모드에서는 컴파일러가 경고를 외치겠지만, 이 상황이 만약 Release 모드라면 큰 문제가 발생합니다.
프로그램의 실행을 보장해야하는 Release 모드에서는 초기화값이 없는 변수를 호출할 경우 원하지 않던 임의의 데이터를 변수에 삽입한 상태로 배포하게 됩니다.
이것은 상당히 치명적인 결함으로 변모되겠죠?
더군다나 이 경우, 사용하는 컴파일러에 따라 해당 변수의 값이 중구난방으로 입력됩니다.
그러한 경우 소프트웨어 품질에 있어 치명적인 영향을 끼친다고 볼 수 있겠습니다.
자, 이번 글은 여기서 마치겠습니다.
사진 출처 - https://blog.daum.net/coolprogramming/8 (RAM 공간 그림)
