
함수(function)
- 특정 작업을 수행하는 코드 블록
함수의 필요성
- 코드 재사용(재활용성)
- 동일한 작업을 반복할 때 매번 코드를 다시 작성할 필요 없음 -> 한 번 정의한 함수는 여러 번 호출 가능
- 코드의 가독성 향상
- 기능 단위로 묶어서 코드가 논리적으로 명확해짐
- 다른 사람이 읽고 이해하기 쉬워짐
- 유지보수 용이성
- 수정이 필요한 부분이 생기면 함수 내부만 고치면 됨 -> 중복 코드 수정의 부담 감소
- 프로그램의 구조화(모듈화)
- 큰 프로그램을 여러 개의 작은 작업으로 나누어 체계적으로 관리
- 각 함수는 하난의 "기능"만 담당하게 설계하는 것이 원칙(단일 책임 원칙)
- 협업과 확장성
- 개발자끼리 작업 분담이 쉬움
- 작은 단위의 함수가 쌓여 큰 기능을 구성(계층적 설계)
내장함수와 사용자 정의 함수
- 내장함수: 파이썬이 기본적으로 제공하는 함수들로, 별도 정의 없이 바로 사용할 수 있는 함수 ex) print(), len()
- 사용자 정의 함수: 사용자가 def 키워드를 사용하여 직접 만든 함수
사용자 정의 함수 기본 문법
- 함수의 정의: define의 약자로 def사용
def 함수이름 (매개변수):
# 실행할 코드
print(매개변수)
return "반환값"
# 함수의 시행(호출, call)
result = 함수이름("인자")
print(result)매개변수(parameter): 매개 + 변수
- 매개: 둘 사이를 연결해줌
- 함수가 실행될 때 인자로부터 입력되는 값을 함수의 코드블록으로 전달하는 역할
- 함수 뒤 괄호: 함수에 전달할 값이 없더라도 실행시 괄호 반드시 필요
- 인자: 함수 호출 시 전달하는 값
함수의 필요성 예제
a = 10
b = 20
if a > b:
print(a - b)
else:
print(b + a)
c = 30
d = 40
if c > d:
print(c - d)
else:
print(c + d)줄이 너무 길고 가독성이 떨어진다.
def my_func(a, b):
if a > b:
return(a - b)
else:
return(b + a)
print(my_func(10, 20))
print(my_func(30, 40))실습 1. 사칙연산 계산기 함수 만들기
def calculator(a, b, operator):
#operator = "+" or "-" or "*" or "/"
if (operator == "+"):
return (a + b)
elif (operator == "-"):
return (a - b)
elif (operator == "*"):
return (a * b)
elif (operator == "/"):
return float(a / b)
else:
return("지원하지 않는 연산입니다.")
print(calculator(4, 5, "*"))
print(calculator(7, 9, "-"))
print(calculator(43454223, 56462, "/"))
print(calculator(65423, 3121, "+"))
print(calculator(4, 5, "#%^"))결과

키워드 인자
# 예시 1.
print("안녕하세요", "반값습니다!", sep='-', end='/')
# 예시 2.
def my_func(a, b, c=None, operator=None):
if operator =="+":
return a + b
else:
return c
print(my_func(10, 20, operator="+"))기본값 인자
단, 기본값 매개변수는 뒤쪽에 위치해야함
def greet(name, message="안녕하세요~!"):
print(f"{name}님, {message}")호출 시 인자 생량 -> 기본값 사용
greet("Dongyun2")
greet("ff", "반갑습니다!")위치 가변 인자(*args <- arguments)
- 여러 개의 값을 유동적으로 받을 수 있음
- 값이 튜플 형태로 받아짐
def add_all(*args):
return sum(args)
print(add_all(1, 2, 3, 4, 5))키워드 가변인자(**kwargs)
- 여러 키워드 인자를 유동적으로 받을 수 있음
- 딕셔너리 형태로 값이 입력됨
def print_info(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
print_info(name = "동윤2", age = 26, city = "포항")
# 가변 인자 사용시 주의사항
# --> 위치 인자 --> 기본값 인자 --> *args --> **kwargs 순서로 정의해야 함매개변수 전달 방식
- 파이썬은 값 전달(call by value)이 아닌, 객체 참조에 의한 전달(call by object reference)방식
- 변경 가능한 객체(mutable): 함수 내 변경 --> 외부에도 영향
- 변경 불가능한 객체(immutable): 함수 내 변경 --> 외부 영향 없음
*args 사용 연습
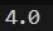
실습 2-1. 숫자 여러 개의 평균 구하기
def average(*args):
return sum(args) / len(args)
print(average(1, 3, 5, 4, 5, 6))결과
실습 2-2. 가장 긴 문자열 찾기(max함수)
def longgest_str(*args):
return max(args, key=len)
print(longgest_str("안녕", "안녕하시렵니까", "쎕쎄요는 나의 유행어", "에어컨~"))결과

*kwargs 사용 연습
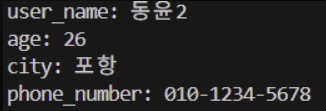
실습 2-3. 사용자 정보 출력 함수
def info(**kwargs):
for key, value in kwargs.items():
print(f"{key}: {value}")
info(user_name = "동윤2", age = 26, city = "포항", phone_number = "010-1234-5678")결과
실습 2-4. 할인 계산기
def bargain(**kwargs):
sale_items = {}
for key, value in kwargs.items():
sale_items[key] = int(value * 0.9)
print(f"{key}: {value}")
return sale_items
print(bargain(cable = 18000, bottle = 5000, chair = 64000, wallet = 50000))결과

파이썬의 메모리 구조
스택 영역
- 지역변수(local variable), 매개변수(parameter) 등이 저장되는 공간
힙 영역 - 파이썬에서 생성되는 모든 객체(숫자, 문자열, 리스트, 딕셔너리, 클래스 등)가 저장되는 공간
변수의 유효 범위(scope)
- scope: 어떤 이름(변수, 함수 등)을 참조할 수 있는 코드의 범위
- 파이썬의 이름 규칙 : LEGB Rule
- local, enclosing, global, built-in
지역변수(local variable)
- 함수 내부에서 선언된 변수
- 함수가 호출될 때 생성되고, 함수가 끝나면 소멸됨
전역변수(global variable)
- 함수 외부에서 선언된 변수
- 프로그램 전체에서 접근 가능(단, 함수 내부에서 값 변경은 제한됨)
# 전역변수
x = 200예제 1.
def my_func():
#지역변수
x = 10
print(x)
my_func()
print("함수 밖", x)예제 2. (UnboundLocalError발생)
x = 10
def my_func2():
# x = 20
x = x + 5
print(x)
my_func2()
print("전역변수", x)예제 3.(global 사용 예제)
x = 10
def my_func3():
global x # 전역변수 사용 선언
x = x + 5
print("지역", x)
my_func3()
print("전역", x)
# 권장되는 패턴
# 부수효과(side effect)를 발생시키지 않는 함수를 위주로 프로그래밍
x = 10
def my_func4(x):
x += 5
return x
x = my_func4(x)
print("전역", x)실습 3. 로그인/로그아웃 전역 상태 관리
current_user = '' # current_user = None
login_count = 0
def login(name):
global current_user
global login_count
if current_user:
print(f"이미 {current_user}(이/가) 로그인되어 있습니다.")
else:
current_user += name
print(f"{name}님 로그인 성공")
return current_user
if current_user == None:
current_user = name
print(f"{name}님 로그인 성공")
else:
print(f"이미 {current_user}(이/가) 로그인되어 있습니다.")
login_count += 1
if login_count > 4
print("더 이상 로그인 시도를 할 수 없습니다.")
def logout():
global current_user
# global login_count
current_user = '' # 걍 초기화 해버림
print("로그아웃 되었습니다.")
return current_user
if current_uesr == None:
print("로그인 상태가 아닙니다.")
else:
print("로그아웃 되었습니다!")
current_user = None
login_count = 0
# login("동윤2")
# login("빠니보틀")
# logout()
# login("빠니보틀")
# print(current_user)결과

재귀함수
- 함수가 자기자신을 호출하는 함수
- 반복문 업이 특정 작업을 반복 수행할 수 있음
재귀함수의 작동 원리
- 함수가 자기자신을 호출하면서, 문제를 더 작은 문제로 나눔
- 기본조건이 충족될 때 까지 재귀 호출을 반복
- 기본조건을 만나면 재귀 호출이 종료되고, 함수가 차례로 반환됨
- 재귀 호출이 끝나려면 반즈싯 기본조건이 필요함 --> 없으면 무한루프 발생
재귀함수의 장점
- 코드가 직관적이고 간결함: 재귀함수는 복잡한 문제를 간결하게 표현할 수 있어 코드 가독성이 높아짐.
- 문제 해결을 논리적으로 표현 가능: 반복문(for, while)보다 문제의 개념을 더 자연스럽게 코드로 표현 가능
- 일부 알고리즘에 적합: 분할 정복, 백트래킹, 트리탐색과 같은 문제에서는 재귀가 매우 유용함.
- 데이터 구조 탐색에 용이: 연결 리스트, 그래프, 트리와 같은 재귀적 구조를 가진 데이터 구조 탐색에 적합함.
귀함수의 단점
- 스택 오버플로우 위험: 너무 깊은 재귀 호출이 발생하면 스택 메모리가 초과되어 프로그램이 종료될 수 있음.
- 반복문보다 성능이 낮을 수 있음: 함수 호출마다 스택 프레임이 생성되므로, 반복문보다 성능이 떨어질 수 있음.
- 메모리 사용량 증가: 각 함수 호출마다 메모리가 추가로 필요하므로, 메모리 사용량이 증가할 수 있음.
- 중복 연산이 발생할 가능성: 피보나치 수열처럼 같은 값을 여러 번 계산하는 경우 불필요한 연산이 많아짐.
- 디버깅이 어려울 수 있음: 반복문보다 실행 흐름을 추적하기 어려울 수 있음.
#재귀함수
#1. 자기 자신을 호출하는 함수
#2. 반드시 기본조건(종료조건)이 있어야 함
#+ 큰 문제를 작은 문제로 나누었을 때, 일정한 패턴이 있어야 한다.
import time
def recursive_func(n):
# 기본조건
if n == 0:
return
recursive_func(n-1)
print("재귀 호출", n)
time.sleep(1)
recursive_func(5)실습4. 거듭 제곱
def power(a, b):
if b == 0:
return 1 # a^0
c = 1 # a^0
for b in range(b): # b번 거듭제곱
c = c * a
return c
# if b == 0:
# return 1
# return a * power(a, b - 1)
# --> b = 0 이 되는 순간까지 b + 1 번 곱
print(power(2, 4)) # 16실습 5. 팩토리얼
def factorial1(a):
if a == 1:
return 1 # a! = a * (a-1) * (a-2) * (a-3)* ..... * (a-n) * .....* 3 * 2 * 1
b = 1 # factorial를 받을 변수 b에 1을 할당 // 0! = 1
for a in range(a, 1, -1):
b = b * a
return b
print(factorial1(5)) # 120
def factorial2(a):
if a == 1:
return 1 # a! = a * (a-1) * (a-2) * (a-3)* ..... * (a-n) * .....* 3 * 2 * 1
return a * factorial2(a-1) # a! = a * (a-1)~~~~~
print(factorial2(5)) # 120실습 6. 피보나치 수열
def fibonacci1(n):
if n <= 0:
return 0
a, b = 1, 1
for n in range(1, n-1):
a, b = b, a+ b
return b
print(fibonacci1(7)) # 13
def fibonacci2(n):
if n <= 0:
return 0
if n <= 2:
return 1
return fibonacci2(n-1) + fibonacci2(n-2)
print(fibonacci2(6)) # 8
# 1 --> 1
# 2 --> 1
# 3 --> 2
# 4 --> 3
# 5 --> 5
# 6 --> 8
# 7 --> 13람다(lambda) 함수
- 익명 함수
- 간단한 함수를 한줄로 표현할 때 사용
람다 함수의 기본 문법
- lambda 매개변수: 표현식
- 표현식: 값이 반환되는 식
일반 함수
def add(x, y):
return x + y람다 함수
add_func = lambda x, y: x + y
print(add_func(3, 5)) # 8람다로 값을 반환하고 사용을 끝내는 경우
print((lambda x: x ** 2)(10)) # 100람다 함수의 활용
- map에서 활용
my_list = [1, 2, 3, 4]일반 함수를 사용
def square_func(x):
return x ** 2함수를 인자로 받는 함수
print(list(map(square_func, my_list))) # [1, 4, 9, 16]람다 함수를 사용
print(list(map(lambda x: x ** 2, my_list))) # [1, 4, 9, 16]- filter에서 활용
my_list2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]일반 함수 사용
def is_even(x):
return x % 2 == 0
print(list(filter(is_even, my_list2))) # [2, 4, 6, 8, 10]람다 함수를 사용
print(list(filter(lambda x: (x % 2) == 0, my_list2))) # [2, 4, 6, 8, 10]3. sorted에서 활용
my_list3 = ["apple", "banana", "watermelon", "grape"]
print(sorted(my_list3, key = lambda word: len(word))) # ['apple', 'grape', 'banana', 'watermelon']람다 함수 사용 주의사항
- 문장 사용 금지: return, if, for 문은 사용 불가(표현식만 가능)
- 디버깅 어려움: 익명이므로 디버깅 시 함수 이름 없음
- 남용주의: 복잡한 로직은 def로 명시적으로 작성하는 것이 좋음
실습 7-1. 특정 조건 만족하는 튜플만 추출
students = [("Alice", [80, 90]), ("Bob", [60, 65]), ("Charlie", [70, 70])]
# 리스트 안에 튜플 안에 문자열과 리스트
# 안의 정수 리스트를 불러와서 계산을 해야됨
print(list(filter(lambda x: sum(x[1]) / len(x[1]) >= 70, students))) # [('Alice', [80, 90]), ('Charlie', [70, 70])]
# x = 튜플, x[1] = 점수 리스트결과

실습 7-2. 키워드 추출 리스트 만들기
sentences = ["Python is fun", "Lambda functions are powerful", "Coding is creative"]
# 규칙이 있다면, 띄어쓰기, 대문자 구분, 문장의 첫 번째 단어?
print(list(map(lambda sentences: sentences.split()[0], sentences))) # ['Python', 'Lambda', 'Coding']
# map이 아닌 filter를 쓰면 람다함수 조건식에 의해서 모든 문자열들이 true로 판별되니까 모든 문장이 필터를 통과하게 된다.
# map --> 데이터를 변환(첫 단어만 뽑아내는 등) / filter --> 데이터를 선별(조건에 맞는 원소만 남김)결과

실습 7-3. 튜플 리스트 정렬하기
people = [("Alice", 30), ("Bob", 25), ("Charlie", 35)]
print(sorted(people, key = lambda x: x[1])) # [('Bob', 25), ('Alice', 30), ('Charlie', 35)]결과


동윤2입니다.