

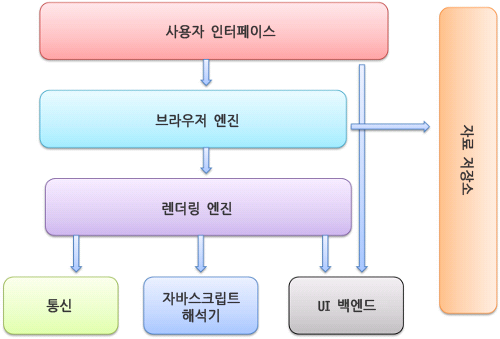
브라우저 구성요소(Browser components)
이미지 출처: https://d2.naver.com/helloworld/59361
사용자 인터페이스(User Interpace)
주소 표시줄, 이전/다음 버튼, 북마크 메뉴 등이 포함되며 요청한 페이지가 표시되는 창을 제외한 브라우저의 모든 부분이 표시된다.브라우저 엔진(Browser engine)
사용자 인터페이스와 렌더링 엔진 사이의 동작을 제어한다.렌더링 엔진(Rendering engine)
요청한 콘텐츠를 표시, 예를 들어 요청된 콘텐츠가 HTML인 경우 HTML 및 CSS를 파싱하여 화면에 표시한다.통신(Networking)
HTTP 요청과 같은 네트워크 호출에 사용되며 플랫폼의 독립적인 인터페이스이다. 각 플랫폼 하부에서 실행된다.UI 백엔드(UI backend)
콤보 박스와 창 같은 기본적인 장치를 그리는데 사용, 플랫폼에서 명시하지 않은 일반적인 인터페이스를 노출하고 운영체제(OS) 사용자 인터페이스 체계를 사용한다.자바스크립트 해석기(JavaScript interpreter)
자바스크립트 코드를 해석하고 실행한다.자료 저장소(Data storage)
자료를 저장하는 계층, 쿠키를 저장하는 것과 같이 모든 종류의 데이터를 로컬에 저장해야 할 수 있다. HTML5 명세에는 브라우저가 지원하는 '웹 데이터 베이스'가 정의되어 있으며 localStorage, IndexedDB, WebSQL 및 FileSystem과 같은 스토리지 메커니즘을 지원한다.
브라우저에 URL을 입력하고 Enter 키를 누르면 어떤 일이 발생하는가?
What happens when you type a URL in the browser and press enter?
- 해당 사이트를 번역하여 기술함.
- "
www.google.com" 검색으로 변경함.
1. 브라우저의 주소 표시줄에 www.google.com 입력한다.
2. 브라우저는 www.google.com의 해당 IP 주소를 찾기 위해 DNS 기록(record)의 캐시(cache)를 확인한다.
DNS(Domain Name System)
-
웹 사이트(URL)의 이름과 연결된 특정 IP 주소를 관리하는 데이터베이스.
-
사람이 읽을 수 있는 도메인 이름을 머신이 읽을 수 있는 IP 주소로 변환하여 컴퓨터가 서로 통신할 수 있도록 한다.
-
인터넷의 DNS 시스템은 이름과 숫자 간의 매핑을 관리하여 마치 전화번호부와 같은 기능을 함.
-
쿼리: DNS 서버에서 이름을 IP 주소로 변환하여 도메인 이름을 웹 브라우저에 입력할 때 최종 사용자를 어떤 서버에 연결할 것인지를 제어하는 것. -
인터넷의 모든 URL에는 고유한 IP 주소가 할당되어 있고 이 IP 주소로 우리가 접속을 요청하는 웹사이트의 서버를 호스팅하는 컴퓨터에 접근할 수 있다.
예를 들어 www.google.com의 IP 주소가 209.85.227.104이면 브라우저에 http://http.85.227.104를 입력하여 www.google.com에 접속할 수 있다.
DNS Query
브라우저에서 DNS 기록을 찾기 위해 확인하는 4가지의 캐시
① 브라우저 캐시를 확인한다.
브라우저는 이전에 방문한 웹사이트에 대해 DNS 기록(record)들의 저장소(repository)를 유지, 관리하고 있다. 그래서 브라우저 캐시를 확인하는 것이 가장 먼저 실행되는 DNS 쿼리(query)이다.
② 브라우저에서 OS 캐시를 확인한다.
브라우저 캐시에 없을 경우 OS가 DNS 레코드 캐시를 유지・관리하기 때문에 브라우저는 기본 컴퓨터 OS에 대한 시스템 호출(system call: 즉, 윈도우의 gethostname)을 하여 레코드를 가져온다.
③ 라우터(router) 캐시를 확인한다.
컴퓨터에도 없는 경우 브라우저는 DNS 레코드 캐시를 유지・관리하는 라우터와 통신한다.
④ ISP 캐시를 확인한다.
모든 단계에 실패하면 브라우저가 ISP로 이동한다. ISP는 DNS 레코드 캐시를 포함하는 자체 DNS 서버를 유지・관리하고 있으며 마지막으로 ISP는 요청된 URL을 찾기 위해 이에 접근한다.
캐시 저장 이유
왜 그렇게 많은 수준에서 유지 보수되는 캐시가 많은지 의아해 할 수 있다. 비록 우리의 정보가 어딘가에 캐싱되는 것이 사생활에 있어서 우리를 편안하게 하지 않지만, 캐시는 네트워크 트래픽을 규제하고 데이터 전송 시간을 개선하는 데 필수적이다.
3. 요청한 URL이 캐시에 없으면 ISP의 DNS 서버가 DNS 쿼리(query)를 시작하여 www.google.com을 호스팅하는 서버의 IP 주소를 찾는다.
내 컴퓨터가 www.google.com을 호스팅하는 서버에 연결하려면 www.google.com의 IP 주소가 필요하다. 여기서 DNS 쿼리의 목적은 웹 사이트에 대한 올바른 IP 주소를 찾을 때까지 인터넷에서 여러 DNS 서버를 검색하는 것을 말한다.
필요한 IP 주소를 찾거나 찾을 수 없다는 오류 응답을 반환할 때까지 DNS 서버에서 DNS 서버로 반복적으로 계속되는 검색을 재귀 검색이라고 한다.
이러한 과정의 ISP DNS 서버를 DNS recursor라 부르며 이 recursor는 인터넷의 다른 DNS서버에 응답을 요청하여 해당 도메인 이름의 적절한 IP주소를 찾는 역할을 한다. 다른 DNS 서버는 웹 사이트 도메인 이름의 도메인 구조에 따라 DNS 검색을 수행하므로 이를 네임 서버(name server)라고 한다.
recursor( = DNS recursive resolver)
DNS 쿼리의 첫 단계. 재귀 확인자(recursive resolver)는 클라이언트와 DNS 네임서버 사이의 중개자 역할을 한다.
재귀 확인자는 웹 클라이언트로부터 DNS 쿼리를 받은 후 캐시된 데이터로 응답하거나 요청을 루트 네임서버로 보내고 또 다른 요청을 TLD 네임서버로 보낸 후 마지막 요청을 권한 있는 네임서버로 보낸다.
재귀 확인자는 요청된 IP 주소가 있는 권한 있는 네임서버로부터 응답을 받은 후 응답을 클라이언트에 보낸다.
이 과정 중 재귀 확인자는 권한 있는 네임서버에서 받은 정보를 캐시한다. 클라이언트가 다른 클라이언트가 최근에 요청한 도메인 이름의 IP 주소를 요청하면 확인자는 네임서버와의 통신 프로세스를 우회하고 캐시에서 요청한 레코드를 클라이언트에 전달할 수 있다.
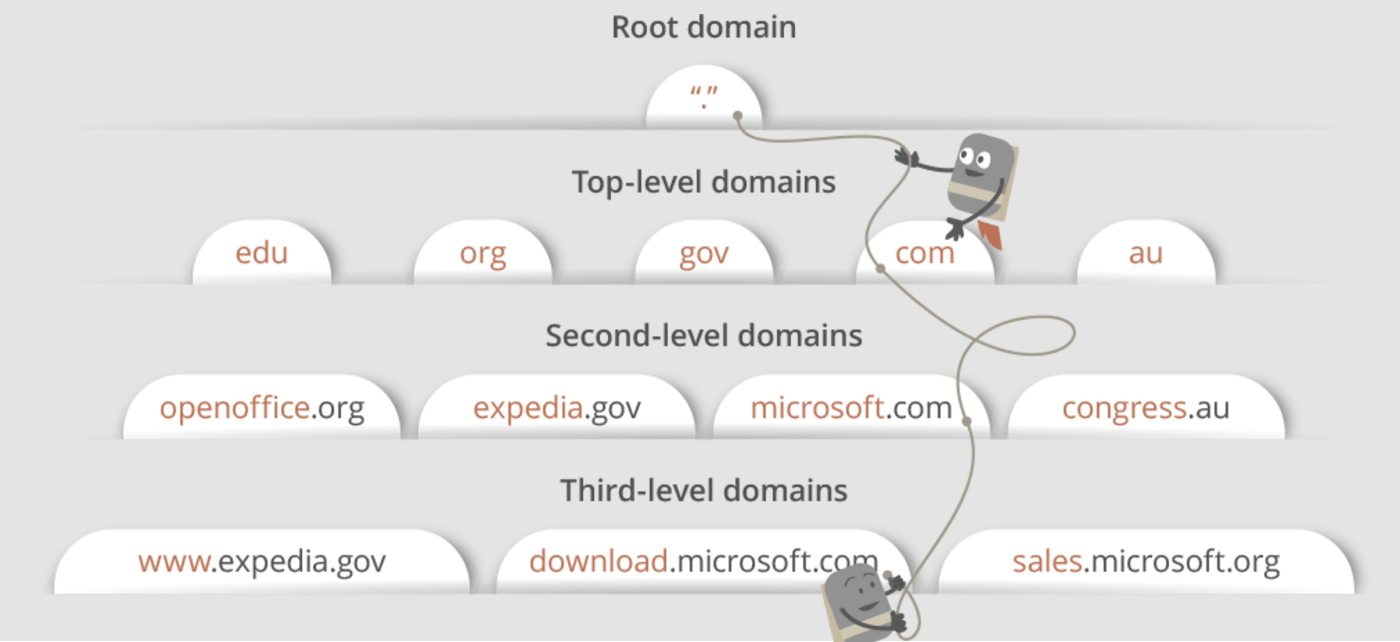
Domain Architecture(도메인 구조)
이미지 출처: https://medium.com/@maneesha.wijesinghe1/what-happens-when-you-type-an-url-in-the-browser-and-press-enter-bb0aa2449c1a
오늘날 우리가 접하는 많은 웹사이트 URL에는 3단계 도메인(third-level domain), 2단계 도메인(second-level domain), 최상위 도메인(top-level domain)이 포함되어 있으며 각 레벨들은 DNS 검색・조회(lookup) 프로세스(process, 과정・절차) 중 쿼리(query)되는 자신만의 고유 이름 서버가 있다.
www.google.com의 경우 DNS recursor가 root name server에 연결한다. root name server는 .com domain name server로 redirect하고 .com name server는 .google.com name servser로 redirect한다. google.com name server는 자신의 DNS 기록(Record)에서 www.google.com에 일치하는 IP 주소를 찾아 DNS recursor에게 반환하고, 이 IP 주소를 브라우저로 다시 보낸다.
Redirect
이러한 요청(request)은 요청 내용 및 IP 주소(DNS recursor의 IP 주소)와 같은 정보를 포함하는 작은 데이터 패킷(packet)을 사용하여 전송된다. 패킷은 올바른 DNS 서버에 도달하기 전에 클라이언트와 서버 사이의 여러 네트워킹 장비를 통해 이동한다. 이 장비는 라우팅 테이블(routing table)을 사용하여 패킷이 목적지에 도달하는 가장 빠른 방법을 알아낸다. 이러한 패킷이 손실되면 요청 실패 오류가 발생하고 오류가 발생하지 않으면 올바른 DNS 서버에 도달하여 IP 주소를 얻은 다음 브라우저로 돌아온다.
4. 브라우저가 서버와의 TCP 연결(connection)을 시작한다.
브라우저가 올바른 IP 주소를 받으면 해당 IP 주소와 일치하는 서버에 연결하여 정보를 전송한 후 인터넷 프로토콜을 사용하여 이러한 연결을 구축한다. 사용할 수 있는 여러 인터넷 프로토콜들이 있으며 그 중 TCP는 HTTP 요청에 사용되는 가장 일반적인 프로토콜이다.
컴퓨터(클라이언트)와 서버 간에 데이터 패킷을 전송하려면 TCP 연결(connection)을 설정해야 한다. TCP 연결은 TCP/IP 3방향 핸드셰이크(three-way handshake)라는 프로세스를 사용하여 설정된다. 이 프로세스는 클라이언트와 서버가 SYN(동기화, synchronize) 및 ACK(승인, acknowledge)메세지를 교환하여 연결을 설정하는 3단계 프로세스이다. 즉, 3번의 프로세스를 거친 후에 연결이 된다.
TCP
client machine
네트워크에 연결되어 서버라는 다른 컴퓨터에 액세스하여 다양한 종류의 리소스를 요청하거나 데이터를 저장하거나 특정 프로그램을 실행하거나 특정 기능을 수행하는 사용자의 컴퓨터를 말한다.
TCP/IP three-way handshake
서버와 클라이언트 간의 연결을 위해 TCP/IP 네트워크에서 사용되는 프로세스이며 실제 데이터 통신 프로세스가 시작되기 전에 클라이언트와 서버가 모두 동기화 및 승인 패킷을 교환해야 하는 3단계 프로세스다.
3방향 핸드셰이크 프로세스는 양쪽 끝이 동시에 TCP 소켓 연결을 시작, 협상 및 분리하는 데 도움이 되도록 설계되었다. 동시에 양방향으로 여러 TCP 소켓 연결을 전송할 수 있다.
3단계 프로세스(three-step process)
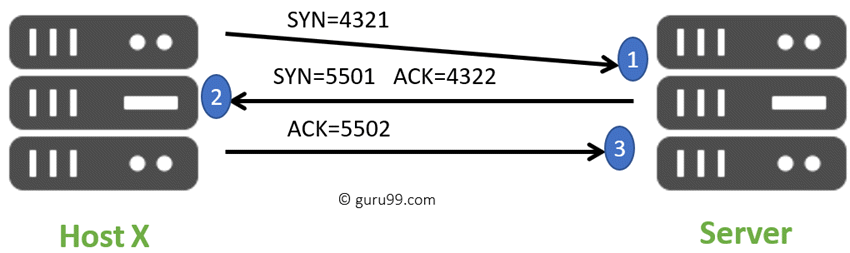
① 클라이언트 머신(client machine)은 인터넷을 통해 서버에 SYN 패킷을 보내 새 연결을 위한 접속을 요청한다.
② 서버에 새로운 연결을 허용하고 시작할 수 있는 포트가 있는 경우, 서버는 SYN/ACK 패킷으로 응답한다.
③ 클라이언트는 서버로부터 SYN/ACK 패킷을 수신하고 ACK 패킷을 전송하여 승인한다.
3단계 프로세스 후에 데이터 전송을 위해 TCP 연결이 설정된다.
5. 브라우저가 HTTP 요청(request)을 웹 서버에 보낸다.
TCP 연결이 설정되면 데이터 전송을 시작해야 한다. 브라우저는 www.google.com의 웹페이지 요청을 위해 GET method로 요청을 보낸다. 사용자의 정보 및 비밀번호 등 자격 증명(Credential)을 입력하거나 form을 제출하는 경우에는 POST 요청일 수 있다. 이 요청에는 브라우저 식별(browser identification: User-Agent 헤더), 수락할 요청의 유형(Accept 헤더), 추가 요청에 대해 TCP 연결(connection)을 활성 상태로 유지하도록 요청하는 connection 헤더와 같은 추가 정보도 포함된다. 또한 브라우저가 이 도메인에 대해 저장한 쿠키에서 가져온 정보를 전달한다.
Sample GET request (Headers are highlighted)

6. 서버가 요청을 처리하고 응답(response)한다.
서버는 브라우저로부터 요청을 수신하고 이를 요청 핸들러(request handler)에 전달하여 받은 응답(response)을 읽고 생성하는 웹 서버(ex, Apache, IIS)를 가지고 있다. 요청 핸들러는 요청된 내용을 확인하거나 필요한 경우 서버의 정보를 업데이트 하기 위해 요청, 헤더 및 쿠키를 읽는 ASP.NET, PHP, Ruby 등으로 작성된 프로그램을 의미한다. 요청 핸들러의 동작 후에 response를 특정한 포맷(형식, JSON, XML, HTML)으로 작성한다.
7. 서버가 HTTP 응답을 보낸다.
서버 응답에는 요청한 웹페이지와 상태 코드(status code), compression type(Content-Encoding), 어떻게 페이지를 캐싱하는지(Cache-Control), 설정할 쿠키, 개인 정보 등이 있다.
HTTP 서버 응답 예시

위의 응답을 보면 첫 번째 줄에 상태 코드가 표시된다.
상태코드는 숫자 코드를 사용하여 설명할 수 있는 5가지 유형이 있다.
- 1xx는 정보 메시지만을 나타냄.
- 2xx는 응답 성공을 나타냄.
- 3xx는 클라이언트를 다른 URL로 리다이렉트(redirect)함.
- 4xx는 클라이언트 측 오류를 나타냄.
- 5xx는 서버 측 오류를 나타냄.
따라서 오류가 발생하면 HTTP 응답을 보고 어떤 유형의 상태 코드를 받았는지 확인할 수 있다.
8. 브라우저는 HTML 내용(content)을 표시한다(가장 일반적인 HTML 응답의 경우).
브라우저는 HTML content를 단계별로 표시한다. 먼저 HTML의 기본틀을 렌더링한다. 그 다음엔 HTML 태그를 확인하고 이미지, CSS stylesheets, JavaScript 파일 등과 같은 웹페이지의 추가 요소에 대한 GET 요청을 보낸다. 이 정적 파일들은 브라우저에 캐싱되므로 다시 브라우저를 방문했을 때 해당 파일을 서버로부터 가져올 필요가 없으며 브라우저에 www.google.com이 나타나게 된다.
이 과정이 매우 지루하고 긴 과정처럼 보이지만, 우리는 키보드에서 Enter 키를 누른 후 웹 페이지를 렌더링하는 데 몇 초도 걸리지 않는다는 것을 알고 있다. 이 모든 단계는 우리가 알아차리기도 전에 밀리초 이내에 일어난다.
출처 및 참고자료
- [웹개발] 브라우저의 작동 원리
- How Browsers Work: Behind the scenes of modern web browsers
- 브라우저는 어떻게 동작하는가?
- 브라우저 동작 원리
- [번역] Browser에 www.google.com을 검색하면 어떤 일이 일어날까?
- Browser에서 Google.com을 검색하면 무슨 일이 발생하나요?
- [CS] 웹 브라우저는 어떻게 작동하는가?
- What happens when you type a URL in the browser and press enter?
- [MDN] 인터넷은 어떻게 동작하는가?
- 검색창에 www.google.com을 검색하면 어떤 일이 일어날까?
- 인터넷은 어떻게 동작하는가?
- DNS 서버
- TCP 3-Way Handshake (SYN, SYN-ACK,ACK)
