
⚠️시작 전 세팅사항들
⚠️잠깐!⚠️
시작하기 전,
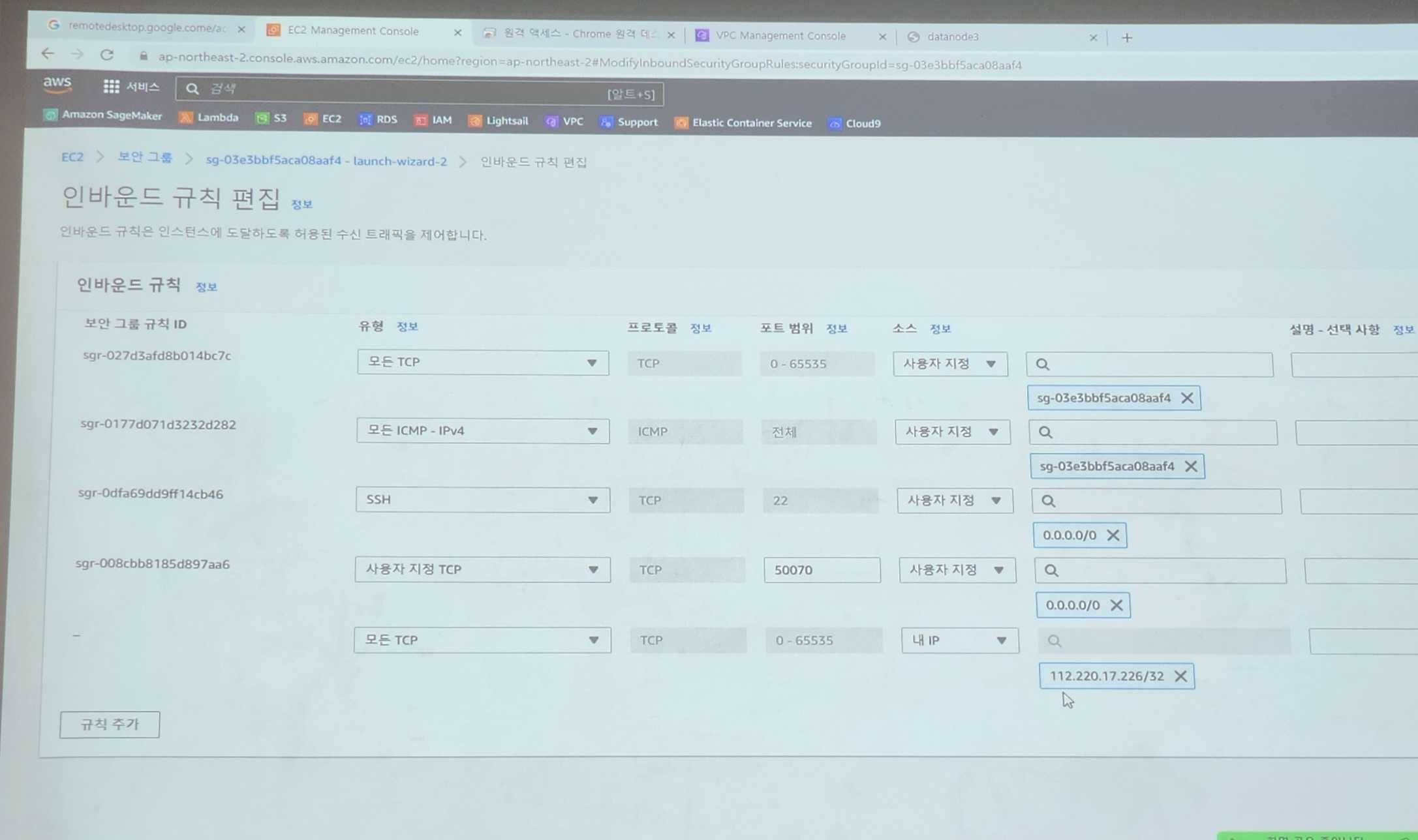
보안그룹의 인바운드 규칙에50070포트와내 IP를 추가해야 한다!
인바운드 규칙 추가하기
EC2 > 보안그룹 > 본인 인스턴스에 적용중인 보안그룹 에서
인바운드 규칙 > 인바운드 규칙 편집 누르면 나오는 편집 창에서
왼쪽 하단의 규칙 추가 버튼을 클릭하여 두 개의 추가 규칙을 생성해준다.
규칙은 다음 사진의 아래 두 개 규칙과 같이 내 IP와 50070번 포트를 추가해준다.
hosts 파일 수정하기
⚠️이게 되어야 하둡에 데이터를 push를 할 수 있다!
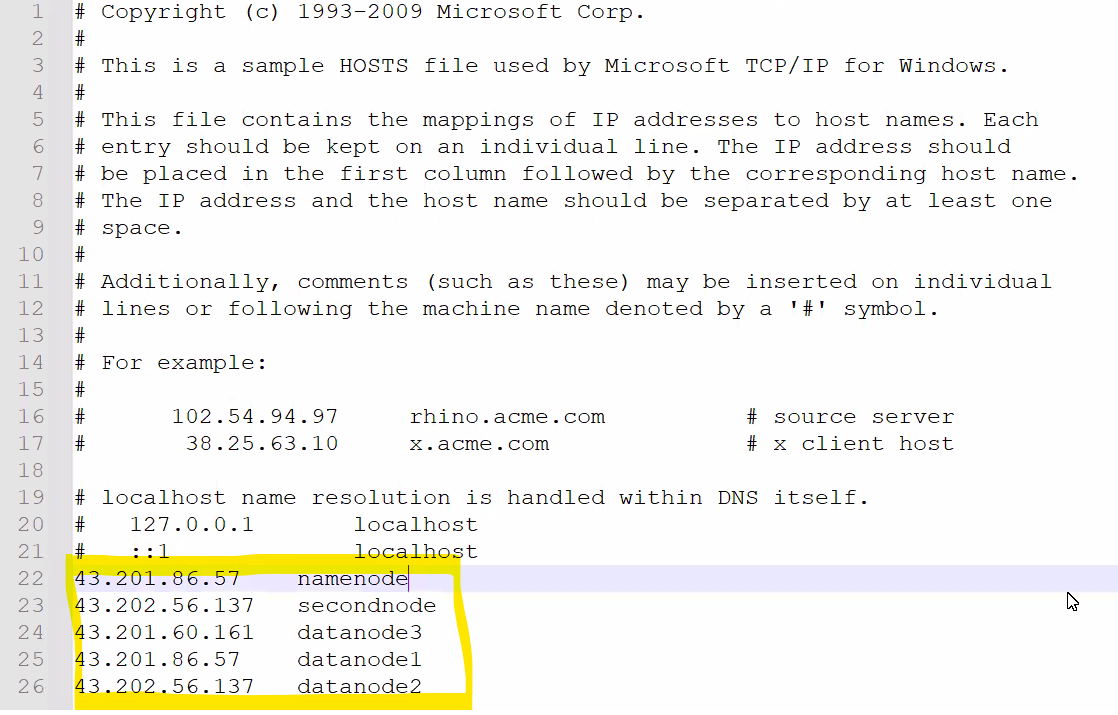
📂 hosts 파일 경로(Windows 기준)
C:\Windows\System32\drivers\etc
위의 경로에서 vim hosts 하면 다음과 같은 파일이 뜰거다.
거기에 사진속 하이라이트 부분처럼 각 노드들의 ip주소를 입력해주어야 한다.
근데!! 얘는 보안 걸려있기 때문에 직접 수정이 안된다.
복사를 하고 따로 메모장 열어 수정한 뒤,
해당 파일을 바꿔치기 해야 한다 (복붙방식)
(아마 붙여넣기 시도하면 관리자 권한 필요하다는 창 뜰거다. Yes 눌러주기!)
💡 막간 정보!

SageMaker: AWS가 제공하는 노트북 (likejupyter notebook)
👉🏻 이 안에 들어가면Spark kernel이 있음
👉🏻 얘가 또Spark밑에Hadoop을 띄움(EMR을 이용해서(비쌈))
👉🏻 분석가들이 주로 쓰는 툴
👉🏻 AWS 사용하는 웬만한 회사들은 다 사용하고 있음
❗ 하둡 초기 구성을 도저히 못하겠어서 하신 분들은 이 방식으로 사용하면 됨
(단, 모든 편한 것은 돈이다. 💰 체크 필)
putty | superputty 접속
$ su hadoop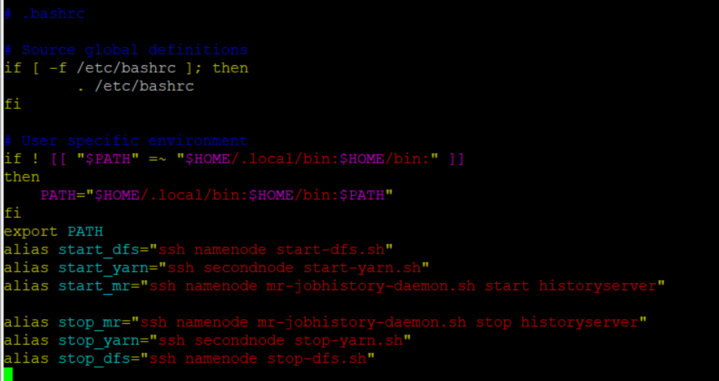
bashrc 파일에 설정해둔 alias 명령어 쭉 실행
$ start dfs$ start_yarn$ start mr🐘 hadoop으로 wordcount 써보기
client에서 작업 시작!
1. hdfs에 새로운 폴더 생성
putty에서 다음의 명령어를 실행하여
hdfs(hadoop file system)에 새로운 폴더를 만들어 준다.
$ hdfs dfs -mkdir /mydata👇🏻 그랬을 때 web으로 hadoop 접속 시 아래와 같이 hdfs 내에 파일이 생성되어 있는 상태여야 함!
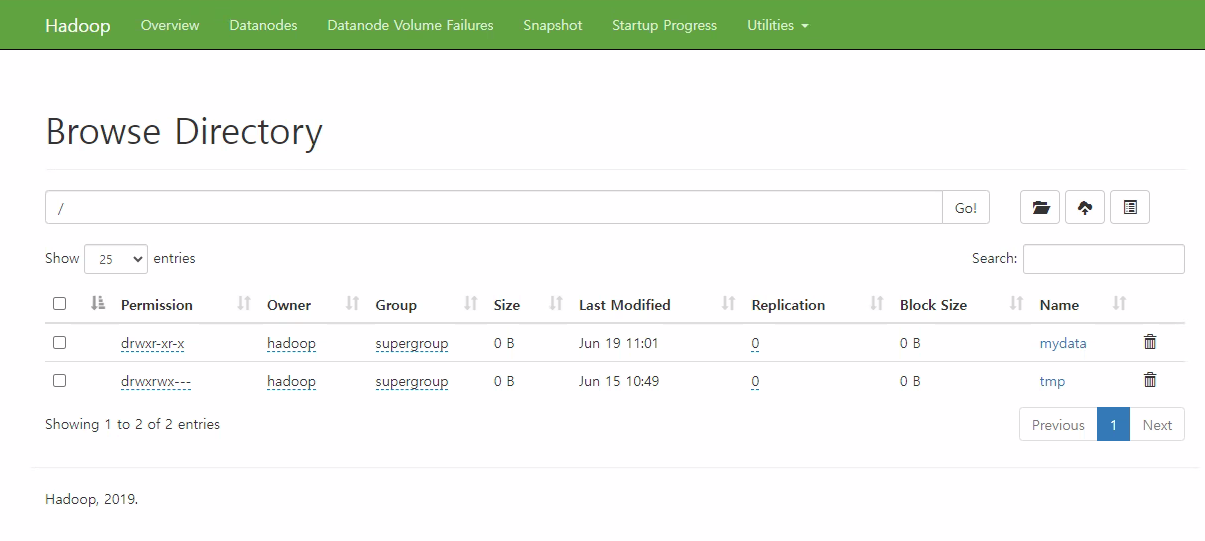
(이거는 하둡 안에 만들어진거다. 브라우저에서 아무리 찾아도 안나옴)
2. hdfs에 데이터 넣기
$ hdfs dfs -put ~/hadoop/etc/hadoop/`*.xml` /mydata👉🏻 다음의 로컬 경로 dir에서 .xml 확장자를 가지는 모든 파일(*) 을 하둡의 /mydata 경로에 넣어줘
3. 🔎 Hadoop 클러스터에서 텍스트 파일 검색하기
putty에서 아래의 명령어를 실행해준다.
$ hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep /mydata /output2 'dfs[a-z.]+'Hadoop MapReduce의 예제 중 하나인
grep을 실행하는 명령어이다.
이 명령어를 사용하여 Hadoop 클러스터에서 텍스트 파일을 검색할 수 있다!
👉🏻 이 긴 명령어가 의미하는 바는, 간단하게 아래와 같다.
/mydata경로에 있는 텍스트 파일을
dfs[a-z.]+라는 문법 (dfs가 들어가는 거를 wordcount 하겠다)을 통해서 작업할거고,
그 아웃풋을/output2에 담겠다.
하지만 더 자세히 알고싶었던 나는, GPT에게 물어봤다.
궁금하신 분들은 아래 GPT의 답변을 참고하시라.
👀 명령어 세부 해석
by. ChatCPT
hadoop jar: Hadoop JAR 파일을 실행하는 명령의 시작입니다.~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar: Hadoop 예제 JAR 파일의 경로입니다. 해당 JAR 파일에는 다양한 Hadoop 예제가 포함되어 있습니다.grep: 실행할 예제 프로그램의 이름입니다. 이 경우 "grep"은 텍스트 파일 내에서 정규 표현식을 사용하여 패턴을 찾는 예제입니다./mydata: 입력 데이터의 경로입니다. "grep" 예제에서는 이 경로에 있는 텍스트 파일에서 패턴을 찾습니다./output2: 출력 결과를 저장할 경로입니다. "grep" 예제에서는 패턴에 일치하는 텍스트를 이 경로에 저장합니다.'dfs[a-z.]+': 검색할 패턴을 지정하는 정규 표현식입니다. 이 예제에서는 "dfs"로 시작하고 소문자 알파벳과 점(.)으로 구성된 문자열을 찾습니다.
4. Mapreduce 성공 결과 세부 내역 확인
3번 과정의 명령어가 성공적으로 수행 되었다면,
다음과 같은 출력값이 나오게 된다.
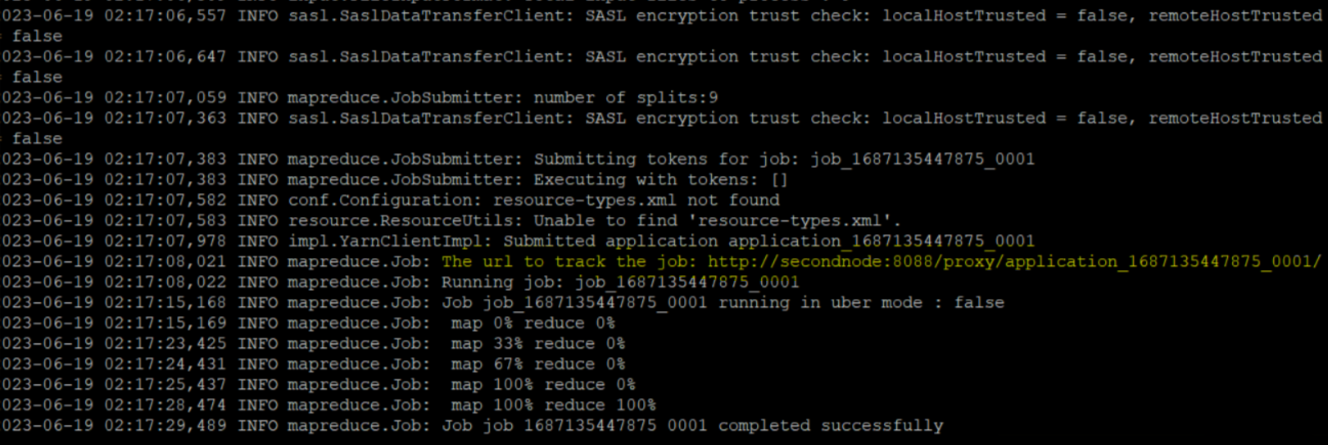
completed successfully 라는 문구만으로도 에러 없이 성공했음을 알 수 있지만,
출력값들 중 실행 결과값을 웹으로 볼 수 있는 URI(위 캡쳐속 노란 하이라이트)를 클릭해서 잘 실행됐는지 세부사항들을 확인 해볼 수도 있다!
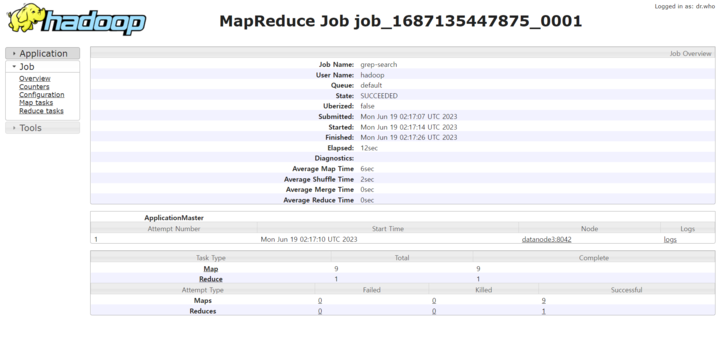
👉🏻 URI를 눌렀을 때, 이렇게 세부 집계 결과를 확인할 수 있는 창이 뜨면 성공!
4. output 확인
$ hdfs dfs -cat /output2/*putty에서 위와 같이 cat 명령어를 통해 3번 과정의 결과물을 출력 해본다.
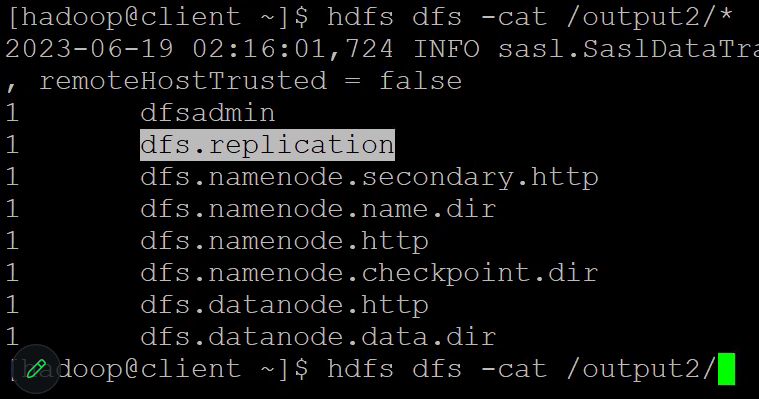
👉🏻 사진과 같이 적용했던 함수의 조건인 dfs로 시작하는 문자열들만 잘 발라져 나온다면 성공!
