💡 즉시 실행함수 IIFE
일회성 함수이며 코드를 읽는 즉시 바로 실행이 가능한 함수이름도 없는 함수입니다. 코드를 보면 함수코드 전체를
()로 감싸서 해당 코드가 변수에 저장되어있는 것 처럼 행동하고 그뒤에()를 붙임으로서 함수를 실행합니다.(function () { console.log('메롱'); })();
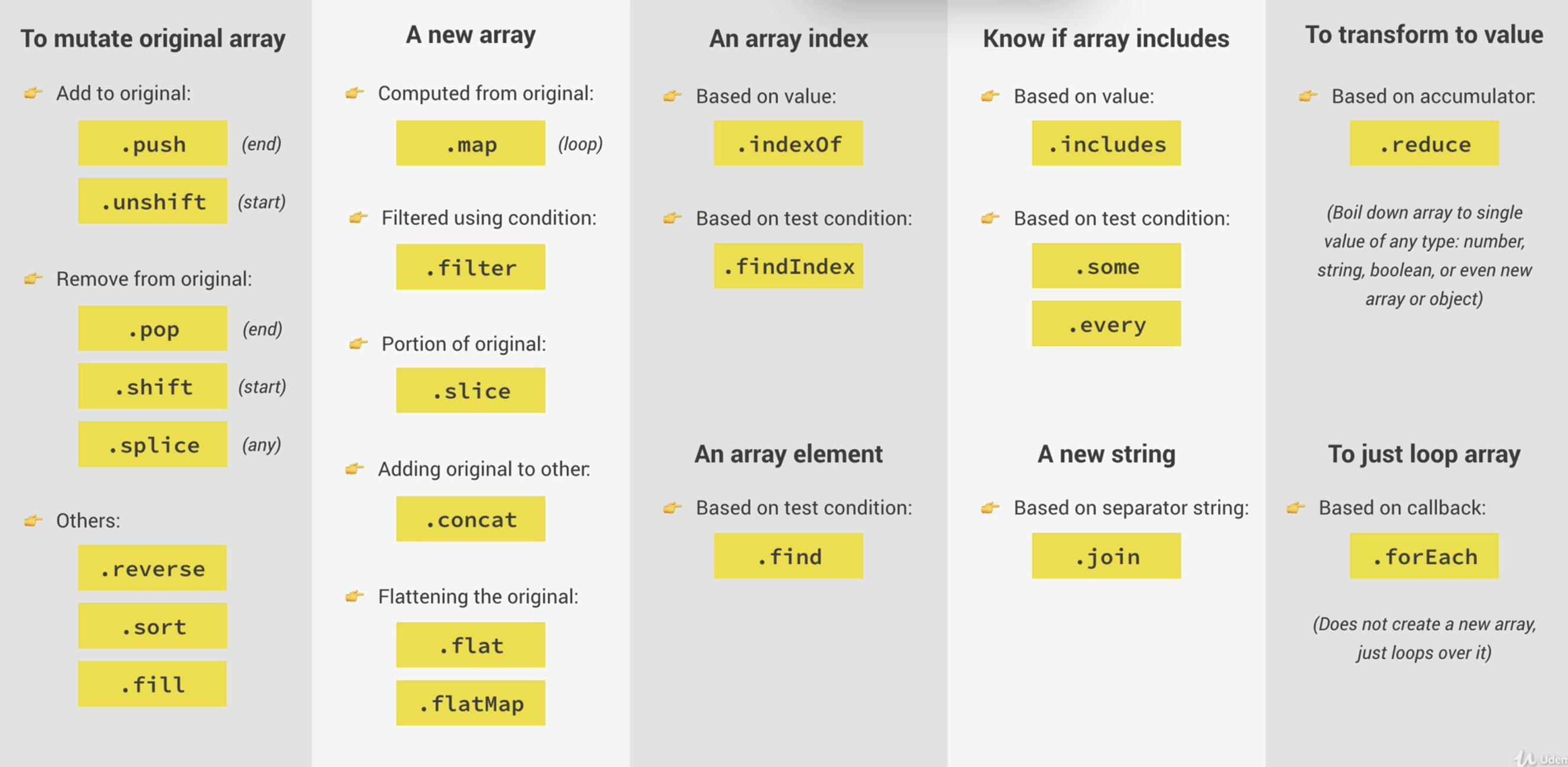
Array method
forEach()
arr.forEach(callback(currentvalue[, index[, array]])[, thisArg])
testArr.forEach(function (item, index, arr) {
console.log(item, index);
console.log(arr);
});위와 같이 굳이 testArr.entries()를 하지 않고도 index, value값을 활용할수 있으며 콜백함수를 넣을수도 있어 매우 용이하다. 다만 forEach는 Array의 iterator를 이용한 함수이므로 중간에 break, continue등이 안된다.
사실 value, index, arr 순이라고 하지만 value key arr 이다. Array iterator에서 key를 에 index가 들어가기에 저러한 정의가 나온것이다.
또한 Map, Set 같은 자료형도 적용이 된다. 객체와 문자열은 적용이 안된다. 그런데 Set의 경우 key = value이기에 의미가 없다. 따라서 중간 매개변수는 그냥 _ 언더바 처리를 한다.
💡 자바스크립트에서는 아얘 쓸모없는 매개변수는
_로 throw 처리를 한다. 예)testSet.forEach(function (item, _, arr) { console.log(item); console.log(arr); });
.map()
array.map((item, index, arr) => {
})const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
movements = movements.map((mov, index) => {
console.log(mov, index);
});위 코드와 같이 배열은 조작하는 함수에 따라 iterator와 비슷하게 동작한다. map 함수는 각배열의 원소를 콜백수로 반복하며 다시 배열에 넣고 이러한 배열을 반환합니다. 이때 반환된 배열은 새로운 배열입니다. map의 매개변수는 순서대로 item(현재 원소), index, arr 입니다.
.reduce()
누산기라고 하는 개념이다. 이전에 있던 값에 콜백함수를 통해서 계속해서 변화를 이어 나가는 것이다. 배열의 프로퍼티 함수이다. 배열의 각 원소를 순회하며 해당 배열의 원소값이 콜백함수를 통해 변형된것을 다시 첫번째 인수로 갖는다. 마지막에는 acc값을 반환한다.
let value = arr.reduce(function(accumulator, item, index, array) {
// ...
}, [initial]);위 코드는 reduce의 정의와 가깝다.
accumulator : snowBall 값이다. 배열을 순회하며 return된 값이 다시 들어간다.
item : 배열의 현재 원소의 값이다.
index : 배열의 현재 원소의 index이다.
array : 현재 reduce를 호출한 배열이다.
[initial] : snowBall의 초기값이다. acc의 초기값을 이렇게 주지 않았을때 만약 reduce를 호출한 배열이 비어있다면 acc가 콜백함수를 돌며 에러를 일으킬수 있다.
const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
movements.reduce(function (acc, item, index, array) {
console.log(acc, item, index, array);
return acc + item;
}, 0);
/*
0 200 0 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
200 450 1 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
650 -400 2 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
250 3000 3 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
3250 -650 4 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
2600 -130 5 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
2470 70 6 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
2540 1300 7 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
*/.filter()
const result = movements.filter((item, index, arr) => {
console.log(item, index, arr);
return true;
});
console.log(result);item, index, arr : 이전 의 소개와 같습니다.
filter()의 결과값은 콜백함수를 통과한 item들을 모아 배열에 넣어서 반환합니다.
다만 콜백함수에서 boolean을 반환해야하는데 이때 true를 반환하면 item을 결과배열에 넣습니다. false를 반환하면 item이 결과 배열에 들어가지 않습니다.
.find()
const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
const result = movements.find((item, index, arr) => {
console.log(item, index, arr);
return true;
});
console.log(result);
/*
200 0 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
200
*/filter 함수 와 상당히 비슷합니다. 다만 반환함에 있어서 콜백함수의 return 값이 true인 item을 바로 반환하고 이후 배열의 순회는 돌지않습니다.
.findIndex()
const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
const result = movements.findIndex((item, index, arr) => {
console.log(item, index, arr);
return item > 400;
});
console.log(result);
/*
200 0 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
450 1 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
1
*/.find()와 같은 역할을 수행하지만 .findIndex()는 해당 배열의 index를 반환한다는 점이 다릅니다.
.some()
const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
const result = movements.some((item, index, arr) => {
console.log(item, index, arr);
return item > 400;
});
console.log(result);
/*
200 0 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
450 1 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
true
*/.find(), .findIndex()와 비슷한 메커니즘을 가진 함수이나 배열에서 어느것 하나라도 조건을 만족하면 true, 하나도 만족하지 않으면 false를 반환하는 함수이다. 중간에 조건을 만족시키는 원소가 있다면 거기까지 순회하고 true를 반환합니다.
.every()
const movements = [200, 450, -400, 3000, -650, -130, 70, 1300];
const result = movements.every((item, index, arr) => {
console.log(item, index, arr);
return item > 400;
});
console.log(result);
/*
200 0 (8) [200, 450, -400, 3000, -650, -130, 70, 1300]
false
*/.some()과 비슷한 매커니즘이지만 some은 어느것 하나라도 조건을 만족하면 true를 반환하지만 every는 모든 배열의 원소가 조건을 만족해야만 true를 반환합니다. 중간에 만족시키지않는 배열이 있다면 거기까지 연산하고 false를 반환합니다.
.flat()
const arr1 = [1, 2, [3, 4]];
arr1.flat();
// [1, 2, 3, 4]
const arr2 = [1, 2, [3, 4, [5, 6]]];
arr2.flat();
// [1, 2, 3, 4, [5, 6]]
const arr3 = [1, 2, [3, 4, [5, 6]]];
arr3.flat(2);
// [1, 2, 3, 4, 5, 6]
const arr4 = [1, 2, [3, 4, [5, 6, [7, 8, [9, 10]]]]];
arr4.flat(Infinity);
// [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
const arr5 = [1, 2, , 4, 5];
arr5.flat();
// [1, 2, 4, 5]배열의 깊이에 따라 배열을 이어 붙이는 함수입니다. 실제로 코드를 보고 결과를 보아야 이해가 됩니다. 기본값으로 1이 들어가는 형태 입니다. Infinity 값을 넣으면 배열의 모든 깊이의 배열값을 모두 연결한 형태의 배열을 반환합니다.
배열의 구멍도 제거합니다.
flat()은 reduce와 spread, concat 등으로 대체 할 수 있습니다. 그렇지만 flat(Infinity) 재귀함수를 이용해서 대체해야합니다.
.flatMap()
const account1 = {
owner: 'Jonas Schmedtmann',
movements: [200, 450, -400, 3000, -650, -130, 70, 1300],
interestRate: 1.2, // %
pin: 1111,
};
const account2 = {
owner: 'Jessica Davis',
movements: [5000, 3400, -150, -790, -3210, -1000, 8500, -30],
interestRate: 1.5,
pin: 2222,
};
const account3 = {
owner: 'Steven Thomas Williams',
movements: [200, -200, 340, -300, -20, 50, 400, -460],
interestRate: 0.7,
pin: 3333,
};
const account4 = {
owner: 'Sarah Smith',
movements: [430, 1000, 700, 50, 90],
interestRate: 1,
pin: 4444,
};
const accounts = [account1, account2, account3, account4];
const overalBalance = accounts.map(acc => acc.movements).flat();
console.log(overalBalance);
const overalBalance2 = accounts.flatMap(acc => acc.movements);
console.log(overalBalance2);위코드에서 accounts는 각 배열마다 account1 .. 을 갖고 있다. overalBalance는 accounts의 각 배열의 자리를 account1.. 들의 movements 원소로 대신하였고, 그러한 새로운 배열은 flat()으로 배열을 평평하게 하였다. 그 작업을 아래 코드에서는 flatMap으로 한번에 한 모습이다.
flat은 Infinity라는 키워드로 배열의 깊이가 아무리 깊이있더라도 평평하게 했으나 flatMap은 한단계만 평평하게 한다.
솔직하게 알아야할 필요는 모르겠다.
.sort() - 배열 정렬
const owners = ['Jonas', 'Zach', 'Adam', 'Martha'];
console.log(owners.sort());
console.log(owners);
// Numbers
console.log(movements.sort());
console.log(movements);
//return > 0 A ,B
//return < 0 B, A
console.log( movements.sort((a, b) => a - b));
console.log(movements.sort((a, b) => a > b ? 1 : -1));
// [-650, -400, -130, 70, 200, 450, 1300, 3000]
배열의 sort 정렬은 원배열이 정렬됩니다. 매개변수로서 배열을 정렬하는 콜백함수를 받습니다. 이때 해당 콜백함수의 반환값은 return > 0 ? A, B : B, A 순으로 정렬됩니다. sort 함수의 매개변수값이 전달이 안되었을 경우 기본값으로 해당 문자를 정렬하면서 유니코드의 값에 따라서 정렬합니다. 유니코드 값에 따라 사전식 정렬이됩니다. (숫자의 크기 순 아님)
따라서 숫자의 오름차순 정렬, 내림차순 정렬은 콜백함수를 주어야 합니다.
위 오름차순의 정렬 함수는 두개가 정확히 동일한 결과를 나타냅니다. 콜백함수가 있기 때문에 사용자의 규칙을 정해서 정렬이 가능해집니다.
배열 생성
new Array(size)
.fill(item, startIndex, endIndex)
// Empty arrays + fill method
const x = new Array(7);
console.log(x);
// [ empty, empty, ... ]
console.log(typeof x[0]);
// undefined
// console.log(x.map(() => 5));
x.fill(1, 1, -1);
//x.fill(1);
console.log(x);배열은 객체이다. 따라서 객체의 생성시 생성자 함수안에 만드려는 배열의 사이즈를 넣으면 해당 크기만큼의 빈 배열이 생성된다. empty라는 키워드가 나오는데 해당 키워드의 타입을 알아보면 undefind이다.
.fill() 이함수는 첫번째 매개변수 만을 넣으면 해당 배열 전체의 원소를 첫번째 매개변수로 모두 채워넣는다.
두번째 매개변수는 해당 item으로 채워넣을 배열의 시작 지점 index를 나타내고 세번째 매개변수가 없다면 시작지점 부터 끝까지 채워넣는다.
세번째 매개변수는 해당 item으로 채워넣을 배열의 마지막 지점의 index를 나타낸다.
💡Array.from()
배열의 모양을 한 객체 혹은 비슷한 모양의 유사배열이나, 이터러블을 인수로 받아서 배열로 바꿔줍니다.
Array.from(similarArr, (item, index) => {
console.log(item, index);
})const y = Array.from({ length: 7 }, () => 1);
console.log(y);
// [1, 1, 1, 1, 1, 1, 1]
const z = Array.from({ length: 7 }, (item, index) => {
return index + 1;
}
// [1, 2, 3, 4, 5, 6, 7]
const testArr = Array.from('doodream', (item, index) => {
console.log(item, index);
return 1
});
// 'd', 0
// 'o', 1 ...
console.log(testArr) // [1, 1, 1, ...]위 코드에 보다시피 Array.from의 첫번째 인수는 유사배열, 객체, 배열등이지만 뒤의 콜백함수는 map과 거의 유사한 기능을 보여줍니다. 콜백함수의 세번째 인수로서 배열의 출력이 안됩니다.
Array.from(arrayLike[, mapFn[, thisArg]])
Summary