[MySQL] DB 다중화
다중화
데이터베이스 특징 : 많은 데이터를 영구적으로 보관해야함
→ 서버 내부의 로컬 저장소나 메모리로는 많은 데이터를 보관하지 못하기에 외부 저장소와 묶여야한다.
→ DB는 서버(계산이나 업무 로직 처리)와 저장소(데이터 보존)로 구분한다.
클러스터링
클러스터링 : 동일한 기능의 컴포넌트를 병렬화하는 것
- 가장 기본적인 다중화로는 1개의 저장소에 2개 이상의 서버를 두는 것
→ 데이터를 보존하는 저장소가 1개여서 정합성을 신경쓰지 않아도 된다. - 2대의 서버가 있는데, 이 2대의 서버가 모두 동작하는지의 여부에 따라 종류를 나눌 수 있다.
[ Active-Active ] : 클러스터를 구성하는 컴포넌트를 동시에 가동 (2개 모두 동작)
장점
- 시스템 다운 시간이 짧다 : 복수의 DB 서버가 동시에 동작하고 있어서 1대가 다운되어도 다른 DB가 계속 요청을 처리해서 시스템 전체가 다운되는 일을 방지할 수 있다.
- 성능이 좋다 : 동시에 동작하는 DB 서버가 증가하면서 동시에 가동하는 CPU나 메모리도 증가하기 때문에 성능도 향상될 수 있다.
단점
- 병목 현상의 가능성 : 여러 대의 서버가 하나의 저장소를 공유하기 때문에 여기서 병목 현상이 발생하여 성능 이슈가 생길 수 있다.
[ Active-Standby ] : 클러스터를 구성하는 컴포넌트 중 실제 가동은 Active만, 다른 하나(Standby)는 대기 상태
- Cold-Standby : 평소엔 Standby DB가 작동하지 않다가 Active DB가 다운된 시점에 작동하는 구성
- Hot-Standby : 평소에도 Standby DB가 작동하는 구성. (전환되는 시간이 짧지만 비싸다.)
- 둘 다 대기할 뿐, 실제로 일을 하는 것은 Active DB 1대 뿐이라는 것은 똑같다.
[ 클러스터링 동작 방식 중 Galera 방식]
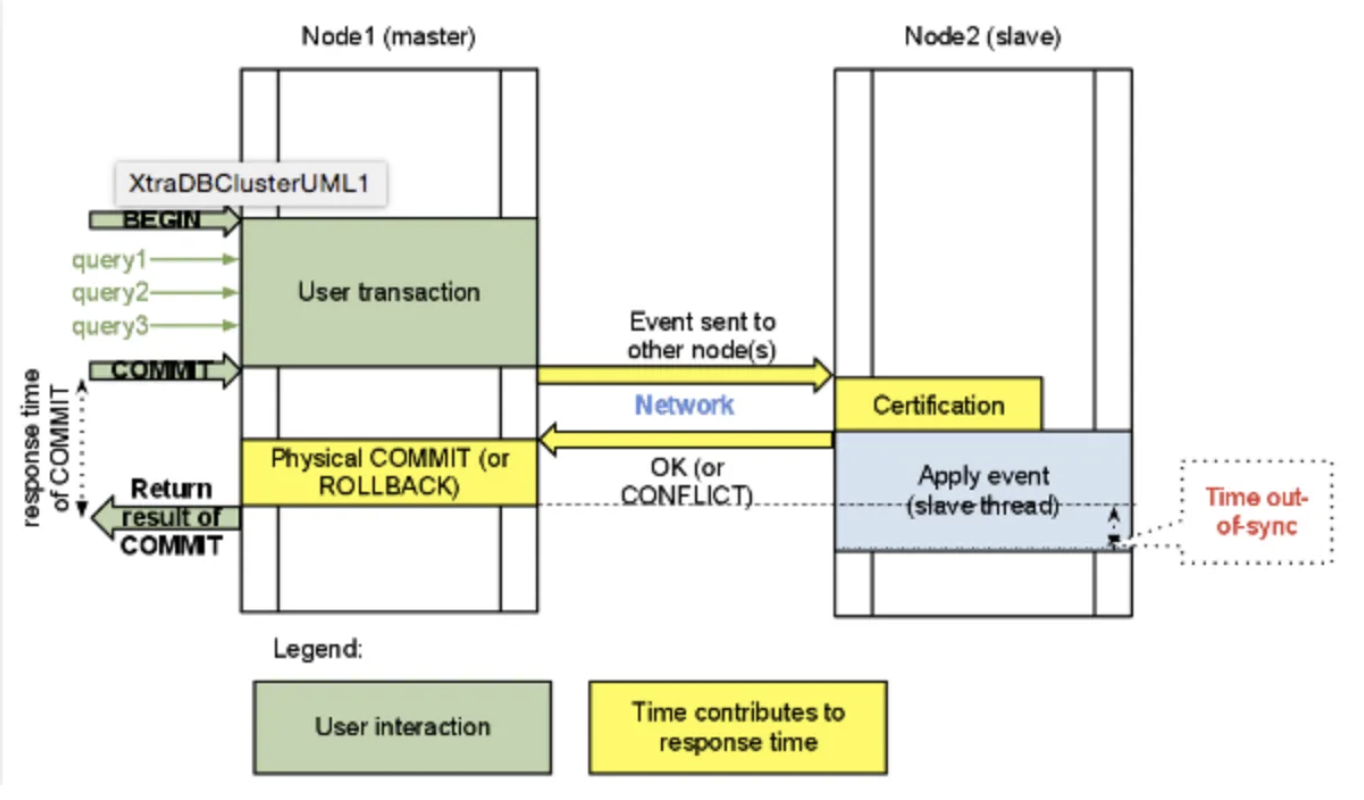
리플리케이션
클러스터링의 단점
- 저장소가 하나다! (고장나면 데이터를 모두 잃는다)
- 동기로 데이터를 공유하기 때문에 write가 느리다.
- 장애 전파의 가능성
리플리케이션 : DB 서버 + 저장소 세트를 복수로 준비하는 구성 (서버 뿐 아니라 데이터도 다중화한다)
- 저장소도 따로 분리하여 준비함으로써, 하나의 저장소가 고장났을 때에도 서비스를 유지할 수 있다. (가용성이 높다)
- 쓰기의 경우 master DB만 하게 될텐데, 그러면 다른 한쪽은 이 데이터를 정해진 주기에 맞춰서 읽어가야한다. → 정해진 주기 사이에 문제가 생기면 그만큼의 데이터는 소실된다.
- 비동기로 데이터를 복사하기 때문에 클러스터링보다 빠르다.
- 클러스터링의 경우 하나의 서버는 놀게 되는데(standby인 경우이고, Active-Active는 둘다 일한다), 리플리케이션은 한쪽을 write 다른 한쪽을 read를 담당하게 하여 성능도 높인다.
[ 리플리케이션 동작 방식 ]
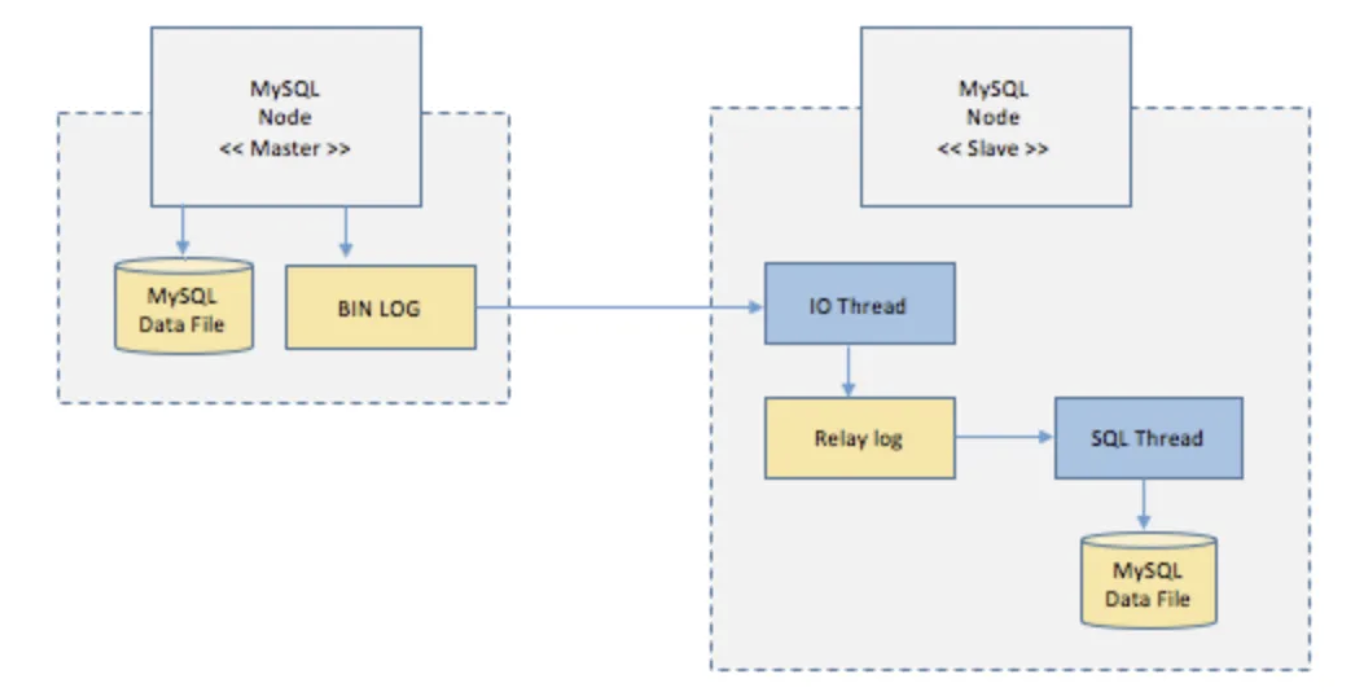
- 마스터 노드에서 시간 순서대로 수행한 업데이트 트랜잭션 로그들을 BIN LOG에 저장한다. (read 관련 트랜잭션은 마스터에서 실행되지 않기 때문에 없다)
- slave 노드의 IO Thread가 BIN LOG를 복사해서 Relay Log에 기록한다.
- SQL Thread가 Relay Log에 기록된 쿼리를 그대로 실행한다. (동일한 쿼리를 실행함으로써 동기화)
[ 클러스터 ] : 모든 디비가 동기화. (서버의 병렬 구조)
- 장애 복구 : 문제가 발생했을 때, 나머지 다른 서버가 들어오는 요청을 처리하여 장애 발생을 피할 수 있다.
- 성능에 대한 이점 : Active-Active의 경우엔 2개의 DB 서버로 요청을 분산할 수 있다.
→ master 서버가 write를 계속 받고, 다른 서버들에도 전달을 해서 master가 죽어도 다른 서버들에도 모두 동일한 데이터가 들어가있다. 그리고 다른 서버가 master로 승격한다.
[ 리플리케이션 ] : 비동기로 동작
→ 데이터 정합성이 깨질 수 있음.
샤딩
Shared-Disk : 복수의 서버가 1대의 저장소를 공유
Shared-Nothing : 서로 데이터를 공유하지 않는다. 서버와 저장소의 세트를 병렬로 늘려서 성능을 향상시킨다.
→ 병목을 방지하여 처리율이 좋다.
샤딩 : 구글이 개발한 Shared-Nothing 방식의 구성
- 저장소를 서로 공유하지 않기 때문에 각 저장소에 문제가 생기면 해당 저장소에 있는 데이터는 읽어오지 못한다.
- 다른 저장소와 데이터를 합쳐서 봐야할 때, 데이터를 합쳐줘야하는 작업을 해야한다.
[ 샤딩의 데이터를 나누는 Shard Key 방식 ]
- Hash Sharding : Hash 함수의 결과에 따라 샤딩하는 방식. DB 서버가 추가되면 해시 알고리즘이 바뀌어야한다.
- Dynamic Sharding : 샤드 키를 정의한 테이블을 만들어서 샤딩하는 방식. 샤드가 늘어나면 테이블의 키만 추가하면 된다.
- Entity Group : 연관성 있는 엔티티를 한 샤드에 두는 방식
