Introspective Tips: Large Language Model for In-Context Decision Making
introspective: 혼자 생각하는, 되돌아보는
abstract) ‘introspective tips’ 를 사용해 decision making 능력을 스스로 최적화한다
few, zero shot 환경에서 성능을 증가시킨다
세가지 시나리오 대해 성능 확인
- agent의 과거 experience로부터 학습
- expert 설명을 합치는 환경
- 다양한 게임에서 일반적인 좋은 성능을 거두는 것
prompt 를 통해 LLM 의 parameter를 변형시키지 않고 성능 증가를 이룬다
introduction)
RL 과 같은 decision making task에서 LLM의 common sense knowledge 가 유리하게 적용
(LLM은 수많은 데이터에 의해 훈련되었기 떄문에)
→ decision making agent가 더욱 informed decision + sparse reward 환경 극복
단점) domain specific 한 시나리오에서 error 나 hallucination을 보임
→ chain of thought, React, reflexion 같은 방식들이 이를 극복하기 위해 나옴
- 위의 방식들은 individual agent 에 특화된 instruction을 만들기 때문에 LLM의 generalization 능력을 약화시킴
사람의 장점 : high generalization + self evolution
→ introspection(되돌아보기) 를 통한 tip 요약하기 덕분에
기능: 과거 experience 되돌아보기, key insight 녹이기, 새로운 환경에서 적용가능한 귀중한 lesson 추출하기
reflection은 agent action 이나 experience의 사소한 특징에 집중하는 경향
- 실패로부터 배우는것에 집중
tips는 high level guidance 나 suggestion 을 제시함
- 다른 agent나 expert에서 배우는 것이 가능하며 성공, 실패 가리지 않고 둘다 모두에게서 배울 수 있음
또 다른 장점
introspective tips는 original trajectory를 있는 그대로 쓰는 것이 아니라 긴 trajectory에서 중요한 정보를 압출한 정보로 작용
- 여러 traj 에서 dependent action을 구분할 수 있도록 해줌
tips는 여러 agent 간 공유되며 generalization performance를 증대시킬 수 있다.
직접 introspective tips를 내뱉게 하기 위한 prompt 작성은 쉽지 않기 때문에 과거 trajectory에서 추출된 insight 에서 prompt 를 dynamic하게 조정하는 프레임워크를 소개한다
contribution)
- few, zero shot 시나리오에서 prompt based 방식으로 훈련없이 효율적인 decision making을 가능하게 함
- 앞서 언급한 세가지 다른 환경에서 prompt 하는 방식 제시
- dynamic 하게 적응하는 prompt 프레임워크 소개
Related work)
향 후 읽어볼 논문이 있을지에 집중
foundation model for decision making
Method)
LLM은 사람처럼 텍스트를 이해하고 만들수 있기 때문에 text-based game에서 좋은 성능을 낼 것으로 기대된다.
하지만 특정 도메인 지식이 부족한 상태에서 바로 사용될 경우 최대한의 결정을 내리지 못할 것이다.
- 저자들은 LLM의 function space가 expert policy를 만들어낼 정도로 expansive 하다고 생각
- 단, prompt를 조건부 확률로 주었을 때 policy로 활약할 수 있을 것으로 생각
즉, 원래 LLM의 function space가 p(theta) 라면
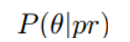
위의 수식을 policy, (pi) 에 근사할 수 있는 것이다.
LLM을 decision making 문제에 도입할 때의 걸림돌
- self-optimization
- input 길이 제한
- prompt 의존성
[self-optimization]
특정 도메인에서 사용하는 경우 LLM은 error 나 hallucination 문제를 일으킬 수 있다.
decision making performance를 위해서는 LLM이 자신의 error를 고칠 수 있는 능력이 필요하다.
→ 현재 나온 대안은 self-reflection
단점) 위의 방식은 reflection 과정에서 자신의 error로 인해 mislead 될 가능성이 있으며 task 나 환경에 대한 comprehensive 이해가 떨어질 수 있다.
대안) introspective tip 을 통한 자기발전을 제안
- 자신의 trajectory, expert 것, 다른 환경에서 trajectory에서 배울 수 있음
[Limited length input]
- RL 환경에서는 trajectory를 사용하기 때문에 input의 길이가 길어지는게 문제가 될 수 있음
- sparse 하게 주어지는 reward 또한 학습에 좋지 않음
→ 이를 해결하기 위해 tips 라는 개념을 사용 (데이터의 condense한 정보를 내포하는 문장 )
효과) crucial aspect 에 집중, trajectory가 긴 경우 미처 집고 넘어가지 못했던 연관성을 학습하는 효과
효과2) 제한적인 데이터나 변화하는 환경에서 학습하기 유리 (distilled 정보가 이러한 환경에서의 적응력을 높이기 때문에)
[prompt dependence]
특정 task에 대한 LLM의 성능은 prompt의 구조에 크게 영향을 받는다.
매번 interactive하게 사람이 prompt를 구성하는 것은 비효율적이고 costly 하기 때문에 과거 trajectory에 기반해 dynamic 하게 prompt를 조정하는 방식을 소개
basic setting
- 유저가 먼저 env 에 대한 textual description을 제시
- LLM-agent가 주어진 정보를 interpret하고 action을 결정해 반환
- system이 반환된 action을 받아 env를 업데이트
