DB를 접하게 되면 필연적으로 마주치게 되는게 있습니다.
바로 인덱스라는 것인데요 인덱스는 무엇이길래 항상 강조되고 중요하다고 얘기하는 걸까요?
그 인덱스에 대해 알아보겠습니다.
인덱스란?
만약 두꺼운 전공 책을 본다고 생각해봅시다. 그 중에서 어떤 주제에 대해 보고 싶다고 하면 우리는 먼저 목차에 들어가서 페이지를 찾죠? 그리고 그 페이지 번호를 보고 그 페이지를 피게 됩니다.
이것처럼 인덱스는 원하는 정보에 더 빠르게 도달할 수 있도록 도와주는 존재입니다.
자 그러면 구조는 어떻게 되어 있나 보면 책의 목차와 페이지 번호에 비유한 것처럼 <key, value> 값으로 이루어져 있습니다.
책에 따로 목차 페이지를 만드는 것처럼 인덱스도 별도의 공간을 차지합니다.
이러한 인덱스를 무조건 사용하는 건 아닌데요 예를 들어서 아주 얇은 책 같은 경우 목차를 들여다 보는거보다 넘기면서 찾는게 더 빠르겠죠?
또 목차에서 안경관련을 보고 싶으면 안경의 대주제에 들어가고 안경의 역사 이런 식으로 접근을 해야 목차를 잘 쓸 수 있겠죠?
인덱스를 타지 않는 경우
1. 적은 양의 데이터
2. 인덱스의 순서대로 쓰지 않는 경우
인덱스를 타지 않는 경우는 더 많지만 가장 기초적인 2가지만 알려드리겠습니다.
인덱스를 검색하다보면 클러스터 인덱스(Clustered Index)와 논클러스터 인덱스(Non Clustered Index)를 접할 수 있는데요 이게 과연 무엇일까요? 지금부터 같이 알아보겠습니다.
인덱스는 크게 루트 페이지, 리프 페이지, 데이터 페이지로 구분되며 루트 페이지 -> 리프 페이지 -> 데이터 페이지순으로 접근하는게 기본입니다.
클러스터 인덱스? 논클러스터 인덱스?
쉽게 설명하자면 클러스터 인덱스는 목차뿐만 아니라 각 부분에 책갈피도 같이 끼워있어서 더 빠르게 접근이 가능한거고 논클러스터 인덱스는 목차만 있어서 클러스터 인덱스보단 더 느리게 원하는 정보에 접근합니다.
클러스터 인덱스는 책갈피가 끼워져있기 때문에 새로 페이지를 추가하거나 수정, 삭제할때 책갈피도 같이 작업을 해줘서 좀 더 느리겠죠?
논클러스터 인덱스는 책갈피가 없기 때문에 목차만 바꿔줘도 돼서 클러스터 인덱스보다 추가,수정,삭제를 더 빠르게 할 수 있습니다.
클러스터 인덱스(Clustered Index)

위 그림처럼 클러스터 인덱스는 루트페이지(책 표지) > 리프페이지and데이터 페이지(책갈피)로 구성되어 있고바로 접근이 가능해요
보시다싶이 클러스터 인덱스는 생성과 동시에 정렬을 하기 때문에 수정을 하기 되면 맞춰서 공간을 채워줘야되기 때문에 수정이 좀 느립니다. 그대신 정렬이 되어 있어 검색이 상당히 빨라요.
쉽게 책갈피가 존재한다고 생각하면 되는데요 책갈피가 리프 페이지 역할을 해서 루트 페이지가 리프페이지로 구성이 되며, 리프 페이지 부분이 데이터 페이지로 되어 있어 바로 접근이 가능합니다.
그렇기에 추가적인 인덱스 페이지를 만들지 않아요
목차보다 책갈피로 더 빠르게 접근한다고 생각하시면 돼요
클러스터 인덱스는 테이블당 딱 1개만 가질 수 있는데 그 이유는 예를 들어서 책갈피가 빨강,파랑,노랑등등 기준이 여러개로 있으면 원하는 정보를 찾기도 힘들겠고 정렬도 이상하게 되기 때문에 하나만 존재하는거죠
그래서 가장 중요한 PK를 클러스터 인덱스로 지정하는 경우가 대부분이예요
루트 페이지에서 리프 페이지와 같아 따로 생성하지 않고 바로 접근하기 때문에 검색 속도가 빠릅니다
하지만 루트 페이지와 리프 페이지가 합쳐져서 정렬 과정을 따로 거쳐줘야 되기 때문에 입력,수정,삭제는 좀 더 느릴 수 밖에 없습니다.
주로 사용하는 경우
데이터가 워낙 방대해서 빠르게 정보에 접근해야 할 때 사용
쿼리를 범위 또는 Group By등으로 묶어서 통계 쿼리를 사용할 경우
정렬된 방식으로 데이터를 반환하는 경우
논클러스터 인덱스(Non Clustered Index)
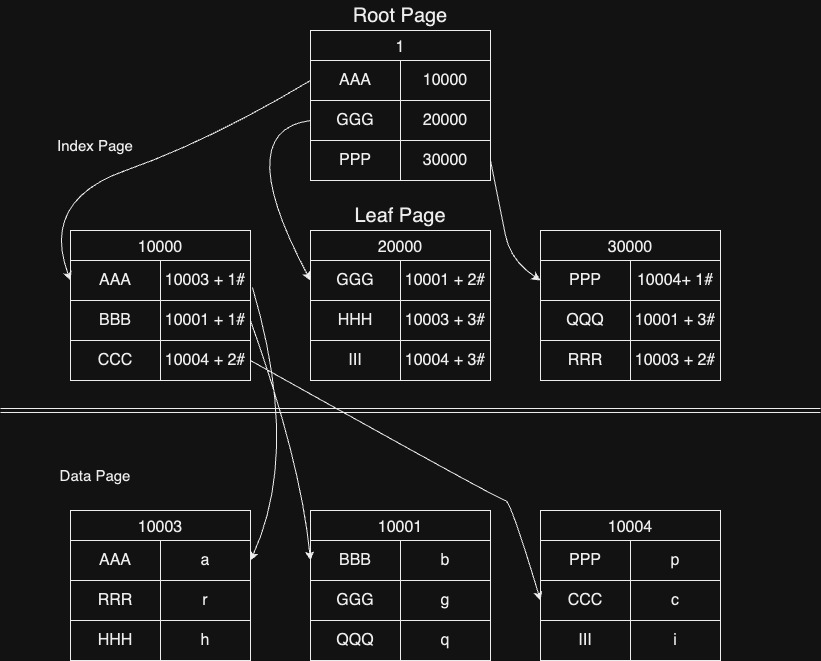
논클러스터 인덱스는 위 그림처럼 루트 페이지(표지) -> 리프 페이지(목차) -> 데이터 페이지(원하는 정보)로 이루어져 있고 정렬을 보장하지 않아서 수정이 빠르게 됩니다. 그대신 정보를 찾아갈땐 정렬이 되어 있지 않아 좀 느리다는 단점이 있습니다.
쉽게 말해서 논클러스터 인덱스는 목차를 거쳐서 가는 개념이라고 생각하시면 됩니다.
루트 페이지에서 리프 페이지(목차)를 거쳐 데이터 페이지에 접근하는거죠 그래서 클러스터 인덱스보다는 속도가 좀 느립니다.
또한 추가적인 공간을 차지합니다.
논클러스터 인덱스는 클러스터 인덱스와 다르게 여러개를 가질 수 있습니다. 목차에 여러개를 가질 수 있는 것처럼요
그치만 엄청 많이 논클러스터 인덱스를 만들어선 안됩니다. 공간을 차지하기 때문에 너무 많이 만들게 되면 오히려 성능에 영향을 줄 수 있어요
보통 5개까지가 맥시멈으로 보고 그보다 적게 만드는 경우가 대부분입니다.
결론적으로 리프 페이지를 거쳐서 데이터에 접근하기에 검색 속도가 좀 느리지만 목차 페이지에서 입력,수정,삭제를 하기 때문에 이 부분은 클러스터 인덱스보다 빠릅니다.
주로 사용하는 경우
데이터가 자주 업데이트 될 때 사용
특정 컬럼이 쿼리에서 자주 사용 될때 사용
비교
| 클러스터 인덱스(Clustered Index) | 논클러스터 인덱스(Non Clustered Index) |
|---|---|
| 하나만 생성 가능 | 여러개 생성 가능 |
| 별도의 공간 필요X | 별도의 공간 필요O |
| 검색이 빠른 대신 삽입,수정,삭제가 느림 | 검색이 느린 대신 삽입,수정,삭제가 빠름 |
| 루트 페이지 -> 리프 페이지 | 루트 페이지 -> 리프 페이지 -> 데이터 페이지 |
무조건 클러스터 인덱스가 빠르다?
결론부터 말하자면 무조건 빠르지는 않습니다.
인덱스는 데이터베이스 시스템, 테이블의 크기, 데이터의 분포, 쿼리 유형 등 여러 요건이 같이 영향을 주기 때문에 항상 클러스터 인덱스가 빠른건 아닙니다.
때에 따라서는 논클러스터 인덱스가 더 빠른 경우가 있습니다.
하지만 모든 상황에서 클러스터 인덱스가 항상 논클러스터 인덱스보다 빠르거나 유의미한 성능 차이가 있는 것은 아니지만 클러스터 인덱스는 효율적인 범위 검색과 정렬 작업을 가능하게 하므로, 이러한 작업이 많은 쿼리에 대해서는 클러스터 인덱스가 논클러스터 인덱스보다 더 나은 성능을 보일 수 있기에 자신의 상황에 맞는 인덱스 설정이 중요합니다.
인덱스에 문자열을 사용하고 싶어요
클러스터 인덱스의 문자열?
클러스터 인덱스에서는 문자열을 권장하지 않습니다.
문자열은 숫자나 정수와 달리 일반적으로 크기가 큽니다.
클러스터 인덱스는 테이블의 데이터와 함께 물리적으로 저장되기 때문에, 인덱스 크기가 커질 수 있고 그로 인해 디스크 공간을 많이 차지하게 돼 인덱스 속도 저하 문제가 있습니다.
또한 문자열을 정렬하는 작업은 숫자나 정수보다 복잡하기 때문에 문자열로 클러스터 인덱스를 생성하면 인덱스 검색과 정렬에 더 많은 시간이 소요될 수 있습니다.
문자열은 다양한 길이와 다양한 문자 조합을 가질 수 있기 때문에 데이터의 분포에 따라 영향을 줄 수 있고 문자열 값이 균일하게 분포되어 있지 않으면 인덱스의 성능이 저하될 수 있고 문자열의 정렬 순서와 인덱스의 순서가 일치하지 않을 수 있어 인덱싱에 문제가 생길 수 있습니다.
문자열을 사용하는 경우는 논클러스터 인덱스로!
논클러스터 인덱스는 데이터베이스 테이블과 별도로 데이터를 저장하므로 인덱스 순서가 데이터 순서가 물리적으로 독립적이기에 사용가능합니다.
또한 논클러스터 인덱스는 인덱스 키 값과 데이터 레코드의 위치를 매핑하기에 데이터 레코드의 주요 검색 열 값을 기준으로 인덱스를 생성하고, 인덱스는 해당 값과 데이터 레코드의 위치를 가리키는 주소로 구성됩니다.
그렇기에 문자열에 인덱스를 생성하고 싶은 경우는 논클러스터 인덱스를 이용하는게 권장됩니다.
하지만 데이터 상황에 따라 비효율적일수도 있기 때문에 상황에 맞는 인덱스 생성이 중요합니다.
결론
인덱스에 대해 알아봤고 세부적인 클러스터 인덱스와 논클러스터 인덱스에 대해 다뤄봤습니다. DB를 구성하고 쿼리를 작성하면서 가장 중요한 게 인덱스를 어떻게 설정하느냐가 아닐까 싶네요
자신이 가지고 있는 데이터의 구조와 상황에 맞게 인덱스를 잘 설정하는 것이 중요할꺼 같습니다.
인덱스를 타지 않는 경우들 인덱스를 만들었다고 무조건 타지 않기에 이 게시글도 한번 참고 해보시면 좋겠습니다.
틀린 점이 있다며 말씀 부탁드립니다.
첨언
댓글 주신 분의 의견대로 저도 여러가지 테스트를 해보았는데 단일 값을 찾아내는 경우에는 유의미한 차이를 발견하기 어려웠고 범위 값을 산정하고 정렬을 한 경우에는 유의미한 차이를 보이는 것을 확인했습니다.
테스트한 테이블은 1200만건정도였으며 그 이상이 될수록 더 큰 차이를 보일 것으로 예상됩니다.
여러가지 조건에 따라 결과 값이 달라질 수도 있기에 실행계획을 같이 실행해보며 자기의 상황에 맞게 인덱싱을 설정하는 게 가장 효율적일거라고 생각합니다.

16개의 댓글



빠르다 느리다 비교를 하는 것 보다. 클러스터 인덱스는 실제 저장공간과 맵핑 관계에 있기 때문에, 그것을 중점적으로 설명을 해주시는게 더 적절하지 않았나합니다. 실제로 속도 차이 에서는 그렇게 유의미한 차이가 없을 것 같습니다. 클러스터 인덱스를 문자열로 하면 왜 안되는지와, 클러스터 인덱스와 논클러스터 인덱스 사이에서의 유의미한 차이가 거의 없음을 설명을 하는 것이 더 적절하지 않았나 싶습니다.
정리가 잘 된 글이네요. 도움이 됐습니다.