✅ 경쟁 상태(Race Condition)
경쟁 상태는 여러 프로세스들이 동시에 데이터에 접근하는 상황에서, 어떤 순서로 접근하느냐에 따라 결과 값이 달라질 수 있는 상황
멀티 프로세서 환경에서 공유 데이터의 동시 접근은 데이터 불일치 문제를 발생시킬 수 있다.
따라서 Race Condition을 막고 일관성을 유지하기 위해서 협력 프로세스 간의 실행 순서를 정해주는 메커니즘은 동기화가 필요하다.
💡 싱글 프로세서 환경에서는 동시성 문제가 발생하지 않는가?
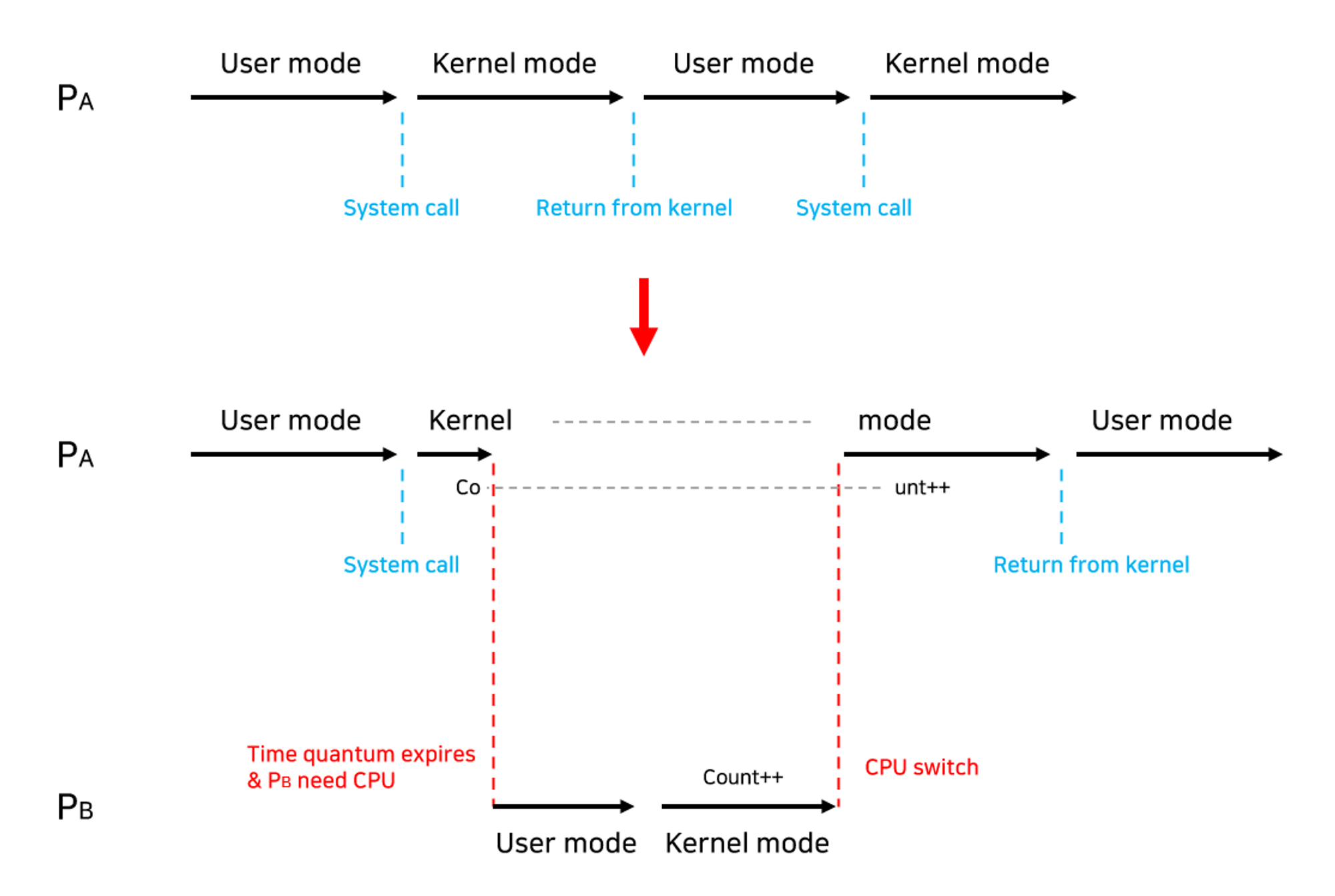
- 그렇지 않다. 일반적으로 두 프로세스의 주소 공간에서는 데이터를 공유하지 않지만, 시스템 콜을 수행하는 동안에는 둘 다 커널 주소 공간의 데이터를 접근한다. 커널 주소 공간은 공유되므로 이때 경쟁 조건이 발생할 수 있다.
아래 직접적인 예시로 설명하겠다.
프로세스가 시스템 콜을 호출해서 커널 모드로 수행 중인데 Context Switch가 발생하는 경우
- 두 프로세스의 주소 공간에서는 데이터를 공유하지 않지만, 시스템 콜을 수행하는 동안에는 둘 다 커널 주소 공간의 데이터에 접근한다.
- 이때, 커널 주소 공간에서 작업을 수행하는 도중에 CPU를 빼앗으면 race condition 발생한다.
✅ 임계구역(Critical Section)
코드상에서 경쟁 상태가 발생할 수 있는 특정 부분을 critical section이라고 한다
- 공유 자원을 사용하는 코드 영역
- 여러 개의 프로세스나 스레드가 동시에 임계구역에 접근하여 공유 자원을 사용하려고 할 때, 데이터의 일관성이 깨지거나 충돌이 발생할 수 있음
- 임계 영역을 포함한 프로세스는 아래와 같이 4가지 영역으로 구성된다.
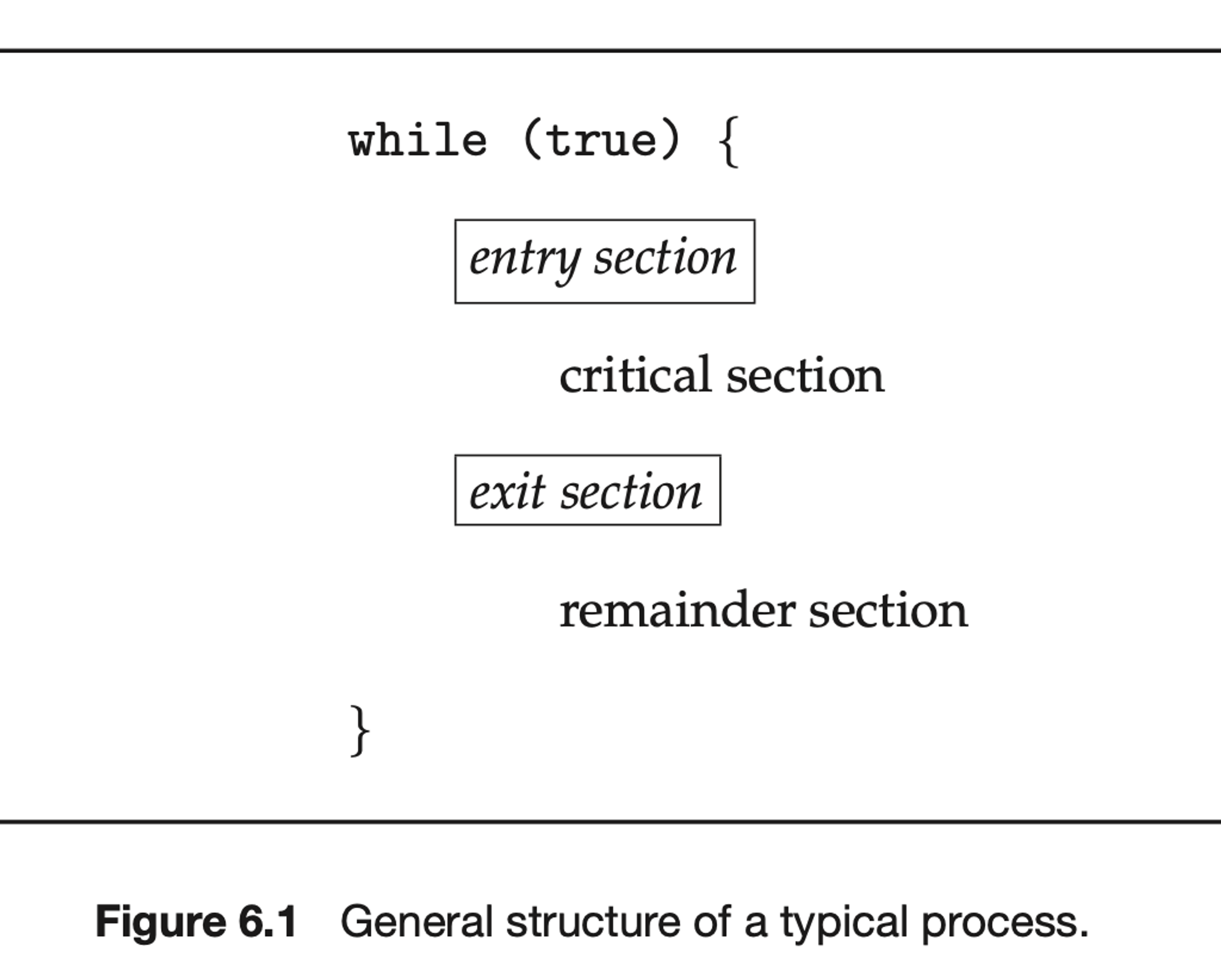
- 임계 영역을 포함한 프로세스는 아래와 같이 4가지 영역으로 구성된다.
✔️ 임계 구역 문제 해결 조건
임계 구역으로 인해 발생하는 문제들을 해결하기 위해선 3가지 조건을 만족해야 한다.
1. Mutual Exclusion(상호 배제)
이미 한 프로세스가 Critical Section에서 작업 중이면 다른 모든 프로세스는 Critical Section에 진입해서는 안된다.
2. Progress(진행)
Critical Section에서 작업 중인 프로세스가 없는 상태에서, Critical Section에 진입하고자 하는 프로세스가 존재하는 경우 진입할 수 있어야 한다.
3. Bounded Waiting(한정 대기)
프로세스가 Critical Section에 들어가기 위해 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 Critical Section에 들어가는 횟수가 한계가 있어야 한다.
- 이 말은, 임계 구역에 진입하려는 프로세스가 무한정 기다려서는 안된다는 의미.
💡 Non-preemptive kernels
임계 영역 문제가 발생하지 않는다. 하지만 비선점 스케줄링은 반응성이 떨어지기 때문에 슈퍼 컴퓨터가 아니고선 잘 사용하지 않는다.
✔️ 임계 구역 해결 방법
Critical Section Problem을 해결하기 위한 방법으로 크게 3가지가 존재함
- 소프트웨어적 방법
- 뮤텍스 (Mutex), 세마포어 (Semaphore)
- 하드웨어적 방법(원자적 명령어로 구현)
- Test-and-Set
- 인터럽트 제어로 해결하는 방법
- 인터럽트 비활성화
✅ Software-based Approach
소프트웨어적 접근 방법은 동기화 알고리즘을 사용하거나, 뮤텍스나 세마포어 같은 도구를 사용하여 문제를 해결할 수 있다.
✔️ Synchronization Algorithms
가정 : 두 프로세스 Pi, Pj가 있고 공유하는 공통 변수가 존재
1. Algorithm
Mutual Exclusion은 만족하지만 Progress는 만족하지 못함
- 현재 임계 구역에 들어갈 프로세스가 어떤 프로세스 인지를 한 변수로 나타내어 일치하는 프로세스만 진입한다.
- Pi가 remainder section이 너무 길어서 수행 중인 상태에서, Pj가 수행을 한 번 마치고 다시 Critical Section으로 진입하려고 한다면 turn == i 이기 때문에 진입할 수 없음
- 따라서 Critical Section에 아무런 프로세스가 존재하지 않음
do {
while(turn != i);
>>> critical section
turn = j;
>>> remainder section
} while(1);2. Algorithm 2
Mutual Exclusion은 만족하지만 Progress는 만족하지 못함
- 특정 프로세스가 Critical Section에 진입할 준비가 되었다는 것을 나타내는 변수를 두어, 다른 프로세스가 Critical Section에 진입하려고 한다면 현재 프로세스는 기다리는 방법
- 두 프로세스가
flag = true를 수행하고 나면 두 프로세스 모두 무한히 Critical Section에 진입하지 못하고 기다리는 상황이 발생하게 됨
do {
flag[i] == true
while (flag[j]);
>>> critical section
flag[i] = false;
>>> remainder section
} while(1);3. Algorithm 3(Peterson’s Algorithm)
Mutual Exclusion, Progress, Bounded Waiting을 모두 만족한다.
하지만 Busy Waiting 문제가 발생
- 1과 2를 합쳐놓은 개념으로 turn과 flag를 동시에 사용
- Critical Section Problem을 해결하기 위한 클래식한 방식이다.
- 두 개의 프로세스가 번갈아가며 임계 영역에 접근한다.
do {
flag[i] == true
turn = j;
while (flag[j] && turn == j);
>>> critical section
flag[i] = false;
>>> remainder section
} while(1);- 위 코드에서 flag[i] == true이면 프로세스 x가 임계 영역에 들어갈 준비가 되었음을 의미하고 turn의 최종 값이 어떤 프로세스가 임계 영역에 진입할지 결정한다.
- Pi는 Critical Section에 진입하기 위해 flag[i] = true로 바꾼다.(들어갈 준비가 되었다). 그리고 turn = j를 수행하여 상대방이 먼저 들어갈 수 있도록 함
- 상대방이 만약 들어가고 싶은 상태이고(flag[j] = true), 현재 상대방이 Critical Section에 들어가 있으면 기다린다.
- 그렇지 않으면 Pi가 들어감
- 이후에 Critical Section을 빠져나오면 flag[i] = false로 바꿔줌💡 하지만 Peterson’s Algorithm은 항상 정상적으로 작동하는 것은 아니다.
- 최신 컴파일러 또는 프로세서는 서로 연관 없는 명령의 순서를 최적화 과정에서 바꿀 수 있기 때문이다.
- 싱글 스레드 프로그램에서 코드의 결과만 고려한다면 문제가 없겠지만, 멀티 스레드 프로그램에서는 최종 결과가 예상과 다를 수 있다.
💡 Busy Waiting
이미 프로세스가 Critical Section에 존재할 때, 다른 프로세스들은 Critical Section에 계속 진입하려고 시도하여 CPU 낭비를 하게 됨
✔️ 동기화 알고리즘 비교
-
Dekker's Algorithm
두 개의 프로세스가 상호배제를 위해 공유 자원에 접근할 때 사용
- 최초의 해결법

- 최초의 해결법
-
Peterson's Algorithm
두 개의 프로세스가 상호배제를 위해 공유 자원에 접근할 때 사용
- 프로세스가 2개 인 경우만 적용 가능
- flag와 turn이라는 변수로 임계영역에 들어갈 프로세스(혹은 스레드)를 결정하는 방식
- 데커 알고리즘과 상당히 유사하지만 상대방(다른 프로세스 혹은 스레드)에게 진입기회를 양보한다는 차이가 있고 더 간단하게 구현됨
-
Bakery Algorithm(Lamport의 제과점)
이 알고리즘은 여러 개의 프로세스가 공유 자원에 접근할 때 사용
- bakery 알고리즘은 프로세스에게 고유한 번호를 부여하고, 번호를 기준으로 우선순위를 정하여 우선순위가 높은 프로세스가 먼저 임계 구역에 진입하도록 구현
- 각 프로세스가 번호를 부여받아 순서대로 자원에 접근

- bakery 알고리즘은 프로세스에게 고유한 번호를 부여하고, 번호를 기준으로 우선순위를 정하여 우선순위가 높은 프로세스가 먼저 임계 구역에 진입하도록 구현
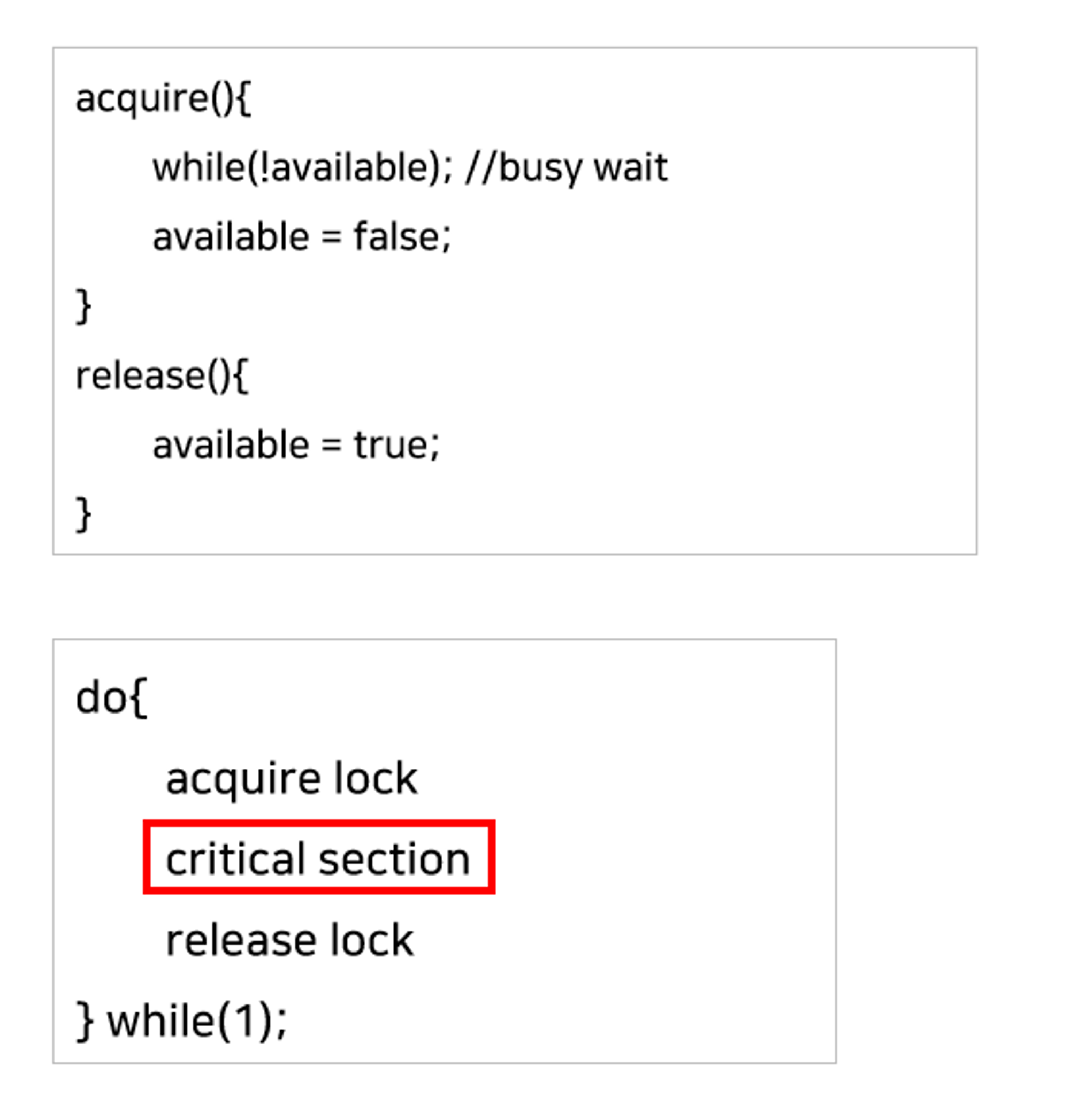
✔️ Mutex Locks
Critical Section Problem을 해결하기 위한 소프트웨어 도구 중 가장 대표적인 방법으로 Mutex(Mutual Exclusion) locks이 있다.
-
Lock이 하나만 존재할 수 있는 locking 메커니즘을 따름
-
이미 하나의 프로세스가 Critical Section에서 작업 중이면 다른 프로세스들을 Critical Section에 들어갈 수 없도록 함
-
락을 걸고 푸는 동작은 하드웨어 방식처럼 atomic하게 수행됨
Busy Waiting의 단점이 발생한다.
- 하지만 이런 Busy Waiting이 항상 나쁜 것만은 아님 (Spin Lock)
💡 Spin Lock
Lock이 반환될 때까지 계속확인하면서 프로세스가 기다리는 것을 이라고 함
- 임계영역에 진입을 위한 대기 시간이 짧을 때, 즉 Context Switching하는 비용보다 기다리는게 더 효율적인 특수한 상황을 위해 고안된 것
- 단일 CPU 시스템에서는 어차피 Lock을 갖고 있는 스레드를 풀어주기 위해서 Context Switching이 일어나야 하기 때문에 유용하지 않고, 멀티 프로세서 시스템에서 종종 사용
✔️ Semaphores
세마포어는 Busy Waiting이 필요없는 동기화 도구이며, 여러 프로세스나 스레드가 Critical Section에 진입할 수 있는 Signaling 메커니즘
카운터를 이용하여 동시에 자원에 접근할 수 있는 프로세스를 제한한다.
- 카운터는 S라는 정수형 변수로 나타내며, 사용 가능한 자원의 개수를 의미
- 세마포어 변수는 오직 두 개의 atomic한 연산을 통해서 접근할 수 있음
- 한 프로세스가 세마포어 변수를 수정할 때 다른 프로세스가 동시에 같은 세마포어 변수를 수정할 수 없음

- value : 세마포어 변수
- L : block된 프로세스들이 기다리는 Queue
세마포어에서 진입 구역과 퇴출 구역은 wait() 함수와
signal() 함수가 담당한다.

-
Block을 수행하면, 커널은 Block을 호출한 프로세스를 suspend 시키고 해당 PCB를 wait queue에 넣어줌
-
Wakeup을 수행하면 block된 프로세스 P를 깨운다음 이 프로세스의 PCB를 Ready Queue로 이동
-
signal 함수에서 S.value가 0 이하인 이유는 이전에 S.value++를 통해 자원을 내놓았는데 아직 0 이하라는 의미가 기다리고 있는 프로세스가 존재한다는 의미
-
wait나 signal 함수는 같은 세마포어에 대해 두 프로세스가 동시에 실행할 수 없으며, 만약 wait나 signal을 수행하는 동중에 preempt 된다면 Critical Section Problem에 빠지게 됨
세마포어의 종류
- Counter Semaphore : 정수 값의 범위가 0 이상으로 제한이 없으며, 주로 자원의 개수를 세는 데 사용
- 여러 프로세스에 제한된 양의 자원을 할당해 줄 때 유용하게 사용
- 임계구역에 진입 가능한 프로세스도 두 개 이상
- Binary Semaphore : 정수 값이 오직 0 또는 1 (Mutex Lock과 동일한 역할을 가짐)
- 세마포어 구조체 value 값이 1로 초기화
- 뮤텍스 락과 거의 비슷
- 다만, waiting queue를 가지고 있어 busy waiting을 방지
세마포어의 단점
- 데드락과 기아현상
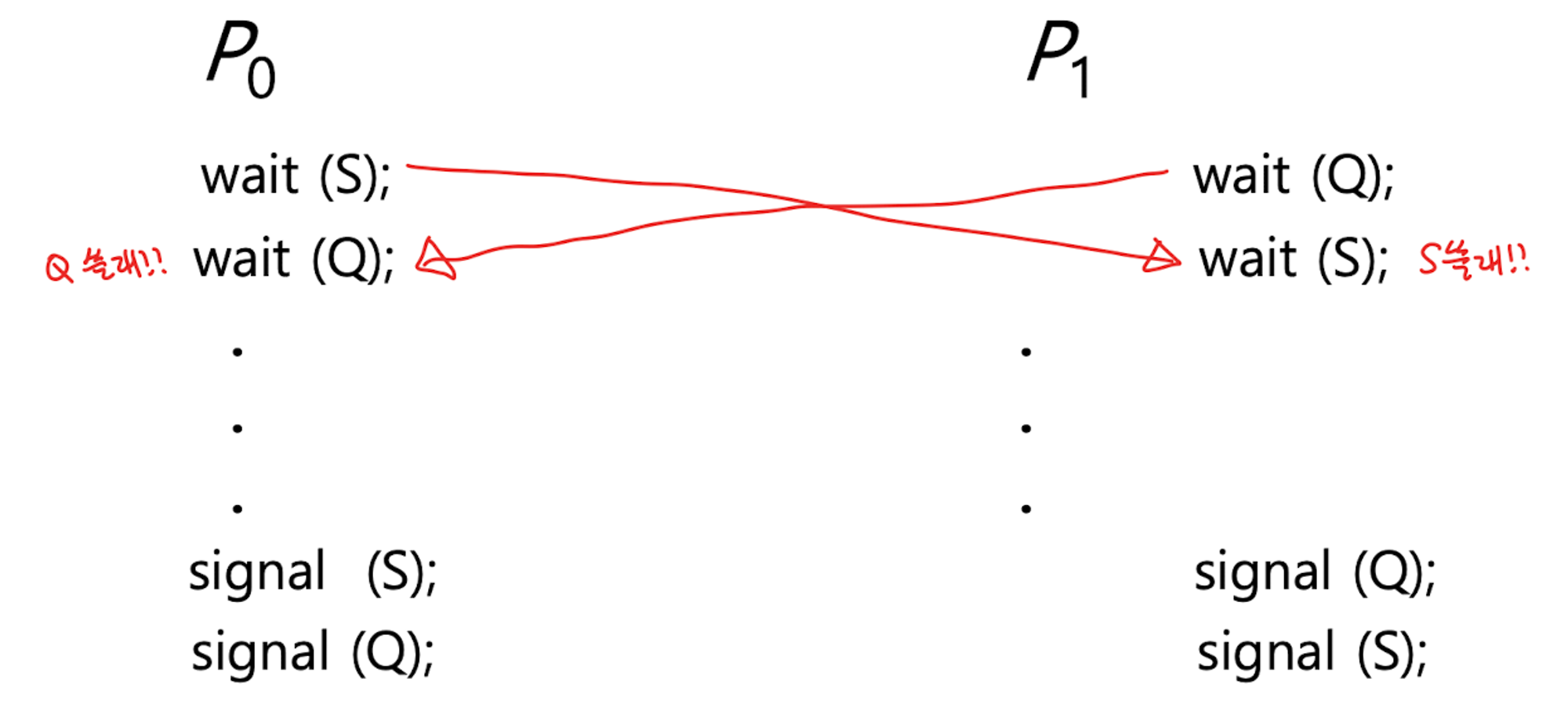
-
S와 Q는 각각 1로 초기화 된 바이너리 세마포어일 때, 위와 같은 순서로 바이너리 세마포어를 호출할 때 S와 Q가 각각 0이됨
-
이후에 두 프로세스가 모두 블록되어 데드락이 발생함
- 우선순위 역전(Priority Inversion)
- 우선순위가 높은 프로세스가 block 되어 우선순위가 낮은 프로세스가 점유하고 있는 자원을 wait하고 있는 경우 우선순위가 낮은 프로세스가 먼저 실행되는 문제
- 세 개의 프로세스 L, M, H가 있고 우선 순위는 L < M < H
- L이 자원 R을 사용중이므로 H는 block()
- L이 CPU를 사용중이다
- R을 사용하지 않는 M이 ready state가 되어 우선순위에 따라 CPU를 뺐어버린다
- M의 실행이 끝나고 L이 다시 CPU를 쓴다
- L은 볼 일 다보고 signal 호출
- H가 R 점유하고 CPU 사용
- 우선순위가 가장 높은 프로세스 H가 제일 마지막에 실행되는데 이러한 현상을 우선순위 역전 현상이라고 함
해결 1. Priority Inheritance Protocol
- PIP 알고리즘은 우선순위가 높은 프로세스가 우선순위가 낮은 프로세스의 자원을 대기하고 있을 때, 자신의 우선순위를 상속하는 방법
- M에 선점 당하지 않고 자신의 작업을 완료할 수 있음
- 데드락 발생 가능
- task2이 S1 (세마포어1) 을 획득한 후 임계 영역을 실행하던 중 task1이 실행되고, task1이 실행 중에 S2 (세마포어2) 를 요청하고 획득한 후, S1을 요청하게 되면 task2를 기다리게 됨.
- 그래서 다시 task2가 실행되는데, task2도 S2를 요청하게 되면 순환 대기가 발생.
- 상호 배제, 점유 및 대기, 순환 대기, 비선점이 모두 일어나므로 자연스레 데드락(deadlock)!
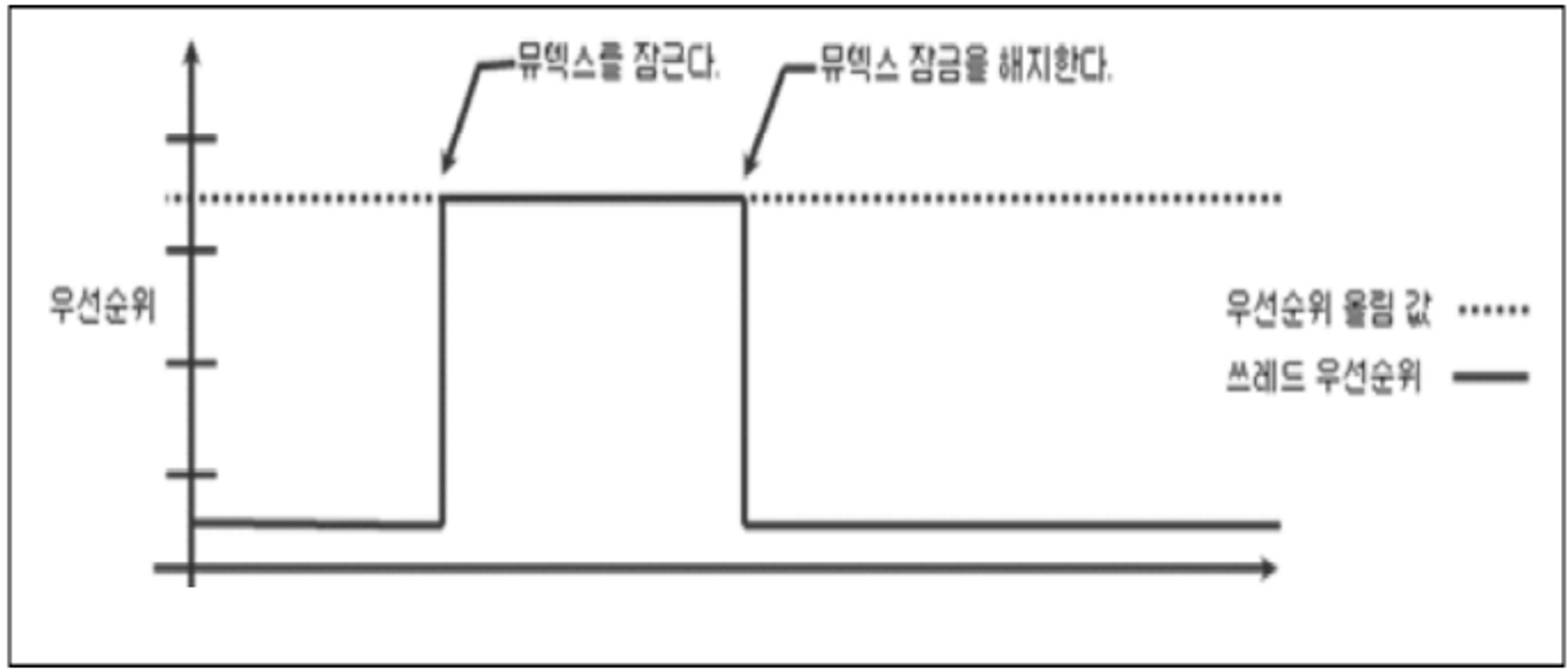
해결 2. Priority Ceiling Protocol
-
스레드가 세마포어(뮤텍스) 소유하는 동안 지정된 우선순위로 올림
-
모든 프로세스의 우선순위와 각 프로세스가 요구하는 공유자원을 미리 알고 있다는 가정 하에 가능
✔️ Monitor
세마포어의 문제점은 코딩하기가 힘들고 실수하기 쉬우며 정확성을 입증하기 어렵다는 것이다. ( V와 P의 순서에 따라 데드락이 생기거나 Mutual Exclusion이 깨질 수 있음 )
반면 Monitor는 동시 수행 중인 프로세스 사이에서 추상 데이터의 안전한 공유를 보장하기 위한 High-level 동기화 구조이다.
- 공유 데이터를 접근하기 위해서 모니터의 내부 Procedure를 통해서만 접근할 수 있음
- lock을 걸 필요가 없다.
- 세마포어는 프로그래머가 직접 wait와 signal을 사용하여 Race Condition을 해결해야하지만 모니터는 자체적인 기능으로 해결할 수 있게 된다.
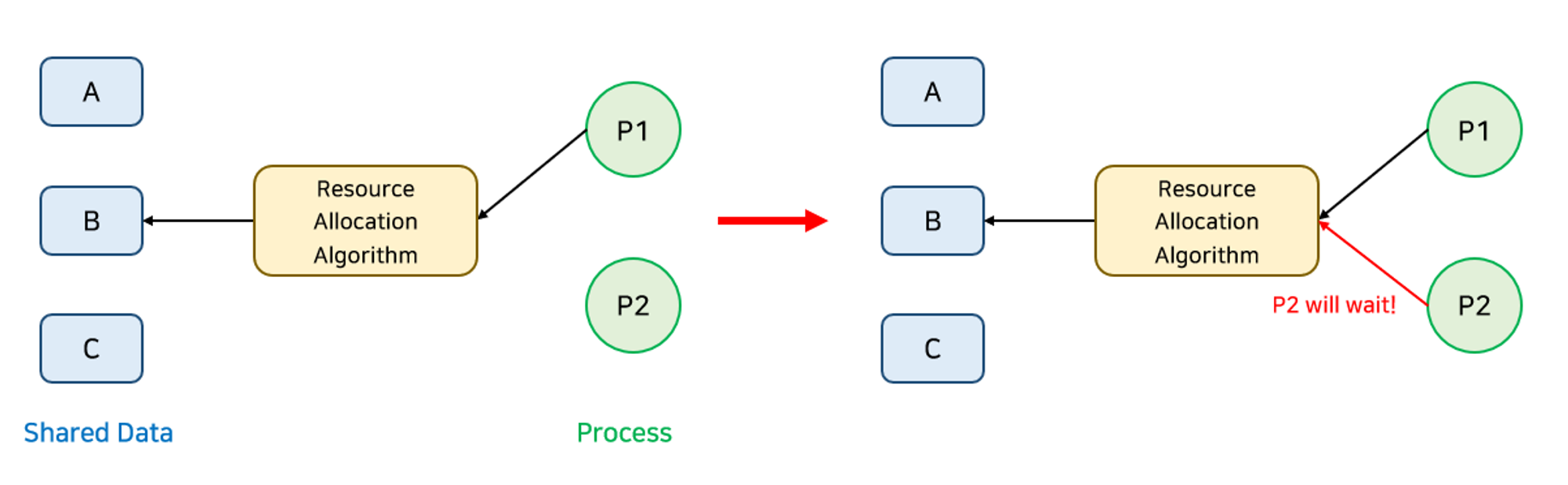
- 세마포어는 위와 같이 P1이 사용하고 있을 때 P2가 접근한다면 이것을 처리해야 하는 과정이 필요하나 모니터는 알아서 해준다.
- 세마포어는 프로그래머가 직접 wait와 signal을 사용하여 Race Condition을 해결해야하지만 모니터는 자체적인 기능으로 해결할 수 있게 된다.
- 프로세스가 공유 데이터를 사용하기 위해서는 반드시 모니터 내의 Procedure를 통과해야 함
- 프로시저는 공유 데이터 구조, 공유 데이터에 대한 연산을 제공한다.
- 모니터에는 동일한 시간에 오직 한 프로세스나 스레드만 들어갈 수 있다.
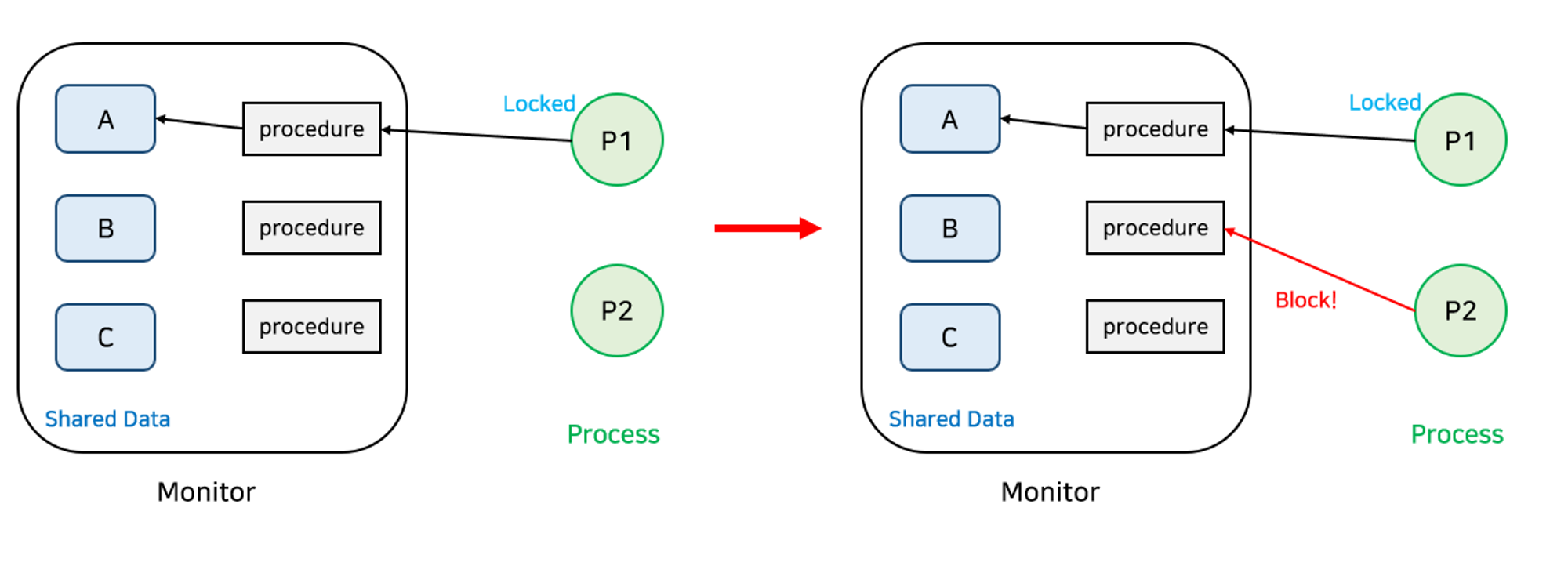
- 모니터에 진입하려고 했지만 내부에 프로세스가 들어가 있어 진입하지 못한 프로세스들은 모니터 큐에서 기다린다.
- 프로세스가 모니터 내에서 기다릴 수 있도록 조건 변수가 사용되며 조건 변수는 오직 wait와 signal 연산만으로 사용될 수 있다.
- 세마포어 변수와 유사하지만 변수가 어떤 값을 가지진 않고, 자신의 큐에 프로세스를 매달아서 sleep 시키거나 큐에서 프로세스를 깨우는 역할만 함
모니터 사용을 통해서 다음과 같은 문제를 해결할 수 있다.
- 경쟁 상태 (race condition) 문제
- 데드락 (deadlock) 문제
- 스레드간의 상호작용 문제
- 일관성 있는 동기화 문제
💡 Java에서는 synchronized에 구현되어 있다.
✅ Synchronization Hardware
소프트웨어적 방식은 데이터를 읽고 쓰는 것을 하나의 명령어로 처리할 수 없어 복잡해진 반면 하드웨어적으로 메모리에서 데이터를 읽으면서 쓰는 것까지 하나의 명령어로 동시에 수행이 가능하다면 코드가 간결해진다.
하드웨어적으로 현재 상태를 확인하고 변경하는 Test & modify를 atomic하게 수행할 수 있도록 지원하면 임계영역 문제를 해결할 수 있다.
- 현대 기계들은 특별한 atomic hardware instruction을 제공한다. 예를 들어, Test and Set 등을 활용하여 validation과 처리를 한번에 묶어서 사용한다.
✔️ Memory Barriers
-
컴퓨터 아키텍처가 애플리케이션 프로그램에게 어떠한 메모리적인 보장을 할 것인지 정하는 것을 memory model이라고 한다.
- Strongly Ordered : 한 프로세서에서의 메모리 변경이 다른 프로세서에서도 바로 확인 가능하다.
- Weakly Ordered : 한 프로세서에서의 메모리 변경이 다른 프로세서에서 바로 확인할 수 없다.
-
이러한 메모리 모델은 프로세서마다 다르기 때문에 커널 개발자들은 공유 메모리를 사용하는 멀티 프로세서에서 메모리 변경에 대한 가시성을 예측하기 어렵다.
-
대신 이 문제를 해결하기 위해 컴퓨터 아키텍처는 메모리의 변경을 다른 프로세서로 전달하는 명령을 제공한다.
- 이것이
memory barriers또는memory fence라 불린다.
- 이것이
-
해당 명령어가 수행되면 이전의 load, store 명령어가 이후의 load, store가 수행되기 전에 완료되는 것을 보장한다.
💡 Memory barrier는 굉장히 저수준의 연산이기 때문에 일반적으로 커널 개발자들이 사용한다.
✔️ test_and_set()
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return rv;
}test_and_set()의 가장 중요한 점은 Atomic하게 실행된다는 것이다.test_and_set()을 지원하는 하드웨어에서 두 개의 test_and_set() 명령이 다른 코어에서 동시에 실행된다면, 순차적으로 실행되는 것이 보장된다. (순서는 알 수 없다.)test_and_set()은 아래 코드처럼 false로 선언된lock변수를 이용해 사용한다.
do {
while (test_and_set(&lock)) ;
/* critical section */
lock = false;
/* remainder section */
} while (true);다만 위와 같은 하드웨어적 명령어는 Bounded Waiting 조건을 만족시키지 못함
- 프로세스 도착 순서와 무관하게 임계 구역에 진입할 프로세스가 정해지기 때문(not fair)
- 문제 해결을 위해 waiting array라는 배열을 사용할 수 있음
✔️ compare_and_swap()
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}Compare-and-swap 연산은 멀티스레드 환경에서 데이터 일관성 문제를 해결하기 위한 동기화 기법 중 하나로
변경하기 전에 공유 자원에 대한 값을 변경하지 않았는지 확인하여, 변경 사항이 없는 경우에만 값을 변경한다.
- 먼저 공유 자원에 대한 현재 값과 새로운 값을 비교하여, 둘이 일치하는 경우에만 새로운 값을 저장하는 연산
💡 락프리 알고리즘
- 대표적으로 CAS(compare-and-swap)를 이용한 알고리즘으로 공유 자원에 대한 접근을 동시에 처리하면서도 경쟁 조건을 방지하는 방법
- 락프리 알고리즘은 뮤텍스나 세마포어 등의 락 기반 알고리즘과 달리 락을 사용하지 않고 스레드 간의 경쟁을 해결
- 락프리 알고리즘은 락 기반 알고리즘에 비해 구현이 복잡하고 성능도 상대적으로 떨어지는 단점
-
test_and_set()과 마찬가지로 Atomic하게 실행되며, 다른 코어에서 동시에 실행되는 경우, 결과적으로는 순차적으로 실행된다. -
언제나 전달받은
value변수의 값을 그대로 반환하며,value값이expected와 다른 경우에만expected값을 새로 대입한다.
